前言
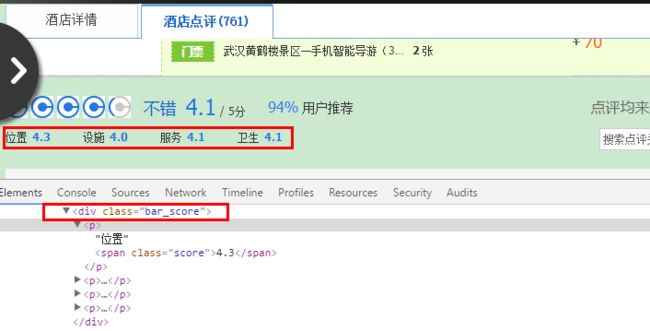
这篇内容讲解js生成内容型,上一篇讲解的所需内容是全部在html源码中可以找得到的,而比如携程网随便打开一个旅店的页面,像图1酒店点评下面的位置等信息在开发者工具中的html代码中可看到在类为bar_score的div中,可是查看源代码搜索bar_score却并没有搜索结果,原因是因为这部分内容是由js代码生成,然后在页面渲染时填充进div中,故源代码中是找不到的。

解决方式:Seleunium+BeautifulSoup
1.Selenium介绍####
Selenium本来是作为一个自动化测试工具。它可以模拟浏览器行为,比如打开浏览器,点击某个元素等等。所以可以利用它获取页面加载后的元素
安装
大多数的python第三方库都可以在以下网站中搜索找到,[python packageIndex]。后面提到的第三方库均可在该网站中下载。(https://pypi.python.org/)
Selenuim仅支持部分浏览器,这里以火狐浏览器为例,并且需要最好下载配套的Selenium和fiirefox,否则可能会遇到版本不兼容问题。这里所用到的是selenium2.42.1和firefox27.0.1(好老)。
操作
打开一个浏览器和网址
from selenium import webdriver
driver = webdriver.Firefox() #打开火狐浏览器
url = 'https://www.baidu.com'
driver.set_page_load_timeout(20) #设置页面超时时间
driver.get(url) #打开对应网址
常用方式定位元素

等待
Selenium中的等待,有时候页面加载需要一定时间,如果立即定位元素可能会出现获取不到元素的错误,所以需要设置等待。
1.强制等待sleep(xx),强制让闪电侠等xx时间,不管浏览器能不能跟上速度,还是已经提前到了,都必须等xx秒。
sleep(3)
2.隐形等待是设置了一个最长等待时间,如果在规定时间内网页加载完成,则执行下一步,否则一直等到时间截止,然后执行下一步。隐性等待,最长等30秒
driver.implicitly_wait(30)
3.显性等待,WebDriverWait,配合该类的until()和until_not()方法,就能够根据判断条件而进行灵活地等待了。它主要的意思就是:程序每隔xx秒看眼,如果条件成立了,则执行下一步,否则继续等待,直到超过设置的最长时间,然后抛出TimeoutException。隐性等待和显性等待可以同时用,但要注意:等待的最长时间取两者之中的大者
from selenium.webdriver.support.wait import WebDriverWait
WebDriverWait(driver, 20, 0.5).until(EC.presence_of_element_located(locator))
2.BeautifulSoup####
Beautiful Soup是一个可以从HTML或XML文件中提取数据的Python库,Beautiful Soup 3 目前已经停止开发,推荐在现在的项目中使用Beautiful Soup 4,不过它已经被移植到BS4了,也就是说导入时我们需要 import bs4 。
from bs4 import BeautifulSoup
可以通过id、css类、文档树等多种方式提取数据,具体使用查看官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
举例:
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_doc,"html.parser")
comment_soup = index.findAll("div", { "class" : "v2_reviewsitem" })
3.xlwt、xlrd、xlutils进行excel读写操作
xlwt::对excel进行写操作
基本操作如下,详情可参考以下文档:http://xlwt.readthedocs.io/en/latest/genindex.html
file = xlwt.Workbook() #新建一个工作簿
sheet1 = file.add_sheet(u'sheet1',cell_overwrite_ok=True) #新建一个工作表,并设置可被改写
sheet1.col(0).width=256*22 #设置第一列的列宽,xlwt的列宽是以256为一个单位
style = xlwt.easyxf('align: wrap on, vert centre, horiz center') #easyxf设置表格样式,此处设置align为垂直水平居中
sheet1.write(0,1,‘text',style) #向第1行第2列以style样式写入text字符串
xlrd:对excel进行读操作
rb_file = xlrd.open_workbook('D:/score.xls') #打开文件
# 获取指定sheet的方式
sheet1 = rb_file.get_sheet(0)
sheet2 = rb_file.sheet_by_index(1) # sheet索引从0开始
sheet3 = rb_file.sheet_by_name('sheet2')
# sheet的姓名、行列操作
print sheet2.name,sheet2.nrows,sheet2.ncols
rows = sheet2.row_values(3) # 获取第四行内容
cols = sheet2.col_values(2) # 获取第三列内容
#单元格操作
print sheet2.cell(1,0).value.encode('utf-8')
print sheet2.cell_value(1,0).encode('utf-8')
print sheet2.row(1)[0].value.encode('utf-8')
print sheet2.cell(1,0).ctype
xlutils:对excel进行追加修改操作
追加方法如下,通过对原有文件建立一个临时副本,在副本后末尾写入新数据,再将原有文件覆盖
rb_file = xlrd.open_workbook('D:/score.xls')
nrows = rb_file.sheets()[0].nrows #获取已存在的excel表格行数
wb_file = copy(rb_file) #复制该excel
sheet1 = wb_file.get_sheet(0) #建立该excel的第一个sheet副本,通过sheet_by_index()获取的sheet没有write()方法
try:
for i in range(0,len(score_list)):
for j in range(0,len(score_list[i])):
#将数据追加至已有行后
sheet1.write(i+nrows,j,score_list[i][j])
except Exception, e:
print e
wb_file.save('D:/score.xls')
携程爬虫实现##
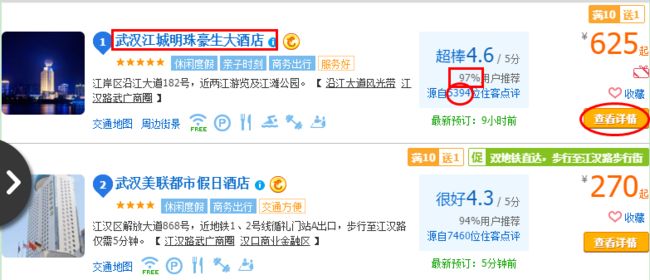
首先进入酒店列表的页面,此处是在首页设置城市为武汉之后进来的页面,在酒店列表获取红圈中的如下信息,查看详情是获取该按钮对应的链接地址,方便后面进入酒店的详情页面
然后是酒店详情页面的如下信息

最终获取数据结果如下图
程序的整体思路是,
1.以每一页为一个单位,爬取一页数据并存储完毕后,使用selenium模拟点击下一页。
2.每一页使用selenuim获取酒店列表的单条酒店信息的整体html,转换成beautifulsoup所需格式存储至hotel_list。
3.遍历hotel_list,使用beautifulsoup提取图一的信息,再跳转至详情页面爬取图二中的信息。将图一图二信息整合至hotel_info的元组,最后追加至info_list列表,构成一页所有酒店的所需信息。
4.每爬取一页存储至excel。因为使用selenium不断打开浏览器操作多了之后会出现浏览器无响应的情况,为避免最后没有数据,所有采用爬取一页存一页的方式。
代码简单讲解:
需下载的库,bs4,xlwt,xlrd,xlutils,selenium
程序结构main 为程序入口,bulid_excel建立excel文件供存储数据,read_hotel爬取数据,并设置每一页爬取完毕后调用save_score向建立的excel追加写入数据。
# -*- coding: utf-8 -*- #这行很重要,所有python代码最好都以utf-8形式编码,以防止中文乱码
import urllib2 #和urlib类似,但是可以构造request请求
from bs4 import BeautifulSoup
import re
import os #文件操作库
import xlwt
import xlrd
from xlutils.copy import copy
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time #时间操作库,强制等待sleep需引入
import traceback #一个很好的错误追踪
import socket
#driver.set_page_load_timeout(30)
socket.setdefaulttimeout(30)
class CommentContent:
#读取武汉酒店列表
def read_hotel(self):
driver = webdriver.Firefox() #打开浏览器
driver.maximize_window() #最大化窗口
page = 0 #提示作用
index_url = 'http://hotels.ctrip.com/hotel/wuhan477#ctm_ref=ctr_hp_sb_lst'
driver.get(index_url) #打开待爬取酒店列表页面
#模拟浏览器勾选酒店类型为青年旅社
btn_qn = driver.find_element_by_id('feature-35')
btn_qn.click()
time.sleep(5)
info_list = []
hotel_list = [] #存储所有带爬取酒店的信息
#range()中的数字可指定需要爬取的页数
for i in range(4):
hotel_loc = []
#获取该页的酒店列表
hotel_loc = driver.find_elements_by_xpath("//div[@class='searchresult_list searchresult_list2']")
count = 0
page_count = len(hotel_loc)
print page_count
while count < page_count:
try:
hotel = ''
#获取酒店列表的html,供beautiful转换后方便提取
hotel = hotel_loc[count].get_attribute("innerHTML")
hotel_list.append(BeautifulSoup(hotel,"html.parser"))
count += 1
except Exception,e:
#print e
print 'get hotel html error'
#continue
#点击下一页按钮
btn_next = driver.find_element_by_id('downHerf')
btn_next.click()
time.sleep(10)
count = 0
hotel_count = len(hotel_list)
#遍历酒店列表里的每一条酒店信息
while count < hotel_count:
try:
#获取每一条酒店的总体评分、用户推荐%数、查看详情的链接地址
hotel_name = hotel_list[count].findAll("h2",{"class","searchresult_name"})[0].contents[0]['title']
total_judgement_score = hotel_list[count].findAll("span", { "class" : "total_judgement_score" })[1].get_text()
hotel_judgement = hotel_list[count].find("span", { "class" : "hotel_judgement" }).get_text()
detail_href = hotel_list[count].find("a", { "class" : "btn_buy" })['href']
#构造酒店详情信息的url
detail_url = 'http://hotels.ctrip.com/' + detail_href
try:
#进入酒店详情页面
print '1-------------'
driver.get(detail_url)
print "start new page"
except TimeoutException:
print 'time out after 30 seconds when loading page'
time.sleep(3)
#点击酒店点评
try:
WebDriverWait(driver, 5).until(lambda x: x.find_element_by_id("commentTab")).click()
#程序执行到该处使用driver等待的方式并不能进入超时exception,也不能进入设定好的页面加载超时错误?????
except socket.error:
print 'commtab error'
time.sleep(10)
#driver.execute("acceptAlert") #此行一直出错,浏览器跳出警告框????无法执行任何有关driver 的操作
#continue
#driver.quit()
try:
time.sleep(3)
bar_score = WebDriverWait(driver, 10).until(lambda x: x.find_element_by_xpath("//div[@class='bar_score']"))
except Exception, e:
print 'bbbbbbbbbbbb'
print e
#bar_score = driver.find_element_by_xpath("//div[@class='bar_score']")
#对获取内容进行具体的正则提取
total_score_ptn = re.compile('(.*?)%')
try:
total_score = total_score_ptn.findall(total_judgement_score)[0]
#total_score = total_score_ptn.search(total_judgement_score).group(1)
hotel_sale_ptn = re.compile(r'\d+')
#hotel_sale = hotel_sale_ptnsearch(hotel_judgement).group(1)
hotel_sale = hotel_sale_ptn.findall(hotel_judgement)[0]
except Exception, e:
print 'tote error'
print e
#获取位置、设施、服务、卫生评分
bar_scores_ptn = re.compile(r'\d.\d') #提取字符串中的数字,格式类似于3.4
bar_scores = bar_scores_ptn.findall(bar_score.text)
try:
loc_score = bar_scores[0]
device_score = bar_scores[1]
service_score = bar_scores[2]
clean_score = bar_scores[3]
except Exception, e:
print '0------'
print e
continue
#将每个酒店的所有数据以元祖形式存储进hotel_info,存储成元组是为了方便后面写入excel,
#后将所有酒店信息追加至info_list
hotel_info = (hotel_name,total_score,hotel_sale,loc_score,device_score,service_score,clean_score)
info_list.append(hotel_info)
count += 1
#每一页有25个酒店,每爬取一页显示next page提示,并调用save_score方法存储进excel.
#另外重启浏览器,以防止其崩溃
if count % 24 == 0:
print "next page"
CommentContent().save_score(info_list)
info_list = []
driver.close()
time.sleep(10)
driver = webdriver.Firefox()
except Exception, e:
print 'get detail info error'
#print e
count += 1
continue
#traceback.print_exc()
#driver.close()
break
return info_list
#建立数据存储的excel和格式,以及写入第一行
def build_excel(self):
file = xlwt.Workbook()
sheet1 = file.add_sheet(u'sheet1',cell_overwrite_ok=True)
head_style = xlwt.easyxf('font: name Times New Roman, color-index red, bold on',
num_format_str='#,##0.00')
row0 = ('hotel_name','total_score','sale','loc_score','device_score', 'service_score', 'clean_score')
for i in range(0,len(row0)):
sheet1.write(0,i,row0[i],head_style)
file.save('D:/score1.xls')
#将数据追加至已建立的excel文件中
def save_score(self, info_list):
score_list = info_list
rb_file = xlrd.open_workbook('D:/score.xls')
nrows = rb_file.sheets()[0].nrows #获取已存在的excel表格行数
wb_file = copy(rb_file) #复制该excel
sheet1 = wb_file.get_sheet(0) #建立该excel的第一个sheet副本
try:
for i in range(0,len(score_list)):
for j in range(0,len(score_list[i])):
#将数据追加至已有行后
sheet1.write(i+nrows,j,score_list[i][j])
except Exception, e:
print e
wb_file.save('D:/score1.xls')
print 'save success'
#程序入口
if __name__ == '__main__':
CommentContent().build_excel()
CommentContent().read_hotel()