TensorRT教程
本教程不适用于CUDA新手
前言:
TensorRT简单介绍
现在TRT出了dynamic shape,重新应用与语音领域,成功一半。(目前在腾讯)
闭源部分就是官方提供的库,是TRT的核心部分;
开源部分在github上,包含Parser(caffe, onnx)、sample和一些plugin。
一、 如何选择TensorRT版本
建议使用TensorRT6.0或者TensorRT7.1:(1)GA版本;(2)支持的cuda版本广泛
TensorRT6.0支持的cuda版本广泛,cuda9.0,cuda10.0,cuda10.2不推荐cuda10.1;比如卡AE100,VE100等。
TensorRT7.1支持cuda版本在10.2以上;比较新的卡,P4,T4等。
综合推荐TensorRT6.0
cmake
demo
docker
include
二、编译TensorRT的开源源码
(1)编译使用github上的源码
环境版本:gcc5.3.1 cuda10.0 cudnn-7.6.5
注意gcc>=5.x
下载源码:
git clone -b release/6.0 htttps://github.com/nvidia/TensorRT
cd TensorRT && git submodule update --init --recursive
export TRT_SOURCE=`pwd`
下载库:
tar -xvzf TensorRT-6.0.1.5.Ubuntu-18.04.2.x86_64-gnu.cuda-10.1.cudnn7.6.tar.gz
export TRT_RELEASE=`pwd`/TensorRT-6.0.1.5 # 环境变量
mkdir build
cd build
vim ../thied_party/ # 可以省去
编译命令
cmake .. -DTRT_LIB_DIR=$TRT_RELEASE/lib -DTRT_OUT_DIR=`pwd`/out -DCUDA_VERSION=10.0-DPROTOBUF_VERSION=3.6.1
make -j4
DTRT_LIB_DIR:tensorrt内部的路径;
DTRT_OUT_DIR:库,也就是这个开源代码生成的文件夹
DCUDA_VERSION:指定cuda版本
DPROTOBUF_VERSION:指定probuf的版本
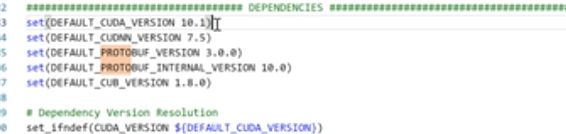
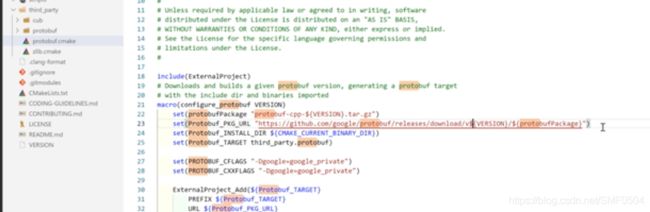
注意这里会联网下载指定版本的probuf
编译成功之后。生成的结果在build的out下,可以查看一下
ls
ll /out
(2) 编译库中带的sample
cd ../sample
make
编译的总结:
GCC版本>=5.x
需要联网下载protobuf
如果只需要sample的话,可以用库里带的源码
三、TensorRT 文档
支持的特性
3.1 基本使用方法
使用其他inference上线方式,跟TensorRT比有什么优缺点
libtorch tensorflow servise
方便时很很方面,但缺乏灵活
三个步骤:
- 定义网络
- build,构建网络,也在优化网络
- Inference
TRT Build生成的模型文件(plan file)不是跨平台的,比如在server gpu上生成的plan file不能在板子上跑。同样是server上的卡,跨架构也是不行的,在Tensla T4上生成的,不能在P40上跑。相同架构的卡,是可以的,P40上生成的,可以在P4上跑,但会报warning。
在Build阶段,TRT能做的优化。比较有限。(不怎么通用)
c++ api
- 根据模型结构使用TRT API复现定义网络 network definition
- 使用builder生成一个优化后的engine
- 将engine序列化到文件中,即生成的plan file
- 读取序列化的plan file并做inference
c++ api vs python api
本质上没啥区别,python适合算法人员验证
Tensorrt步骤
1.创建引擎 build engine
Create parser: 创建解析器
Setworkspace 设置工作空间
SetkType 设置推理模式 int8 fp16
Serialize:序列化:可以把一个引擎序列化为一个文件,可以把这个文件反序列化为引擎的一个方法或者说是操作(生成引擎)
Free : 释放空间
2.构建推理 do_inference
Bind the buffers: 绑定输入和输出,把gpu和cpu的空间想对应起来,通过名字或者id
Create GPU buffers and s stream:创建gpu的空间和它支持的流,(tensorrt可以有多流的执行,多个流或者不同的流中去执行我们的程序,成为不同的引擎。)
Trainsfer data:创建数据
Enqueue:执行
Release the stream and the buffers:
总结:
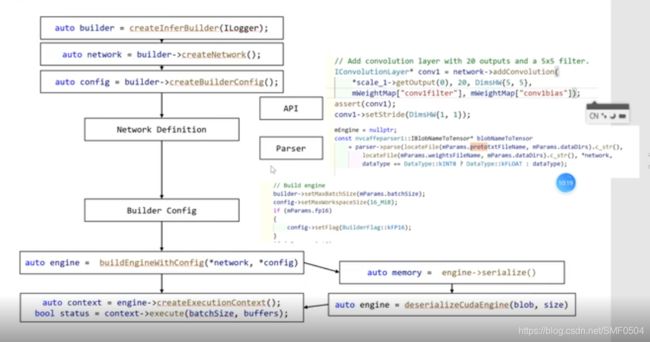

Ilogger是一个接口,可以在这个接口中定义自己的log格式,可以直接生成一个builder
序列化模型,也就是数组和内存,放在内存中。
building an engine in c++
在build阶段,TRT会根据GPU的特性和输入数据的大小,选择最后的实现算法(比如矩阵乘),所以最好build和inference都在一块显卡上。cudablas tensorrt底层调用算法不一样。(可以自己些一个全连接层,设置不通用的输入大小,查看底层调用的算法。)
谨慎设置max_batch_size
在build阶段,TRT选择最优算法的时候,是需要一定workspace的,所以设置足够的workspace size比较重要。(它会把每一个算法跑一遍,看哪个最快选择哪个,比如卷积,有一种算法,可以直接算,另一个,输入的图像转为矩阵格式,然后再给一个卷积去做矩阵乘,这样的矩阵乘就可以int8;另一种,就是将矩阵战成一个向量)
注意:
序列化顾名思义可就是将engine写到文件中,TRT build阶段比较耗时,可以一半的操作是离线build,并序列化。然后线上反序列化模型文件到inference。
调用context进行inference操作。
Engine内存储网络结构、模型参数以及必要的存储空间。
context则存储网络的中间结果。
多个context可以共享一个engine,即共享权值。这样效率比较高。
TRT显存管理
TRT显存管理,在生成context的时候,trt会根据maxBatch先开辟足够的显存。如果不想在生成context的时候开辟显存,则使用createExecutionWithoutDeviceMemory这个接口生成context。
支持自定义显存申请接口。
不重新build的情况下,更新engine中的权值
实例:
api构建网络
sampleMINISTAPI.cpp 重点:build
parser构建网络
sampleMINIST.cpp
3.2 TRT可借鉴的代码样例
看一下头文件:Nvinfer.h
layerType
第一个onnx的pa
build_op_inporters.cpp讲解了onnx转为trt
tensorflowd的tensorlow2tensorrt
3.3 plugin
3.3.1 plugin 例子和原理
-
溜一下文档(第四章)
TRT支持的Layer有限:(1)不支持的操作可以自己写plugin;(2)合并优化(比如两个op合并一个op)
编写plugin,需要继承TRT的base class,不同的base class特性如下:
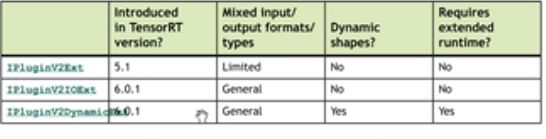
上表的三个base class中,IPluginV2Ext是为了兼容5.1,不推介使用了。推挤使用后两个,如果不需要支持dynamic shape,用IPluginV2Ext。需要支持dynamic shape则使用IPluginV2dynamicExt。

-
看sampleUffPluginV2Ext的例子,输入长度固定。
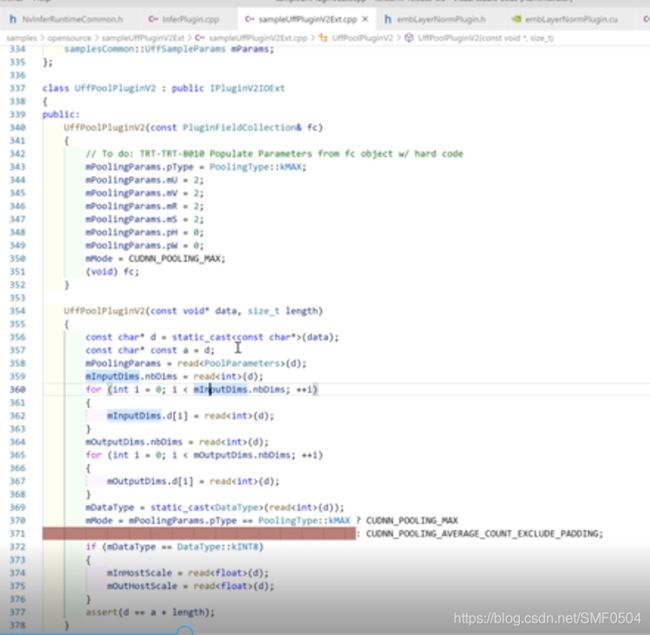
两个构造函数, -
总结各个函数的执行顺序
-
分享比较好的资料:实现TensorRT自定义插件(plugin)自由!
3.3.2 如何打造自己的plugin库

3.3.3 dynamic shape plugin库以及讲解bert的代码