一,前言
利用暑假学习了一段时间的DL,德国交通标志马上实践一下,下面主要提到我用的模型以及数据处理,如果有哪些地方大佬们觉得哪些地方做得不好或者可以改进得,非常欢迎直接在评论里提出来,初学需要一起努力。
二,数据

上面是网站中给出来的数据我已经下载下来并且保存到百度网盘中了,看情况下载(网盘限速),网盘链接:链接:https://pan.baidu.com/s/1yJ202EtrwUa7ihlfHPp9PQ 密码:v3t0。
我只需要上面四类文件中“图像与注释”的内容(其他feature我也不会用。。。),下载下来之后打开看看文件构成。

像官网介绍的一样,一共43个种类的数据,43个文件夹,每个文件夹都有小到几百张,大到上千张图片,在文件的最后都以csv格式给出来了label,图像用ppm格式给了出来,接下来我们尝试对数据进行处理。
1, 首先官网给出了从文件夹中读取数据的py程序,可以直接拿来用,可以省掉很多时间,我们先来看看他的程序以及读取结果。

上面中文注释是我看程序的时候加上去的方便理解,range()函数中的数字是你要读取的文件种类,现在是(1,2),表示读取了第二类文件!如果全数据集的话应该是(0,43),中间有一段resize()函数,这一段是方便读取的时候就统一照片尺寸,有利于后面的参数设置。
接下来用matplotlib绘制图像,将每个种类的第一张照片以及他的数量输出,代码以及效果如下图所示:

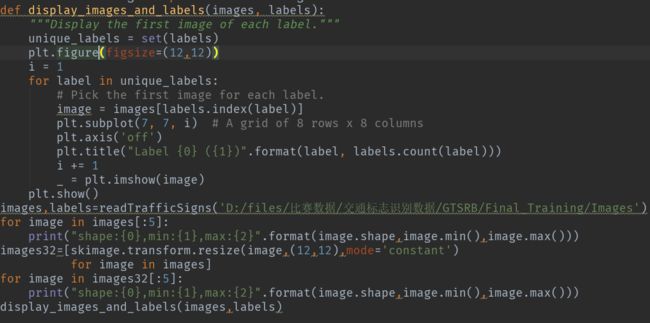
三,模型分析
对数据有了初步的认识,接下来我们就要准备模型,这里选择了难度程度较低的LeNet-5模型,LeNet-5模型由两个卷积层与两个池化层,以及两个全连接层构成。在前向传播traffic_inference中卷积层,池化层以及全连接层的参数设置如下:第一层卷积层深度为32,卷积核大小为5,第一层池化层中strides=[1,2,2,1],padding='SAME'。第一层全连接节点个数为512
后面的卷积层以及池化层参数设置都类似,这里不再一一写出 , 下面给出一组卷积层以及池化层的代码作为参考。

接下来应该是全连接神经网络,现在我们的数据是一个矩阵形式,而全链接神经网络需要我们把数据进行“拍扁”,变成一维的数据才能继续进行,我们对矩阵进行拉伸成一个一维数组,具体代码如下:

上面经过第二层池化层之后,我们将数据通过pool2的shape()函数来获取里面一共有多少个参数,将其转化为list,注意我们是一个一个batch训练的,所以shape中的第一个数字表示batch_size的大小,后面才是我们的参数,求得nodes之后我们就求得了pool2中一共的参数个数,通过reshape()函数我们将pool2重现拉伸为一维数组,之后便可以输入到全链接神经网络中,具体代码最后给出。
目前为止我们实现了前向传播的整个过程,接下来我们要实现反向传播过程,也就是我们的循环训练过程,所有代码在最后的github连接中给了出来

其中我们定义了滑动平均类为:
variable_average = tf.train.ExponentialMovingAverage(MOVING_AVERAGE_DECARY, global_step)
其中我们设定了MOVING_AVERAGE_DECARY中是滑动平均率,滑动平均可以让我们采取一种这种的方式更新我们的参数,可以防止一定的噪声。
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=y, labels=tf.argmax(y_,1))
cross_entropy采用了tf.nn.sparse_softmax_cross_entropy_with_logits(),因为最后的结果只有一个,所以可以采用上面的函数,把损失函数和softmax()函数结合到一起了,加快了运算速度,而最后的tf.argmax()函数是因为你的正确标签是one-hot类型的,至于如何转换成one-hot类型我们等会再说
learning_rate = tf.train.exponential_decay(
LEARNING_RATE_BASE,
global_step,
400,
LEARNING_RATE_DECAY,
staircase = True
)
learning_rate采用的指数下降函数,学习率刚开始设置一个合适的值,然后随着训练轮数的叠加而不断降低,这样我们就可以在迭代后期采用较小的学习率防止产生loss区线震荡,同时学习率也不宜过大,如果过大会出现loss值是None或者非常大的情况,如果出现说明你应该调低你的初始学习率,调低大概2-3个位数。
我们通过官网给出来的程序读取的数据不可以直接放进网络中训练!
不管是images的数据还是标签的数据都不符合网络要求。
①首先我们应该把照片的size重新置成一个固定值,这个我们已经在读取程序中更改过了,就是在readTrafficSign.py中的resize()函数中做的。
②接下来将图片矩阵转换成numpy矩阵才可以输入到网络中。而且读取出来的标签中是str格式,我们也需要将其转换成int形式,并且转换成one-hot数据形式,普通的数据list不能被算法学习,简单来说就是你输入进去一堆一维的数组,每个数字都表示一个实例的标签,感觉数据和标签都输入进去就可以训练了,但是有一个问题,程序根本不知道你有多少个标签,以后可以尝试用sklearn来快速转化一下(无奈现在还不会),所以现在我们需要构造一个稀疏矩阵,具体代码如下:

关于如何转化成one-hot数据类型有两种方法详细可以参考这篇文章:
https://blog.csdn.net/chaojipikaqiu/article/details/81504944
这样的话数据就可以使用了,用一个一个batch_size输入到程序中训练,需要注意的是从文件中读取数据训练的时候需要打乱顺序读取,不再给出打乱文件的程序自己感兴趣的可以自己完成。
其实中间还有很多细节没有提到,其中的具体内容就不在这里写出来,感兴趣可以去看一看。
最后给出来整个程序的连接:
https://github.com/liumengkai/Germany-traffic-sign
参考文章:https://blog.csdn.net/fu_shuwu/article/details/77073857
http://www.terrylmay.com/2017/06/generate-one-hot-data/