题记
上一篇爬的是www.dy2018.com,其实只是爬了电影列表中的标题和电影详细页链接而已,并没有对爬电影的详细页面。今天要爬的网站是http://www.87g.com/ ,当然我不想爬整个站,那就爬爬这个网站中的美女吧。
1.目标网站分析
http://www.87g.com/tupian/mnml.html ,这是目标网址。
这个网站与dy2018不一样的就是图片列表是动态加载的,页面上没有分页功能。对于动态加载问题应该如何处理,这是我们以前没有碰到的。按F12打开开发者工具,点到Network页面,向下滚动鼠标。
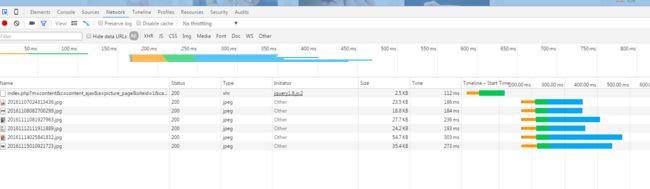
截图里面产生了网络请求,而且还返回了六张图片。
#请求地址
http://www.87g.com/index.php?m=content&c=content_ajax&a=picture_page&siteid=1&catid=35&page=7&_=1483880663241
#返回数据
{
1309: {id: "1309", content: "", readpoint: "0", groupids_view: "", paginationtype: "0", maxcharperpage: "0",…}
1310: {id: "1310", content: "", readpoint: "0", groupids_view: "", paginationtype: "0", maxcharperpage: "0",…}
1313: {id: "1313", content: "", readpoint: "0", groupids_view: "", paginationtype: "0", maxcharperpage: "0",…}
1314: {id: "1314", content: "", readpoint: "0", groupids_view: "", paginationtype: "0", maxcharperpage: "0",…}
1316: {id: "1316", content: "", readpoint: "0", groupids_view: "", paginationtype: "0", maxcharperpage: "0",…}
1317: {id: "1317", content: "", readpoint: "0", groupids_view: "", paginationtype: "0", maxcharperpage: "0",…}
}
可以分析一下请求这个链接,是不是看到一个page参数,如果修改这个page值是不是可以返回其它数据呢!实践证明确实是这样的。
美女列表分析完了,这时候随便点一个图片就能进入美女的美照详细页面,这个页面有很多图片,这些图片就是要下载的图片。
2.爬虫编写
- json解码
根据上面的分析,我并不需要加载http://www.87g.com/tupian/mnml.html ,直接访问上面的链接就可以获得所需的数据。注意response.body是bytes类型,所以需要转化为utf-8。json中的key没有实际意义,所以在代码中就直接忽略了。
#parse函数
data = json.loads(response.body.decode('utf-8'))
for v in data.values():
url = v['url']
url = response.urljoin(url)
yield scrapy.Request(url, callback=self.parsepage)
#parsepage用来分析详细页面
- xpath
上个例子解析页面使用的是BeautifulSoup,很简单也很好用,这里使用的是xpath。在详细页中按F12,打开Elements标签。

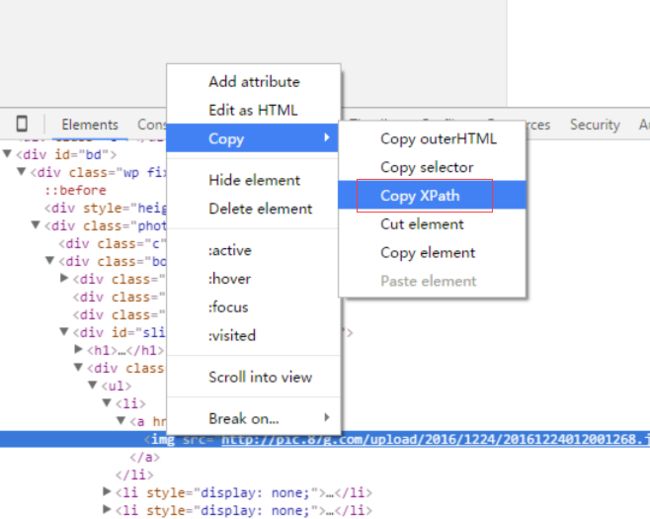
#这个是复制出来的xpath
//*[@id="mkPic"]/ul/li[1]/a/img
这时候我们要验证xpath是否能获取我想要的数据(图片链接地址)。
scrapy有个shell命令,特别好用。
Microsoft Windows [版本 6.1.7601]
版权所有 (c) 2009 Microsoft Corporation。保留所有权利。
C:\Users\Administrator>scrapy shell "http://www.87g.com/tupian/1356.html"
2017-01-08 21:34:07 [scrapy.utils.log] INFO: Scrapy 1.3.0 started (bot: scrapybot)
2017-01-08 21:34:07 [scrapy.utils.log] INFO: Overridden settings: {'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilte
r', 'LOGSTATS_INTERVAL': 0}
2017-01-08 21:34:08 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.corestats.CoreStats']
2017-01-08 21:34:08 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2017-01-08 21:34:08 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2017-01-08 21:34:08 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2017-01-08 21:34:08 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2017-01-08 21:34:08 [scrapy.core.engine] INFO: Spider opened
2017-01-08 21:34:08 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler
[s] item {}
[s] request
[s] response <200 http://www.87g.com/tupian/1356.html>
[s] settings
[s] spider
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
>>>
上面显示了很多内容,其实就是个python命令行环境,只是内置了一些scrapy对象。
>>> response.xpath('//*[@id="mkPic"]/ul/li[1]/a/img')
[]
把复制的xpath放进去确实能获取到img这个标签,可是出来的是Selector,那就再加个extract函数调用吧!
>>> response.xpath('//*[@id="mkPic"]/ul/li[1]/a/img').extract()
['']
这里我简略的谈一下xpath语法,@attr可以获取属性,一个/可以理解为层级结构,//代表根路径,*代表任何元素标签。对这个xpath修改一下,达到我的要求,获取li下面所有的img,还有进一步获取scr的属性值。
>>> response.xpath('//*[@id="mkPic"]/ul/li/a/img').extract()
['', ' ', '',
'', '
', '',
'', ' ', '',
'', '
', '',
'', ' ', '',
'', '
', '',
'', ' ', '']
', '']
我把初始的xpath中li后面的序号去掉了,还在后面加了'/@src',就这两个区别就获取了所有图片的地址。不得不说xpath比BeautifulSoup还简单,我甚至并不懂多少xpath语法。
- 详细页编码
def parsepage(self, response):
image_urls= response.xpath('//*[@id="mkPic"]/ul/li/a/img/@src').extract()
return {'image_urls':image_urls}
上面的代码其实很简单,但是有没有注意到一个问题,分析json所在的函数是parse,而处理详细页却在parsepage这个函数。分而治之的好处就是我不需要判断该如何处理当前页面内容,因为每个函数处理的页面已经固定好了。
- 图片下载
spider在完成页面的下载和分析之后接着会进入pipeline,parsepage函数返回一个图片链接列表给pipeline。
#pipelines.py
import requests
import os
class ImageDownloadPipeline(object):
def process_item(self, item, spider):
if 'image_urls' in item:#如何‘图片地址’在项目中
images = []#定义图片空集
#dir_path = ''%s/%s' % (settings.IMAGES_STORE, spider.name)'
dir_path = 'D:/images'#图片保存路径
if not os.path.exists(dir_path):
os.makedirs(dir_path)#创建文件夹
for image_url in item['image_urls']:
us = image_url.split('/')[3:]#获取路径地址,实际这个方法不太通用
#使用image_url[image_url.rfind('/')+1:]会是一个更通用的办法
image_file_name = '_'.join(us)
file_path = '%s/%s' % (dir_path, image_file_name)
images.append(file_path)
if os.path.exists(file_path):
continue
with open(file_path, 'wb') as handle:
response = requests.get(image_url, stream=True)
for block in response.iter_content(1024):
if not block:
break
handle.write(block)
item['images'] = images
return item
这里使用requests下载图片,requests不是异步库因此会影响速度。在完成了这个类之后,还要去设置才能工作。
#settings.py
ITEM_PIPELINES = {
# 'myproject.pipelines.MongoPipeline': 300,
'myproject.pipelines.ImageDownloadPipeline': 300, #这个用来在mm97这个爬虫下载图片
# 'scrapy.pipelines.images.ImagesPipeline': 1,#系统自带的下载图片
}
IMAGES_STORE = 'D:/meizitu'
当然也可以是用系统自带的图片下载pipeline,还可以在settings.py设置保存路径(IMAGE_STORE)。
3.思考
(1)一开始的时候肯定不会想到直接获取json来获取页面内容,直接分析页面也是可以获取内容的,但是动态加载,使得直接分析存在数据不全的问题。还有程序中没有考虑到该获取多少页的问题,代码中我设置的是100页,实际上确实在一百页左右,这个手动验证的。要是几千页上万页那应该如何获取边界问题呢,我想到一个二分法的问题。我假设初始值设置为100,获取第100页,如果有内容,那么就获取第200页,要是没有内容,以一个值就是150页。。。
init_page = 100
end = init_page
start = 1
while True:
if get(end) is None:
end = (start+end)/2
else:
start = end
end = 2*end
if start == end:
break
(2)这里再说说其它一个例子,www.meizitu.com这个网站有反爬虫机制,实际就是会封ip,这个后面会继续推进如何解决这个问题!