Flink API介绍
Flink提供了三层API,每层在简洁性和表达性之间进行了不同的权衡。
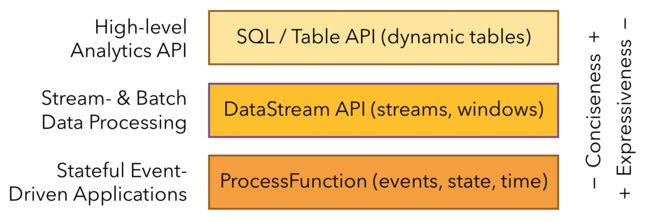
ProcessFunction是Flink提供的最具表现力的功能接口,它提供了对时间和状态的细粒度控制,能够任意修改状态。所以ProcessFunction能够为许多有事件驱动的应用程序实现复杂的事件处理逻辑。
DataStream API为许多通用的流处理操作提供原语,比如window。DataStream API适用于Java和Scala,它基于函数实现,比如map()、reduce()等。我们也可以自己扩展接口自定义函数。
SQL & Table API 这两个都是关系API,是批处理和流处理统一的API。Table API和SQL利用Apache Calcite进行解析、验证和查询优化。它们可以与DataStream和DataSet API无缝集成,并支持用户定义标量、聚合和表值函数。关系API(relational api)目标在于简化数据分析、数据流水线(data pipelining)和ETL。
我们一般主要使用DataStream进行数据处理,下面介绍的API也是DataStream相关的API。
DataStream API
DataStream是Flink编写流处理作业的API。我们前面说过一个完整的Flink处理程序应该包含三部分:数据源(Source)、转换操作(Transformation)、结果接收(Sink)。下面我们从这三部分来看DataStream API。
数据源(Source)
Flink应用程序从数据源获取要处理的数据,DataStream通过StreamExecutionEnvironment.addResource(SourceFunction) 来添加数据源。为了方便使用,Flink预提几类预定义的数据源,比如读取文件的Source、通过Sockt读取的Source、从内存中获取的Source等。
基于集合的预定义Source
基于集合的数据源一般是指从内存集合中直接读取要处理的数据,StreamExecutionEnvironment提供了4类预定义方法。
fromCollection
fromCollection是从给定的集合中创建DataStream,StreamExecutionEnvironment提供了4种重载方法:
- fromCollection(Collection
data):通过给定的集合创建DataStream。返回数据类型为集合元素类型。 - fromCollection(Collection
data,TypeInformation typeInfo):通过给定的非空集合创建DataStream。返回数据类型为typeInfo。 - fromCollection(Iterator
data,Class type):通过给定的迭代器创建DataStream。返回数据类型为type。 - fromCollection(Iterator
data,TypeInformation typeInfo):通过给定的迭代器创建DataStream。返回数据类型为typeInfo。
fromParallelCollection
fromParallelCollection和fromCollection类似,但是是并行的从迭代器中创建DataStream。
- fromParallelCollection(SplittableIterator
data,Class type) - fromParallelCollection(SplittableIterator
,TypeInfomation typeInfo)
和Iterable中Spliterator类似,这是JDK1.8新增的特性,并行读取集合元素。
fromElements
fromElements从给定的对象序列中创建DataStream,StreamExecutionEnvironment提供了2种重载方法:
- fromElements(T... data):从给定对象序列中创建DataStream,返回的数据类型为该对象类型自身。
- fromElements(Class
type,T... data):从给定对象序列中创建DataStream,返回的数据类型type。
generateSequence
generateSequence(long from,long to)从给定间隔的数字序列中创建DataStream,比如from为1,to为10,则会生成1~10的序列。
基于Socket的预定义Source
我们还可以通过Socket来读取数据,通过Sockt创建的DataStream能够从Socket中无限接收字符串,字符编码采用系统默认字符集。当Socket关闭时,Source停止读取。Socket提供了5个重载方法,但是有两个方法已经标记废弃。
- socketTextStream(String hostname,int port):指定Socket主机和端口,默认数据分隔符为换行符(\n)。
- socketTextStream(String hostname,int port,String delimiter):指定Socket主机和端口,数据分隔符为delimiter。
- socketTextStream(String hostname,int port,String delimiter,long maxRetry):该重载方法能够当与Socket断开时进行重连,重连次数由maxRetry决定,时间间隔为1秒。如果为0则表示立即终止不重连,如果为负数则表示一直重试。
基于文件的预定义Source
基于文件创建DataStream主要有两种方式:readTextFile和readFile。(readFileStream已废弃)。readTextFile就是简单读取文件,而readFile的使用方式比较灵活。
readTextFile
readTextFile提供了两个重载方法:
- readTextFile(String filePath):逐行读取指定文件来创建DataStream,使用系统默认字符编码读取。
- readTextFile(String filePath,String charsetName):逐行读取文件来创建DataStream,使用charsetName编码读取。
readFile
readFile通过指定的FileInputFormat来读取用户指定路径的文件。对于指定路径文件,我们可以使用不同的处理模式来处理,FileProcessingMode.PROCESS_ONCE模式只会处理文件数据一次,而FileProcessingMode.PROCESS_CONTINUOUSLY会监控数据源文件是否有新数据,如果有新数据则会继续处理。
readFile(FileInputFormat inputFormat,String filePath,FileProcessingMode watchType,long interval,TypeInformation typrInfo)
| 参数 | 说明 | 实例 |
|---|---|---|
| inputFormat | 创建DataStream指定的输入格式 | |
| filePath | 读取的文件路径,为URI格式。既可以读取普通文件,可以读取HDFS文件 | file:///some/local/file 或hdfs://host:port/file/path |
| watchType | 文件数据处理方式 | FileProcessingMode.PROCESS_ONCE或FileProcessingMode.PROCESS_CONTINUOUSLY |
| interval | 在周期性监控Source的模式下(PROCESS_CONTINUOUSLY),指定每次扫描的时间间隔 | 10 |
| typeInformation | 返回数据流的类型 |
readFile提供了几个便于使用的重载方法,但它们最终都是调用上面这个方法的。
- readFile(FileInputFormat
inputFormat,String filePath):处理方式默认使用FileProcessingMode.PROCESS_ONCE。 - readFile(FileInputFormat
inputFormat,String filePath,FileProcessingMode watchType,long interval):返回类型默认为inputFormat类型。
需要注意:在使用FileProcessingMode.PROCESS_CONTINUOUSLY时,当修改读取文件时,Flink会将文件整体内容重新处理,也就是打破了"exactly-once"。
自定义Source
除了预定义的Source外,我们还可以通过实现SourceFunction来自定义Source,然后通过StreamExecutionEnvironment.addSource(sourceFunction)添加进来。比如读取Kafka数据的Source:
addSource(new FlinkKafkaConsumer08<>);
我们可以实现以下三个接口来自定义Source:
- SourceFunction:创建非并行数据源。
- ParallelSourceFunction:创建并行数据源。
- RichParallelSourceFunction:创建并行数据源。
数据转换(Transformation)
数据处理的核心就是对数据进行各种转化操作,在Flink上就是通过转换将一个或多个DataStream转换成新的DataStream。
为了更好的理解transformation函数,下面给出匿名类的方式来实现各个函数。
所有转换函数都是依赖以下基础:
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream dataStream = env.readTextFile("/opt/yjz/flink/flink-1.7.2/README.txt");
基础转换操作
Map
接受一个元素,输出一个元素。MapFunction
dataStream.map(new MapFunction() {
@Override
public String map(String line) throws Exception {
return line.toUpperCase();
}
});
flatMap
输入一个元素,输出0个、1个或多个元素。FlatMapFunction
dataStream.flatMap(new FlatMapFunction() {
@Override
public void flatMap(String line, Collector collector) throws Exception {
for(String word : line.split(" "))
collector.collect(word);
}
});
转换前后数据类型:DataStream->DataStream。
filter
过滤指定元素数据,如果返回true则该元素继续向下传递,如果为false则将该元素过滤掉。FilterFunction
dataStream.filter(new FilterFunction() {
@Override
public boolean filter(String line) throws Exception {
if(line.contains("flink"))
return true;
else
return false;
}
});
转换前后数据类型:DataStream->DataStream。
keyBy
逻辑上将数据流元素进行分区,具有相同key的记录将被划分到同一分区。指定Key的方式有多种,这个我们在之前说过了。返回类型KeyedStream
KeyedStream keyedStream = dataStream.keyBy(0);
以下情况的元素不能作为key使用:
- POJO类型,但没有重写hashCode(),而是依赖Object.hashCode()。
- 该元素是数组类型。
keyBy内部使用散列来实现的。
转换前后数据类型:DataStream->KeyedStream。
reduce
对指定的“虚拟”key相同的记录进行滚动合并,也就是当前元素与最后一次的reduce结果进行reduce操作。ReduceFunction
keyedStream.reduce(new ReduceFunction() {
@Override
public String reduce(String value1, String value2) throws Exception {
return value1 + value2;
}
});
转换前后数据类型:KeyedStream->DataStream。
Fold(Deprecated)
Fold功能和Reduce类似,但是Fold提供了初始值,从初始值开始滚动对相同的key记录进行滚动合并。FoldFunction
keyedStream.fold(0, new FoldFunction() {
@Override
public Integer fold(Integer accumulator, String value) throws Exception {
return accumulator + value.split(" ").length;
}
});
该方法已经标记为废弃!
转换前后数据类型:KeyedStream->DataStream。
Aggregations
滚动聚合具有相同key的数据流元素,我们可以指定需要聚合的字段(field)。DataStream
//对KeyedStream中元素的第一个Filed求和
DataStream dataStream1 = keyedStream.sum(0);
//对KeyedStream中元素的“count”字段求和
keyedStream.sum("count");
//获取keyedStream中第一个字段的最小值
keyedStream.min(0);
//获取keyedStream中count字段的最小值的元素
keyedStream.minBy("count");
keyedStream.max("count");
keyedStream.maxBy(0);
min和minBy的区别是:min返回指定字段的最小值,而minBy返回最小值所在的元素。
转换前后数据类型:KeyedStream->DataStream。
window
对已经分区的KeyedStream上定义窗口,Window会根据某些规则(比如在最后5s到达的数据)对虚拟“key”相同的记录进行分组。WindowedStream
WindowedStream windowedStream = keyedStream.window(TumblingEventTimeWindows.of(Time.seconds(5)));
转换前后的数据类型:KeyedStream->WindowedStream
关于Window之后会拿出来专门一篇文章来说。
windowAll
我们也可以在常规DataStream上使用窗口,Window根据某些条件(比如最后5s到达的数据)对所有流事件进行分组。AllWindowedStream
AllWindowedStream allWindowedStream = dataStream.windowAll(TumblingEventTimeWindows.of(Time.seconds(5)));
注意:该方法在许多时候并不是并行执行的,所有记录都会收集到一个task中
转换前后的数据类型:DataStream->AllWindowedStream
Window Apply
将整个窗口应用在指定函数上,可以对WindowedStream和AllWindowedStream使用。WindowFunction
windowedStream.apply(new WindowFunction() {
@Override
public void apply(Tuple tuple, TimeWindow window, Iterable input, Collector out) throws Exception {
int sumCount = 0;
for(String line : input){
sumCount += line.split(" ").length;
}
out.collect(String.valueOf(sumCount));
}
});
AllWindowedStream使用与WindowedStream类似。
转换前后的数据类型:WindowedStream->DataStream或AllWindowedStream->DataStream
Window Reduce/Fold/Aggregation/
对于WindowedStream数据流我们同样也可以应用Reduce、Fold、Aggregation函数。
windowedStream.reduce(new ReduceFunction() {
@Override
public String reduce(String value1, String value2) throws Exception {
return value1 + value2;
}
});
windowedStream.fold(0, new FoldFunction() {
@Override
public Integer fold(Integer accumulator, String value) throws Exception {
return accumulator + value.split(" ").length;
}
});
windowedStream.sum(0);
windowedStream.max("count");
转换前后的数据类型:WindowedStream->DataStream
Union
联合(Union)两个或多个DataStream,所有DataStream中的元素都会组合成一个新的DataStream。如果联合自身,则每个元素出现两次在新的DataStream。
dataStream.union(dataStream1);
转换前后的数据类型:DataStream*->DataStream
Window Join
在指定key的公共窗口上连接两个数据流。JoinFunction
dataStream
.join(dataStream1)
.where(new MyKeySelector()).equalTo(new MyKeySelector())
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.apply(new JoinFunction() {
@Override
public String join(String first, String second) throws Exception {
return first + second;
}
});
转换前后的数据类型:DataStream,DataStream->DataStream
Interval Join
对指定的时间间隔内使用公共key来连接两个KeyedStream。ProcessJoinFunction
keyedStream
.intervalJoin(keyedStream)
.between(Time.milliseconds(-2),Time.milliseconds(2))//间隔时间
.lowerBoundExclusive()//并不包含下限时间
.upperBoundExclusive()
.process(new ProcessJoinFunction() {
@Override
public void processElement(String left, String right, Context ctx, Collector out) throws Exception {
//...
}
});
Window CoGroup
对两个指定的key的DataStream在公共窗口上执行CoGroup,和Join功能类似,但是更加灵活。CoGroupFunction
dataStream
.coGroup(dataStream1)
.where(new MyKeySelector()).equalTo(new MyKeySelector())
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.apply(new CoGroupFunction() {
@Override
public void coGroup(Iterable first, Iterable second, Collector out) throws Exception {
}
});
转换前后的数据类型:DataStream,DataStream->DataStream
Connect
连接(connect)两个流,并且保留其类型。两个数据流之间可以共享状态。ConnectedStreams
ConnectedStreams connectedStreams = dataStream.connect(dataStream);
转换前后的数据类型:DataStream,DataStream->ConnectedDataStreams
CoFlatMap/CoMap
可以对连接流执行类似map和flatMap操作。
connectedStreams.map(new CoMapFunction() {
@Override
public String map1(String value) throws Exception {
return value.toUpperCase();
}
@Override
public String map2(String value) throws Exception {
return value.toLowerCase();
}
});
转换前后的数据类型:ConnectedDataStreams->DataStream
Split(Deprecated)
我们可以根据某些规则将数据流切分成两个或多个数据流。
dataStream.split(new OutputSelector() {
@Override
public Iterable select(String value) {
List outList = new ArrayList<>();
if(value.contains("flink"))
outList.add("flink");
else
outList.add("other");
return outList;
}
});
该方法底层引用以被标记为废弃!
转换前后的数据类型:DataStream->SplitStream
Select
我们可以对SplitStream分开的流进行选择,可以将其转换成一个或多个DataStream。
splitStream.select("flink");
splitStream.select("other");
Extract Timestamps(Deprecated)
从记录中提取时间戳,以便使用事件时间语义窗口。之后会专门来看Flink的Event Time。
dataStream.assignTimestamps(new TimestampExtractor() {
@Override
public long extractTimestamp(String element, long currentTimestamp) {
return 0;
}
@Override
public long extractWatermark(String element, long currentTimestamp) {
return 0;
}
@Override
public long getCurrentWatermark() {
return 0;
}
});
该方法以被标记为废弃!
转换前后的数据类型:DataStream->DataStream
Iterate
可以使用iterate方法来获取IterativeStream。
IterativeStream iterativeStream = dataStream.iterate();
转换前后的数据类型:DataStream->IterativeStream
Project
对元组类型的DataStream可以使用Project选取子元组。
DataStream> dataStream2 = dataStream.project(0,2);
转换前后的数据类型:DataStream->DataStream
自定义分区(partitionCustom)
使用用户自定义的分区函数对指定key进行分区,partitionCustom只支持单分区。
dataStream.partitionCustom(new Partitioner() {
@Override
public int partition(String key, int numPartitions) {
return key.hashCode() % numPartitions;
}
},1);
转换前后的数据类型:DataStream->DataStream
随机分区(shuffle)
均匀随机将元素进行分区。
dataStream.shuffle();
转换前后的数据类型:DataStream->DataStream
rebalance
以轮询的方式为每个分区均衡分配元素,对于优化数据倾斜该方法非常有效。
dataStream.rebalance();
转换前后的数据类型:DataStream->DataStream
broadcast
使用broadcast可以向每个分区广播元素。
dataStream.broadcast();
转换前后的数据类型:DataStream->DataStream
rescale
根据上下游task数进行分区。
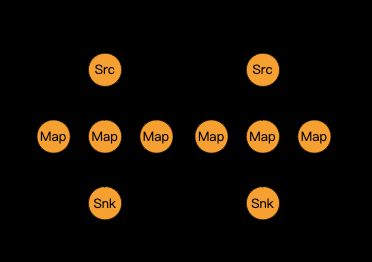
dataStream.rescale();
转换前后的数据类型:DataStream->DataStream
结果数据接收器(Data sink)
数据经过Flink处理之后,最终结果会写到file、socket、外部系统或者直接打印出来。数据接收器定义在DataStream类下,我们通过addSink()可以来添加一个接收器。同Source,Flink也提供了一些预定义的Data Sink让我们直接使用。
写入文本文件
DataStream提供了两个writeAsText重载方法,写入格式会调用写入对象的toString()方法。
- writeAsText(String path):将DataStream数据写入到指定文件。
- writeAsText(String path,WriteMode writeMode):将DataStream数据写入到指定文件,可以通过writeMode来指定如果文件已经存在应该采用什么方式,可以指定OVERWRITE或NO_OVERWRITE。
写入CSV文件
DataStream提供了三个写入csv文件的重载方法,对于DataStream中的每个Filed,都会调用其对象的toString()方法作为写入格式。writeAsCsv只能用于元组(Tuple)的DataStream。
writeAsCsv(String path,WriteMode writeMode,String rowDelimiter,String fieldDelimiter)
| 参数 | 说明 | 实例 |
|---|---|---|
| path | 写入文件路径 | |
| writeMode | 如果写入文件已经存在,采用什么方式处理 | WriteMode.NO_OVERWRITE 或WriteMode.OVERWRITE |
| rowDelimiter | 定义行分隔符 | |
| fieldDelimiter | 定义列分隔符 |
DataStream提供了两个简易重载方法:
- writeAsCsv(String path):使用"\n"作为行分隔符,使用","作为列分隔符。
- writeAsCsv(String path,WriteMode writeMode):使用"\n"作为行分隔符,使用","作为列分隔符。
写入Socket
Flink提供了将DataStream作为字节数组写入Socket的方法,通过SerializationSchema来指定输出格式。
writeToSocket(String hostName,int port,SerializationSchema schema)
指定输出格式
DataStream提供了自定义文件输出的类和方法,我们能够自定义对象到字节的转换。
writeUsingOutputFormat(OutputFormat format)
结果打印
DataStream提供了print和printToErr打印标准输出/标准错误流。DataStream中的每个元素都会调用其toString()方法作为输出格式,我们也可以指定一个前缀字符来区分不同的输出。
- print():标准输出
- print(String sinkIdentifier):指定输出前缀
- printToErr():标准错误输出
- printToErr(String sinkIdentifier):指定输出前缀
对于并行度大于1的输出,输出结果也将输出任务的标识符作为前缀。
自定义输出器
我们一般会自定义输出器,通过实现SinkFunction接口,然后通过DataStream.addSink(sinkFunction)来指定数据接收器。
addSink(SinkFunction sinkFunction)
注意:对于DataStream中的writeXxx()方法一般都是用于测试使用,因为他们并没有参与chaeckpoint,所以它们只有"at-last-once"也就是至少处理一次语义。
如果想要可靠输出,想要使用"exactly-once"语义准确将结果写入到文件系统中,我们需要使用flink-connector-filesystem。此外,我们也可以通过addSink()自定义输出器来使用Flink的checkpoint来完成"exactl-oncey"语义。