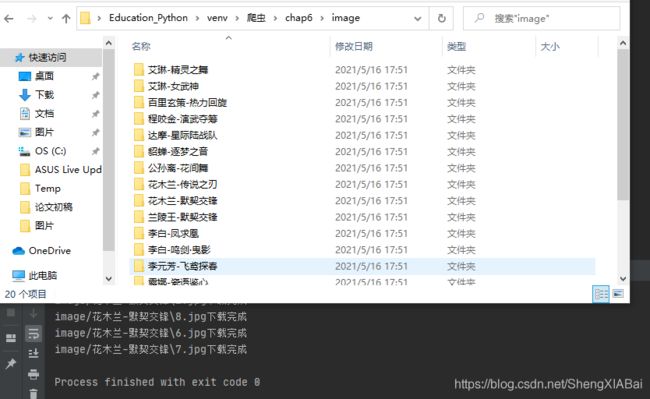
Python学习 Day55 多线程下载壁纸 04
多线程下载王者荣耀高清壁纸
网址:https://pvp.qq.com/web201605/wallpaper.shtml
一、分析数据URL
1.判读数据是在服务器端继承好再发回浏览器端显示的还是通过Ajax请求发送过来的
- 方式一:点击下一页,观察地址栏是否发生变化,若无变化则是Ajax请求
- 方式二:
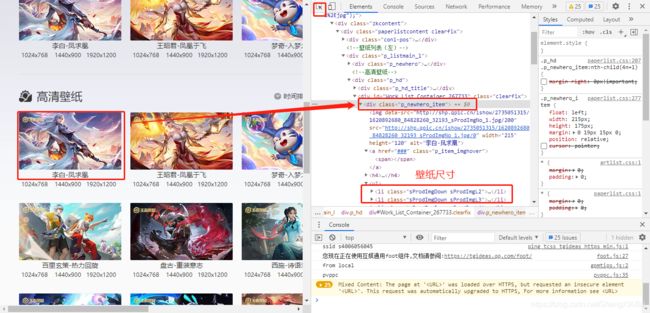
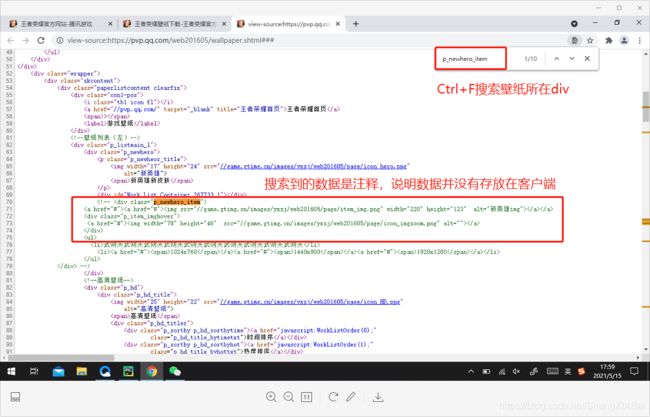
2.寻找真实数据源
复制URL到网页中
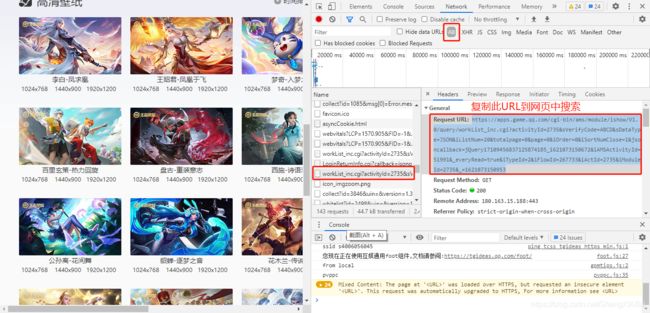
得到的数据
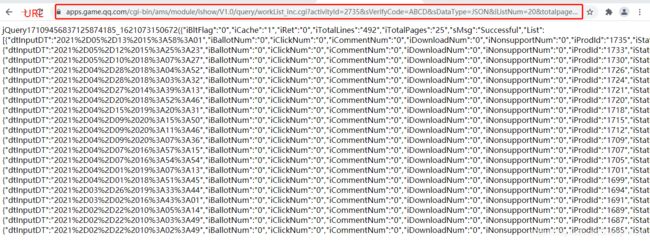
将其复制到JSON在线解析器
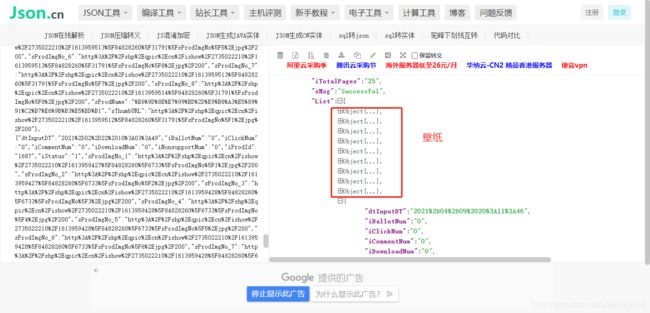
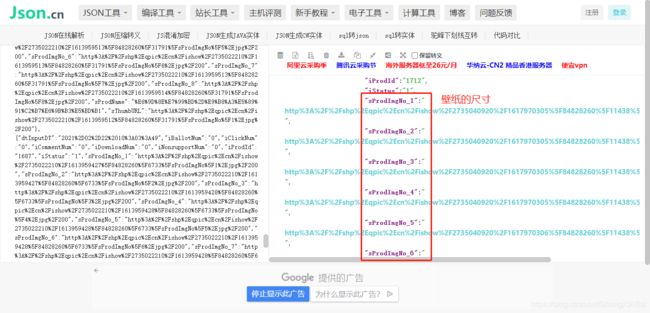
打开图片地址到网页中搜索没有数据
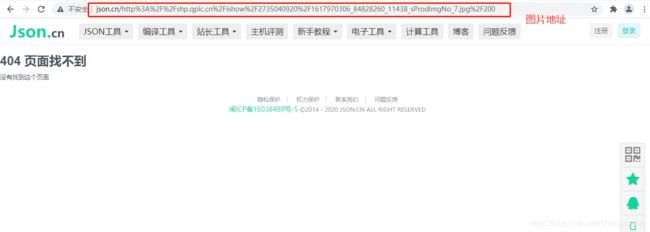
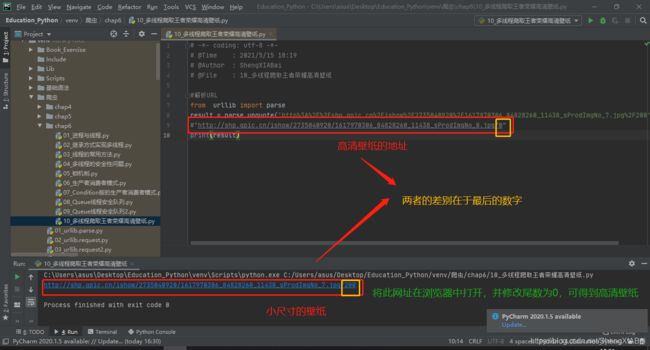
用pycharm代码对图片网址进行解析
#解析URL
from urllib import parse
result = parse.unquote('http%3A%2F%2Fshp.qpic.cn%2Fishow%2F2735040920%2F1617970306_84828260_11438_sProdImgNo_7.jpg%2F200')
print(result)
得到一个可点击的链接
http://shp.qpic.cn/ishow/2735040920/1617970306_84828260_11438_sProdImgNo_7.jpg/200
Process finished with exit code 0
点击链接得到壁纸(尺寸最小)
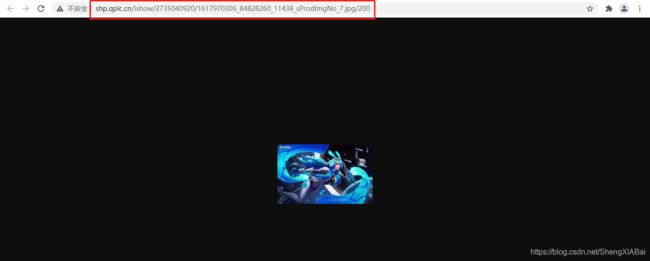
获取尺寸最大的壁纸
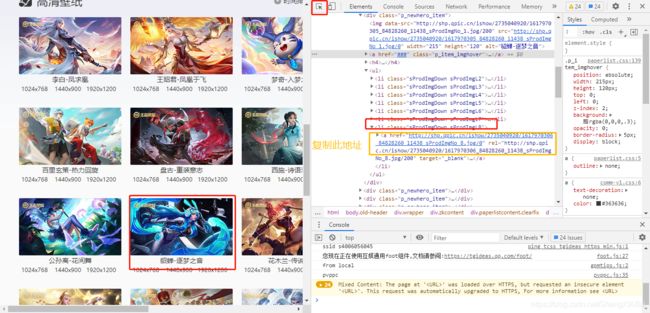
分析壁纸URL的规律
至此URL分析完成
- 高清壁纸的URL:https://pvp.qq.com/web201605/wallpaper.shtml
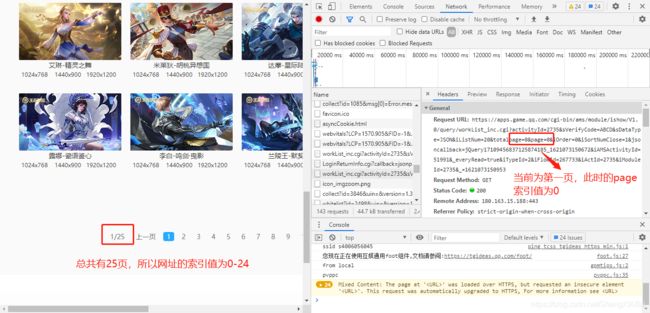
- 含有数据的URL:https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=0&iOrder=0&iSortNumClose=1&jsoncallback=jQuery17109456837125874185_1621073150672&iAMSActivityId=51991&everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&=1621073150953
- 页码范围:一共25页,为0到24
二、爬取第一页数据
- 添加请求头参数headers和referer应对反爬
- urllib下的parse解析URL与解码中文编码
import requests
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36',
'referer':'https://pvp.qq.com/'
}
def send_requests():
url = 'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=0&iOrder=0&iSortNumClose=1&jsoncallback=jQuery171006071737506646002_1621078799273&iAMSActivityId=51991&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1621078799790'
resp = requests.get(url,headers=headers)
print(resp.text)
def start():
send_requests()
if __name__ == '__main__':
start()
结果是不符合JSON数据格式的对象

去掉数据URL中的jsoncallback参数

得到符合JSON格式规范的数据
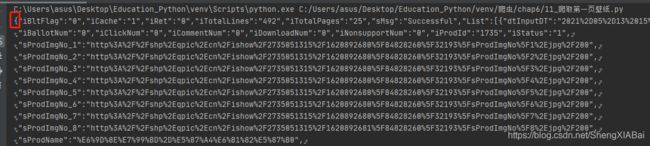
解析json数据


import requests
from urllib import parse
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36',
'referer':'https://pvp.qq.com/'
}
def exact_utl(data):
'''提前每个字典当中的八张壁纸'''
image_url_lst = [] #存储链接的列表
for i in range(1,9): #注意索引是从1开始的
# 解析获取到的URL,并将地址尾数200替换成0
image_url = parse.unquote(data['sProdImgNo_{}'.format(i)]).replace('200','0')
image_url_lst.append(image_url)
return image_url_lst #返回图片的URL
def send_requests():
url = 'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=0&iOrder=0&iSortNumClose=1&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1621078799790'
resp = requests.get(url,headers=headers)
#print(resp.text)
return resp.json()
def parse_json(json_data):
'''解析json数据'''
d = {
} #用于存放壁纸名和壁纸URL的字典
data_list = json_data['List'] #获得一个列表
for data in data_list:
image_url_lst = exact_utl(data)
sProdName = parse.unquote(data['sProdName']) #获取壁纸名称并解析
d[sProdName] = image_url_lst
for item in d:
print(item,d[item])
def start():
json_data = send_requests() #返回数据是一个json对象
parse_json(json_data)
if __name__ == '__main__':
start()

三、存储壁纸
- 路径的拼接
- os.mkdir()创建文件夹
- requests.urlretrieve(url,path)从URL处下载并存储到path中
import requests
from urllib import parse
import os
from urllib import request
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36',
'referer':'https://pvp.qq.com/'
}
def exact_utl(data):
'''提取每个字典当中的八张壁纸'''
image_url_lst = [] #存储链接的列表
for i in range(1,9): #注意索引是从1开始的
# 解析获取到的URL,并将地址尾数200替换成0
image_url = parse.unquote(data['sProdImgNo_{}'.format(i)]).replace('200','0')
image_url_lst.append(image_url)
return image_url_lst #返回图片的URL
def send_requests():
url = 'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page=0&iOrder=0&iSortNumClose=1&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1621078799790'
resp = requests.get(url,headers=headers)
#print(resp.text)
return resp.json()
def parse_json(json_data):
'''解析json数据'''
d = {
} #用于存放壁纸名和壁纸URL的字典
data_list = json_data['List'] #获得一个列表
for data in data_list:
image_url_lst = exact_utl(data)
sProdName = parse.unquote(data['sProdName']) #获取壁纸名称并解析
d[sProdName] = image_url_lst
'''for item in d:
print(item,d[item])'''
save_jpg(d)
def save_jpg(d):
'''保存图片'''
for key in d:
# 拼接路径 image/李白-凤求凰
'''
dirpath = os.path.join('image',key.strip(' ') 去掉空格
os.mkdir(dirpath)
'''
dirpath = 'image/'+key
if not os.path.exists(dirpath):
# 创建文件夹
os.mkdir(dirpath)
# 下载图片并进行保存
for index,image_url in enumerate(d[key]):
#request.urlretrieve()方法:打开图片的URL并下载到文件中
request.urlretrieve(image_url,os.path.join(dirpath,'{}.jpg').format(index+1))
print('{}下载完毕'.format(d[key][index]))
def start():
json_data = send_requests() #返回数据是一个json对象
parse_json(json_data)
if __name__ == '__main__':
start()
第一页壁纸下载完毕
四、多线程下载壁纸
生产者线程:生产图片路径
- page_queue
- page_queue.get()
- image_url_queue
- image_url_queue.put()
消费者线程:下载图片并进行存储
- image_url_queue
- image_url_queue.get()
获取每一页的URL,修改原URL中的page=0为page={i}
![]()
import requests
from urllib import parse
from queue import Queue
import threading
import os
from urllib import request
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.212 Safari/537.36',
'referer': 'https://pvp.qq.com/'
}
def exact_utl(data):
'''提取每个字典当中的八张壁纸'''
image_url_lst = [] # 存储链接的列表
for i in range(1, 9): # 注意索引是从1开始的
# 解析获取到的URL,并将地址尾数200替换成0
image_url = parse.unquote(data['sProdImgNo_{}'.format(i)]).replace('200', '0')
image_url_lst.append(image_url)
return image_url_lst # 返回图片的URL
# 生产者线程
class Producer(threading.Thread):
def __init__(self, page_queue, image_url_queue):
super().__init__()
self.page_queue = page_queue
self.image_url_queue = image_url_queue
def run(self):
# 如果队列不为空
while not self.page_queue.empty():
# 则从队列当中取出URL
page_url = self.page_queue.get()
# 取出URL后发送请求
resp = requests.get(page_url, headers=headers)
# 将返回的resp对象转换成json数据格式
json_data = resp.json()
# 数据的提取
d = {
} # 用于存放壁纸名和壁纸URL的字典
data_list = json_data['List'] # 获得一个列表
for data in data_list:
image_url_lst = exact_utl(data) # 图片URL的列表
sProdName = parse.unquote(data['sProdName']) # 获取壁纸名称并解析
d[sProdName] = image_url_lst
# 创建文件夹并存放数据
for key in d:
'''
dirpath = os.path.join('image',key.strip(' ').replace('·','').replace('1:1','') 去掉空格,“·”,“1:1”等中文字符
os.mkdir(dirpath)
'''
dirpath = 'image/' + key
if not os.path.exists(dirpath):
# 创建文件夹
os.mkdir(dirpath)
# 下载图片并进行保存
for index, image_url in enumerate(d[key]):
# 生产图片的URL
self.image_url_queue.put(
{
'image_path': os.path.join(dirpath, f'{index + 1}.jpg'), 'image_url': image_url})
# 消费者线程
class Customer(threading.Thread):
def __init__(self, image_url_queue):
super().__init__()
self.image_url_queue = image_url_queue
def run(self):
while True:
try:
# 取出生产者线程生产的图片URL
# timeout参数,若程序超过20s还未响应则停止
image_obj = self.image_url_queue.get(timeout=20)
request.urlretrieve(image_obj['image_url'], image_obj['image_path'])
print(f'{image_obj["image_path"]}下载完成')
except:
break
# 启动线程
def start():
# 存储每一页URL的队列,共25页
page_queue = Queue(25)
# 存储图片的路径
image_url_queue = Queue(1000)
for i in range(0, 1):
page_url = f'https://apps.game.qq.com/cgi-bin/ams/module/ishow/V1.0/query/workList_inc.cgi?activityId=2735&sVerifyCode=ABCD&sDataType=JSON&iListNum=20&totalpage=0&page={i}&iOrder=0&iSortNumClose=1&_everyRead=true&iTypeId=2&iFlowId=267733&iActId=2735&iModuleId=2735&_=1621078799790'
# print(page_url)
page_queue.put(page_url)
# 创建生产者线程对象
for i in range(5):
t = Producer(page_queue, image_url_queue)
t.start()
# 创建消费者线程对象
for i in range(10):
t = Customer(image_url_queue)
t.start()
if __name__ == '__main__':
start()