python common模块_python-常用模块
re模块
re模块的常用用法
import re
# 字符串
# 匹配
# findall*****# ret= re.findall('\d+','19874ashfk01248')
# print(ret) # 参数 返回值类型:列表 返回值个数:1返回值内容:所有匹配上的项
# ret1= re.findall('\s+','19874ashfk01248')
# print(ret1)
# search*****# ret2= re.search('\d+','@$19874ashfk01248')
# print(ret2) # 返回值类型: 正则匹配结果的对象 返回值个数:1如果匹配上了就返回对象
#ifret2:print(ret2.group()) # 返回的对象通过group来获取匹配到的第一个结果
# ret3= re.search('\s+','19874ashfk01248')
# print(ret3) # 返回值类型: None 如果没有匹配上就是None
# match**# ret4= re.match('\d+','19874ashfk01248')
# print(ret4)
# ret5= re.match('\d+','%^19874ashfk01248')
# print(ret5)
# 替换 replace
# sub***# print('replace789,24utdeedeeeeshf'.replace('e','H',3))
# ret= re.sub('\d+','H','replace789nbc2xcz392zx')
# print(ret)
# ret= re.sub('\d+','H','replace789nbc2xcz392zx,48495',1)
# print(ret)
# subn***# ret= re.subn('\d+','H','replace789nbc2xcz392zx')
# print(ret)
# 切割
# split***# print('alex|83|'.split('|'))
# ret= re.split('\d+','alex83egon20taibai40')
# print(ret)
# 进阶方法-爬虫\自动化开发
# compile*****时间效率
# re.findall('-0\.\d+|-[1-9]+(\.\d+)?','alex83egon20taibai40') --> python解释器能理解的代码 -->执行代码
# ret= re.compile('-0\.\d+|-[1-9]\d+(\.\d+)?')
# res= ret.search('alex83egon-20taibai-40')
# print(res.group())
# 节省时间 : 只有在多次使用某一个相同的正则表达式的时候,这个compile才会帮助我们提高程序的效率
# finditer*****空间效率
# print(re.findall('\d','sjkhkdy982ufejwsh02yu93jfpwcmc'))
# ret= re.finditer('\d','sjkhkdy982ufejwsh02yu93jfpwcmc')
#for r inret:
# print(r.group())
random模块
random模块常用方法
import random
# 随机 : 在某个范围内取到每一个值的概率是相同的
# 随机小数
# print(random.random()) #0-1之内的随机小数
# print(random.uniform(1,5)) # 任意范围之内的随机小数
# 随机整数*****# print(random.randint(1,2)) # [1,2] 包含2在内的范围内随机取整数
# print(random.randrange(1,2)) # [1,2)不包含2在内的范围内随机取整数
# print(random.randrange(1,10,2)) # [1,10)不包含10在内的范围内随机取奇数
# 随机抽取
# 随机抽取一个值
# lst= [1,2,3,'aaa',('wahaha','qqxing')]
# ret=random.choice(l)
# print(ret)
# 随机抽取多个值
# ret= random.sample(lst,2)
# print(ret)
# 打乱顺序 在原列表的基础上做乱序
# lst= [1,2,3,'aaa',('wahaha','qqxing')]
# random.shuffle(lst)
# print(lst)
# 抽奖 \ 彩票 \发红包 \验证码 \洗牌


# 生成随机验证码
# 4位数字的
import random
#0-9# 基础版本
# code= ''#for i in range(4):
# num= random.randint(0,9)
# code+=str(num)
# print(code)
# 函数版本
# def rand_code(n=4):
# code= ''#for i inrange(n):
# num= random.randint(0,9)
# code+=str(num)
#returncode
#
# print(rand_code())
# print(rand_code(6))
# 6位 数字+字母
# print(chr(97))
# print(chr(122))
# import random
# 基础版
# code= ''#for i in range(6):
# rand_num= str(random.randint(0,9))
# rand_alph= chr(random.randint(97,122))
# rand_alph_upper= chr(random.randint(65,90))
# atom_code=random.choice([rand_num,rand_alph,rand_alph_upper])
# code+=atom_code
# print(code)
# 函数版
# def rand_code(n=6):
# code= ''#for i inrange(n):
# rand_num= str(random.randint(0,9))
# rand_alph= chr(random.randint(97,122))
# rand_alph_upper= chr(random.randint(65,90))
# atom_code=random.choice([rand_num,rand_alph,rand_alph_upper])
# code+=atom_code
#returncode
#
# ret=rand_code()
# print(ret)
# 数字/数字+字母
# def rand_code(n=6 , alph_flag =True):
# code= ''#for i inrange(n):
# rand_num= str(random.randint(0,9))
#ifalph_flag:
# rand_alph= chr(random.randint(97,122))
# rand_alph_upper= chr(random.randint(65,90))
# rand_num=random.choice([rand_num,rand_alph,rand_alph_upper])
# code+=rand_num
#returncode
#
# ret= rand_code(n = 4)
# print(ret)
#*****永远不要创建一个和你知道的模块同名的文件名
#函数 : 发红包 : 200块钱 , 10个
生成随机验证码
time模块
表示时间的三种方式
时间戳时间,格林威治时间,float数据类型 给机器用的
结构化时间,时间对象 上下两种格式的中间状态
格式化时间,字符串时间,str数据类型 给人看的
%y 两位数的年份表示(00-99)%Y 四位数的年份表示(000-9999)%m 月份(01-12)%d 月内中的一天(0-31)%H 24小时制小时数(0-23)%I 12小时制小时数(01-12)%M 分钟数(00=59)%S 秒(00-59)%a 本地简化星期名称%A 本地完整星期名称%b 本地简化的月份名称%B 本地完整的月份名称%c 本地相应的日期表示和时间表示%j 年内的一天(001-366)%p 本地A.M.或P.M.的等价符%U 一年中的星期数(00-53)星期天为星期的开始%w 星期(0-6),星期天为星期的开始%W 一年中的星期数(00-53)星期一为星期的开始%x 本地相应的日期表示%X 本地相应的时间表示%Z 当前时区的名称%% %号本身
python中时间日期格式化符号:
python中时间日期格式化符号
python中表示时间的几种格式:
#导入时间模块>>>import time
#时间戳>>>time.time()1500875844.800804#时间字符串>>>time.strftime("%Y-%m-%d %X")'2017-07-24 13:54:37'
>>>time.strftime("%Y-%m-%d %H-%M-%S")'2017-07-24 13-55-04'#时间元组:localtime将一个时间戳转换为当前时区的struct_time
time.localtime()
time.struct_time(tm_year=2017, tm_mon=7, tm_mday=24,
tm_hour=13, tm_min=59, tm_sec=37,
tm_wday=0, tm_yday=205, tm_isdst=0)
几种格式之间的转换
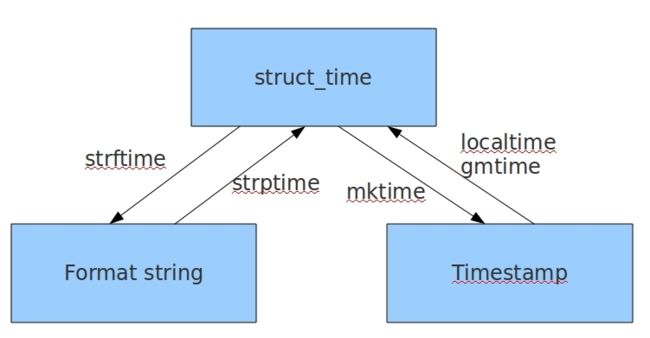
#几种格式之间的转换
# print(time.time())
# print(time.localtime(1500000000))
# print(time.localtime(2000000000))
# time_obj= time.localtime(3000000000)
# format_time= time.strftime('%y-%m-%d %H:%M:%S',time_obj)
# print(format_time)
#2008-8-8# struct_time= time.strptime('2008-8-8','%Y-%m-%d')
# print(struct_time)
# print(time.mktime(struct_time))
# 计算本月一号的时间戳时间
# 结构化时间
# struct_time=time.localtime()
# struct_time= time.strptime('%s-%s-1'%(struct_time.tm_year,struct_time.tm_mon),'%Y-%m-%d')
# print(time.mktime(struct_time))
# 格式化时间
# ret= time.strftime('%Y-%m-1')
# struct_time= time.strptime(ret,'%Y-%m-%d')
# print(time.mktime(struct_time))
datetime模块
datetime.now() # 获取当前datetime
datetime.utcnow() # 获取当前格林威治时间
fromdatetime import datetime
#获取当前本地时间
a=datetime.now()
print('当前日期:',a)
#获取当前世界时间
b=datetime.utcnow()
print('世界时间:',b)
2.datetime(2017, 5, 23, 12, 20) # 用指定日期时间创建datetime
fromdatetime import datetime
#用指定日期创建
c=datetime(2017, 5, 23, 12, 20)
print('指定日期:',c)
3.将以下字符串转换成datetime类型:
'2017/9/30'
'2017年9月30日星期六'
'2017年9月30日星期六8时42分24秒'
'9/30/2017'
'9/30/2017 8:42:50 '
fromdatetime import datetime
d=datetime.strptime('2017/9/30','%Y/%m/%d')
print(d)
e=datetime.strptime('2017年9月30日星期六','%Y年%m月%d日星期六')
print(e)
f=datetime.strptime('2017年9月30日星期六8时42分24秒','%Y年%m月%d日星期六%H时%M分%S秒')
print(f)
g=datetime.strptime('9/30/2017','%m/%d/%Y')
print(g)
h=datetime.strptime('9/30/2017 8:42:50','%m/%d/%Y %H:%M:%S')
print(h)
时间字符串格式化
4.将以下datetime类型转换成字符串:
2017年9月28日星期4,10时3分43秒
Saturday, September 30, 2017
9/30/2017 9:22:17 AM
September 30, 2017
fromdatetime import datetime
i=datetime(2017,9,28,10,3,43)
print(i.strftime('%Y年%m月%d日%A,%H时%M分%S秒'))
j=datetime(2017,9,30,10,3,43)
print(j.strftime('%A,%B %d,%Y'))
k=datetime(2017,9,30,9,22,17)
print(k.strftime('%m/%d/%Y %I:%M:%S%p'))
l=datetime(2017,9,30)
print(l.strftime('%B %d,%Y'))
时间字符串格式化
5.用系统时间输出以下字符串:
今天是2017年9月30日
今天是这周的第?天
今天是今年的第?天
今周是今年的第?周
今天是当月的第?天
fromdatetime import datetime
#获取当前系统时间
m=datetime.now()
print(m.strftime('今天是%Y年%m月%d日'))
print(m.strftime('今天是这周的第%w天'))
print(m.strftime('今天是今年的第%j天'))
print(m.strftime('今周是今年的第%W周'))
print(m.strftime('今天是当月的第%d天'))
sys模块
sys模块是与python解释器交互的一个接口
sys.modules
sys.argv 命令行参数List,第一个元素是程序本身路径
sys.exit(n) 退出程序,正常退出时exit(0),错误退出sys.exit(1)
sys.version 获取Python解释程序的版本信息
sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform 返回操作系统平台名称
OS模块
os模块是与操作系统交互的一个接口
os.makedirs('dirname1/dirname2') 可生成多层递归目录
os.removedirs('dirname1') 若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir('dirname') 生成单级目录;相当于shell中mkdir dirname
os.rmdir('dirname') 删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir('dirname') 列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
os.remove() 删除一个文件
os.rename("oldname","newname") 重命名文件/目录
os.stat('path/filename') 获取文件/目录信息
os.system("bash command") 运行shell命令,直接显示
os.popen("bash command).read() 运行shell命令,获取执行结果
os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径
os.chdir("dirname") 改变当前脚本工作目录;相当于shell下cd
os.path
os.path.abspath(path) 返回path规范化的绝对路径os.path.split(path) 将path分割成目录和文件名二元组返回
os.path.dirname(path) 返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path) 返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素
os.path.exists(path) 如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path) 如果path是绝对路径,返回True
os.path.isfile(path) 如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path) 如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, ...]]) 将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path) 返回path所指向的文件或者目录的最后访问时间
os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path) 返回path的大小
logging模块
日志格式的规范
操作的简化
日志的分级管理
函数式简单配置
import logging
logging.debug('debug message') # 调式模式
logging.info('info message') # 基础信息
logging.warning('warning message') #警告
logging.error('error message') # 错误
logging.critical('critical message') # 严重错误
默认情况下Python的logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志,这说明默认的日志级别设置为WARNING(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG),默认的日志格式为日志级别:Logger名称:用户输出消息
灵活配置日志级别,日志格式,输出位置:
import logging
file_handler = logging.FileHandler(filename='test.log', mode='a', encoding='utf-8',)
logging.basicConfig(
format='%(asctime)s - %(name)s - %(levelname)s -%(module)s: %(message)s',
datefmt='%Y-%m-%d %H:%M:%S %p',
handlers=[file_handler,],
level=logging.ERROR
)
logging.error('你好')
format='%(asctime)s #时间 %(filename)s #错误的文件 [line:%(lineno)d] # 哪一行的错误%(levelname)s # 什么级别的错误%(message)s', # 错误信息
参数配置
logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有:
filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open(‘test.log’,’w’)),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。
format参数中可能用到的格式化串:%(name)s Logger的名字%(levelno)s 数字形式的日志级别%(levelname)s 文本形式的日志级别%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有%(filename)s 调用日志输出函数的模块的文件名%(module)s 调用日志输出函数的模块名%(funcName)s 调用日志输出函数的函数名%(lineno)d 调用日志输出函数的语句所在的代码行%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒%(thread)d 线程ID。可能没有%(threadName)s 线程名。可能没有%(process)d 进程ID。可能没有%(message)s用户输出的消息
View Code
logger对象配置
# logger对象的形式来操作日志文件
# 创建一个logger对象
# 创建一个文件管理操作符
# 创建一个屏幕管理操作符
# 创建一个日志输出的格式
# 文件管理操作符 绑定一个 格式
# 屏幕管理操作符 绑定一个 格式
# logger对象 绑定 文件管理操作符
# logger对象 绑定 屏幕管理操作符
import logging
# 创建一个logger对象
logger = logging.getLogger()
# 创建一个文件管理操作符
fh = logging.FileHandler('logger.log',encoding='utf-8')
# 创建一个屏幕管理操作符
sh = logging.StreamHandler()
# 创建一个日志输出的格式
format1 = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
# 文件管理操作符 绑定一个 格式
fh.setFormatter(format1)
# 屏幕管理操作符 绑定一个 格式
sh.setFormatter(format1)
logger.setLevel(logging.DEBUG)
# logger对象 绑定 文件管理操作符
# logger.addHandler(fh)
# logger对象 绑定 屏幕管理操作符
logger.addHandler(sh)
logger.debug('debug message') # 调试模式
logger.info('我的信息') # 基础信息
logger.warning('warning message') # 警告
logger.error('error message') # 错误
logger.critical('critical message')# 严重错误
hashlib模块
Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等。
什么是摘要算法呢?摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)。
我们以常见的摘要算法MD5为例,计算出一个字符串的MD5值:
import hashlib
md5 = hashlib.md5()
md5.update('how to use md5 in python hashlib?')
print md5.hexdigest()
计算结果如下:
d26a53750bc40b38b65a520292f69306
如果数据量很大,可以分块多次调用update(),最后计算的结果是一样的:
md5 =hashlib.md5()
md5.update('how to use md5 in')
md5.update('python hashlib?')
print md5.hexdigest()
MD5是最常见的摘要算法,速度很快,生成结果是固定的128 bit字节,通常用一个32位的16进制字符串表示。另一种常见的摘要算法是SHA1,调用SHA1和调用MD5完全类似:
import hashlib
sha1 = hashlib.sha1()
sha1.update('how to use sha1 in ')
sha1.update('python hashlib?')
print sha1.hexdigest()
SHA1,通常用一个40位的16进制字符串表示,算法相对复杂 计算速度也慢, 比SHA1更安全的算法是SHA256和SHA512,不过越安全的算法越慢,而且摘要长度更长。
摘要算法应用
1.登录的密文验证
密码不能解密,但可以撞库
# 数据库 -撞库
#111111 -->结果
#666666#123456# alex3714-->aee949757a2e698417463d47acac93df
# s1= '123456'# md5_obj=hashlib.md5()
# md5_obj.update(s1.encode('utf-8'))
# res=md5_obj.hexdigest()
# print(res,len(res),type(res))
View Code
加盐
# 加盐 # wind3714 d3cefe8cdd566977ec41566f1f11abd9
# md5_obj= hashlib.md5('任意的字符串作为盐'.encode('utf-8'))
# md5_obj.update(s1.encode('utf-8'))
# res=md5_obj.hexdigest()
# print(res,len(res),type(res))
# wind登录 alex3714|d3cefe8cdd566977ec41566f1f11abd9
# wind|d3cefe8cdd566977ec41566f1f11abd9
# 张三|d3cefe8cdd566977ec41566f1f11abd8 123456# 鞠莹莹|d3cefe8cdd566977ec41566f1f11abd8 123456
View Code
动态加盐
# 遇到恶意用户 注册500个账号,我们采用动态加盐
# 张三|123456 '任意的字符串作为盐'.encode('utf-8') d3cefe8cdd566977ec41566f1f11abd8
# 李四|111111# eee|alex3714
# 动态加盐
# username= input('username :')
# passwd= input('password :')
# md5obj= hashlib.md5(username.encode('utf-8'))
# md5obj.update(passwd.encode('utf-8'))
# print(md5obj.hexdigest())
# ee838c58e5bb3c9e687065edd0ec454f
View Code
2.文件的一致性校验
# md5_obj =hashlib.md5()
# with open('5.序列化模块_shelve.py','rb') asf:
# md5_obj.update(f.read())
# ret1=md5_obj.hexdigest()
#
# md5_obj=hashlib.md5()
# with open('5.序列化模块_shelve.py.bak','rb') asf:
# md5_obj.update(f.read())
# ret2=md5_obj.hexdigest()
# print(ret1,ret2)
View Code
大文件的一致性校验
# 写成一个函数
# 参数 : 文件1的路径,文件2的路径,默认参数= 1024000# 计算这两个文件的md5值
# 返回它们的一致性结果 T/F1import hashlib2 md5_obj =hashlib.md5()3import os4 filesize = os.path.getsize('filename') #文件大小5 f = open('filename','rb')6 while filesize>0:7 if filesize > 1024:8 content = f.read(1024)9 filesize -= 1024
10 else:11 content =f.read(filesize)12 filesize -=filesize13md5_obj.update(content)14 # for line inf:15 # md5_obj.update(line.encode('utf-8'))16md5_obj.hexdigest()
文件校验(检测文件改变了没)
View Code
序列化模块
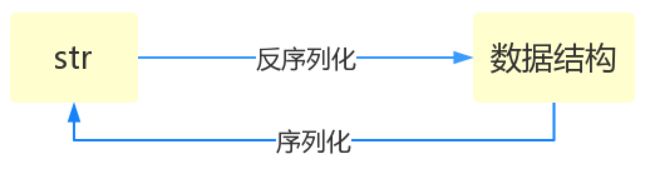
什么叫序列化——将原本的字典、列表等内容转换成一个字符串的过程就叫做序列化。
json
Json模块提供了四个功能:dumps、dump、loads、load
import json
# json格式的限制1,json格式的key必须是字符串数据类型
# json格式中的字符串只能是""# 如果是数字为key,那么dump之后会强行转成字符串数据类型
# dic= {1:2,3:4}
# str_dic=json.dumps(dic)
# print(str_dic)
# new_dic=json.loads(str_dic)
# print(new_dic)
# json是否支持元组,对元组做value的字典会把元组强制转换成列表
# dic= {'abc':(1,2,3)}
# str_dic=json.dumps(dic)
# print(str_dic)
# new_dic=json.loads(str_dic)
# print(new_dic)
# json是否支持元组做key,不支持
# dic= {(1,2,3):'abc'}
# str_dic=json.dumps(dic) # 报错
# 对列表的dump
# lst= ['aaa',123,'bbb',12.456]
# with open('json_demo','w') asf:
# json.dump(lst,f)
# with open('json_demo') asf:
# ret=json.load(f)
# print(ret)
# 能不能多次dump数据到文件里,可以多次dump但是不能load出来了
# dic= {'abc':(1,2,3)}
# lst= ['aaa',123,'bbb',12.456]
# with open('json_demo','w') asf:
# json.dump(lst,f)
# json.dump(dic,f)
# with open('json_demo') asf:
# ret=json.load(f)
# print(ret)
# 想dump多个数据进入文件,用dumps
# dic= {'abc':(1,2,3)}
# lst= ['aaa',123,'bbb',12.456]
# with open('json_demo','w') asf:
# str_lst=json.dumps(lst)
# str_dic=json.dumps(dic)
# f.write(str_lst+'\n')
# f.write(str_dic+'\n')
# with open('json_demo') asf:
#for line inf:
# ret=json.loads(line)
# print(ret)
# 中文格式的 ensure_ascii=False
# dic= {'abc':(1,2,3),'country':'中国'}
# ret= json.dumps(dic,ensure_ascii =False)
# print(ret)
# dic_new=json.loads(ret)
# print(dic_new)
# with open('json_demo','w',encoding='utf-8') asf:
# json.dump(dic,f,ensure_ascii=False)
# json的其他参数,是为了用户看的更方便,但是会相对浪费存储空间
# import json
# data= {'username':['李华','二愣子'],'sex':'male','age':16}
# json_dic2= json.dumps(data,sort_keys=True,indent=4,separators=(',',':'),ensure_ascii=False)
# print(json_dic2)
# set不能被dump/dumps
View Code
pickle
用于序列化的两个模块
json,用于字符串 和 python数据类型间进行转换
pickle,用于python特有的类型 和 python的数据类型间进行转换
pickle模块提供了四个功能:dumps、dump(序列化,存)、loads(反序列化,读)、load (不仅可以序列化字典,列表...可以把python中任意的数据类型序列化)
# pickle
dic= {1:(12,3,4),('a','b'):4}
import pickle
# dump的结果是bytes,dump用的f文件句柄需要以wb的形式打开,load所用的f是'rb'模式
# 支持几乎所有对象的序列化
# 对于对象的序列化需要这个对象对应的类在内存中
# 对于多次dump/load的操作做了良好的处理
# pic_dic=pickle.dumps(dic)
# print(pic_dic) # bytes类型
# new_dic=pickle.loads(pic_dic)
# print(new_dic)
# pickle支持几乎所有对象的
#classStudent:
# def __init__(self,name,age):
# self.name=name
# self.age=age
#
# alex= Student('alex',83)
# ret=pickle.dumps(alex)
# 小花=pickle.loads(ret)
# print(小花.name)
# print(小花.age)
#classStudent:
# def __init__(self,name,age):
# self.name=name
# self.age=age
#
# alex= Student('alex',83)
# with open('pickle_demo','wb') asf:
# pickle.dump(alex,f)
# with open('pickle_demo','rb') asf:
# 旺财=pickle.load(f)
# print(旺财.name)
# 学员选课系统 pickle模块来存储每个学员的对象
# with open('pickle_demo','wb') asf:
# pickle.dump({'k1':'v1'}, f)
# pickle.dump({'k11':'v1'}, f)
# pickle.dump({'k11':'v1'}, f)
# pickle.dump({'k12':[1,2,3]}, f)
# pickle.dump(['k1','v1','l1'], f)
# with open('pickle_demo','rb') asf:
#whileTrue:
#try:
# print(pickle.load(f))
# except EOFError:
#break
pickle
既然pickle如此强大,为什么还要学json呢?
这里我们要说明一下,json是一种所有的语言都可以识别的数据结构。
如果我们将一个字典或者序列化成了一个json存在文件里,那么java代码或者js代码也可以拿来用。
但是如果我们用pickle进行序列化,其他语言就不能读懂这是什么了~
所以,如果你序列化的内容是列表或者字典,我们非常推荐你使用json模块
但如果出于某种原因你不得不序列化其他的数据类型,而未来你还会用python对这个数据进行反序列化的话,那么就可以使用pickle
collections模块
数据类型的扩展模块
在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。
1.namedtuple: 生成可以使用名字来访问元素内容的tuple
2.deque: 双端队列,可以快速的从另外一侧追加和推出对象
3.Counter: 计数器,主要用来计数
4.OrderedDict: 有序字典
5.defaultdict: 带有默认值的字典
什么是队列?
# 先进先出
# import queue
# q=queue.Queue()
# print(q.qsize())
# q.put(1)
# q.put('a')
# q.put((1,2,3))
# q.put(({'k':'v'}))
# print(q.qsize())
# print('q :',q)
# print('get :',q.get())
# print(q.qsize())
deque 双端队列
# fromcollections import deque
# dq=deque()
# dq.append(2)
# dq.append(5)
# dq.appendleft('a')
# dq.appendleft('b')
# print(dq)
# # print(dq.pop())
# # print(dq)
# # print(dq.popleft())
# # print(dq)
# print(dq.remove('a'))
# print(dq.insert(2,'123'))
# print(dq)
在insert remove的时候 deque的平均效率要高于列表
列表根据索引查看某个值的效率要高于deque
append 和pop对于列表的效率是没有影响
Counter计数器
1. 对字符串\列表\元祖\字典进行计数,返回一个字典类型的数据,键是元素,值是元素出现的次数
举例:
from collections import Counter
s = "hello-python-hello-world"
a = Counter(s)
print(a)
# 结果
Counter({'-': 3, 'd': 1, 'e': 2, 'h': 3, 'l': 5, 'n': 1, 'o': 4, 'p': 1, 'r': 1, 't': 1, 'w': 1, 'y': 1})
1
2
3
4
5
6
2. most_common(n) (统计出现最多次数的n个元素)
举例:
print(a.most_common(3))
# 结果
[('l', 5), ('o', 4), ('h', 3)] 出现次数最多的三个元素
1
2
3
3. elements (返回一个Counter计数后的各个元素的迭代器)
举例:
for i in a.elements():
print(i, end="")
# 结果:
hhheellllloooo---pytnwrd
1
2
3
4
4. update (类似集合的update,进行更新)
举例:
a.update("hello123121")
print(a)
# 结果:
Counter({'-': 3, '1': 3, '2': 2, '3': 1, 'd': 1, 'e': 3, 'h': 4, 'l': 7, 'n': 1, 'o': 5, 'p': 1, 'r': 1, 't': 1, 'w': 1, 'y': 1})
1
2
3
5. subtract (类似update,做减法)
s1 = "abcd"
s2 = "cdef"
a1 = Counter(s1)
a2 = Counter(s2)
a1.subtract(a2)
print(a1)
# 结果:
Counter({'a': 1, 'b': 1, 'c': 0, 'd': 0, 'e': -1, 'f': -1