目标检测中算法评价指标FPS和mAp的原理和代码实现
FPS和mAP是目标检测算法的两个重要评估指标, FPS是用来评估目标检测的速度,即每秒内可以处理的图片数量或者处理一张图片所需时间来评估检测速度,时间越短,速度越快。mAP是物体检测器准确率的度量方法,通俗来说就是目标检测准确度, 那他们到底是如何进行计算的呢?
文章目录
一、FPS概念原理
二、计算FPS代码实现
三、mAP概念原理
四、绘制mAP代码实现
一、FPS(每秒传输帧数-Frames Per Second)
FPS就是目标网络每秒可以处理(检测)多少帧(多少张图片),FPS简单来理解就是图像的刷新频率,也就是每秒多少帧,假设目标检测网络处理1帧要0.02s,此时FPS就是1/0.02=50。
二、计算FPS代码实现
目标检测中的目标检测算法去检测视频或者调用电脑摄像头。
实现思路: 利用opencv调用摄像头,读取每一帧传入目标检测网络检测,将检测结果呈现,由于目标检测要求输入的图片格式一般为RGB格式,CV2读取的时候会使用BGR格式,因此在检测的时候要利用cv2.cvtColor进行图片格式转换。
# yolo = YOLO() # 首先定义我们的检测模型类
# 调用摄像头
capture = cv2.VideoCapture(0) #0代表调用电脑的默认摄像头
# # 检测视频
# capture = cv2.VideoCapture("1.mp4") #对视频进行检测,则将0改为视频文件
# 定义起始fps
fps = 0.0
while(True):
# 检测图片的起始时间
t1 = time.time()
# 读取某一帧
ref,frame = capture.read()
# 格式转变,BGRtoRGB
frame = cv2.cvtColor(frame,cv2.COLOR_BGR2RGB) # 利用OpenCV读取出来的图片的格式是BGR的,而目标检测中用到的图片格式是RGB
# 转变成Image
frame = Image.fromarray(np.uint8(frame)) # 平时进行目标检测的库PIL中的Image,因此图片转换成Image进行存储。将读取出来的以数组形式存储的图片转换成图片Image
# 网络进行检测fps计算
# 对传入的图片使用自己的目标检测算法进行检测
frame = np.array(yolo.detect_image(frame))
# RGBtoBGR满足opencv显示格式
frame = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR)
# 将我们检测好了的图片的格式从RGB转换成OpenCV可处理的BGR的格式进行图片的展示
# fps的计算
fps = (fps + (1. / (time.time() - t1))) / 2 #此处的time.time()就是检测完这张图片的结束时间,除以2是为了和之前的fps求一个平均
print("fps= %.2f"%fps)
frame = cv2.putText(frame, "fps= %.2f"%(fps), (0, 40), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 255, 0), 2)
# 检测完的图片的展示
cv2.imshow("video", frame)
c = cv2.waitKey(30) & 0xff
if c == 27:
capture.release()
break
三、mAP概念原理
mAP实际上是对测试集来评估的,主要是计算测试集和测试集的预测结果的准确率,指标是测试集中的真实框和目标是否检测出来,对于预测结果中的预测框和测试集中的真实框的IOU检测大于阈值,就判定这个框框和目标为TP即分类正确的正样本,其他的预测结果(预测框和真实框小于阈值)判定为FP负样本,而测试集中未被检测出来的目标和真实框(就是测试集标记的目标和框框减去预测正确的目标和框框)的就为FN。
简单来说,mAp是用来评估你的测试集中的实际框和目标-你制作的标签,是否预测出来的指标
注意:
mAp中的正样本和负样本和我们为模型进行训练时候制作“负样本”两者是不同的概念,模型训练时制作“负样本”是为了防止模型过拟合,让模型具有更强的鲁棒性,而这里计算mAP所指的“负样本"是指评估算法中的测试集中预测小于阈值的预测结果。
2.mAp的计算
[1]TP、FP、FN概念
-
T是True
-
F是False
-
P是Positive
-
N是Negative
TP: 是指预测框和测试集真实框的IOU大于我们所设定的阈值,即所有预测边界框中分类正确且边界框坐标正确的边界框的数量。
FP: 是指预测框和测试集真实框的IOU小于我们所设定的阈值,即预测的边界框中分类错误或者边界框坐标不达标的预测框的数量,即预测出的所有边界框中除去预测正确的边界框,剩下的边界框的数量就是FP。
FN:是指测试集中所有没有被预测到的目标真实框的数量,即测试集中所有真实的边界框的数量减去所有预测结果中的分类正确的且边界框坐标正确的数量,就是FN。
[2]Percision(精确率)和Recall(召回率)
对于多分类目标检测任务,会分别计算每个类别的TP、FP、FN的数量,然后进一步计算每个类别的Precision和Recall
Percision(准确率)
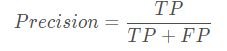
准确率是指模型只找到相关目标的能力,体现了模型本身预测结果中的准确率,即模型给出的所有预测结果中命中真实目标的比例。
Recall(召回率)
![]()
召回率是指模型找到所有相关目标的能力,即模型给出的最终经过筛选的预测结果中覆盖了测试集中多少真实目标(测试集)的比例。
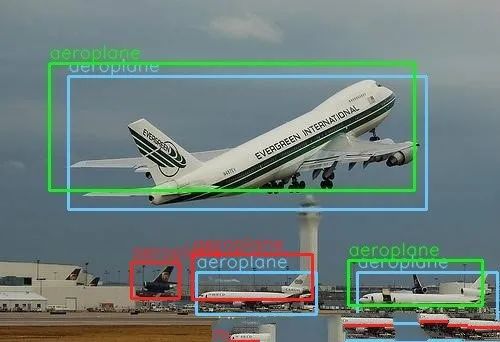
如上这幅图所示,蓝色的是测试集中的真实框和目标,绿色和红色的是预测框,假设我们设置的阈值,只有绿色的框是和真实框大于阈值的,那么
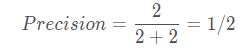
![]()
[3]平均精度AP(averge precision)
AP是指将精确度Precision和召回率Recall二者进行结合,因为Precision是表现的是所有预测结果中命中目标能通过阈值的预测能力,而Recall体现的针对能够覆盖测试集中真实目标的能力,将二者结合可以更好评估我们的模型。而我们设置不同的阈值(置信度)我们就可以得到每一个类别的不同Precision和Recall值。
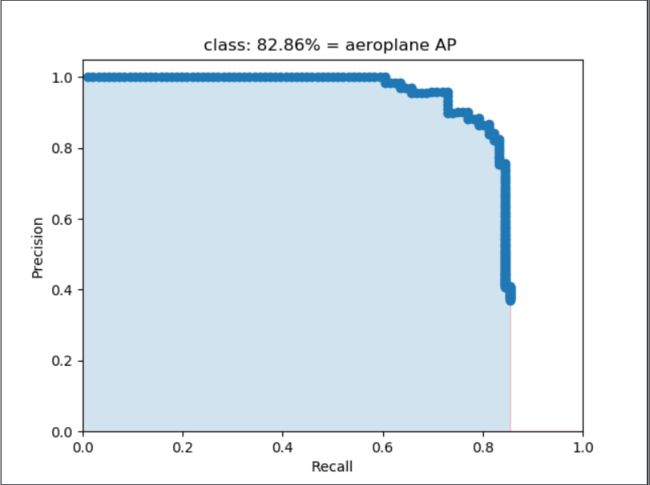
AP事实上指的是,利用Precision值为纵轴和Recall值为横轴的点的组合,画出来的曲线的下面的面积,这个曲线又叫做pr曲线,求得的面积也是这个类别的平均精度。
这是设置不同的置信度,如下面这幅图所示是飞机这个类别的PR曲线。
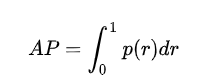
【4】mAP
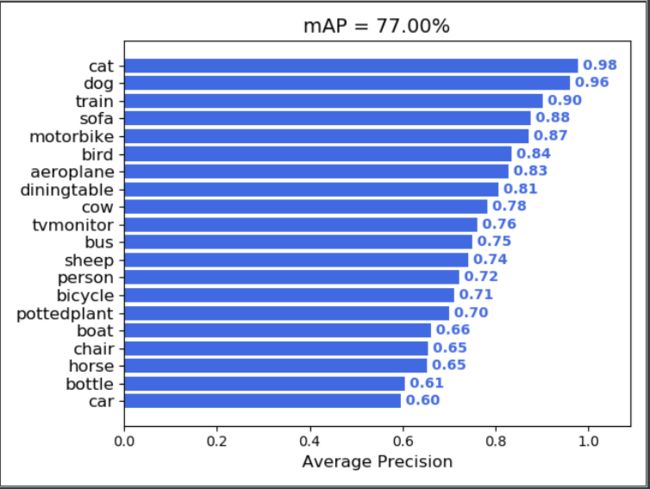
而mAP则是每个类别的平均精度的均值,也就是各个类别的AP的均值。
四、绘制mAP代码实现
第一步:下载绘制mAP所需的代码
我们首先在这个github上下载绘制mAP所需的代码:https://github.com/Cartucho/mAP。
第二步:准备Input文件夹中所需要的内容
在这个代码中,如果想要绘制mAP则需要三个内容:
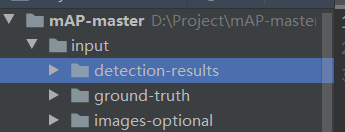
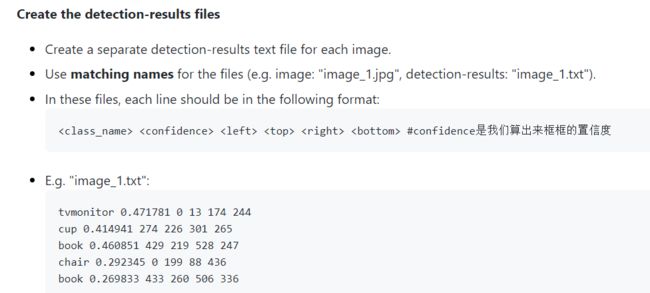
1.detection-results
指的是目标检测算法的测试集对应的每一张图片预测结果的txt文件(这里指的是最终预测结果,经过NMS筛选了的)
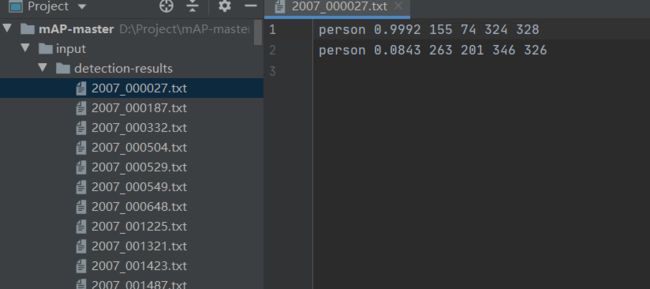
包含信息的格式:
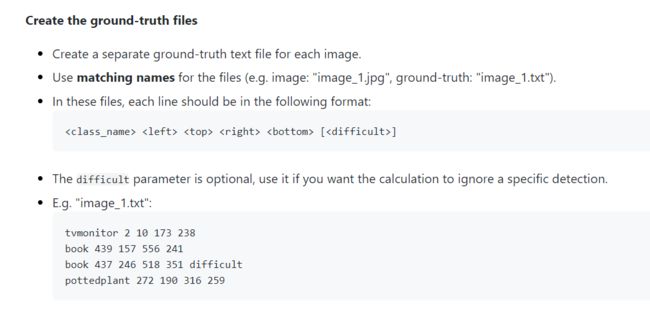
2.ground-truth
指的是测试集中每一张图片所对应的真实框的txt文件。
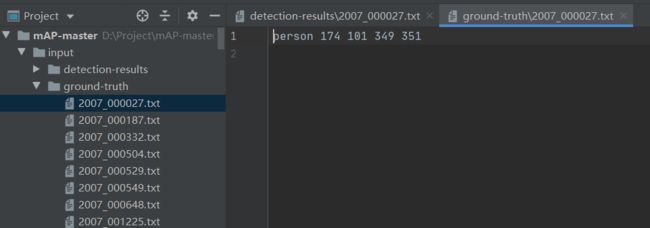
包含的信息格式
3.image-optional
指的是是否在计算mAp过程中显示预测框和真实框图片,这个可以可视化出来,也可以不可视化。
SSD算法检测的mAP计算
( 这里以目标检测SSD算法对Voc2012数据集进行mAP计算为例)
第一步:下载SSD目标检测算法和Voc2012数据集
https://github.com/bubbliiiing/count-mAP-txt
我们首先将整个VOC2012的数据集放到VOCdevikit中
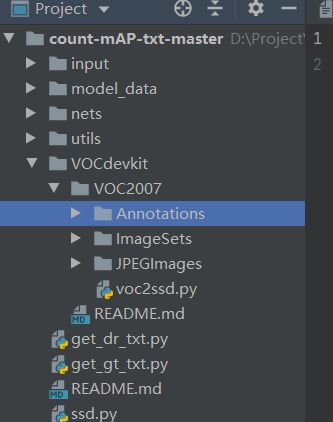
第二步:划分数据集,将Voc2012数据集进行划分得到要测试的test数据集
修改voc2ssd.py里面的trainval_percent=0.9,表示用Voc2012数据集的10%用来测试,一般测试图片用10%或者更少。
如果大家放进VOCdevikit的数据集不是全部数据,而是已经筛选好的测试数据集的话,那么就把trainval_percent设置成0,表示全部的数据都用于测试。
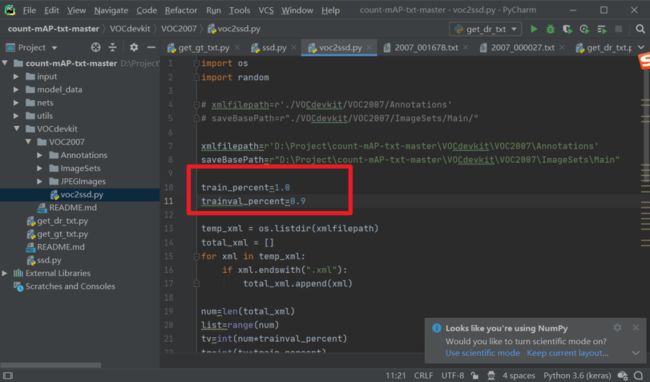
第三步:然后运行voc2ssd.py,此时会生成测试集test.txt,存放用于测试的图片的名字。
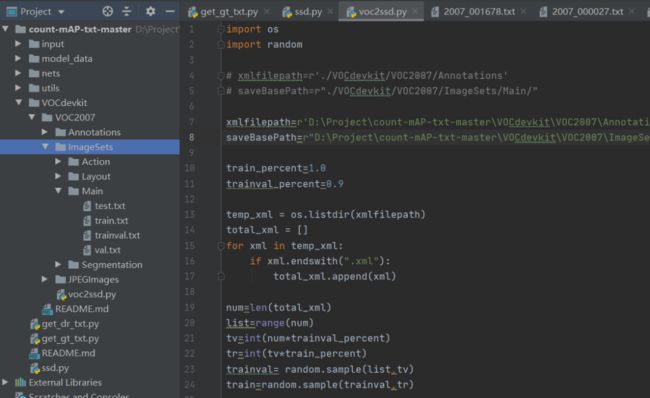
第四步:依次运行主目录下的get_dr_txt.py和get_gt_txt.py获得预测框对应的txt和真实框对应的txt。
get_dr_txt.py是用来检测测试集里面的图片的,然后会生成每一个图片的检测结果,我重写了detect_image代码,用于生成预测框的txt。
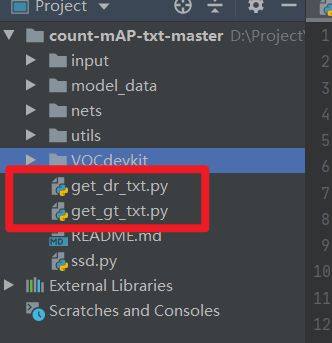
第五步:完成后,我们就可以得到用于计算mAP的Input文件夹内的3个内容,将其复制到mAP-master中即可。

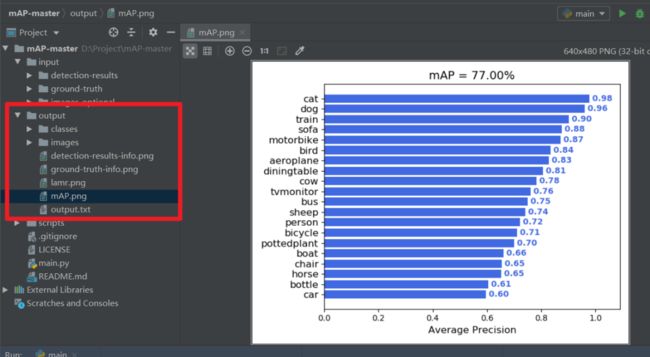
第六步:最后运行main.py,在output文件夹内,即可获得最终VOC2012数据集在SSD检测算法的mAP
本讲上所有用到的代码,在后台回复:项目实战,即可获取。
精彩推荐:
原理讲解-项目实战 <-> Mtcnn + Facenet 搭建人脸识别平台(中奖名单公示)
原理讲解-项目实战 <-> Keras搭建Mtcnn人脸检测平台
Yolov3算法实现社交距离安全检测项目讲解和实战(Social Distance Detector)
万字长文,用代码的思想讲解Yolo3算法实现原理,Visdrone数据集和自己制作数据集两种方式在Pytorch训练Yolo模型
