Pytorch实现Deep Mutual Learning网络
- -Model(pytorch版本
参考资料:
信息熵是什么?
交叉熵和相对熵(KL散度), 极大似然估计求loss, softmax多分类
一文搞懂熵、相对熵、交叉熵损失
class torch.nn.KLDivLoss(size_average=True, reduce=True)
信息量:I(x0)=−log(p(x0)) ,一个事件发生的概率越大,则它所携带的信息量就越小
熵:对于一个随机变量X而言,它的所有可能取值的信息量的期望(E[I(x)])就称为熵。![]()
熵的单位随着公式中log运算的底数而变化,当底数为2时,单位为“比特”(bit),底数为e时,单位为“奈特”。
熵用来衡量一个系统的混乱程度,代表系统中信息量的总和;熵值越大,表明这个系统的不确定性就越大。
相对熵:也称为KL散度(Kullback-Leibler divergence),表示同一个随机变量的两个不同分布间的距离。
真实分布为p,假设分布q,优化相对熵, 即等于优化假设分布q来拟合真实分布p.
交叉熵:设 p(x),q(x) 分别是 离散随机变量X的两个概率分布,其中p(x)是目标分布,p和q的交叉熵可以看做是,使用分布q(x) 表示目标分布p(x)的困难程度
Deep Mutual Learnging训练核心::


链接: Deep Mutual Learning代码实现 提取码: ahqt
- 1.一 论文导读
- 2.二 论文精读
- 3.三 代码实现
- 4.四 问题思索
《Deep Mutual Learning》
—深度相互学习网络(DML)
作者:Ying Zhang,etc
发表会议及时间:CVPR 2018
一 论文导读
- 目标识别简介
- 目标识别的相关技术
- 相关知识
- DML研究背景、创新、贡献
- 讨论
- 目标识别简介
目标类别与目标检测的区别:

目标识别是计算机视觉的基础任务,被广泛应用在不同的领域中。包括安防领域的人脸识别、行人检测、智能视频分析,行人跟踪等,交通领域的交通场景物体识别、车辆计数、逆行检测、车牌检测与识别、以及互联网的基于内容的图像检索、相册自动归类等。
目标识别的常用数据集:

目标识别的流程:

目标识别的难点:

- 目标识别的相关技术
基于深度学习的目标识别:

- 相关知识
蒸馏模型:蒸馏模型的一般形式, 教师和学生网络
交叉熵:交叉熵公式
KL散度:KL散度公式、数值大小、代表意义
- DML研究背景、创新、成果
研究背景:
依靠深度堆叠网络层数,增加网络宽度实现,这种结构设计会产生大量的参数。
一方面,会拖慢运行速度和执行效率
另一方面,需要很大的存储空间进行存储。
这两方面也限制了很多网络在实际应用中落地。
因此,如何在保证性能的情况下设计更小,更快速的网络,就成了我们关注的重点。
创新:
1 本文提出了一种简单且普适的方法DML来提高深度神经网络的性能。在目标分类,任
务重识别上取得了很好的效果。
2 受蒸馏模型的启发,将几个网络一起训练, 相互蒸馏。用这种方法,可以获得紧凑的
网络,大大减少了网络中的参数量,提升了计算效率。
3 实验证明,DML相比传统的蒸馏模型更好更健壮。此外,DML也能提高大型网络的性能,并
且以这种方式训练的网络队列可以作为一个集成来进一步提高性能。
成果:
作者通过在CIFAR- 100和Market-1501数据集上的实验,表明DML网络在分类和任务重识别任务中的有效
性和高效性。
- 讨论
资料推荐

知识扩展:
经典网络结构
Google Net: 2014冠军
运行几个并行的卷积核,对输入
进行卷积和池化,采用不同大小
的卷积核意味着不同大小的感受
野,最后拼接意味着不同尺度特
征的融合

交叉熵和KL散度
信息量
信息熵
交叉熵
KL散度:即相对熵,是描述两个概率分布P和Q差异的一种方法
![]()

蒸馏模型

资料推荐:

二 论文精读
引言:
-
深度神经网络通常采用增加宽度,深度,基数等方法提升性能,但是这些结构也引入了复杂的参数,拖慢训练速度,增加存储负担。
-
蒸馏模型通过迁移学习使学生网络有了跟教师网络匹敌的特征表示能力,为什么说能匹敌教师网络,是因为损失函数的设计,学生网络的损失函数中一是有自身拟合的损失函数,二是有和教师网络相连的交叉熵损失函数,这两种损失确保了学生网络自身比较简单的情况下,获得比较好的表现,即特征表现能力。
-
受蒸馏模型启发,提出深度相互学习网络,只需要简单的学生网络相互学习,相互监督就能有很好的性能表现,抛弃了教师模型的复杂臃肿。
-
性能随着队列中网络的数量增加而增加且适用于各种网络架构,也适用于异构群组,即学生网络不仅仅是两个,可以是三个,甚至多个,这里意义其实还是很大的,因为他拓展了深度学习的"宽度”。其实如果比较熟悉机器学习,这种思想就是集成学习的一种,是模型融合方法思想之一。
相关工作:
- 蒸馏模型将强大且易于训练的大型网络提炼成小型但较难训练的网络
- 对偶学习(Dual Learning)两个跨语言翻译模型相互学习,适用于特定的自然语言问题
- DML对网络模型无要求,能够使网络找到健壮的解决方案,很好地拟合测试数据,并泛化到新数据。
经典算法模型:
蒸馏模型:


补充:激活函数

本文算法:

- 与蒸馏模型不同,DML网络中参与训练的都 是随机初始化的学生网络,我们想让网络既 具有自身的识别能力,又能从别的网络那里 学到知识经验。
- 因此在训练过程中,一方面,要通过自身监督学习,提高预测准确性;另一方面,要尽可能拟合队列中其它网络的预测概率。
- 这样,网络的性能会比单独一个网络进行预测要提升很多
算法详解:


这就是普通的损失函数,多分类的交叉熵

主要要理解上图的![]() 损失函数,使用了KL散度,即相对熵,其实就是一种相关系数,越小代表相似度越高。
损失函数,使用了KL散度,即相对熵,其实就是一种相关系数,越小代表相似度越高。
我们的目标希望是第一个网路能够学到第二个网络的经验,那如果表示第一个网络学到了第二个网路的经验了呢?
就是第二个损失函数
这个损失函数表示了 第一个网络和第二个网络的预测相似程度,让这个损失值越小,就代表第一个网络学到第二个网络的经验越多。
最后的损失函数设计:

补充:学生网络(互学习网络)的选择和设计,可以作为提升点。按照模型融合的原则: 不同模型差异越大,而效果却同样好,则模型融合效果越好的原则。
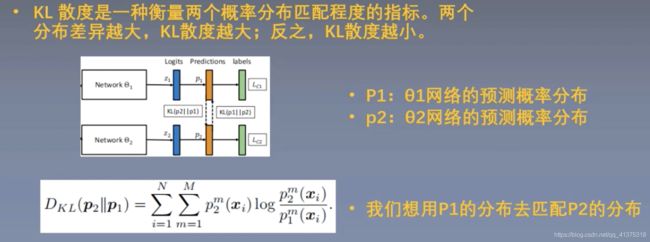

注意:更新θ2时,利用的是已经更新完毕的01的参数。
DML扩展:多个学生网络(互学习网络)
下面是两种不同的损失函数设计:

左边的:
注意对 的理解,是为了削弱其他网络对这个网络过多的干涉影响,网络越多,削弱越多
的理解,是为了削弱其他网络对这个网络过多的干涉影响,网络越多,削弱越多
右边的:

他是取了其他网络所有预测值的平均值,再和本网络的预测值做KL散度
本论文的环境配置和实验结果:


讨论:
问题1:
相比蒸馏模型,相互学习中额外的知识从何获得?
解决1:
每个学生 网络的训练主要受自身监督学习主导。在监督
学习下,所有的网络很快就会为每个训练实例预测相同
的(真实的)标签。但是由于每个学生网络是未经预训练,
随机初始化的,所以它们的softmax层输出的第二个最可
能类别的标签是不同的,而正是这些secondary信息,为
蒸馏和相互学习提供了额外的知识
问题2
DML训练中 如何找到更鲁棒的最小值?
解决2
DML会要求每个网络匹配其同伴网络的概率估计,如果
给定网络预测为零,而其对等网络预测为非零,则该网
络将受到严重惩罚。DML中的所有网络都倾向于聚合它
们对次级概率的预测。DML是通过对“合理的"次概率预
测的相互概率匹配来寻找更宽泛的最小值
论文主要创新点
A
提出了一种深度相互学习策略
1.受蒸馏模型启发
2.利用学生网络间的相互学习
B
DML同样适用于网络集成
C
在提升性能的同时获得了更紧凑的网络模型
推荐阅读资料:

三 代码实现
链接: Deep Mutual Learning代码实现 提取码: ahqt
1.项目结构:
Config.py:配置文件,包括各种参数的配置
Data_ loader.py :数据加载,包括训练集,验证集,测试集,转化为pytorch接受的格式
trainer. py:训练,验证,优化算法实现
utils.py:正确率计算函数的实现
resnet.py:作为学生网络的残差网络
main.py:项目运行入口

- 运行
运行main.py即可
看了一下输入图像和标签,结果挺正常,应该是在真训练



images:

labels:

补充:



pin_memory:加快读取数据的速度,一般数据是先加入虚拟内存,再加入锁页内存,最后进入cuda,设置pin_memory=Ture可以直接加入锁页内存。
- 现在说SGD一般都指MBGD
- config参数:
Namespace(batch_size=256, best=False, ckpt_dir='./ckpt', data_dir='./data/cifar100', epochs=1, gamma=0.1, init_lr=0.1, is_train=True, logs_dir='./logs/', lr_patience=10, model_num=2, momentum=0.9, nesterov=True, num_classes=100, num_workers=4, pin_memory=True, print_freq=10, random_seed=1, resume=False, save_name='model', shuffle=True, train_patience=100, use_gpu=True, use_tensorboard=True, weight_decay=0.0005)

main.py
# -*- coding: utf-8 -*-
"""
一般模型训练的大致顺序:
# ============================ step 0/5 参数设置 ============================
# ============================ step 1/5 数据 ================================
# ============================ step 2/5 模型 ================================
# ============================ step 3/5 损失函数 相当重要的 ============================
# ============================ step 4/5 优化器 ==============================
# ============================ step 5/5 训练 ================================
# ============================ inference ====================================
"""
import torch
from trainer import Trainer
from config import get_config
from utils import prepare_dirs, save_config
from data_loader_tired_driving import get_train_loader_tired_driving,get_valid_loader_tired_driving
def main(config):
# ============================ 参数设置 ============================
prepare_dirs(config) # 确保创建模型保存和日志文件夹
# ensure reproducibility
#torch.manual_seed(config.random_seed)
kwargs = {
} # 字典变量,保存参数进行传参
if config.use_gpu:
#torch.cuda.manual_seed_all(config.random_seed)
kwargs = {
'num_workers': config.num_workers, 'pin_memory': config.pin_memory} # 读取数据的进程数 读进锁页
#torch.backends.cudnn.deterministic = True
# ============================ 数据 ============================
# 数据部分三件套
# 1.transform
# 2.dataset
# 3.dataloader
#-------------------------------get_valid_loader------------------------------------
# valid_data_loader = get_valid_loader(
# config.data_dir, config.batch_size, **kwargs
# )
#-----------------------------------get_valid_loader_tired_driving--------------------------------
valid_data_loader = get_valid_loader_tired_driving(
config.data_dir, config.batch_size, **kwargs
)
if config.is_train:
# -------------------------------get_train_loader------------------------------------
# train_data_loader = get_train_loader(
# config.data_dir, config.batch_size,
# config.random_seed, config.shuffle, **kwargs
# )
# -------------------------------get_train_loader_tired_driving------------------------------------
train_data_loader = get_train_loader_tired_driving(
config.data_dir, config.batch_size,
config.random_seed, config.shuffle, **kwargs
)
data_loader = (train_data_loader, valid_data_loader)
# ============================ 训练 ============================
trainer = Trainer(config, data_loader)
# either train
if config.is_train:
save_config(config)
trainer.train()
if __name__ == '__main__':
config, unparsed = get_config() # 获取参数
# print("-----config-------")
# print(config)
# print("------unparsed------")
# print(unparsed)
main(config)
train.py
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.optim as optim
import torch.nn.functional as F
import os
import time
import shutil
from tqdm import tqdm
from utils import accuracy, AverageMeter
from tensorboard_logger import configure, log_value
from models.se_resnet import se_resnet18
from models.resnet import ResNet18
from models.alexnet import AlexNet
from models.googlenet import GoogLeNet
class Trainer(object):
"""
Trainer encapsulates all the logic necessary for
training the MobileNet Model.
All hyperparameters are provided by the user in the
config file.
"""
def __init__(self, config, data_loader):
"""
Construct a new Trainer instance.
Args
----
- config: object containing command line arguments.
- data_loader: data iterator
"""
self.config = config
# data params
if config.is_train: # data_loader = (train_data_loader, test_data_loader)
self.train_loader = data_loader[0] # train_data_loader
self.valid_loader = data_loader[1] # valid_data_loader
self.num_train = len(self.train_loader.dataset) # 获取训练数据长度
self.num_valid = len(self.valid_loader.dataset) # 获取验证数据长度
else:
self.test_loader = data_loader
self.num_test = len(self.test_loader.dataset)
self.num_classes = config.num_classes # 总分类数
# 训练参数设置
self.epochs = config.epochs
self.start_epoch = 0
self.momentum = config.momentum
self.lr = config.init_lr
self.weight_decay = config.weight_decay
self.nesterov = config.nesterov
self.gamma = config.gamma
# misc params
self.use_gpu = config.use_gpu
self.best = config.best
self.ckpt_dir = config.ckpt_dir
self.logs_dir = config.logs_dir
self.counter = 0
self.lr_patience = config.lr_patience
self.train_patience = config.train_patience
self.use_tensorboard = config.use_tensorboard
self.resume = config.resume
self.print_freq = config.print_freq
self.model_name = config.save_name
self.model_num = config.model_num
self.models = []
self.optimizers = []
self.schedulers = []
self.loss_kl = nn.KLDivLoss(reduction='batchmean')
self.loss_ce = nn.CrossEntropyLoss()
self.best_valid_accs = [0.] * self.model_num
# configure tensorboard logging
if self.use_tensorboard: # 保存日志
tensorboard_dir = self.logs_dir + self.model_name
print('[*] Saving tensorboard logs to {}'.format(tensorboard_dir))
if not os.path.exists(tensorboard_dir):
os.makedirs(tensorboard_dir)
configure(tensorboard_dir)
"""
***重要***
"""
for i in range(self.model_num):
# build models
model =GoogLeNet() # 选定模型
model1=se_resnet18()
model1.to('cuda:0')
if self.use_gpu: # 放入cuda
model.cuda()
# 就是在这里进行了互学习模型的各模型选定
"""
***重要*** 模型选择
"""
if(i == 0):
self.models.append(model)
if (i == 1):
self.models.append(model1)
# 确定优化器和优化策略
optimizer = optim.SGD(model.parameters(), lr=self.lr, momentum=self.momentum,
weight_decay=self.weight_decay, nesterov=self.nesterov)
# L2正则化的目的就是为了让权重衰减到更小的值,在一定程度上减少模型过拟合的问题,所以权重衰减也叫L2正则化
# https://blog.csdn.net/program_developer/article/details/80867468 这篇blok把正则化的作用讲的挺好的
"""
作用:权重衰减(L2正则化)可以避免模型过拟合问题。
思考:L2正则化项有让w变小的效果,但是为什么w变小可以防止过拟合呢?
原理:(1)从模型的复杂度上解释:更小的权值w,从某种意义上说,表示网络的复杂度更低,对数据的拟合更好(这个法则也叫做奥卡姆剃刀)
,而在实际应用中,也验证了这一点,L2正则化的效果往往好于未经正则化的效果。
(2)从数学方面的解释:过拟合的时候,拟合函数的系数往往非常大,为什么?如下图所示,过拟合,就是拟合函数需要顾忌每一个点,
最终形成的拟合函数波动很大。在某些很小的区间里,函数值的变化很剧烈。这就意味着函数在某些小区间里的导数值(绝对值)非常大,
由于自变量值可大可小,所以只有系数足够大,才能保证导数值很大。而正则化是通过约束参数的范数使其不要太大,所以可以在一定程度上减少过拟合情况
"""
self.optimizers.append(optimizer)
# 设置学习衰减率 set learning rate decay
scheduler = optim.lr_scheduler.StepLR(self.optimizers[i], step_size=60, gamma=self.gamma, last_epoch=-1)
self.schedulers.append(scheduler)
print('[*] Number of parameters of one model: {:,}'.format(
sum([p.data.nelement() for p in self.models[0].parameters()]))) # 一个模型的参数数量
def train(self):
"""
Train the model on the training set.
A checkpoint of the model is saved after each epoch
and if the validation accuracy is improved upon,
a separate ckpt is created for use on the test set.
"""
# load the most recent checkpoint
if self.resume:
self.load_checkpoint(best=False)
print("\n[*] Train on {} samples, validate on {} samples".format(
self.num_train, self.num_valid) # 训练和验证在多少样本数上
)
for epoch in range(self.start_epoch, self.epochs): # 循环训练epoch遍
for scheduler in self.schedulers: # 一个一个模型的优化
scheduler.step(epoch)
print(
'\nEpoch: {}/{} - LR: {:.6f}'.format(
epoch+1, self.epochs, self.optimizers[0].param_groups[0]['lr'],)
)
# train for 1 epoch
train_losses, train_accs = self.train_one_epoch(epoch)
# evaluate on validation set
valid_losses, valid_accs = self.validate(epoch)
for i in range(self.model_num):
is_best = valid_accs[i].avg> self.best_valid_accs[i]
msg1 = "model_{:d}: train loss: {:.3f} - train acc: {:.3f} "
msg2 = "- val loss: {:.3f} - val acc: {:.3f}"
if is_best:
#self.counter = 0
msg2 += " [*]"
msg = msg1 + msg2
print(msg.format(i+1, train_losses[i].avg, train_accs[i].avg, valid_losses[i].avg, valid_accs[i].avg))
# check for improvement
#if not is_best:
#self.counter += 1
#if self.counter > self.train_patience:
#print("[!] No improvement in a while, stopping training.")
#return
self.best_valid_accs[i] = max(valid_accs[i].avg, self.best_valid_accs[i])
self.save_checkpoint(i,
{
'epoch': epoch + 1,
'model_state': self.models[i].state_dict(),
'optim_state': self.optimizers[i].state_dict(),
'best_valid_acc': self.best_valid_accs[i],
}, is_best
)
def train_one_epoch(self, epoch):
"""
Train the model for 1 epoch of the training set.
An epoch corresponds to one full pass through the entire
training set in successive mini-batches.
This is used by train() and should not be called manually.
"""
batch_time = AverageMeter()
losses = []
accs = []
for i in range(self.model_num):
self.models[i].train()
losses.append(AverageMeter())
accs.append(AverageMeter())
tic = time.time()
with tqdm(total=self.num_train) as pbar:
for i, (images, labels) in enumerate(self.train_loader):
if self.use_gpu:
images, labels = images.cuda(), labels.cuda() # images、labels 是16个
images, labels = Variable(images), Variable(labels)
#forward pass
outputs=[]
for model in self.models: # 一个模型
outputs.append(model(images)) # output[0]=16 model1 output[]
"""
***重要***
"""
# ============================ 损失函数 ============================
# 这个循环结束就是所有模型训练了一遍,即整个互学习模型训练了一遍,即以前那种单个模型训练一遍
for i in range(self.model_num):
ce_loss = self.loss_ce(outputs[i], labels) # 当前模型的交叉熵损失值
kl_loss = 0
for j in range(self.model_num): # KL散度 重点
if i!=j:
kl_loss += self.loss_kl(F.log_softmax(outputs[i], dim = 1), # lenet
F.softmax(Variable(outputs[j]), dim=1)) # 当前模型的kl散度 re_res target
loss = ce_loss + kl_loss / (self.model_num - 1) # 当前模型最后的loss
# measure accuracy and record losstrain loss:
prec = accuracy(outputs[i].data, labels.data, topk=(1,))[0]
# if i==1
# prec1=prec
# if i == 2
# prec2 = prec
#
# prec=prec1/2+ prec2/2
losses[i].update(loss.item(), images.size()[0]) # 记录每个模型的loss
accs[i].update(prec.item(), images.size()[0]) # 记录每个模型的acc
# compute gradients and update SGD
# ============================ 优化器 ==============================
self.optimizers[i].zero_grad() # 当前模型的梯度清零
loss.backward() # loss反向传播
self.optimizers[i].step() # 当前模型的优化器进行优化
# measure elapsed(时间流逝) time
toc = time.time()
batch_time.update(toc-tic) # 一个batchsize 所花时间
pbar.set_description(
(
"{:.1f}s - model_all_avg_loss: {:.3f} - model_all_avg_acc: {:.3f}".format(
################################对各个网络a求平均值############################################
(toc-tic), (losses[0].avg+losses[1].avg)/2, (accs[0].avg+accs[1].avg)/2 # avg()返回组中值的平均值, 即所有模型loss 和 acc 的平均值
)
)
)
self.batch_size = images.shape[0]
pbar.update(self.batch_size)
# log to tensorboard
if self.use_tensorboard:
iteration = epoch*len(self.train_loader) + i
for i in range(self.model_num):
log_value('train_loss_%d' % (i+1), losses[i].avg, iteration)
log_value('train_acc_%d' % (i+1), accs[i].avg, iteration)
return losses, accs
def validate(self, epoch):
"""
Evaluate the model on the validation set.
"""
losses = []
accs = []
for i in range(self.model_num):
self.models[i].eval() # 模型参数固化
losses.append(AverageMeter())
accs.append(AverageMeter())
for i, (images, labels) in enumerate(self.valid_loader):
if self.use_gpu:
images, labels = images.cuda(), labels.cuda()
images, labels = Variable(images), Variable(labels)
#forward pass
outputs=[]
for model in self.models:
outputs.append(model(images))
"""
***重要***
"""
# ============================ 损失函数 ============================
for i in range(self.model_num):
ce_loss = self.loss_ce(outputs[i], labels)
kl_loss = 0
for j in range(self.model_num):
if i!=j: # 其他模型的的
kl_loss += self.loss_kl(F.log_softmax(outputs[i], dim = 1),
F.softmax(Variable(outputs[j]), dim=1))
loss = ce_loss + kl_loss / (self.model_num - 1)
# measure accuracy and record loss
prec = accuracy(outputs[i].data, labels.data, topk=(1,))[0]
losses[i].update(loss.item(), images.size()[0]) # update 类似于 append
accs[i].update(prec.item(), images.size()[0])
# log to tensorboard for every epoch
if self.use_tensorboard:
for i in range(self.model_num):
log_value('valid_loss_%d' % (i+1), losses[i].avg, epoch+1)
log_value('valid_acc_%d' % (i+1), accs[i].avg, epoch+1)
return losses, accs
def save_checkpoint(self, i, state, is_best):
"""
Save a copy of the model so that it can be loaded at a future
date. This function is used when the model is being evaluated
on the test data.
If this model has reached the best validation accuracy thus
far, a seperate file with the suffix `best` is created.
"""
# print("[*] Saving model to {}".format(self.ckpt_dir))
filename = self.model_name + str(i+1) + '_ckpt.pth.tar'
ckpt_path = os.path.join(self.ckpt_dir, filename)
torch.save(state, ckpt_path)
if is_best:
filename = self.model_name + str(i+1) + '_model_best.pth.tar'
shutil.copyfile(
ckpt_path, os.path.join(self.ckpt_dir, filename)
)
def load_checkpoint(self, best=False):
"""
Load the best copy of a model. This is useful for 2 cases:
- Resuming training with the most recent model checkpoint.
- Loading the best validation model to evaluate on the test data.
Params
------
- best: if set to True, loads the best model. Use this if you want
to evaluate your model on the test data. Else, set to False in
which case the most recent version of the checkpoint is used.
"""
print("[*] Loading model from {}".format(self.ckpt_dir))
filename = self.model_name + '_ckpt.pth.tar'
if best:
filename = self.model_name + '_model_best.pth.tar'
ckpt_path = os.path.join(self.ckpt_dir, filename)
ckpt = torch.load("./ckpt/model2_ckpt.pth.tar")
# load variables from checkpoint
self.start_epoch = ckpt['epoch']
self.best_valid_acc = ckpt['best_valid_acc']
self.model.load_state_dict(ckpt['model_state'])
self.optimizer.load_state_dict(ckpt['optim_state'])
if best:
print(
"[*] Loaded {} checkpoint @ epoch {} "
"with best valid acc of {:.3f}".format(
filename, ckpt['epoch'], ckpt['best_valid_acc'])
)
else:
print(
"[*] Loaded {} checkpoint @ epoch {}".format(
filename, ckpt['epoch'])
)
data_loader.py
import numpy as np
import os
import torch
from torchvision import transforms
from my_dataset import MyDataset
# 数据路径
split_dir = os.path.join("data", "split_data")
train_dir = os.path.join(split_dir, "train_test")
valid_dir = os.path.join(split_dir, "valid_test")
# 图像的均值和标准差
norm_mean = [0.33424968,0.33424437, 0.33428448]
norm_std = [0.24796878, 0.24796101, 0.24801227]
# 训练数据预处理
def get_train_loader_tired_driving(data_dir,
batch_size,
random_seed,
shuffle=True,
num_workers=4,
pin_memory=True):
train_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomCrop(32, padding=4),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
dataset = MyDataset(data_dir=train_dir, transform=train_transform)
if shuffle:
np.random.seed(random_seed)
train_loader = torch.utils.data.DataLoader(
dataset, batch_size=batch_size, shuffle=shuffle, num_workers=num_workers, pin_memory=pin_memory,
)
return train_loader
# 验证数据预处理
def get_valid_loader_tired_driving(data_dir,
batch_size,
num_workers=4,
pin_memory=True):
valid_transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(norm_mean, norm_std),
])
# 构建MyDataset实例
dataset = MyDataset(data_dir=valid_dir, transform=valid_transform)
data_loader = torch.utils.data.DataLoader(
dataset, batch_size=batch_size, shuffle=False,
num_workers=num_workers, pin_memory=pin_memory,
)
return data_loader
dataset.py
"""
各数据集的Dataset定义
"""
import os
import random
from PIL import Image
from torch.utils.data import Dataset
random.seed(1)
rmb_label = {
"eyesclosed": 0, "lookingarroud": 1, "safedriving": 2, "smoking": 3, "yawning": 4} # 如果改了分类目标,这里需要修改
# 主要是用来接受索引返回样本用的
class MyDataset(Dataset):
def __init__(self, data_dir, transform=None):
"""
:param data_dir: str, 数据集所在路径
:param transform: torch.transform,数据预处理
"""
self.label_name = {
"eyesclosed": 0, "lookingarroud": 1, "safedriving": 2, "smoking": 3, "yawning": 4} # 如果改了分类目标,这里需要修改
self.data_info = self.get_img_info(data_dir) # data_info存储所有图片路径和标签,在DataLoader中通过index读取样本
self.transform = transform
#接受一个索引,返回一个样本 --- img, label
def __getitem__(self, index):
path_img, label = self.data_info[index]
img = Image.open(path_img).convert('RGB') # 0~255
if self.transform is not None:
img = self.transform(img) # 在这里做transform,转为tensor等等
return img, label
def __len__(self):
return len(self.data_info)
@staticmethod
def get_img_info(data_dir):
data_info = list()
for root, dirs, _ in os.walk(data_dir):
# 遍历类别
for sub_dir in dirs:
img_names = os.listdir(os.path.join(root, sub_dir))
img_names = list(filter(lambda x: x.endswith('.jpg'), img_names)) # 如果改了图片格式,这里需要修改
# 遍历图片
for i in range(len(img_names)):
img_name = img_names[i]
path_img = os.path.join(root, sub_dir, img_name)
label = rmb_label[sub_dir]
data_info.append((path_img, int(label)))
return data_info
utils.py
import os
import json
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from PIL import Image
def denormalize(T, coords):
return (0.5 * ((coords + 1.0) * T))
class AverageMeter(object):
"""
Computes and stores the average and
current value.
"""
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def accuracy(output, target, topk=(1,)):
"""Computes the precision@k for the specified values of k"""
maxk = max(topk) # 最大概率
batch_size = target.size(0) # 256
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].view(-1).float().sum(0)
res.append(correct_k.mul_(100.0 / batch_size))
return res
def resize_array(x, size):
# 3D and 4D tensors allowed only
assert x.ndim in [3, 4], "Only 3D and 4D Tensors allowed!"
# 4D Tensor
if x.ndim == 4:
res = []
for i in range(x.shape[0]):
img = array2img(x[i])
img = img.resize((size, size))
img = np.asarray(img, dtype='float32')
img = np.expand_dims(img, axis=0)
img /= 255.0
res.append(img)
res = np.concatenate(res)
res = np.expand_dims(res, axis=1)
return res
# 3D Tensor
img = array2img(x)
img = img.resize((size, size))
res = np.asarray(img, dtype='float32')
res = np.expand_dims(res, axis=0)
res /= 255.0
return res
def img2array(data_path, desired_size=None, expand=False, view=False):
"""
Util function for loading RGB image into a numpy array.
Returns array of shape (1, H, W, C).
"""
img = Image.open(data_path)
img = img.convert('RGB')
if desired_size:
img = img.resize((desired_size[1], desired_size[0]))
if view:
img.show()
x = np.asarray(img, dtype='float32')
if expand:
x = np.expand_dims(x, axis=0)
x /= 255.0
return x
def array2img(x):
"""
Util function for converting anumpy array to a PIL img.
Returns PIL RGB img.
"""
x = np.asarray(x)
x = x + max(-np.min(x), 0)
x_max = np.max(x)
if x_max != 0:
x /= x_max
x *= 255
return Image.fromarray(x.astype('uint8'), 'RGB')
def prepare_dirs(config): # 创建模型保存和日志文件夹
for path in [config.ckpt_dir, config.logs_dir]:
if not os.path.exists(path):
os.makedirs(path)
def save_config(config):
model_name = config.save_name
filename = model_name + '_params.json'
param_path = os.path.join(config.ckpt_dir, filename)
print("[*] Model Checkpoint Dir: {}".format(config.ckpt_dir))
print("[*] Param Path: {}".format(param_path))
with open(param_path, 'w') as fp:
json.dump(config.__dict__, fp, indent=4, sort_keys=True)
config.py
# ============================ step 0/5 参数设置 ============================
import argparse
arg_lists = []
parser = argparse.ArgumentParser(description='mobilenet_classification')
def str2bool(v):
return v.lower() in ('true', '1')
def add_argument_group(name):
arg = parser.add_argument_group(name)
arg_lists.append(arg)
return arg
# data params
data_arg = add_argument_group('Data Params')
# -----------------------------------100----------------------------------------
# data_arg.add_argument('--num_classes', type=int, default=100, # 分类数 *要改
# help='Number of classes to classify')
# -------------------------------------5--------------------------------------
data_arg.add_argument('--num_classes', type=int, default=5, # 分类数 *要改 // 可能无用了
help='Number of classes to classify')
# ---------------------------------------------------------------------------
data_arg.add_argument('--batch_size', type=int, default=16, # batch_size
help='# of images in each batch of data')
data_arg.add_argument('--num_workers', type=int, default=4, # 读取数据的进程数
help='# of subprocesses to use for data loading')
data_arg.add_argument('--pin_memory', type=str2bool, default=True, # 读进锁页内存
help='whether to copy tensors into CUDA pinned memory')
data_arg.add_argument('--shuffle', type=str2bool, default=True, # 乱序
help='Whether to shuffle the train indices')
# training params
train_arg = add_argument_group('Training Params')
train_arg.add_argument('--is_train', type=str2bool, default=True, # 是否训练
help='Whether to train or test the model')
train_arg.add_argument('--momentum', type=float, default=0.9, # 动量
help='Momentum value')
train_arg.add_argument('--epochs', type=int, default=100, # 轮数 *要改
help='# of epochs to train for')
train_arg.add_argument('--init_lr', type=float, default=0.1, # 初始学习率
help='Initial learning rate value')
train_arg.add_argument('--weight_decay', type=float, default=5e-4, # 权重衰减率
help='value of weight dacay for regularization')
train_arg.add_argument('--nesterov', type=str2bool, default=True, #
help='Whether to use Nesterov momentum') # Nesterov Momentum是对Momentum的改进,nesterov动量在标准动量方法中添加了一个校正因子
train_arg.add_argument('--lr_patience', type=int, default=10, # 如果学习率不下降,也还要训练10个epoch
help='Number of epochs to wait before reducing lr')
train_arg.add_argument('--train_patience', type=int, default=100, # 如果停止训练,也还要训练100个epoch,这个有点假
help='Number of epochs to wait before stopping train')
train_arg.add_argument('--gamma', type=float, default=0.1, # 学习率衰减率,衰减gamma倍
help='value of learning rate decay')
# other params
misc_arg = add_argument_group('Misc.')
misc_arg.add_argument('--use_gpu', type=str2bool, default=True, # 是否使用gpu
help="Whether to run on the GPU")
misc_arg.add_argument('--best', type=str2bool, default=False, # 加载最好或最常用的模型,,???
help='Load best model or most recent for testing')
misc_arg.add_argument('--random_seed', type=int, default=1, # 加入随机种子,确保一定程度上的复现
help='Seed to ensure reproducibility')
"""
深度学习网络模型中初始的权值参数通常都是初始化成随机数
而使用梯度下降法最终得到的局部最优解对于初始位置点的选择很敏感
为了能够完全复现作者的开源深度学习代码,随机种子的选择能够减少一定程度上
算法结果的随机性,也就是更接近于原始作者的结果
即产生随机种子意味着每次运行实验,产生的随机数都是相同的
但是
在大多数情况下,即使设定了随机种子,仍然没有办法完全复现paper中所给出的模型性能,这是因为深度学习代码中除了产生随机数中带有随机性,其训练的过程中使用 mini-batch SGD或者优化算法进行训练时,本身就带有了随机性。
因为每次更新都是从训练数据集中随机采样出batch size个训练样本计算的平均梯度
作为当前step对于网络权值的更新值,所以即使提供了原始代码和随机种子,想要
复现作者paper中的性能也是非常困难的
"""
misc_arg.add_argument('--data_dir', type=str, default='./data/cifar100', # 确定数据目录
help='Directory in which data is stored')
misc_arg.add_argument('--ckpt_dir', type=str, default='./ckpt', # 确定模型保存目录
help='Directory in which to save model checkpoints')
misc_arg.add_argument('--logs_dir', type=str, default='./logs/', # 日志目录
help='Directory in which Tensorboard logs wil be stored')
misc_arg.add_argument('--use_tensorboard', type=str2bool, default=True, # 是否使用tensorboard
help='Whether to use tensorboard for visualization')
misc_arg.add_argument('--resume', type=str2bool, default=False, # 是否训练中断后继续在原保存模型上进行训练
help='Whether to resume training from checkpoint')
misc_arg.add_argument('--print_freq', type=int, default=10, # 打印训练细节频率
help='How frequently to print training details')
misc_arg.add_argument('--save_name', type=str, default='model', # 保存模型名字
help='Name of the model to save as')
misc_arg.add_argument('--model_num', type=int, default=2, # 互学习模型数量 *要改
help='Number of models to train for DML')
def get_config():
config, unparsed = parser.parse_known_args()
return config, unparsed
四 问题思索
- 熟练掌握DML的结构及主要思想,损失函数的设计原则,理解学生网络之间是如何进行信息的传递和聚合的。
- 掌握DML的两种结构扩展形式
即:
-
概括DML的核心思想
-
以两个学生网络(θ1和θ2)构成的DML网络为例,自己写出DML算法流程