【20】MobileNetV3
文章目录
-
-
- 1.MobilenetV3的介绍
- 2.MobilenetV3的结构
-
-
- 1)尾部结构改变
- 2)头部channel数量改变
- 3)h-swish激活函数
- 4)加入了注意力机制(SE模块)
-
- 3.MobilenetV3的性能统计
- 4.MobilenetV3的pytorch实现
-
1.MobilenetV3的介绍
回顾MobilenetV1与MobilenetV2结构
- MobilenetV1:
引入了深度可分离卷积作为传统卷积层的有效替代,大大减少计算量。深度可分离卷积通过将空间滤波与特征生成机制分离,有效地分解了传统卷积。深度可分离卷积由两个单独的层定义:用于空间滤波的轻量深度卷积和用于特征生成的较重的1x1卷积。
- MobilenetV2:
引入线性瓶颈和倒置残差结构,以便通过利用问题的低秩性质来提高层结构的效率。
1.Linear Bottlenecks
Bottlenecks的最后把ReLU函数替换为Linear 线性函数,以防止ReLU破坏特征。
2.Inverted residuals
Bottlenecks 采用与resnet相反的设计方式,先扩张 -> 提取特征 -> 压缩。

- MnasNet
建立在MobileNetV2结构上,通过在瓶颈结构中引入基于挤压和激励的轻量级注意模块。注意,与[18]中提出的基于ResNet的模块相比,挤压和激励模块集成在不同的位置。模块位于展开中的深度过滤器之后,以便注意应用于最大的表示。
MobilenetV3的亮点:
- 更新了Block(bneck),加入了SE模块(squeeze and excitation)
- 更新了激活函数,使用h-swish函数
MobilenetV3使用以上三种的不同层的组合作为构建块,以构建最有效的模型。图层也通过修改的swish非线性激活函数进行了升级。squeeze and excitation结构以及swish非线性函数都使用sigmoid,这对于定点算术的计算效率低下又难以维持精度,因此我们将其替换为hard sigmoid。
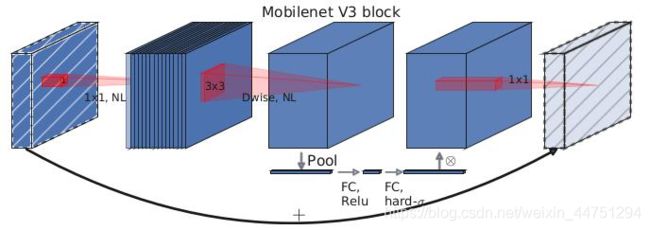
现在其综合了以下四个特点:
- MobileNetV1的深度可分离卷积(depthwise separable convolutions)。
- MobileNetV2的具有线性瓶颈的逆残差结构(the inverted residual with linear bottleneck)。
- 轻量级的注意力模型。
- 利用h-swish代替swish函数。
2.MobilenetV3的结构
网络结构的主要改变
在网络的开头和结尾重新设计了计算昂贵的层。 引入了新的非线性h-swish,这是最近的swish非线性的改进版本,它计算速度更快,对量化更友好。
通过架构搜索找到模型后,我们会发现某些最后一层以及一些较早的层比其他层更昂贵。 我们建议对体系结构进行一些修改,以减少这些慢层的等待时间,同时保持准确性。 这些修改超出了当前搜索空间的范围。
1)尾部结构改变
当前基于MobileNetV2的倒置瓶颈结构和变体的模型使用1x1卷积作为最后一层,以便扩展到更高维度的特征空间。为了具有丰富的预测特征,这一层至关重要。 但是,这要付出额外的计算和延时。为了在保留高维特征的前提下减小延时,将平均池化前的层移除并用1*1卷积来计算特征图。特征生成层被移除后,先前用于瓶颈映射的层也不再需要了,这将为减少7ms的开销,在提速11%的同时减小了30m的操作数。
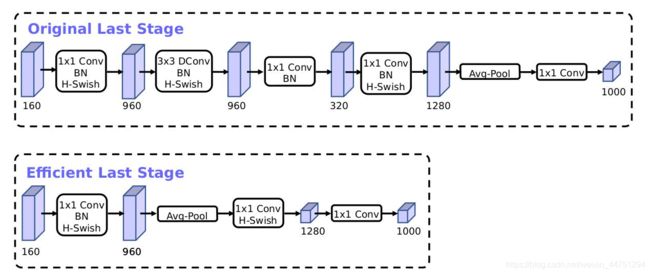
2)头部channel数量改变
当前的MobilenetV2开始使用32个 3 * 3的滤波器,作者发现使用h-swish激活函数相比于使用sigmoid和swish函数,可以在保持精度不减的情况下,将channel降低到16个,并且提速2ms。
给出MobilenetV2和MobilenetV3的结构如下,重点关注前面的通道数 32/16。
MobilenetV2

MoblenetV3-small

3)h-swish激活函数
swish非线性激活函数作为ReLU的替代,可以可以显着提高神经网络的准确性,其定义如下:
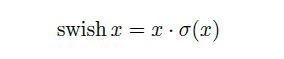
尽管这种非线性提高了准确性,但在嵌入式环境中却带来了非零成本,因为S型函数在移动设备上的计算成本更高。主要是计算、求导复杂,
对量化过程不友好。
改进的h-swish函数如下:


4)加入了注意力机制(SE模块)
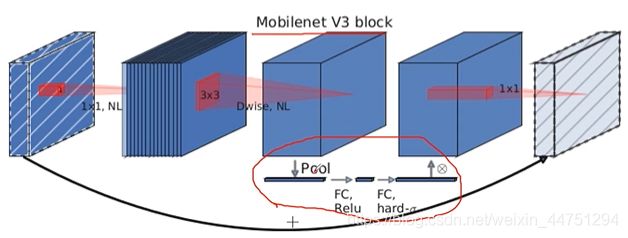
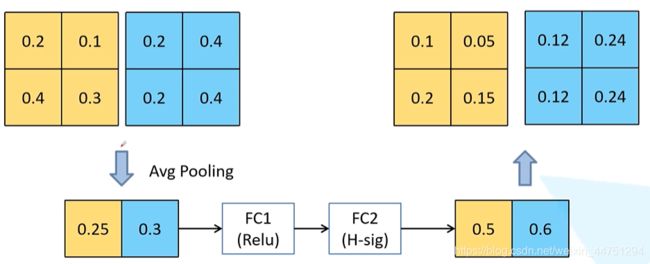
主要的操作是针对输出的特征矩阵的每一个channel进行池化处理,所得到的向量个数就是channel的个数。然后再通过两个全连接层,得到我们输出的向量。其中,第一个全连接层的向量个数是channel个数的四分之一,然后第二个全连接层的输出与channel个数相同。而且,这两个全连接的所使用的的激活函数是不一样的。前一个使用的ReLu激活函数,后一个使用h-swish激活函数。
所得到的的这个向量可以理解为对刚刚输入的每一个channel分析出了一个权重关系。也就是如果他觉得比较重要的channel就会赋予一个比较大的权重,而如果是没有那么重要的channel就会赋予一个比较小的权重。
过程可以用下图来理解
3.MobilenetV3的性能统计
更准确,更高效,参数量更少,实时性更高

准确度也更高

模型的大小,可以看见MobileNetV3_Small版本要远比v1,v2的要小,但是准确度同样的会下降一点。

4.MobilenetV3的pytorch实现
给出了MobilenetV3-large 和MobilenetV3-small两个版本,分别针对高资源用例和低资源用例,结构如下图:
MobilenetV3-large

MobilenetV3-small

分析:
- 第一列Input代表mobilenetV3每个特征层的shape变化;
- 第二列Operator代表每次特征层即将经历的block结构,我们可以看到在MobileNetV3中,特征提取经过了许多的bneck结构;
- 第三、四列分别代表了bneck内逆残差结构上升后的通道数、输入到bneck时特征层的通道数。
- 第五列SE代表了是否在这一层引入注意力机制。
- 第六列NL代表了激活函数的种类,HS代表h-swish,RE代表RELU。
- 第七列s代表了每一次block结构所用的步长。
参考代码:
import torch
import torch.nn as nn
import torchvision
num_class = 5
# 定义h-swith激活函数
class HardSwish(nn.Module):
def __init__(self, inplace=True):
super(HardSwish, self).__init__()
self.relu6 = nn.ReLU6(inplace)
def forward(self, x):
return x*self.relu6(x+3)/6
# DW卷积
def ConvBNActivation(in_channels,out_channels,kernel_size,stride,activate):
# 通过设置padding达到当stride=2时,hw减半的效果。此时不与kernel_size有关,所实现的公式为: padding=(kernel_size-1)//2
# 当kernel_size=3,padding=1时: stride=2 hw减半, stride=1 hw不变
# 当kernel_size=5,padding=2时: stride=2 hw减半, stride=1 hw不变
# 从而达到了使用 stride 来控制hw的效果, 不用去关心kernel_size的大小,控制单一变量
return nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=kernel_size, stride=stride, padding=(kernel_size-1)//2, groups=in_channels),
nn.BatchNorm2d(out_channels),
nn.ReLU6(inplace=True) if activate == 'relu' else HardSwish()
)
# PW卷积(接全连接层)
def Conv1x1BN(in_channels,out_channels):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1),
nn.BatchNorm2d(out_channels)
)
# 普通的1x1卷积
def Conv1x1BNActivation(in_channels,out_channels,activate):
return nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1, stride=1),
nn.BatchNorm2d(out_channels),
nn.ReLU6(inplace=True) if activate == 'relu' else HardSwish()
)
# 注意力机制(SE模块)
class SqueezeAndExcite(nn.Module):
def __init__(self, in_channels, out_channels, se_kernel_size, divide=4):
super(SqueezeAndExcite, self).__init__()
mid_channels = in_channels // divide # 维度变为原来的1/4
# 将当前的channel平均池化成1
self.pool = nn.AvgPool2d(kernel_size=se_kernel_size,stride=1)
# 两个全连接层 最后输出每层channel的权值
self.SEblock = nn.Sequential(
nn.Linear(in_features=in_channels, out_features=mid_channels),
nn.ReLU6(inplace=True),
nn.Linear(in_features=mid_channels, out_features=out_channels),
HardSwish(inplace=True),
)
def forward(self, x):
b, c, h, w = x.size()
out = self.pool(x) # 不管当前的 h,w 为多少, 全部池化为1
out = out.view(b, -1) # 打平处理,与全连接层相连
# 获取注意力机制后的权重
out = self.SEblock(out)
# out是每层channel的权重,需要扩维才能与原特征矩阵相乘
out = out.view(b, c, 1, 1) # 增维
return out * x
class SEInvertedBottleneck(nn.Module):
def __init__(self, in_channels, mid_channels, out_channels, kernel_size, stride, activate, use_se, se_kernel_size=1):
super(SEInvertedBottleneck, self).__init__()
self.stride = stride
self.use_se = use_se
self.in_channels = in_channels
self.out_channels = out_channels
# mid_channels = (in_channels * expansion_factor)
# 普通1x1卷积升维操作
self.conv = Conv1x1BNActivation(in_channels, mid_channels,activate)
# DW卷积 维度不变,但可通过stride改变尺寸 groups=in_channels
self.depth_conv = ConvBNActivation(mid_channels, mid_channels, kernel_size,stride,activate)
# 注意力机制的使用判断
if self.use_se:
self.SEblock = SqueezeAndExcite(mid_channels, mid_channels, se_kernel_size)
# PW卷积 降维操作
self.point_conv = Conv1x1BNActivation(mid_channels, out_channels,activate)
# shortcut的使用判断
if self.stride == 1:
self.shortcut = Conv1x1BN(in_channels, out_channels)
def forward(self, x):
# DW卷积
out = self.depth_conv(self.conv(x))
# 当 use_se=True 时使用注意力机制
if self.use_se:
out = self.SEblock(out)
# PW卷积
out = self.point_conv(out)
# 残差操作
# 第一种: 只看步长,步长相同shape不一样的输入输出使用1x1卷积使其相加
# out = (out + self.shortcut(x)) if self.stride == 1 else out
# 第二种: 同时满足步长与输入输出的channel, 不使用1x1卷积强行升维
out = (out + x) if self.stride == 1 and self.in_channels == self.out_channels else out
return out
class MobileNetV3(nn.Module):
def __init__(self, num_classes=num_class, type='large'):
super(MobileNetV3, self).__init__()
self.type = type
# 224x224x3 conv2d 3 -> 16 SE=False HS s=2
self.first_conv = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=2, padding=1),
nn.BatchNorm2d(16),
HardSwish(inplace=True),
)
# torch.Size([1, 16, 112, 112])
# MobileNetV3_Large 网络结构
if type=='large':
self.large_bottleneck = nn.Sequential(
# torch.Size([1, 16, 112, 112]) 16 -> 16 -> 16 SE=False RE s=1
SEInvertedBottleneck(in_channels=16, mid_channels=16, out_channels=16, kernel_size=3, stride=1,activate='relu', use_se=False),
# torch.Size([1, 16, 112, 112]) 16 -> 64 -> 24 SE=False RE s=2
SEInvertedBottleneck(in_channels=16, mid_channels=64, out_channels=24, kernel_size=3, stride=2, activate='relu', use_se=False),
# torch.Size([1, 24, 56, 56]) 24 -> 72 -> 24 SE=False RE s=1
SEInvertedBottleneck(in_channels=24, mid_channels=72, out_channels=24, kernel_size=3, stride=1, activate='relu', use_se=False),
# torch.Size([1, 24, 56, 56]) 24 -> 72 -> 40 SE=True RE s=2
SEInvertedBottleneck(in_channels=24, mid_channels=72, out_channels=40, kernel_size=5, stride=2,activate='relu', use_se=True, se_kernel_size=28),
# torch.Size([1, 40, 28, 28]) 40 -> 120 -> 40 SE=True RE s=1
SEInvertedBottleneck(in_channels=40, mid_channels=120, out_channels=40, kernel_size=5, stride=1,activate='relu', use_se=True, se_kernel_size=28),
# torch.Size([1, 40, 28, 28]) 40 -> 120 -> 40 SE=True RE s=1
SEInvertedBottleneck(in_channels=40, mid_channels=120, out_channels=40, kernel_size=5, stride=1,activate='relu', use_se=True, se_kernel_size=28),
# torch.Size([1, 40, 28, 28]) 40 -> 240 -> 80 SE=False HS s=1
SEInvertedBottleneck(in_channels=40, mid_channels=240, out_channels=80, kernel_size=3, stride=1,activate='hswish', use_se=False),
# torch.Size([1, 80, 28, 28]) 80 -> 200 -> 80 SE=False HS s=1
SEInvertedBottleneck(in_channels=80, mid_channels=200, out_channels=80, kernel_size=3, stride=1,activate='hswish', use_se=False),
# torch.Size([1, 80, 28, 28]) 80 -> 184 -> 80 SE=False HS s=2
SEInvertedBottleneck(in_channels=80, mid_channels=184, out_channels=80, kernel_size=3, stride=2,activate='hswish', use_se=False),
# torch.Size([1, 80, 14, 14]) 80 -> 184 -> 80 SE=False HS s=1
SEInvertedBottleneck(in_channels=80, mid_channels=184, out_channels=80, kernel_size=3, stride=1,activate='hswish', use_se=False),
# torch.Size([1, 80, 14, 14]) 80 -> 480 -> 112 SE=True HS s=1
SEInvertedBottleneck(in_channels=80, mid_channels=480, out_channels=112, kernel_size=3, stride=1,activate='hswish', use_se=True, se_kernel_size=14),
# torch.Size([1, 112, 14, 14]) 112 -> 672 -> 112 SE=True HS s=1
SEInvertedBottleneck(in_channels=112, mid_channels=672, out_channels=112, kernel_size=3, stride=1,activate='hswish', use_se=True, se_kernel_size=14),
# torch.Size([1, 112, 14, 14]) 112 -> 672 -> 160 SE=True HS s=2
SEInvertedBottleneck(in_channels=112, mid_channels=672, out_channels=160, kernel_size=5, stride=2,activate='hswish', use_se=True,se_kernel_size=7),
# torch.Size([1, 160, 7, 7]) 160 -> 960 -> 160 SE=True HS s=1
SEInvertedBottleneck(in_channels=160, mid_channels=960, out_channels=160, kernel_size=5, stride=1,activate='hswish', use_se=True,se_kernel_size=7),
# torch.Size([1, 160, 7, 7]) 160 -> 960 -> 160 SE=True HS s=1
SEInvertedBottleneck(in_channels=160, mid_channels=960, out_channels=160, kernel_size=5, stride=1,activate='hswish', use_se=True,se_kernel_size=7),
)
# torch.Size([1, 160, 7, 7])
# 相比MobileNetV2,尾部结构改变,,变得更加的高效
self.large_last_stage = nn.Sequential(
nn.Conv2d(in_channels=160, out_channels=960, kernel_size=1, stride=1),
nn.BatchNorm2d(960),
HardSwish(inplace=True),
nn.AvgPool2d(kernel_size=7, stride=1),
nn.Conv2d(in_channels=960, out_channels=1280, kernel_size=1, stride=1),
HardSwish(inplace=True),
)
# MobileNetV3_Small 网络结构
if type=='small':
self.small_bottleneck = nn.Sequential(
# torch.Size([1, 16, 112, 112]) 16 -> 16 -> 16 SE=False RE s=2
SEInvertedBottleneck(in_channels=16, mid_channels=16, out_channels=16, kernel_size=3, stride=2,activate='relu', use_se=True, se_kernel_size=56),
# torch.Size([1, 16, 56, 56]) 16 -> 72 -> 24 SE=False RE s=2
SEInvertedBottleneck(in_channels=16, mid_channels=72, out_channels=24, kernel_size=3, stride=2,activate='relu', use_se=False),
# torch.Size([1, 24, 28, 28]) 24 -> 88 -> 24 SE=False RE s=1
SEInvertedBottleneck(in_channels=24, mid_channels=88, out_channels=24, kernel_size=3, stride=1,activate='relu', use_se=False),
# torch.Size([1, 24, 28, 28]) 24 -> 96 -> 40 SE=True RE s=2
SEInvertedBottleneck(in_channels=24, mid_channels=96, out_channels=40, kernel_size=5, stride=2,activate='hswish', use_se=True, se_kernel_size=14),
# torch.Size([1, 40, 14, 14]) 40 -> 240 -> 40 SE=True RE s=1
SEInvertedBottleneck(in_channels=40, mid_channels=240, out_channels=40, kernel_size=5, stride=1,activate='hswish', use_se=True, se_kernel_size=14),
# torch.Size([1, 40, 14, 14]) 40 -> 240 -> 40 SE=True RE s=1
SEInvertedBottleneck(in_channels=40, mid_channels=240, out_channels=40, kernel_size=5, stride=1,activate='hswish', use_se=True, se_kernel_size=14),
# torch.Size([1, 40, 14, 14]) 40 -> 120 -> 48 SE=True RE s=1
SEInvertedBottleneck(in_channels=40, mid_channels=120, out_channels=48, kernel_size=5, stride=1,activate='hswish', use_se=True, se_kernel_size=14),
# torch.Size([1, 48, 14, 14]) 48 -> 144 -> 48 SE=True RE s=1
SEInvertedBottleneck(in_channels=48, mid_channels=144, out_channels=48, kernel_size=5, stride=1,activate='hswish', use_se=True, se_kernel_size=14),
# torch.Size([1, 48, 14, 14]) 48 -> 288 -> 96 SE=True RE s=2
SEInvertedBottleneck(in_channels=48, mid_channels=288, out_channels=96, kernel_size=5, stride=2,activate='hswish', use_se=True, se_kernel_size=7),
# torch.Size([1, 96, 7, 7]) 96 -> 576 -> 96 SE=True RE s=1
SEInvertedBottleneck(in_channels=96, mid_channels=576, out_channels=96, kernel_size=5, stride=1,activate='hswish', use_se=True, se_kernel_size=7),
# torch.Size([1, 96, 7, 7]) 96 -> 576 -> 96 SE=True RE s=1
SEInvertedBottleneck(in_channels=96, mid_channels=576, out_channels=96, kernel_size=5, stride=1,activate='hswish', use_se=True, se_kernel_size=7),
)
# torch.Size([1, 96, 7, 7])
# 相比MobileNetV2,尾部结构改变,,变得更加的高效
self.small_last_stage = nn.Sequential(
nn.Conv2d(in_channels=96, out_channels=576, kernel_size=1, stride=1),
nn.BatchNorm2d(576),
HardSwish(inplace=True),
nn.AvgPool2d(kernel_size=7, stride=1),
nn.Conv2d(in_channels=576, out_channels=1280, kernel_size=1, stride=1),
HardSwish(inplace=True),
)
self.classifier = nn.Linear(in_features=1280,out_features=num_classes)
self.init_params()
# 初始化权重
def init_params(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d) or isinstance(m, nn.Linear):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.first_conv(x) # torch.Size([1, 16, 112, 112])
if self.type == 'large':
x = self.large_bottleneck(x) # torch.Size([1, 160, 7, 7])
x = self.large_last_stage(x) # torch.Size([1, 1280, 1, 1])
if self.type == 'small':
x = self.small_bottleneck(x) # torch.Size([1, 96, 7, 7])
x = self.small_last_stage(x) # torch.Size([1, 1280, 1, 1])
x = x.view(x.size(0), -1) # torch.Size([1, 1280])
x = self.classifier(x) # torch.Size([1, 5])
return x
if __name__ == '__main__':
# model = MobileNetV3(type='small')
model = MobileNetV3(type='large')
# print(model)
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)
torch.save(model.state_dict(), 'MobileNetV3_Large.mdl')
参考:
https://blog.csdn.net/c2250645962/article/details/105434036
https://blog.csdn.net/weixin_44791964/article/details/104068321