代码下载:原理讲解-项目实战 <-> MobileNet模型的讲解和训练
上次给大家讲解利用Mtcnn+MobileNet整体实现口罩识别的原理和训练,Mtcnn用于实现人脸检测,而MobileNet用于在检测到人脸之后判断是否佩戴口罩,这期给大奖详细讲解MobileNet模型的原理结构和训练过程,文末获取源代码,上次忘记了
口罩识别:原理讲解-项目实战<->Mtcnn+Mobilent实现人脸口罩检测
文章目录
一、什么是MobileNet
二、MobileNet模型的构建和预训练模型测试
三、MobileNet模型的训练
四、代码下载和环境设置
一、什么是MobileNet模型
MobileNet模型是Google针对手机等嵌入式设备提出的一种轻量级的深层神经网络,其使用的核心思想是深度可分离卷积deepthwise separable convolution,深度可分离卷积由:DW(deepth wise)和PW(pointwise)两个部分结合起来,用来提取特征feature map,相比常规的卷积操作,其参数数量和运算成本低,其轻量表现在使用深度可分离卷积的方式大量减少了模型的参数。
【1】什么是深度可分离卷积?为什么深度可分离卷积嫩减少参数量?
1.常规卷积操作
对于一张5 x 5 像素、三通道(shape为 5 x 5 x 3),经过3 x3 卷积核的卷积层(假设卷积核的个数为4,即过滤器的个数为4),则卷积核(过滤器)的shape为3 x 3 x 3 x 4,最终输出4个Feature Map

卷积层总共有4个3 x 3卷积核(过滤器),每个卷积核是3通道(卷积核的通道数必须和输入的通道数一致),大小为3 x 3,即每个卷积核的shape为3 x 3 x 3,因此卷积层的参数为 N_std= 3*3*3*4= 108
2.深度可分离卷积(DW+PW)
第一步:DW——Deepthwise Convolution的一个卷积核负责一个通道,一个通道只被一个卷积核卷积
一张5×5像素、三通道彩色输入图片(shape为5×5×3),Depthwise Convolution首先经过第一次卷积运算,DW完全是在二维平面内进行。卷积核的数量与上一层的通道数相同(卷积核(过滤器)的个数和上一层的通道数一一对应)。所以一个三通道的图像经过运算后生成了3个Feature map(如果有same padding则尺寸与输入层相同为5×5)
如下图所示:
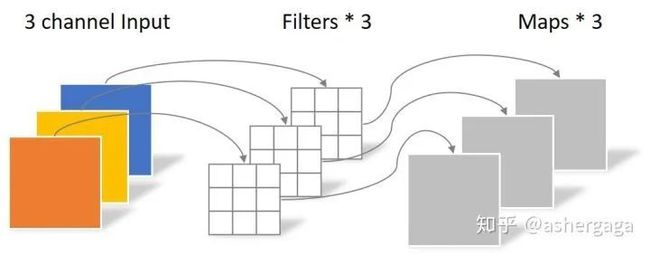
这里的一个卷积核只有一个通道数,即一个卷积核的shape为3x3x1,总共有3个卷积核(过滤器) 因此卷积层的参数个数为:
N_depthwise = 3 × 3 × 3 = 27
DW(Depthwise Convolution )完成后的特征层Feature map 数量和输入层的通道数相同,因此无法扩展Feature map,这种运算对输入层的每个通道独立进行卷积运算,没有有效的利用不同通道在相同空间位置上的feature信息,所以需要使用PW(Poiintwise Convolution)来将这些Feature map进行组合生成新的Feature map。
第二步:PW(逐点卷积)——Pointwise Convolution
Pointwise Convolution的运算与常规卷积运算非常相似,它的卷积核的尺寸为 1×1×M,M为上一层的通道数。这里的卷积运算会将DW计算得到的特征层Feature map在深度方向上进行加权组合,生成新的Feature map,卷积层有几个卷积核就有几个输出的特征层Feature map

这里的Pointwise采用的是1x1卷积的方式,卷积层的参数个数:
N_pointwise = 1 × 1 × 3 × 4 = 12
经过Pointwise Convolution之后,最后同样输出了4张Feature map, 与我们直接用常规卷积最终的输出维度相同。
深度可分离卷积最终使用的参数个数:
N_separable = N_depthwise + N_pointwise = 39
而常规卷积操作需要的参数N_std= 3*3*3*4 = 108
总结:相同的输入,同样是得到4张Feature map,Separable Convolution的参数个数是常规卷积的约1/3。因此,在参数量相同的前提下,采用Separable Convolution的神经网络层数可以做的更深。
【2】深度可分离卷积结构
深度可分离卷积结构= DW + PW
在DW结构中,卷积核(过滤器)的个数是与输入的通道数一致,在DW卷积计算时,每个通道得到对应的一个特征层。

深度可分离卷积结构的代码实现
在建立模型的时候,可以使用Keras中的DepthwiseConv2D层实现深度可分离卷积,然后再利用1x1卷积调整channels数,得到与常规卷积操作相同的通道数。通俗的理解是3x3的卷积核厚度只有一层,然后再输入张量上一层一层地滑动,每一次卷积完生成一个输出通道,当卷积完成后,再利用1x1的卷积调整厚度。
二、MobileNet模型的构建和预训练模型测试
【1】MobileNet网络结构
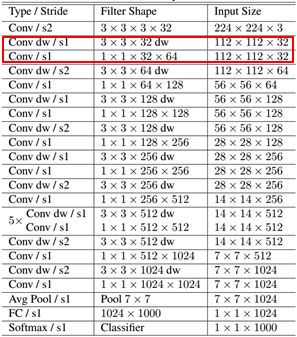
其中Conv dw 就是分层卷积(DW),其之后都会接一个1*1的卷积进行通道处理-PW。
【2】使用预训练模型MobileNet网络代码实现
import warnings
import numpy as np
from keras.preprocessing import image
from keras.models import Model
from keras.layers import DepthwiseConv2D,Input,Activation,Dropout,Reshape,BatchNormalization,GlobalAveragePooling2D,GlobalMaxPooling2D,Conv2D
from keras.applications.imagenet_utils import decode_predictions
from keras import backend as K
def MobileNet(input_shape=[224,224,3],
depth_multiplier=1,
dropout=1e-3,
classes=1000):
img_input = Input(shape=input_shape)
# 224,224,3 -> 112,112,32
x = _conv_block(img_input, 32, strides=(2, 2))
# 112,112,32 -> 112,112,64
x = _depthwise_conv_block(x, 64, depth_multiplier, block_id=1)
# 112,112,64 -> 56,56,128
x = _depthwise_conv_block(x, 128, depth_multiplier,
strides=(2, 2), block_id=2)
# 56,56,128 -> 56,56,128
x = _depthwise_conv_block(x, 128, depth_multiplier, block_id=3)
# 56,56,128 -> 28,28,256
x = _depthwise_conv_block(x, 256, depth_multiplier,
strides=(2, 2), block_id=4)
# 28,28,256 -> 28,28,256
x = _depthwise_conv_block(x, 256, depth_multiplier, block_id=5)
# 28,28,256 -> 14,14,512
x = _depthwise_conv_block(x, 512, depth_multiplier,
strides=(2, 2), block_id=6)
# 14,14,512 -> 14,14,512
x = _depthwise_conv_block(x, 512, depth_multiplier, block_id=7)
x = _depthwise_conv_block(x, 512, depth_multiplier, block_id=8)
x = _depthwise_conv_block(x, 512, depth_multiplier, block_id=9)
x = _depthwise_conv_block(x, 512, depth_multiplier, block_id=10)
x = _depthwise_conv_block(x, 512, depth_multiplier, block_id=11)
# 14,14,512 -> 7,7,1024
x = _depthwise_conv_block(x, 1024, depth_multiplier,
strides=(2, 2), block_id=12)
x = _depthwise_conv_block(x, 1024, depth_multiplier, block_id=13)
# 7,7,1024 平均池化-> 1,1,1024
# 7x7x1024
# 1024
# mobilenet中用平均池化代替VGG中的全连接层
# 因为VGG参数量大,平均池化没有什么参数量
x = GlobalAveragePooling2D()(x)
x = Reshape((1, 1, 1024), name='reshape_1')(x) #卷积层结构(1,1,1024),不是全连接层结构
# 使一些神经元失效dropout,防止过拟合
x = Dropout(dropout, name='dropout')(x)
# 映射到10000个classes数量上 1024*2
x = Conv2D(classes, (1, 1),padding='same', name='conv_preds')(x)
# softmax计算每一个类的概率
x = Activation('softmax', name='act_softmax')(x)
x = Reshape((classes,), name='reshape_2')(x)
inputs = img_input
model = Model(inputs, x, name='mobilenet_1_0_224_tf')
# 测试Mobilenet
# 使用预训练模型进行测试
model_name = 'D:\Project\mask-recognize-master\model_data\mobilenet_1_0_224_tf.h5'
# 载入模型参数
model.load_weights(model_name)
return model
def _conv_block(inputs, filters, kernel=(3, 3), strides=(1, 1)):
x = Conv2D(filters, kernel,
padding='same',
use_bias=False,
strides=strides,
name='conv1')(inputs)
x = BatchNormalization(name='conv1_bn')(x)
return Activation(relu6, name='conv1_relu')(x)
def _depthwise_conv_block(inputs, pointwise_conv_filters,
depth_multiplier=1, strides=(1, 1), block_id=1):
x = DepthwiseConv2D((3, 3),
padding='same',
depth_multiplier=depth_multiplier,
strides=strides,
use_bias=False,
name='conv_dw_%d' % block_id)(inputs)
x = BatchNormalization(name='conv_dw_%d_bn' % block_id)(x)
x = Activation(relu6, name='conv_dw_%d_relu' % block_id)(x)
x = Conv2D(pointwise_conv_filters, (1, 1),
padding='same',
use_bias=False,
strides=(1, 1),
name='conv_pw_%d' % block_id)(x)
x = BatchNormalization(name='conv_pw_%d_bn' % block_id)(x)
return Activation(relu6, name='conv_pw_%d_relu' % block_id)(x)
def relu6(x):
return K.relu(x, max_value=6)
使用的预训练权重为:

【3】MobileNet图片预测
建立网络之后,我们可以使用以下代码进行预测:
def preprocess_input(x):
x /= 255.
x -= 0.5
x *= 2.
return x
if __name__ == '__main__':
model = MobileNet(input_shape=(224, 224, 3))
# model.summary()
img_path = 'D:\\Project\\mask-recognize-master\\test_data\\1.jpg'
img = image.load_img(img_path, target_size=(224, 224))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
x = preprocess_input(x)
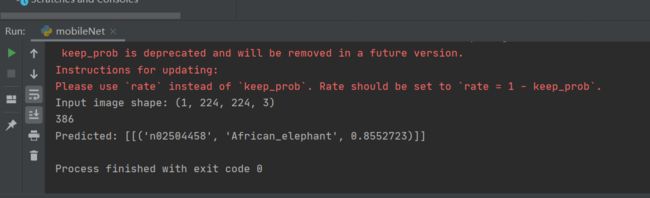
print('Input image shape:', x.shape)
preds = model.predict(x)
print(np.argmax(preds))
print('Predicted:', decode_predictions(preds, 1))
测试图片

测试结果
三、MobileNet模型的训练
【1】MobileNet网络结构
import warnings
import numpy as np
from keras.preprocessing import image
from keras.models import Model
from keras.layers import DepthwiseConv2D,Input,Activation,Dropout,Reshape,BatchNormalization,GlobalAveragePooling2D,GlobalMaxPooling2D,Conv2D
from keras.applications.imagenet_utils import decode_predictions
from keras import backend as K
def MobileNet(input_shape=[224,224,3],
depth_multiplier=1,
dropout=1e-3,
classes=1000):
img_input = Input(shape=input_shape)
# 224,224,3 -> 112,112,32
x = _conv_block(img_input, 32, strides=(2, 2))
# 112,112,32 -> 112,112,64
x = _depthwise_conv_block(x, 64, depth_multiplier, block_id=1)
# 112,112,64 -> 56,56,128
x = _depthwise_conv_block(x, 128, depth_multiplier,
strides=(2, 2), block_id=2)
# 56,56,128 -> 56,56,128
x = _depthwise_conv_block(x, 128, depth_multiplier, block_id=3)
# 56,56,128 -> 28,28,256
x = _depthwise_conv_block(x, 256, depth_multiplier,
strides=(2, 2), block_id=4)
# 28,28,256 -> 28,28,256
x = _depthwise_conv_block(x, 256, depth_multiplier, block_id=5)
# 28,28,256 -> 14,14,512
x = _depthwise_conv_block(x, 512, depth_multiplier,
strides=(2, 2), block_id=6)
# 14,14,512 -> 14,14,512
x = _depthwise_conv_block(x, 512, depth_multiplier, block_id=7)
x = _depthwise_conv_block(x, 512, depth_multiplier, block_id=8)
x = _depthwise_conv_block(x, 512, depth_multiplier, block_id=9)
x = _depthwise_conv_block(x, 512, depth_multiplier, block_id=10)
x = _depthwise_conv_block(x, 512, depth_multiplier, block_id=11)
# 14,14,512 -> 7,7,1024
x = _depthwise_conv_block(x, 1024, depth_multiplier,
strides=(2, 2), block_id=12)
x = _depthwise_conv_block(x, 1024, depth_multiplier, block_id=13)
# 7,7,1024 平均池化-> 1,1,1024
# 7x7x1024
# 1024
# mobilenet中用平均池化代替VGG中的全连接层
# 因为VGG参数量大,平均池化没有什么参数量
x = GlobalAveragePooling2D()(x)
x = Reshape((1, 1, 1024), name='reshape_1')(x)
#卷积层结构(1,1,1024),不是全连接层结构
# 使一些神经元失效dropout,防止过拟合
x = Dropout(dropout, name='dropout')(x)
# 映射到10000个classes数量上 1024*2
x = Conv2D(classes, (1, 1),padding='same', name='conv_preds')(x)
# softmax计算每一个类的概率
x = Activation('softmax', name='act_softmax')(x)
x = Reshape((classes,), name='reshape_2')(x)
inputs = img_input
model = Model(inputs, x, name='mobilenet_1_0_224_tf')
# 注意这里测试和训练用到的预训练权重不一样,这和你实际应用有关,在进行训练MobileNet时,将这里红字部分注销掉
# # 测试Mobilenet
# #测试时使用预训练权重
# model_name = 'D:\Project\mask-recognize-master\model_data\mobilenet_1_0_224_tf.h5'
# # 载入模型参数
# model.load_weights(model_name)
return model
def _conv_block(inputs, filters, kernel=(3, 3), strides=(1, 1)):
x = Conv2D(filters, kernel,
padding='same',
use_bias=False,
strides=strides,
name='conv1')(inputs)
x = BatchNormalization(name='conv1_bn')(x)
return Activation(relu6, name='conv1_relu')(x)
def _depthwise_conv_block(inputs, pointwise_conv_filters,
depth_multiplier=1, strides=(1, 1), block_id=1):
x = DepthwiseConv2D((3, 3),
padding='same',
depth_multiplier=depth_multiplier,
strides=strides,
use_bias=False,
name='conv_dw_%d' % block_id)(inputs)
x = BatchNormalization(name='conv_dw_%d_bn' % block_id)(x)
x = Activation(relu6, name='conv_dw_%d_relu' % block_id)(x)
x = Conv2D(pointwise_conv_filters, (1, 1),
padding='same',
use_bias=False,
strides=(1, 1),
name='conv_pw_%d' % block_id)(x)
x = BatchNormalization(name='conv_pw_%d_bn' % block_id)(x)
return Activation(relu6, name='conv_pw_%d_relu' % block_id)(x)
def relu6(x):
return K.relu(x, max_value=6)
def preprocess_input(x):
x /= 255.
x -= 0.5
x *= 2.
return x
用自己的数据集训练使用的预训练权重为红色标记,Pnet、Rnet、Onet的权重是Mtcnn人脸检测模型的预训练权重

【2】MobileNet训练部分
from keras.callbacks import TensorBoard, ModelCheckpoint, ReduceLROnPlateau, EarlyStopping
from keras.applications.imagenet_utils import preprocess_input
from keras.utils import np_utils,get_file
from keras.optimizers import Adam
from keras import backend as K
from utils.utils import get_random_data
from net.mobileNet import MobileNet
from PIL import Image
import numpy as np
import cv2
K.set_image_dim_ordering('tf')
# 网上下载mobilent的预训练权重,这里我下好了放在model_data里面
# BASE_WEIGHT_PATH = ('https://github.com/fchollet/deep-learning-models/'
#'releases/download/v0.6/')
HEIGHT = 160
WIDTH = 160
NUM_CLASSES = 2 # 分2类,一类带口罩,一类不带口罩
# 加灰条
def letterbox_image(image, size):
iw, ih = image.size
w, h = size
scale = min(w/iw, h/ih)
nw = int(iw*scale)
nh = int(ih*scale)
image = image.resize((nw,nh), Image.BICUBIC)
new_image = Image.new('RGB', size, (0,0,0))
new_image.paste(image, ((w-nw)//2, (h-nh)//2))
return new_image
# 对数据集的图片进行数据预处理
# # 图片归一化和其标签处理完之后就可以传入到模型中进行训练了
def generate_arrays_from_file(lines,batch_size,train):
# 获取总长度,即训练集中总共多少张图片
n = len(lines)
i = 0
while 1:
X_train = []
Y_train = []
# 获取一个batch_size大小的数据,也就是8张图片
for b in range(batch_size):
if i==0:
# i=0说明已经经过一个世代循环了,也就是之前取出的8张图片已经训练完了,需要把数据进行一个打乱
np.random.shuffle(lines)
name = lines[i].split(';')[0]
# 从文件中读取图像
img = Image.open(r".\data\image\train" + '/' + name)
if train == True:
# 图像数据增强get_random_data,让网络变得更加有鲁棒性
img = np.array(get_random_data(img,[HEIGHT,WIDTH]),dtype = np.float64) # 生成训练数据
else:
# 不失真的情况下改变(resize)我们输入图片的大小(长和宽)为模型输入的要求
img = np.array(letterbox_image(img,[HEIGHT,WIDTH]),dtype = np.float64) # 生成验证数据
# 将这张增强后的图片数据保存到X_train里面
X_train.append(img)
# 对这张图片的标签进行处理
Y_train.append(lines[i].split(';')[1])
# 读完一个周期后重新开始
i = (i+1) % n
# 处理图像,图像的归一化
X_train = preprocess_input(np.array(X_train).reshape(-1,HEIGHT,WIDTH,3))
# 对图片的标签进行处理,转换成one_hot的形式
Y_train = np_utils.to_categorical(np.array(Y_train),num_classes= NUM_CLASSES)
yield (X_train, Y_train) # 图片归一化和其标签处理完之后就可以传入到模型中进行训练了
if __name__ == "__main__":
# 设置模型保存的位置
log_dir = "./logs/"
# 打开数据集的txt
with open(r".\data\train.txt","r") as f:
lines = f.readlines()
# 打乱行shuffle,这个txt主要用于帮助读取数据来训练
# 打乱的数据更有利于训练
np.random.seed(10101)
np.random.shuffle(lines)
np.random.seed(None)
# 划分验证集和数据集
# 90%用于训练,10%用于估计。
num_val = int(len(lines)*0.1)
num_train = len(lines) - num_val
# 数据的预处理
# 图片的归一化处理,标签的预处理,在后面的generate_arrays_from_file函数
# 建立MobileNet模型 输入:160*160*3的图片
model = MobileNet(input_shape=[HEIGHT,WIDTH,3],classes=NUM_CLASSES)
# 去网上下载Mobilent的预训练权重,这里使用我下载好了的权重
# model_name = 'mobilenet_1_0_224_tf_no_top.h5'
# weight_path = BASE_WEIGHT_PATH + model_name
# weights_path = get_file(model_name, weight_path, cache_subdir='models')
#注意这里测试和训练用到的预训练权重不一样,这和你实际应用有关
#训练时用的预训练权重
weights_path = "D:\Project\mask-recognize-master\model_data\mobilenet_1_0_224_tf_no_top.h5"
model.load_weights(weights_path,by_name=True)
# 保存模型权重的方式,3世代保存一次
checkpoint_period1 = ModelCheckpoint(
log_dir + 'ep{epoch:03d}-loss{loss:.3f}-val_loss{val_loss:.3f}.h5',
monitor='acc',
save_weights_only=False,
save_best_only=True,
period=3
)
# 学习率下降的方式,acc精确度三次不下降就下降学习率继续训练
reduce_lr = ReduceLROnPlateau(
monitor='acc',
factor=0.5,
patience=3,
verbose=1
)
# 是否需要早停,当连续10个世代val_loss一直不下降的时候意味着模型基本训练完毕,可以停止
early_stopping = EarlyStopping(
monitor='val_loss',
min_delta=0,
patience=10,
verbose=1
)
# 定义训练的loss函数和优化器
# 交叉熵,这里学习率较高,是比较粗略的训练
model.compile(loss = 'categorical_crossentropy',
optimizer = Adam(lr=1e-3),
metrics = ['accuracy'])
# 一次的训练集大小
# 一次训练传入8张图片,可根据自己电脑的配置来调
batch_size = 16
# 正式开始训练
model.fit_generator(generate_arrays_from_file(lines[:num_train], batch_size, True), # 训练trains数据
steps_per_epoch=max(1, num_train//batch_size),
validation_data=generate_arrays_from_file(lines[num_train:], batch_size, False), # 训练val数据
validation_steps=max(1, num_val // batch_size),
epochs=10,
initial_epoch=0,
callbacks=[checkpoint_period1, reduce_lr])
model.save_weights(log_dir+'middle_one.h5')
# 交叉熵,梯度下降反向传播
# 这里的学习率比较低1e-4是比较的精确的训练,但是这里进行粗略的训练就有一个比较好的检测效果
# 这里训练的比较快,因为网络输入比较小时160*160,训练3个世代,验证集的loss非常小,准确率acc比较高,这是归功于数据增强的功能,数据增强函数让整个网络变得更加具有鲁棒性了
model.compile(loss = 'categorical_crossentropy',
optimizer = Adam(lr=1e-4),
metrics = ['accuracy'])
# 开始训练
model.fit_generator(generate_arrays_from_file(lines[:num_train], batch_size, True),
steps_per_epoch=max(1, num_train//batch_size),
validation_data=generate_arrays_from_file(lines[num_train:], batch_size, False),
validation_steps=max(1, num_val//batch_size),
epochs=20,
initial_epoch=10,
callbacks=[checkpoint_period1, reduce_lr])
model.save_weights(log_dir+'last_one.h5')
这里使用Mtcnn+Mobilenet进行口罩的识别训练集,如下所示:
首先将我们的训练图片存放在data/image/train文件夹下,图片的命名形式为图片中人戴口罩了则命名为mask_x.jpg,没有佩戴口罩则命名为nomask_x.jpg,利用图片的名字就可以对我们的图片的类型进行判断,每一张图片的大小为Mobilenet模型输入的大小160*160。具体如下所示,下面的图片都是经过人脸对齐了的:

然后利用data/image/Gnerate_TrainTxT.py文件将训练图片生成为模型训练格式的数据集,以train.txt形式保存,如下所示:

利用Gnerate_TrainTxT.py生成的train.txt, 可以看到训练集中的每张训练图片之间以行隔开,每一行代表一张训练图片,每一行的“ ; ”前面是我们事先命名图片的名字,“ ; ”后面是指这张图片所属的标签, mask的标签是:0,nomask的标签是:1 。训练的时候就会读取train.txt的每一行,获得每一张图片和其所属的标签。


记得将model_data文件夹下classes.txt修改为你想要的检测的类别

【3】MobileNet训练示例

训练过程中以及最后的的权重参数保存在logs文件夹下
Mtcnn+Mobilenet口罩识别结果展示:

四、代码下载和环境设置
代码下载,回复:项目实战,即可获取。
环境
-
python==3.6
-
tensorflow-gpu==1.13.1
-
keras==2.1.5
精彩推荐:
原理讲解-项目实战 <-> Mtcnn + Facenet 搭建人脸识别平台(中奖名单公示)
原理讲解-项目实战 <-> Keras搭建Mtcnn人脸检测平台
Yolov3算法实现社交距离安全检测项目讲解和实战(Social Distance Detector)
万字长文,用代码的思想讲解Yolo3算法实现原理,Visdrone数据集和自己制作数据集两种方式在Pytorch训练Yolo模型
