【AI全栈三】语音质量算法、评价指标 看一篇就够系列(附算法源码+干货)
文章目录
-
-
- 那么我们过去是怎么评价的?
- 客观评价-基于指标
- 客观评价-基于模型
- R&S®UPV音频分析仪
- 小结
- 那么我们现在用哪些评价方法呢?
-
- 基于深度学习的方法:AutoMOS, QualityNe, NISQA, MOSNet
- MOSNet(`absolute.mosnet`或`mosnet`)
- 语音质量的感知评估(Perceptual evaluation of speech quality, PESQ)
- 客观语音质量评估的单端方法P.563
-
- 预处理
- 特征参数提取
- 失真类型判决和结果映射
- 客观评价结果的映射模型
- NISQA: 无参考语音通信网络的语音质量
- 小结
-
- 噪声
- 解决方法
- 音频处理之回声消除及调试经验
- 2,调试
- 最后最后
-
- 语音增强噪声 及其评估方法
- 噪声类型
-
- 语音增强
- 总结
-
大家好,我是cv君,涉猎语音一段时间了,今天提笔浅述一下 语音的传输前后,质量如何过关,也就是说,怎么评价我们语音的质量,比如麦克风等声音设备等等。
我们在语音质量方面,有三种全局上的评价方法:有参考客观评价方法,有参考客观评价方法,主观评价方法。
那么我们细分到他的子类,就会有很多使用的算法与评价思路。
语音质量极其重要,能够让聊天的你我免受一些噪声的烦扰,能够让部队军方的通信更可靠,能够让每逢佳节倍思亲,与家人通电话时 重温那久违,真实,亲切的话语和音色。
那么我们过去是怎么评价的?
主观评价主要参照国家标准《YDT2309-2011音频质量主观测试方法》,国家标准主要也是参考国际标准 中的主观评价:ITU-R BS.1116-1997。国际标准中比较常用的有:ITU-T P800(电话传输系统语音质量主观评价)、ITU-T P830(电话宽带和宽带数字语音编解码器主观评价方法)、ITU-T P805 (对话质量主观评价)。

cv君到他们的官网找到了以前的评价方法,可是很全面的哦。
标准中的测试规则主要定义几点:
-
参考的标准音频和被测试音频间隔测试,连续重复4次;
-
音频源采用15~20s;
-
一次完整的测试时间不应超过15~20min;
-
测试成员:专家成员最少10人,非专家20人。
-
如果预先定义评分值,则不需要对单个评分值做归一化,否则需要归一化处理。
-
评分可以采用5分或者7分制。

图1 :YDT2309-2011 标准中的测试方法
评分标准
评分标准可以采用5分或者7分,预先定义好评分值,则不需要归一化处理。否则需要做归一化处理

图2 :YDT2309-2011评分标准
评价维度
国标里面针对音频主观判断的评价列举了很多的维度,这些维度需要根据实际的产品进行删减或者增加。
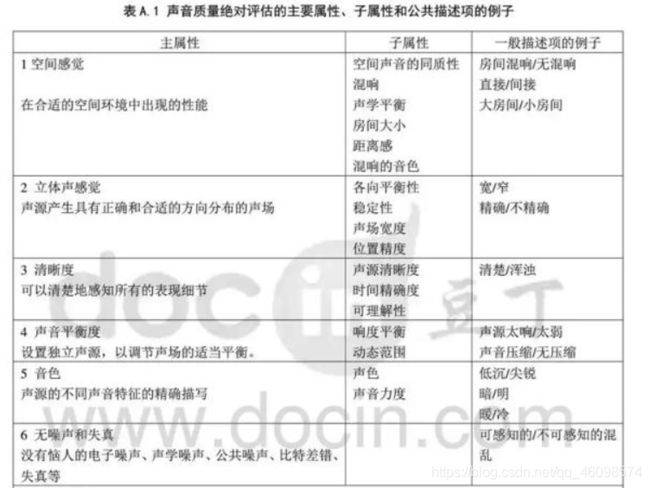
图3 :YDT2309-2011 评价维度

图4 :YDT2309-2011 评价维度
cv君认为 语音客观评价标准一般分为语音质量评价和语音可懂度评价,这里先介绍语音质量评价。提起语音质量评价,大家第一个想到的肯定是信噪比这个十分常用的评价标准以及它的相关衍生标准,这里总结一些常用的语音质量评价标准供大家参考和使用。
客观评价-基于指标
(一) 相关的标准
常见的音频测试的项目可以粗略的分类为:动态范围,频率响应、灵敏度,谐波失真,互调失真,信噪比,最大输入输出电平等。在目前应用广泛的音频标准中都是分别从不同的角度考察了音频常见产品的性能,现将分类如下:

客观评价-基于模型
(一) 背景及标准
刚刚cv君有说到客观评价 基于指标的方案,那么我么来看看基于模型的方案。最早的语音质量评测标准仅是基于无线指标的(RxQual),但实际语音在传输中会经过无线、传输、交换、路由等多个节点,任一环节出现问题都会导致用户语音感知差,仅仅考虑无线指标是无法发现和定位语音质量问题的,于是基于用户感知的语音质量评价方法逐渐成为用户语音服务质量评测的最主要标准。
常用的语音质量评价方法分为主观评价和客观评价。早期语音质量的评价方式是凭主观的,人们在打通电话之后通过人耳来感知语音质量的好坏。1996年国际ITU组织在ITU-T P.800和P.830建议书开始制订相关的评测标准:MOS(Mean Opinion Score)测试。它是一种主观测试方法,将用户接听和感知语音质量的行为进行调研和量化,由不同的调查用户分别对原始标准语音和经过无线网传播后的衰退声音进行主观感受对比,评出MOS分值,见表1。

注:对于GSM网络而言,评分在3以上即为比较好的语音质量。
不过显而易见,在现实中让一组人接听语音和评价语音质量是非常困难和昂贵的。因此,ITU组织推行了大量的端到端语音质量客观测试技术的标准化工作,发布了几种语音评估算法标准:PAMS、PSQM、PSQM +、MNB、PESQ。MOS评测开始摆脱原始的主观评估方式,而使用量化算法计算相对应的级别及语音质量好坏程度。
其中,P.862-PESQ(Perceptual Evaluation of Speech Quality)算法是ITU组织在2001年2月发布的目前最新的语音传输质量测量标准,由于其强大的功能和良好的相关性,它迅速成为目前最主流的语音评估算法。PESQ算法适用于评价各类端到端网络的语音质量,它综合考虑了感知中的各项影响因素(如编解码失真、错误、丢包、延时、抖动和过滤等)来客观地评价语音信号的质量,从而提供可以完全量化的语音质量衡量方法。
从PESQ算法模型的结构图(见图6)中可以看到整个算法的处理流程。参考信号和通过无线网络传输后的退化信号通过电平调整,再用输入滤波器模拟标准电话听筒进行滤波(FFT)。这两个信号在时间上对准,并通过听觉变换。这个变换包括对系统中线性滤波和增益变化的补偿和均衡,再通过认知模型,从而映射到对主观平均意见分的预测。一般情况下,输出信号和参照信号的差异性越大,计算出的MOS分值就越低。那么cv君说到这,大家可能有点迷茫,我们可以看看同济大学的这副图。
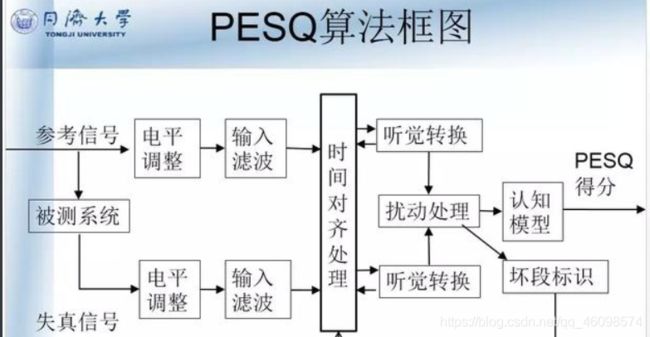
图6 :PESQ算法原理框图
PESQ作为ITU-P.862中推荐的语音评估最新算法,相对于PSQM和MNB只能用于窄带编解码测量,并且对某些类型的编解码、背景噪声和端到端的影响,比如滤波和时延变化只能给出不精确的预测值,它的算法模型能提供更好的相关性(见表2),能在更广泛的条件下对主观质量给出精确的预测,包括背景噪声、模拟滤波、时延变化等。
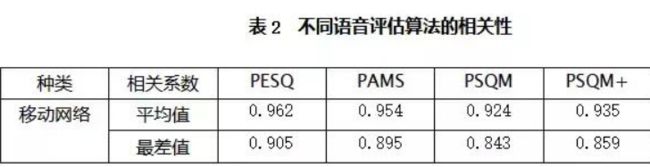
ITU-T相关的资料也已证明:PESQ能够给出非常精确的预测值,它适用于目前所知的所有移动通信技术,如GSM、CDMA、3G等,以及编码器语音质量的测量(AMR等)。可以说,PESQ是目前最为先进和准确的语音评估量化算法,由该算法得到的MOS评估结果最为切合用户的实际主观感受。
(二) 测试方法
Mos的客观评价主要基于模型和算法,模型可运行与独立的mos测试盒,或者使用带mos测试的音频分析仪器。
- 鼎利MOS路测系统
支持基于2G/3G的多款测试手机或商用手机进行基于PESQ的评估测试。Pioneer作为一个通用的综合测试平台,仅需增加单独的音频MOS盒配件,即可平滑升级到MOS测试功能,其结构图如下:


图7 Pioneer MOS测试结构图
Pioneer路测系统的主要功能分为两个方面:一方面是记录测试时的无线网络质量情况;另一方面,内置PESQ最新算法模块,实时计算MOS分值并录制退化声音文件,同时给出一些相关质量测试指标。
R&S®UPV音频分析仪
cv君认为这个名字不是很好念,R&S®UPV除了可以分析常规的音频指标,还可以分析基于模型的mos音频质量评价。



图9 罗德与施瓦茨公司具备mos测试的音频分析仪
小结
cv君写完了过去人们使用的语音评价方法,上文提供了三种不同的音频质量测试方法,有条件的公司可以三种方法都用上,但是,条件一般的公司,可以选择性的用1/2,1/3,2/3组合,甚至单纯其中一种。三种不同的方法总结如下:
- 基于主观判断:
基于主观的音频质量判断,主要依靠评审专家的人为试听。优点是成本较低,测试环境容易实现。缺点是:对评审专家的要求较高,并且离散型较大,样本数量不足,不适合大批量的生产测试。
- 基于客观指标判断:
基于客观指标的音频质量判断,主要依靠仪器的测试测量。优点是测试环境容易实现,参考标准统一,测试结果准确并且客观;缺点是参数指标是生硬的,并不能客观反映人的感受,就会出现,指标很好,但是音质不好的现象。
- 基于客观模型判断:
基于客观模型的音频质量判断,主要依靠仪器以及使用的算法模型。优点是:MOS评测开始摆脱原始的主观评估方式,而使用量化算法计算相对应的级别及语音质量好坏程度。PESQ算法适用于评价各类端到端网络的语音质量,它综合考虑了感知中的各项影响因素(如编解码失真、错误、丢包、延时、抖动和过滤等)来客观地评价语音信号的质量,从而提供可以完全量化的语音质量衡量方法。缺点是: MOS客观评价依赖模型和算法的成熟度及相关性,不同的模型标准不统一,客观性不如指标测试。
那么我们现在用哪些评价方法呢?
刚刚cv君说了很三种过去我们使用的语音评价方法,当然,现在也还有公司使用这些方法,经典还是可敬的,我们最近用哪些方法呢?我们一起来看看吧。
在实践中,有很多主观和客观的方法评价语音质量。主观方法就是通过人类对语音进行打分,比如MOS、CMOS和ABX Test。客观方法即是通过算法评测语音质量,在实时语音通话领域,这一问题研究较多,出现了诸如如PESQ和P.563这样的有参考和无参考的语音质量评价标准。在语音合成领域,研究的比较少,论文中常常通过展示频谱细节,计算MCD(mel cepstral distortion)等方法作为客观评价。所谓有参考和无参考质量评估,取决于该方法是否需要标准信号。有参考除了待评测信号,还需要一个音质优异的,没有损伤的参考信号;而无参考则不需要,直接根据待评估信号,给出质量评分。近些年也出现了MOSNet等基于深度网络的自动语音质量评估方法。
基于深度学习的方法:AutoMOS, QualityNe, NISQA, MOSNet
cv君认为这个倒是不是很难,当然人家也发了paper,获得了一定的认可,贡献还是有的,部分使用的是CNN做的分类,结合语音特征提取方法。我们深度学习模型需要哪些呢?
数据制作和读取
特征选择和提取
损失等评价指标设定
模型搭建和训练
模型验证和测试
其中我们看这一步,评价指标,这边就是我们本节关注的内容了。
在深度学习评价方法的: speechmetrics 中
它消融对比了几个评价指标
MOSNet(absolute.mosnet或mosnet)
无量纲,越高越好。0 =非常差,5 =非常好
如MOSNet的作者所提供:基于深度学习的语音转换目标评估
MOS评测实际是一种很宽泛的说法。由于给出评测分数的是人类,因此可以灵活的测试语音的不同方面。比如在语音合成领域,常见的有自然度MOS(MOS of naturalness),相似度MOS(MOS of similarity)。在实时通讯领域,有收听质量(Listening Quality)评价和对话质量(Conversational Quality)评价。但是人类给出的评分结果受到的干扰因素特别多,一般不同论文给出的MOS不具有非常明确的可比性,同一篇文章中的MOS才可以比较不同系统的优劣。谷歌在SSW10发表的Evaluating Long-form Text-to-Speech: Comparing the Ratings of Sentences and Paragraphs对若干种多行文本合成语音的评估方法进行了比较,在评估较长文本中的单个句子时,音频样本的呈现形式会显著影响被测人员给出的结果。比如仅提供单个句子而不提供上下文,与相同句子给出语境相比,被测人员给出的评分结果差异显著。

在实时通讯领域,国际电信联盟(ITU)将语音质量的主观评价方法做了标准化处理,代号为ITU-T P.800.1。其中收听质量的绝对等级评分(Absolute Category Rating, ACR) 是目前比较广泛采用的一种主观评价方法。在使用ACR方法对语音质量评价时,参与评测的人员对语音整体质量进行打分,分值范围为1-5分,分数越大表示语音质量最好。
一般MOS应为4或者更高,这可以被认为是比较好的语音质量,若MOS低于3.6,则表示大部分被测不太满意这个语音质量。
MOS测试一般要求:
- 足够多样化的样本(即试听者和句子数量)以确保结果在统计上的显著;
- 控制每个试听者的实验环境和设备保持一致;
- 每个试听者遵循同样的评估标准。
除了绝对等级评分,其它常用的语音质量主观评价有失真等级评分(Degradation Category Rating, DCR)和相对等级评分(Comparative Category Rating, CCR),这两种方式不仅需要提供失真语音信号还需要原始语音信号,通过比较失真信号和原始信号获得评价结果(类似于ABX Test),比较适合于评估背景噪音对语音质量的影响,或者不同算法之间的直接较量。附语音合成论文中计算MOS的小脚本,其不仅强调MOS值,并且要求95%的置信区间内的分数
这边cv君找了份代码,大家可以看看,比较简单,就不赘述了。
# -*- coding: utf-8 -*-
import math
import numpy as np
import pandas as pd
from scipy.linalg import solve
from scipy.stats import t
def calc_mos(data_path: str):
'''
计算MOS,数据格式:MxN,M个句子,N个试听人,data_path为MOS得分文件,内容都是数字,为每个试听的得分
:param data_path:
:return:
'''
data = pd.read_csv(data_path)
mu = np.mean(data.values)
var_uw = (data.std(axis=1) ** 2).mean()
var_su = (data.std(axis=0) ** 2).mean()
mos_data = np.asarray([x for x in data.values.flatten() if not math.isnan(x)])
var_swu = mos_data.std() ** 2
x = np.asarray([[0, 1, 1], [1, 0, 1], [1, 1, 1]])
y = np.asarray([var_uw, var_su, var_swu])
[var_s, var_w, var_u] = solve(x, y)
M = min(data.count(axis=0))
N = min(data.count(axis=1))
var_mu = var_s / M + var_w / N + var_u / (M * N)
df = min(M, N) - 1 # 可以不减1
t_interval = t.ppf(0.975, df, loc=0, scale=1) # t分布的97.5%置信区间临界值
interval = t_interval * np.sqrt(var_mu)
print('{} 的MOS95%的置信区间为:{} +—{} '.format(data_path, round(float(mu), 3), round(interval, 3)))
if __name__ == '__main__':
data_path = ''
calc_mos(data_path)
语音质量的感知评估(Perceptual evaluation of speech quality, PESQ)
PESQ在国际电信联盟的标注化代号为ITU-T P.862。总的想法是:
- 对原始信号和通过被测系统的信号首先电平调整到标准听觉电平,再利用IRS(Intermediate Reference System)滤波器模拟标准电话听筒进行滤波;
- 对通过电平调整和滤波之后的两个信号在时间上对准,并进行听觉变换,这个变换包括对系统中线性滤波和增益变化的补偿和均衡;
- 将两个听觉变换后的信号之间的谱失真测度作为扰动(即差值),分析扰动曲面提取出的两个退化参数,在频率和时间上累积起来,映射到MOS的预测值。
cv君这边还介绍个和PESQ比较的:P.563算法 很好用哦
客观语音质量评估的单端方法P.563
P.563和PESQ最大的区别就是,P.563只需要经过音频引擎传输后的输出信号,不需要原始信号,直接可以输出该信号的流畅度。因此,P.563的可用性更高,但是其准确性要比PESQ低。
P.563算法主要由三个部分组成:
- 预处理;
- 特征参数估计;
- 感知映射模型
P.563将语音进行预处理后,首先计算出若干个最重要的特征参数,根据这些特征参数判断语音的失真类型,失真类型直接决定了感知映射模型的系数和所使用的特征。利用感知映射模型(其实就是线性方程)计算得到最终的评价结果。
预处理
类似的,语音信号首先进行电平校准和滤波。P.563假设所有语音信号的声压级都是76dB SPL,并将输入语音信号的电平值校准到-26dBov。P.563算法的所使用的滤波器分为两类,第一类滤波器的频率响应特性类似于上述的中间参考系统(IRS),第二类滤波器采用一个四阶巴特沃斯高通滤波器,其截止频率为100Hz且高频响应曲线较为平缓,通过这类滤波器的语音信号可用于基音同步提取、声道模型分析及信号电平和噪声电平的计算。信号预处理的最后一部分是语音活动检测(Voice Activity Detection, VAD),它以帧长4ms的信号功率为阈值,区分语音和噪声。高于该阈值的为语音,否则为噪声。该阈值时动态调整的
表示第nn帧噪声信号的功率,N为噪声帧的帧数。
阈值的初始值为所有帧长为4ms信号的平均功率。为了提高VAD的精度,对VAD的结果进行后处理:如果某一段话大于阈值但是长度小于等于12ms(3帧),则将信号判定为噪声;如果两段已经被判定为语音,但是它们的间隔小于200ms,则将这两段语音合并为一整段语音。
特征参数提取
P.563算法在特征提取过程中利用人类的发声和听觉感知原理,不需要考虑通讯网络相关的信息。P.563算法利用三个相互独立的参数分析模块对预处理后的语音信号提取特征:
- 第一个模块着眼于人类的声音产生系统,通过对声道建模,分析不自然变化造成的语音失真;
- 第二个模块主要用于原始语音信号重建,并分析失真语音信号中存在的噪声,包括加性噪声和信号包络相关的乘性噪声;
- 第三个模块定义并估计语音信号中的间断、静音、时域截断等失真。
P.563算法共提取43个不同的特征参数,其中8个被称作关键参数(Key Parameters)用于判断语音的失真类型。
失真类型判决和结果映射
优先级最高的失真类型是背景噪音,它根据信号的信噪比(SNR)决定,背景噪音会严重影响语音质量,大部分含有背景噪音的语音MOS值一般在1~3范围内。语音信号的间断失真是指语音信号有静音或中断,即信号的电平值发生突变。乘性噪声失真是指语音信号中与信号包络有关的噪声,该类失真仅出现在活动语音部分。语音的机械声与语音的音调密切相关。优先级最低的失真类型是语音整体的不自然度,由于语音编解码器的输出质量和性别有关,P.563基于基音频率将该失真类型分为男声和女声两种情况。如下图:

这些算法,cv君算法出身 的,表示已经很熟了~大家可以看看,有什么不会的可以咨询我。
客观评价结果的映射模型
在P.563中映射模型就是一个线性模型。P.563算法根据上述求出的失真类型对线性方程的系数设置了不同的值。每一种失真类型包括12个不同的语音特征,P.563首先根据待测语音的失真类型对这12个语音特征线性组合得到评价结果的中间值,再将中间值结合另外的11个特征参数得到最终的结果。
NISQA: 无参考语音通信网络的语音质量
cv君带大家回顾一下,这个算法就是前面文章介绍过的哦~
使用的深度网络可以自动进行特征提取,因此这类方法直接将梅尔频谱系数或者MFCC直接送入模型即可。以NISQA为例。cv君不得不说,梅尔图很厉害。

如上图,整个网络结构十分简单,对数梅尔系数分别送入CNN和计算MFCC,CNN实际输出了帧级别的语音质量。为了使整个模型能够对语音的整体质量进行评估,CNN输出的结果和MFCC连接起来送入LSTM,以得到最终的MOS分。
其中,CNN的设计细节:

NISQA是用于语音质量预测的深度学习模型/框架。NISQA模型权重可用于预测已通过通信系统(例如电话或视频呼叫)发送的语音样本的质量。除了整体的语音质量,NISQA还提供了质量方面的预测吵闹,着色,不连续和响度给更多洞察质量下降的原因。
TTS自然度预测:
NISQA-TTS模型权重可用于估计由语音转换或文本语音转换系统(Siri,Alexa等)生成的合成语音的自然度。
训练/微调:
NISQA可用于训练具有不同深度学习架构的新的单端或双端语音质量预测模型,例如CNN或DFF->自注意力或LSTM->注意力池或最大池。所提供的模型权重还可以应用于针对新数据微调训练后的模型或用于向不同回归任务的转移学习(例如,增强语音的质量估计,说话者相似性估计或情感识别)。
小结
语音质量评估对给予了语音一个定量指标,对语音质量的评价(Audio Quality Assessment)其实是一个多年以来得到了深入研究的问题。大致可以分为需要标准信号的无参考(Non-intrusive)和有参考(instrusive)方法。无参考语音质量评估在实时通讯领域出现了许多传统和深度学习方法,但是在语音合成领域,成果其实是寥寥无几的。
噪声
cv君来说说一些噪声,因为这大大的影响了质量。
设备噪声: 比如单频音,笔记本风扇音等等。
环境噪声:鸣笛等,
信号溢出:爆破音
还有个音量小问题,包括,设备读取声音小,说话人声音小等。
解决方法
这边有一些建议方法,cv君认为可以用独立检测的方法,对这些类型的杂音做精准的检测,然后割离。
包括训练检测模型,针对杂音,硬件噪声,
下面cv君再针对回声介绍一种解决方法:
音频处理之回声消除及调试经验
本节讲的回声(Echo)是指语音通信时产生的回声,即打电话时自己讲的话又从对方传回来被自己听到。回声在固话和手机上都有,小时还可以忍受,大时严重影响沟通交流,它是影响语音质量的重要因素之一。可能有的朋友要问了,为什么我打电话时没有听见自己的回声,那是因为市面上的成熟产品回声都被消除掉了。回声分为线路回声(line echo)和声学回声(acoustic echo),线路回声主要存在于固话中,是由于2-4线转换引入的回声,声学回声是由于空间声学反射产生的回声 。回声消除(Echo canceller, EC)是语音前处理的重要环节,下面主要讲其基本原理和调试中的一些经验。
1,基本原理
1)自适应滤波器和自适应算法
一般滤波器的系数是固定的,而自适应滤波器的系数是变化的,是依据自适应算法来调整滤波器系数的。自适应滤波器的结构采用FIR或IIR均可,由于IIR存在稳定性问题,因此一般采用FIR。下图是自适应滤波器的一般结构:

上图中,x(k)为输入信号,y(k)为输出信号,d(k)为期望信号,e(k)是d(k)和y(k)的误差信号。自适应滤波器的滤波器系数受误差信号e(k)控制,根据e(k)的值和自适应算法自动调整。
自适应算法一般采用LMS(least mean square,最小均方)算法及其变种(如NLMS算法)。LMS算法是随机梯度算法族中的一员。具体可以看相关的文章。
2)回声消除基本原理。
下图是回声消除基本原理的框图:

处理过程如下:
a) 算近端远端语音数据的energy,确定双方是silent还是talk。
b) 远端输入经过自适应FIR滤波器后就得到了近似于近端输入的数据,并与近端输入相减后得到了误差e。
c) 误差e同时也会经过NLP(非线性处理)后产生舒适噪声送给对方。
2,调试
个人觉得对EC零基础但已有EC算法代码的基础上去调试主要有如下几步:
1)学习回声消除的基本原理,涉及信号处理知识(从固定系数滤波器到系数自适应滤波器)和高等数学知识(梯度)等。因为不是做算法,掌握基本的就可以了。如果基础扎实,当然搞得越明白越好了。
2)看算法代码。如果有实现的设计文档那是最好了,好多算法实现有技巧,有设计文档的话能更好的帮助理解代码。没有只能硬着头皮啃了。刚开始可能有些看不懂,多看几遍,也许每一次都会多懂一些。
3)做个应用程序验证算法。这个应用程序输入是近端和远端的PCM文件,把EC的输出写进一个PCM文件里,看处理效果如何。这里面也可以分几小步:
a) 设latency为零,近端和远端的PCM文件相同,理论上输出是全零数据。如果是这样,恭喜你选择的算法有一个好的base。如果不是那就需要去调算法里的一些系数了,这也许要调好多次,最终调试结果要是算法输出基本听不见回声。
b) 设一定的latency,近端的PCM和远端的数据一样,但是近端的PCM数据相对远端的有一定的delay,这个值跟设定的latency值是一样的,这时理论上输出还是全零数据。
c) 获取实际产品上的近端和远端PCM数据,可以近似得到近端和远端的latency。把这几个作为输入,看算法输出,也要基本听不见回声。这步调好后算法基本上就可以用了。
- 在具体硬件平台上去调。每个硬件平台上的latency都是不一样的。在芯片公司时有demo板,每个客户也有他们的电路板,硬件平台相对不多一个个获取近远端PCM数据调好latency就可以了。在移动互联网公司做APP时,手机类型众多,用上面方法太累,于是在UI上做了一个滑动条去配置latency,让测试人员去测试找到一个相对较好的latency,然后放在配置文件里保存下来,以后这款手机就用这个latency值了。
经过上面几步后在真正产品上的EC调试就算结束了。
最后最后
语音增强噪声 及其评估方法
噪声类型
语音增强的目的是提高语音信号的质量或可懂度,减少失真。这里主要介绍单麦克风信号语音增强,常见的失真有:
(a) 加性声学噪声:就是麦克风在录制语音时同时录制进去的背景环境声音
(b) 声学混响:多径反射引起的叠加效应
(c) 卷积信道效应:导致不均匀或带宽限制响应,为了去除信道脉冲响应,做信道均衡时对通信信道没有有效建模
(d) 非线性失真:比如信号输入时不适当的增益
语音增强
cv君刚刚介绍噪声类别,那么我们就可以针对性的做一些解决。可以将信号退化分成3类:
1)在声学和电子学中可能产生与期望信号不相干的加性噪声,其影响了声音可懂度和听觉质量,极端情况下,甚至掩盖了期望语音。对于一些加性噪声,其频谱特征是平稳的或随时间缓慢变换的,比如嗡嗡声、功放噪声和一些环境噪声。谱减法和单信道自适应滤波器成功应用于这些平稳噪声。还有一些加性噪声是间歇的或高度非平稳的,这些噪声的鉴定和消除效果还不理想,比如媒体干扰、非期望语音干扰和一些电子干扰。
2)卷积影响一般是由混响、反射等造成的,其与加性噪声的区别是:加性噪声和期望语音时不相干的,而卷积噪声和期望语音是相干的。麦克风的位置、麦克风的特性和CODEC局限性可能引起带宽限制和不均匀的频谱响应。对卷积噪声的处理效果不是很好。
3)非线性失真频繁出现于幅度限制、麦克风功放等。这类噪声也比较难处理。
3.2 按帧处理
其中n=0;…;N-1,w(n)是窗函数,M是帧移,N是窗长,是频率分辨率和时间分辨率的折衷,一般是10~30ms,对应50Hz左右的频率分辨率。为了减小窗函数的影响,窗函数的选择和帧移选择很重要,可以用汉宁窗,半帧长的帧移。
3.3 谱减法
1979年提出,广泛用于减少加性噪声。只要在频谱上乘以一个增益系数。谱减法如果减得不够,会有噪声残留,如果减得过多,又会造成语音失真。
总结
这篇文章很长,但很有意义,综述了过去几年和近今年语音传输,语音编解码前后的质量问题,另外我还针对了几种噪声,提出了解决的方案,以便我们更好地解决问题。
如果大家对文章感兴趣,不妨看看我在InfoQ写的另一篇文章:声网的算法和噪声等的相关解决方案,这里篇幅原因,有时间下次整合一起介绍~ 其实还包括使用强化学习,对抗生成等方式的解决问题方法,特别强,以后可以详细分析一下。
再会~