爬虫笔记10:python内置re模块(正则表达式)
一、什么是正则表达式
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
二、正则表达式的使用
在Python当中有一个内置模块re ,专门实现正则表达式。
¤普通字符
字母、数字、汉字、下划线、以及没有特殊定义的符号,都是"普通字符"。正则表达式中的普通字符,在匹配的时候,只匹配与自身相同的一个字符。例如:表达式c,在匹配字符串abcde时,匹配结果是:成功;匹配到的内容是c;匹配到的位置开始于2,结束于3。(注:下标从0开始还是从1开始,因当前编程语言的不同而可能不同)
match()函数:从字符串第一个开始匹配。
¤元字符,用来表示一些特殊的含义或功能
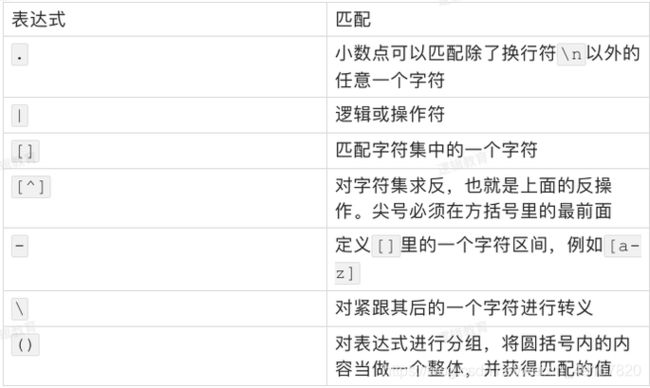
注意 :在写正则表达式模板的时候 如果正则表达式的模板当中出现了一些元字符,但是这些元字符不在你的正则表达式的逻辑当中 用转义字符 " \ " 处理一下
¤预定义匹配字符集

¤重复匹配

¤位置匹配

三、re模块中的match函数
import re
re.match(pattern, string, flags=0)
参数:
1 pattern 正则表达式的模板
2 string 数据
3 flags 标致位 匹配的方式 例如 是否区分大小写、是否换行匹配…
match()函数是有返回值的,如果匹配成功了,就返回一个match对象;否则返回一个None。
match()函数是从字符串第一个开始匹配的。
匹配对象Macth Object具有group方法,用来返回字符串的匹配部分。
p = 'python'
s = 'python and java'
result = re.match(p,s)
print(result)
print(type(result))
print(result.group())
k='python123abc'
result = re.match(p,k)
print(result.group())
h='apython123abc'
result = re.match(p,h)
print(result)
结果:

四、正则表达式子在爬虫中的应用
定义一个函数,实现匹配数据的功能。
比如:匹配一个数字或者字母开头的QQ邮箱。
import re
def fn(ptn,lst):
for x in lst:
result = re.match(ptn,x)
if result:
print(x,'匹配成功!','匹配的结果是:',result.group())
else:
print(x,'匹配失败') #pass
ptn = '\[email protected]'
lst = ['[email protected]','[email protected]','[email protected]']
fn(ptn,lst)
结果:

五、正则表达式的使用举例




\s(小写): 匹配空白,即 空格,tab键





五、贪婪匹配和非贪婪匹配

以实际的爬虫案例为例:(前面内容+.*?+后面的内容)

六、炒股实际应用
(1)先确定好要用的正则表达式:

(2)丰富代码:
import re
import pandas as pd
df=pd.DataFrame({'name':['高瓴资本管理有限公司-HCM中国基金','社保基金'],
'sum':[123,456]})
#print(df)
def fn(ptn,lst):
for index,value in enumerate(lst):
result = re.search(ptn,value)
if result:
return index
target=pd.DataFrame()
ptn ='.*高瓴资本.*'
lst =df['name']
target=target.append(df.iloc[fn(ptn,lst)])
print(target)
结果:

