3综述 yolo_无人驾驶综述论文学习(一)

论文介绍
论文为2019年发布在Robotics上的
"A Survey of Autonomous Driving: Common Practices and Emerging Technologies"[1]
论文对比
作者首先比较了目前的无人驾驶综述论文,存在的问题是目前无人驾驶综述论文的侧重点都不一样,所以作者准备做一个详尽的调查,下图是不同论文的侧重点:
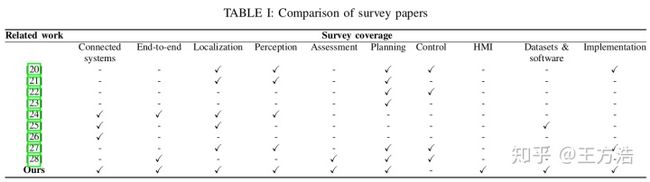
可以看到上述论文都只是针对无人驾驶的某几个模块做了介绍,而最后一个是本论文的介绍,比较完备(除了没有control模块):Connected systems, End-to-End, Localization, Perception, Assessment, Planning, Control, HMI, Datesets & Software, Implementation.
前景和挑战
接着作者介绍了无人驾驶的前景和挑战,首先作者提出虽然ADS短期并不会普及,但是还是可以遇见到带来的好处,作者总结的非常好,包括3个方面:
- 可以解决的问题 - 预防交通事故,减少交通拥堵,减少排放
- 可以捉住的机会 - 重新分配驾驶时间,解决运输出行障碍
- 新趋势 - 出行既服务,物流革命
首先自动驾驶可以解决在由于人类驾驶员错误行为导致的交通事故,例如分心,超速,酒驾等情况;其次60岁以上的老人增加的很快,解决老年人的出行问题对他们的生活质量改善很大;最后,共享出行现在是一个趋势,节省了出行成本。
按照目前的驾驶技术还不能达到level4的水平。
系统架构
作者分别从2个层面论述了无人驾驶系统的架构,一是从连接层面,二是从算法层面,下图是具体的划分:
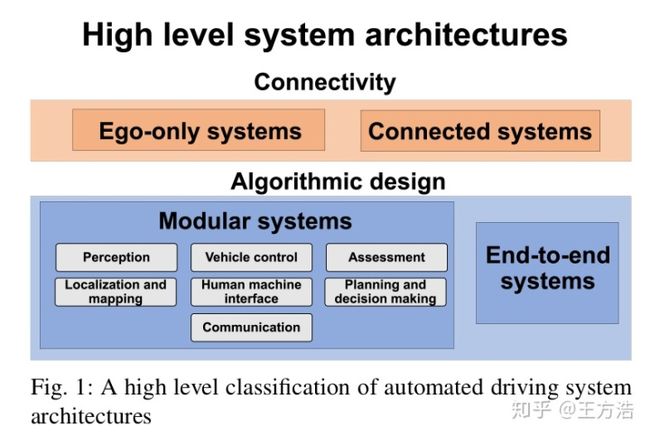
连接层面 - 在连接层面分为2种:一种是单车智能,即单个车即使不联网也具备自动驾驶能力;另一种是网连智能,不强调单车的智能(有的话当然更好),强调通过网络实现整个交通的智能,不仅仅包括车,还包括交通灯,摄像头,以及其他设备,目前中美两国的分歧也在这里,看起来是押国运的2个方案。ego-only systems主要是指依赖本车的智能,而不需要依赖其他车辆或者外部传感器,而connected systems则是相对的,汽车通过v2x设备组成车联网。
算法层面 - 在算法层面分为2种:一种是目前主流的分模块的划分;另一种就是端到端的自动驾驶系统。可以看到左边的系统架构根据无人驾驶的需要将不同的功能划分为不同的模块,各个模块负责不同的功能,最后组成整个自动驾驶系统;而右边的架构为端到端的自动驾驶方案,说直白一点就是直接根据传感器输入,然后输出汽车的方向盘转交,油门刹车信息。端到端的自动驾驶好处是系统简单,主要的方法可以参考英伟达的论文。
下面是端到端无人驾驶的流程图:

端到端的自动驾驶系统结构非常简单,也很接近人类驾驶的习惯,坏处是不可解释性,目前也达不到强人工智能,超过人类驾驶员。
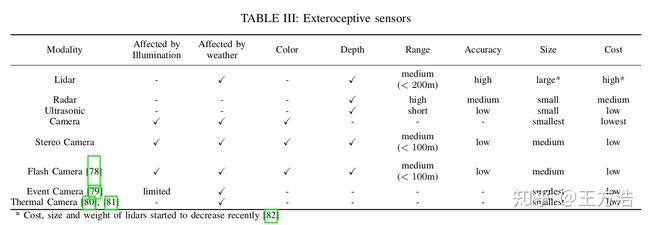
传感器
作者接着介绍了无人驾驶的各种传感器以及传感器的优缺点,这一点其他资料介绍的非常多了,这里直接上图:
定位
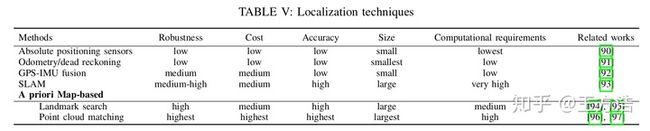
目前state-of-art的定位主要分为3种:
- GPS/IMU融合 - Gps和IMU融合的方案是目前主流的定位方案,采用rtk 技术之后定位的精度可以达到厘米级别,目前遇到的问题是在高楼,隧道等信号不太好的地方定位误差会变大。
- 基于先验地图 - 基于先验地图的方案主要是实现把周围环境的信息保存下来,以高精度地图为例子,实现采集并存储高精度地图中的点云信息,然后基于ICP或者NDT算法进行点云匹配,匹配到的位置即是当前车辆的位置,好处是在Gps信号不好的时候也可以使用,缺点是运算量大,在周围环境发生变化时,如何更新地图。
- SLAM - slam方法的好处是不依赖于先验地图,可以在陌生环境(乡村或者一些环境变化迅速的场景)使用,缺点是计算量太大,算法做不到实时,基于视觉的slam精度也达不到要求。
下面是作者对各种定位方法做的对比和总结:
下图是基于NDT点云定位的例子:

预测主要分为几块:基于图像的物体识别,语义分割,3D物体识别,道路和车道线识别和物体追踪,下面我们来分别介绍。
基于图像的物体识别
无人驾驶中的物体识别是指识别感兴趣对象的位置和大小,包括静态物体识别:红绿灯,交通标志,道路交叉口和动态物体识别:车辆,行人和自行车。
目前最先进的方法都依赖于DCNN(深度卷积神经网络),但它们之间目前存在明显的区别:
- 单级检测框架使用单个网络同时生成对象检测位置和类别预测。主流的算法有:YOLO(You Only Look Once), SSD(Single Shot Detector)
- 区域提取检测框架分为两个不同的阶段,首先提出感兴趣的常规区域,然后通过单独的分类器网络进行分类。
下图是主流的图像目标检测算法在ImageNet上的benchmark:
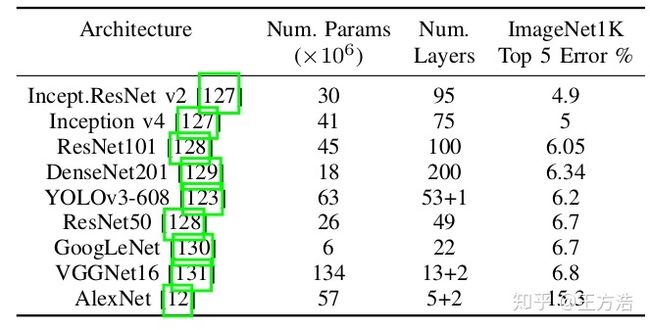
区域提取检测框架是目前效果最好的方法,但是需要很高的计算能力,并且通常难以实施,训练和微调。同时,单级检测算法往往具有快速的推理时间和较低的存储成本,能够满足无人驾驶实时计算的需求。
由于近年来计算能力的提升,讲来RPN(region proposal networks)可能取代单机检测网络,成为自动驾驶的主流检测算法。
由于图像检测算法强依赖于相机,这里作者又对2种新的相机做了简单的介绍:
全向相机(Omnidirectional Cameras)
全向相机可以得出一个360度视角的图像,这类相机由于视角很大,有些是2颗摄像头,有些是4-6颗摄像头,摄像头多为广交鱼眼镜头,往往需要考虑镜面反射或鱼眼镜头变形,要进行校准。全向相机的主要应用场景是:SLAM和三维重建。
下面是全向相机的一个例子:

事件相机(Event Cameras)
事件相机是一种新的相机,主要是根据场景中的运动成像,也就是说事件相机对运行的捕捉非常快,响应时间为微秒。而普通的相机是感光成像,类似人眼,速度快了之后会出现“运动模糊”(因为速度快了之后,感光时间不够导致重影或者运动模糊)。得益于事件相机的帧率,响应时间,这样在高速驾驶的时候也能够清晰成像,事件相机目前已经应用在端到端的无人驾驶系统中。
下图是事件相机的一个例子,左边的根据物体的动态成像,而右边是普通相机的感光成像:

照明不良和外观变化
使用相机的主要缺点是照明条件的变化会严重影响其性能。弱光照条件的场景本来就很难解决,更不要说由于强光照射,阴影移动,天气和季节变化导致的照明变化可能导致算法的失败了。一个显而易见的方法是用备份的传感方式进行感知,例如lidar和radar。但是lidar和radar的感知都有受限的场景,因此传感器融合方案可能是最佳的选择。
通过红外传感器的热成像也可用于弱光条件下的物体检测,这对行人检测很有效。当然目前还已经开发出尝试直接处理动态照明条件的纯相机方法,已经提出尝试提取照明不变特征和评估特征质量2种方法。
照明不变特征可以参考论文"Illumination Invariant Imaging: Applications in Robust Vision-based Localisation, Mapping and Classification for Autonomous Vehicles"[2],下面是截取的论文中的一个例子,可以看到在上午9点和下午5点不同的光照条件下提取出照明不变特征:

评估特征质量的方法参考论文"PROBE-GK: Predictive robust estimation using generalized kernels"。该论文的主要观点是:大多数基于特征的方法都依靠随机样本共识算法,将提取的特征划分为离群值和离群值,而本论文则描述了一种以数据为依据的有原则的方法来为视觉里程表建立噪声模型。
目前应对照明不足和照明变化带来的不可预测性仍然是阻止纯相机方法在自动驾驶中广泛应用的主要挑战。
语义分割
这项任务对驾驶自动化特别重要,因为某些目标对象很难通过边界框来定义,特别是道路,交通线,人行道和建筑物。下面是图像分割的一个例子:
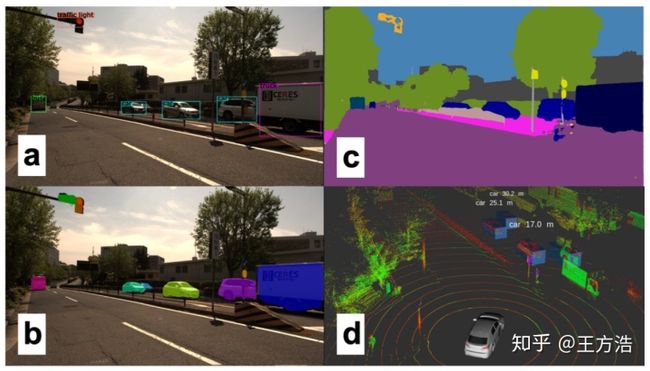
语义分割和物体识别实际上非常相似,用于分割的Mask R-CNN是Faster R-CNN的概括。当能够达到5fps的速率时,就可以满足自动驾驶的要求了。
目前用于语义分割的网络还是太慢而且计算代价太昂贵了,鉴于上面的介绍,作者认为未来会有单一,通用的网络能够解决自动驾驶不同感知任务的可能性。
3D物体识别
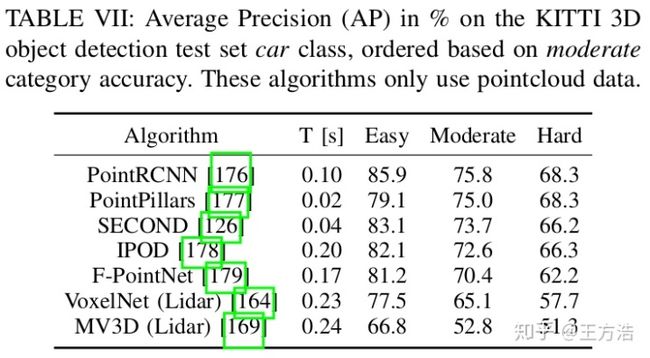
在避障等动态驾驶任务需要环境的3D信息,目前3D信息主要依赖点激光雷达的点云数据,下面是kiit 上各种算法的对比,对应用来说,不仅仅是准确率,耗时也是很重要的指标(3D的卷积神经网络比2D的卷积神经网络更加耗时)。
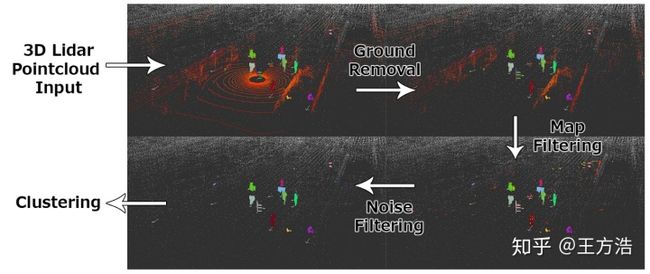
下图是3d物体识别例子,3d物体识别的流程一般是先进行滤波,然后进行聚类,最后提取特征做识别:
当然也可以用RGB-D相机获取深度信息,但由于RGB-D的作用范围有限,并且在室外不太可靠,目前没有应用在自动驾驶领域。
雷达(Radar)
讲雷达系统应用在自动驾驶中主要的缺点是雷达的对物体形状的采样精度不够,这对测量大物体,例如汽车来说是可行的,但是对于行人和静态物体是个挑战。另外一个问题是雷达的视野范围非常有限,需要一组雷达去覆盖比较全的视野范围。
虽然如此,雷达还是在自动驾驶中应用广泛,雷达测量的距离很远,低成本,并且对恶劣天气的适应性强。目前往往需要lidar和radar一起应用于自动驾驶感知。
另外一个和radar相似的传感器是声纳,由于它的距离非常短<2m,和比较差的角度分辨率,目前只能应用于非常近的障碍物感知。
物体追踪
概述了滤波方法和深度学习2种方法:
- 滤波方法 - 卡尔曼滤波,粒子滤波等方法,是之前的传统方法,主要是根据统计学的方法来估计物体的轨迹。
- 深度学习 - 深度学习的方法是目前比较新的方法,目前的算法也接近实时了。
下面是作者用基础粒子滤波做的追踪效果图:

当然也有2种方法结合的,这里说下我自己的看法,看了下物体追踪相关的材料,发现传统的滤波方法和深度学习的方法目前都不相上下,其实现在问题有点演变成了逐帧识别物体,然后每帧的位置就是当前物体的位置。这也好理解,我们跟踪一个人也是根据特征找到他,然后预测他下次大概会出现在哪里。
而无人车刚好需要做物体识别,所以之后顺理成章的把识别好的数据拿来做追踪,如果说需要纯研究追踪也有直接提取特征,不需要做识别的。目前apollo系统中的预测模块就是拿感知模块作为输入,然后预测的轨迹,至于这块步建议参考纯追踪算法。
道路和车道线识别
可行驶区域识别对自动驾驶至关重要,并且单独作为一个子问题在研究,目前能够识别并且理解道路的结构化信息依然是一个很有挑战的问题。
此问题通常细分为几个任务,每个任务都可以实现一定程度的自动化:
- 可行驶区域检测 - 检测车道和本车当前行驶车道,可以应用于:车道偏离警告,车道保持和自适应巡航控制。
- 道路复杂语义理解 - 识别其他车道和方向, 以及道路是合并还是转弯,简单点说就是理解道路的结构化信息。应用于全自动驾驶。
目前道路的结构化信息还是通过高精度地图来获取。

目前车道识别已经成功应用于车道保持的功能,但是真正鲁棒和普适性的方法还是需要进一步研究,下面2篇论文是作者推荐的道路和车道识别的综述论文:
- Recent progress in road and lane detection: a survey
- A hybrid Vision-Map method for urban road detection
评估
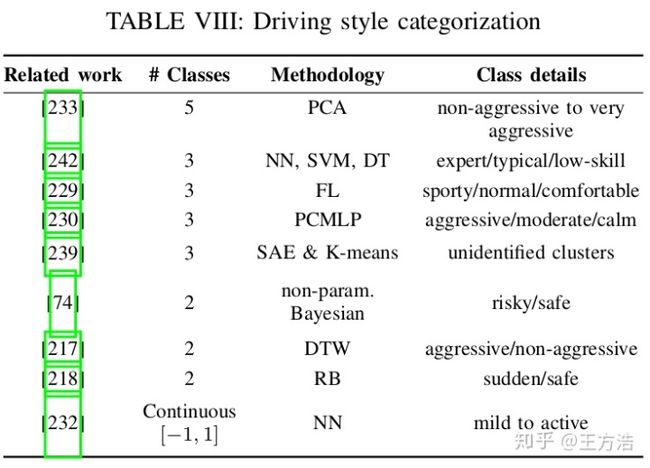
自动驾驶汽车应该能够评估环境的整体风险水平,并且预测周围驾驶员和行人的意图,交通事故往往是缺乏急性评估机制引起的。评估也主要分为3个部分:风险和不确定性评估,周围驾驶行为评估和驾驶风格识别。这块的介绍后面再展开,下面是关于驾驶风格识别方法的对比:
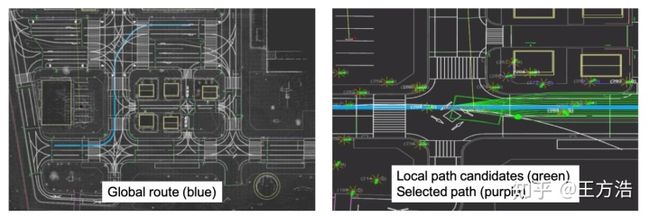
接着我们介绍规划,在本文中规划被分为二个方面:全局规划,本地规划。
全局规划
全局规划主要是规划目的地,类似目前用到的地图导航,传统的方法分为以下4个类别:
- goal-directed - A*是一种标准的目标导向路径规划算法,广泛在各个领域应用了50多年。
- separator-based - 主要是思想是从图中删除一部分顶点或圆弧,从而加快计算速度。
- hierarchical - 道路分为不同的等级:普通公路,高速公路和大动脉,这样导致的问题是最短的距离不一定是最快的(走高速更快),而收缩层次结构法(Contraction Hierarchies)用来处理该问题。
- bounded-hop 预先计算好2个点之间的距离和时间,这样计算的时候只需要查表就可以了,预处理技术是利用空间换时间。
目前融合了上述几种方法的全局路径规划算法已经非常成熟了,往往可以在毫秒内进行查询。左图首先展示了全局规划,即找到一条从A点到B点的路径。而右图是本地规划,主要考虑汽车在道路上如何行驶,同时需要考虑障碍物,红绿灯等情况。
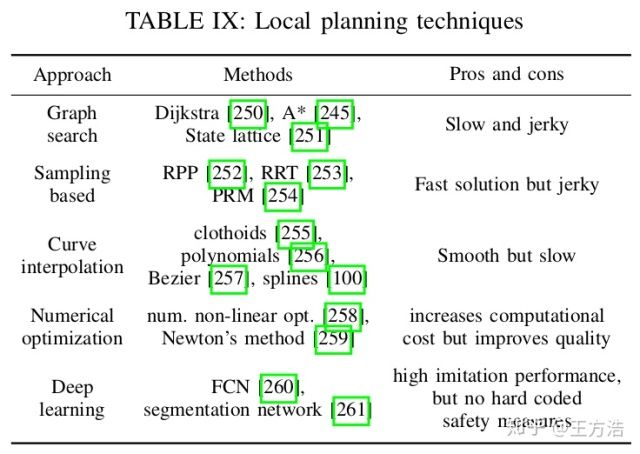
本地规划
本地规划则是路径规划,即是短期的路径规划,分为4种传统方法加上1种深度学习的方法:
- graph-based planners - 图搜索算法的经典算法是Dijkstra和A*算法,输出的是离散路径而不是连续路径,更高级的图搜索算法是state lattice,对动态环境的路径规划非常有用。
- Sampling-based planners - 尝试通过随机采样来建立C-space的连通性。
- Interpolating curve planners - 曲线拟合到一组已知的点,主要的避障策略是对新的无碰撞路径进行插值,该路径首先会偏离,然后重新进入初始计划轨迹。得到的轨迹是平滑的,有各种常用的曲线族,例如回旋曲线,多项式,贝塞尔曲线和样条曲线。
- Optimization based motion planners - 通过优化功能提高现有路径的质量。
- deep learning based planners - 利用深度学习的方法输出规划路径,和端到端自动驾驶的区别是输出结果,前者是输出曲线,后者是输出油门刹车和方向盘。
上述路径规划算法对比见下图:
人机交互接口
无人驾驶车通过人机交互接口(HMI)与驾驶员和乘客进行通信。其中最基本的是驾驶任务的交互,例如驾驶目的地的选择。听觉用户界面(AUI)将会是打车交互的好选择,目前车内的噪音以及角色理解可能是很难处理的部分。而且会出现新的交互需求,例如乘客需要了解和监控无人驾驶汽车目前的状况。
人机交互详细的介绍可以直接参考论文,这里就不展开了,人机交互这块在商业化交付的时候需要格外重视。
本文最后介绍了无人驾驶数据集和可用的工具。
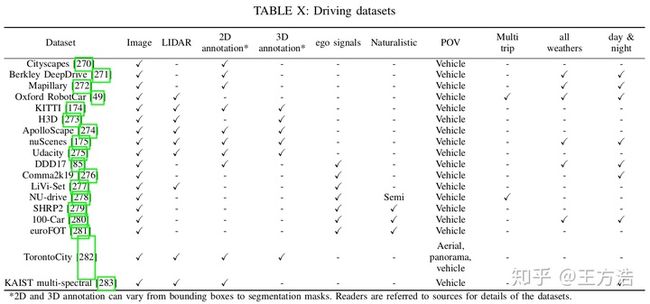
数据集和基准
本文整理了和对比了目前主流的数据集,直接上图:
开源框架和仿真器
目前主流的开源框架主要是:
- Autoware
- Apollo
- Nvidia DriveWorks
- openpilot
无人驾驶的仿真如下:
- CARLA
- TORCS
- Gazebo
- SUMO
上述软件大部分是开源的可以直接下载使用。
总结
至此整个论文的学习就结束了,关于本文的一个优点是不仅仅介绍目前主流的方法,而且还加入了自己的判断,并给出了建议,我觉得这是论文做的比较好的方面(很多论文只是简单的介绍方法,没有自己的判断和理解),论文的内容比较新也比较全面,总的来说非常推荐。
如果觉得文章对你有帮助,欢迎点赞转发 : )
参考
- ^A Survey of Autonomous Driving: Common Practices and Emerging Technologies https://arxiv.org/abs/1906.05113
- ^Illumination Invariant Imaging: Applications in Robust Vision-based Localisation, Mapping and Classification for Autonomous Vehicles http://www.robots.ox.ac.uk/~mobile/Papers/2014ICRA_maddern.pdf