Hadoop的搭建,VmwareWorkstation 16pro + Ubuntu18.04.1
文章目录
-
前言
-
一、VmwareWorkstation 16pro安装Ubuntu18.04.1
-
二、Ubuntu的基础配置
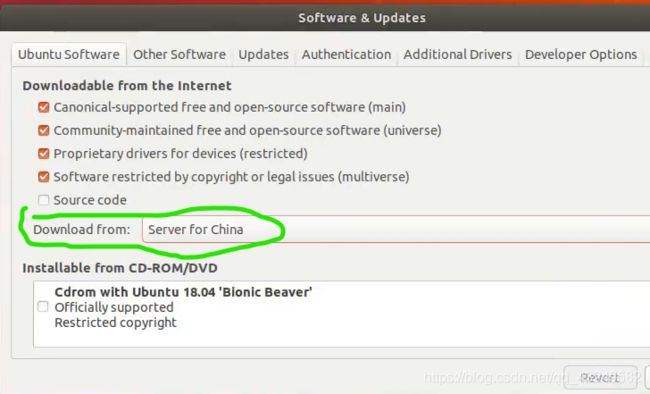
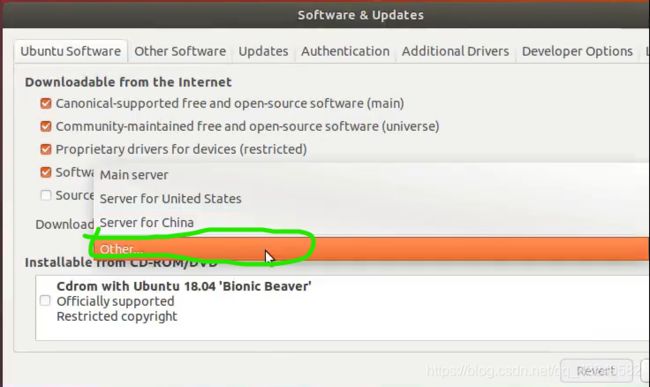
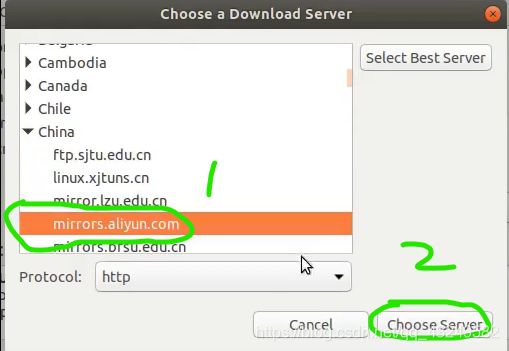
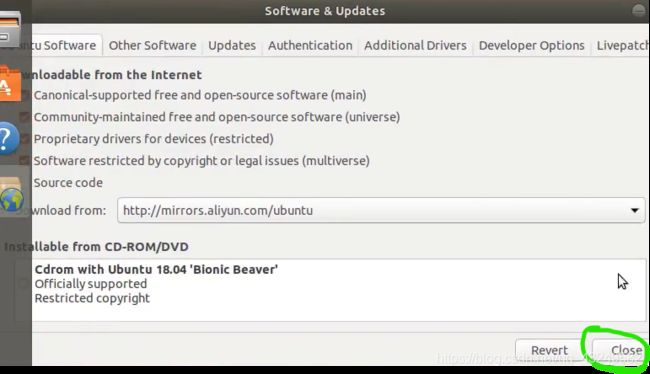
1.设置国内镜像源
2.下载安装Vmware Tools
-
三、安装Hadoop
-
总结
前言
Hadoop的搭建过程。
一、VmwareWorkstation 16pro安装Ubuntu18.04.1
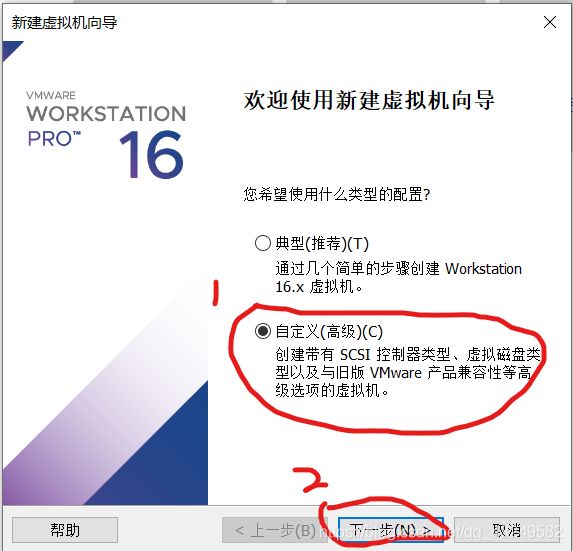
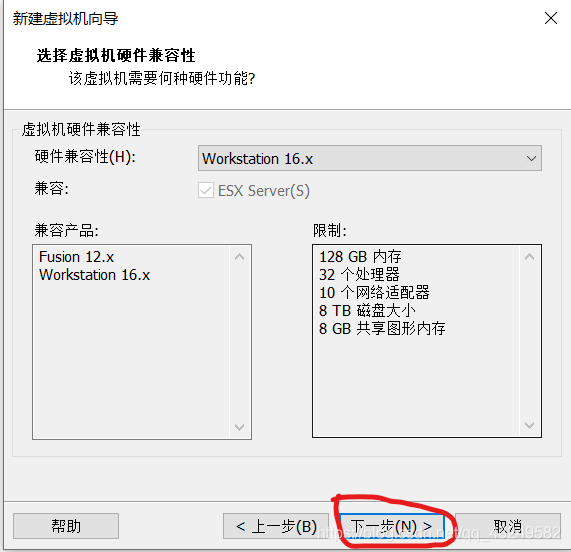
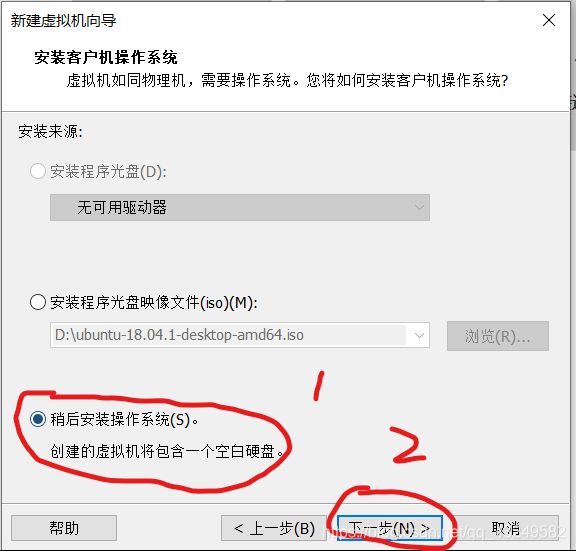
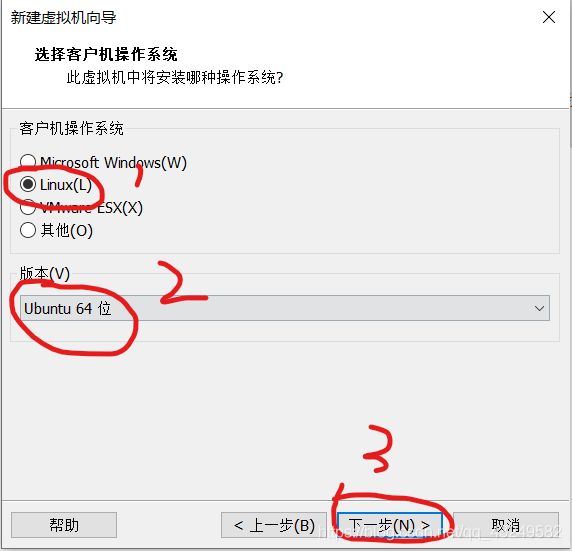
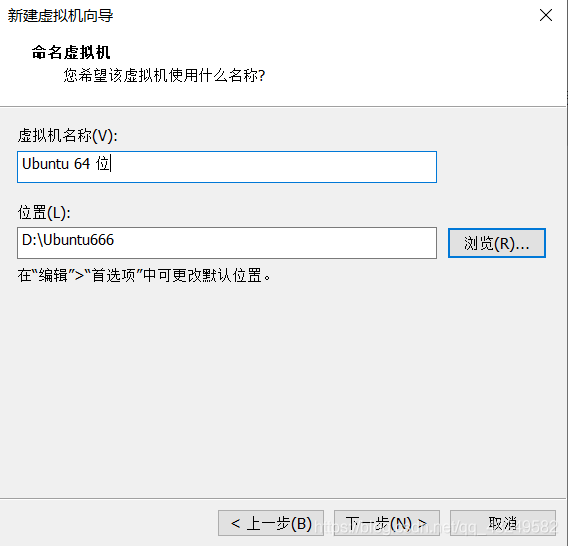
虚拟机名称可以根据自己喜好命名,安装位置根据自己电脑实际情况选择合适的位置,点击下一步。
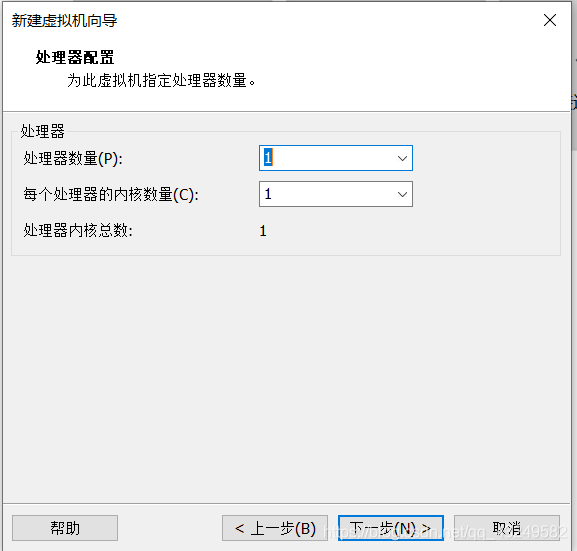
处理器核数多的话可以给2个,核数少直接都给1个,点击下一步。
一般电脑运存为8g,使用推荐内存,如果小于8g则选择最低推荐内存,点击下一步。
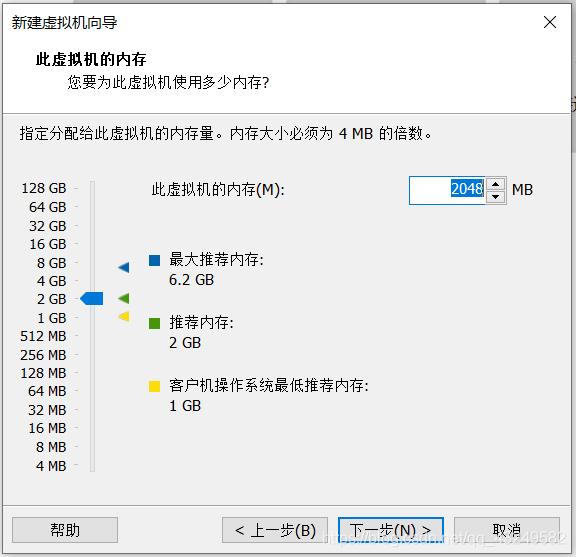
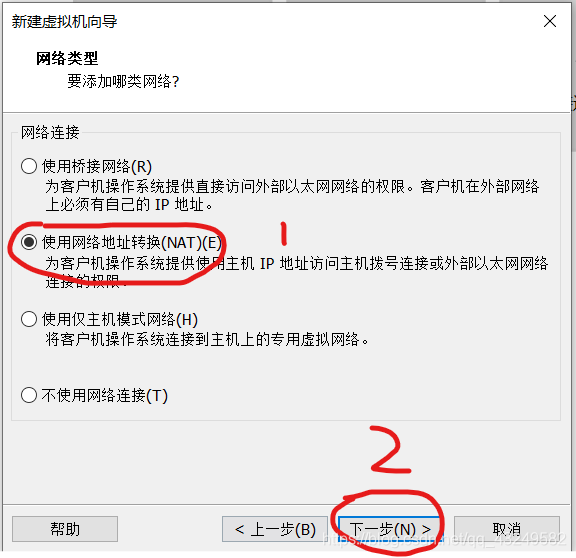
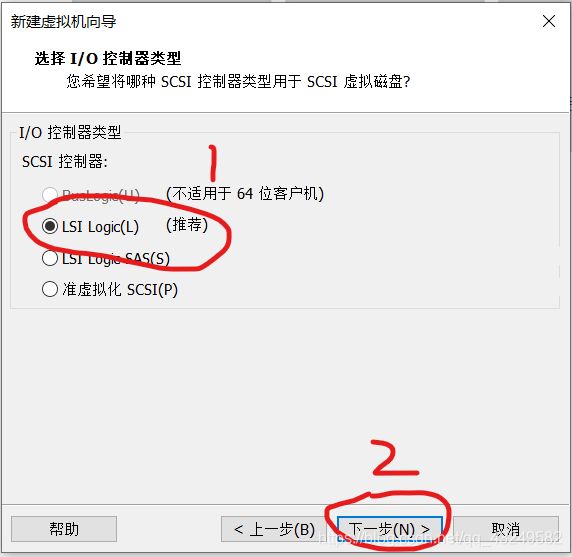
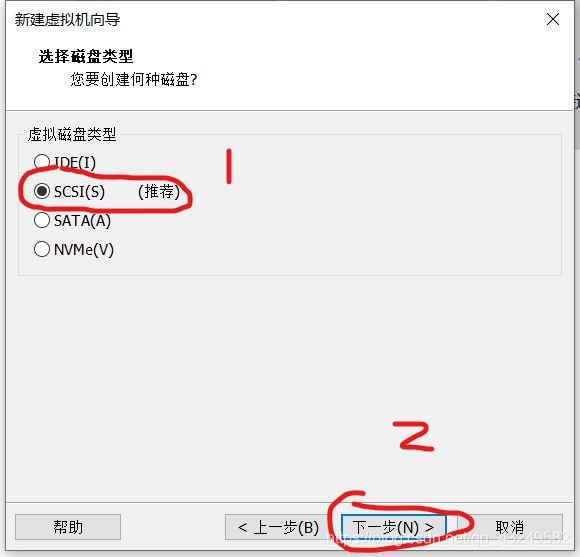
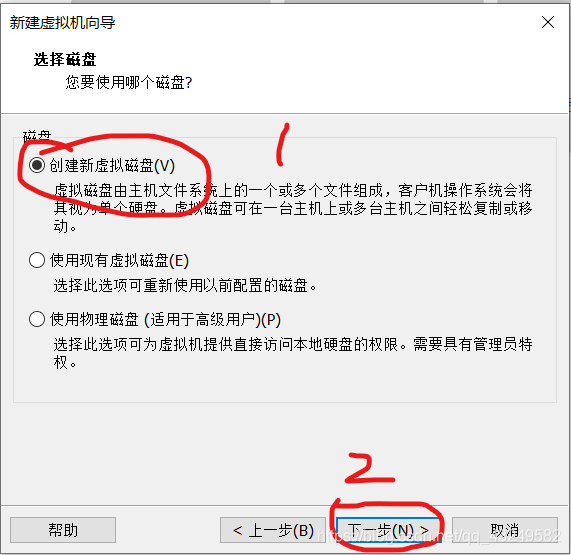
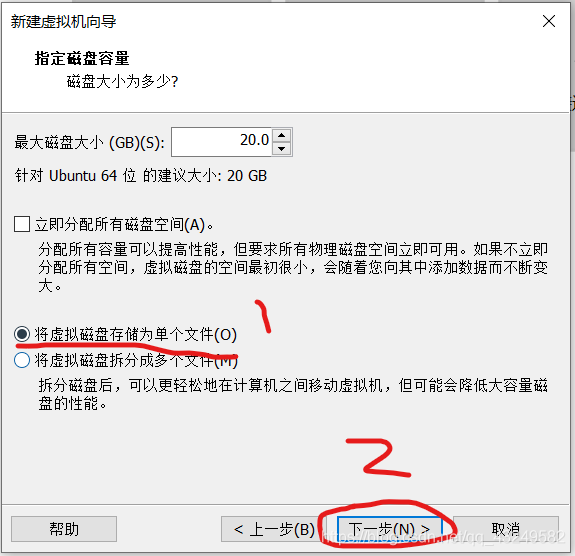
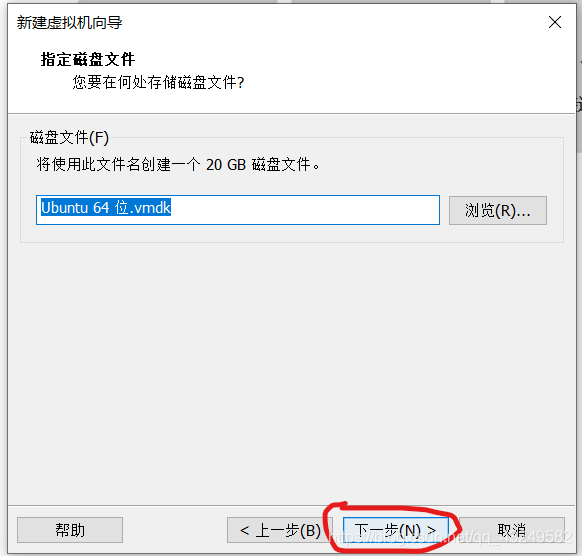
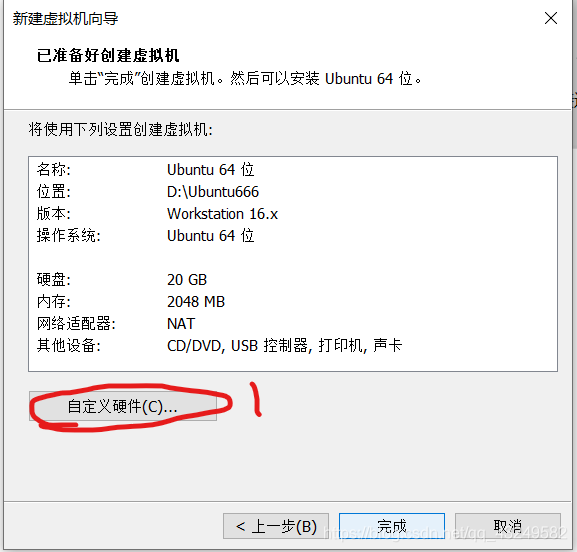
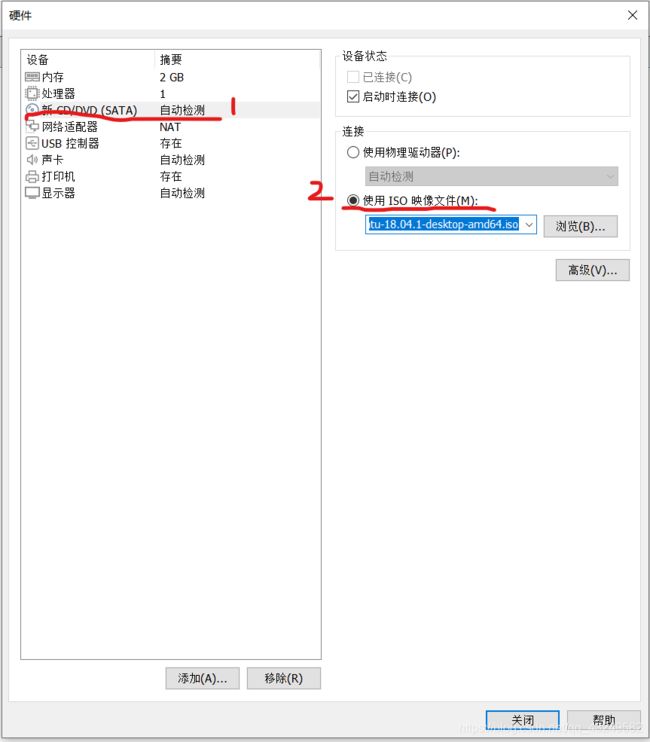
选择使用ISO映像文件,点击浏览找到UbuntuISO镜像文件,然后点击关闭,然后点击完成。
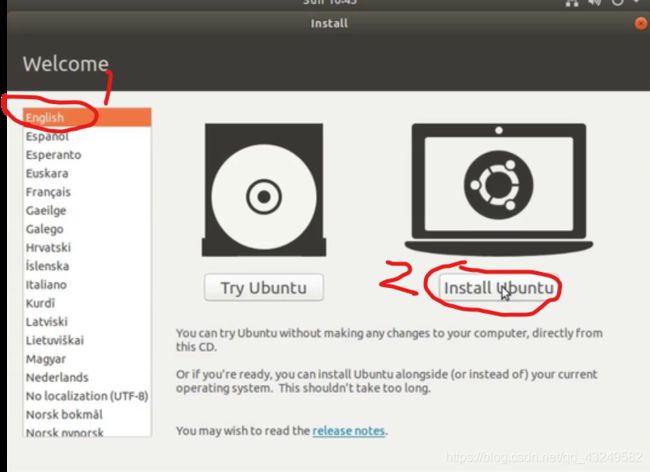
建议大家选择全英的系统,不然后期会很难受

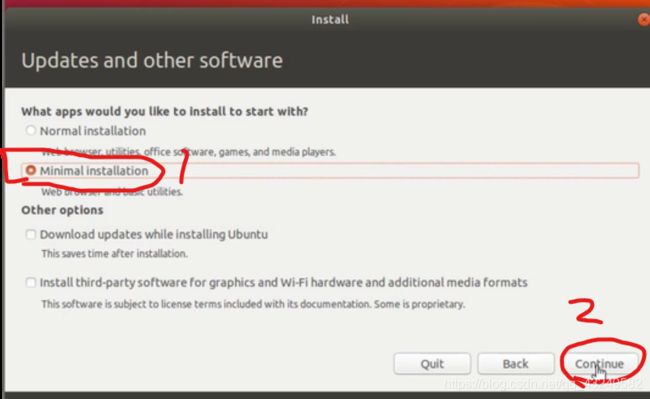
这个是minimal的安装,可以避免很多不需要的软件安装上去

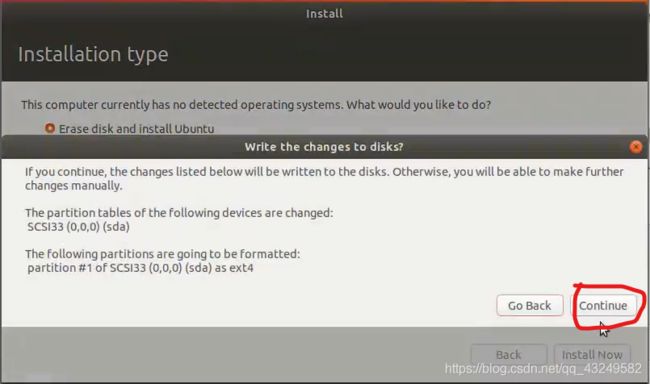
选择上海
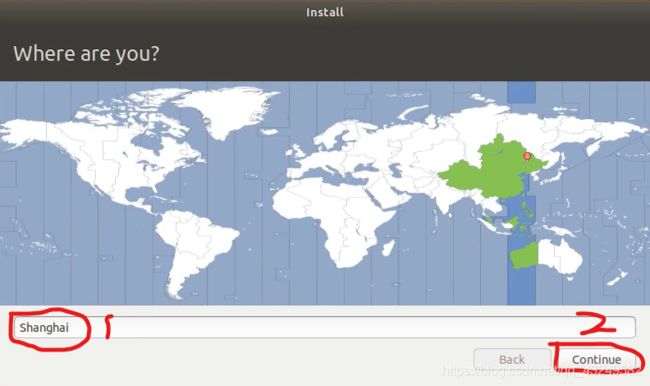
设置用户名和密码,然后Continue
这一步能点Skip就点,不然很慢,因为它用的是国外的镜像源下载,咱们一会去设置国内镜像源。

点击Restart Now

这个界面看英文要回车,别傻等哈。

安装成功,咱们enjoy。

二、Ubuntu的基础配置
1.设置国内镜像源
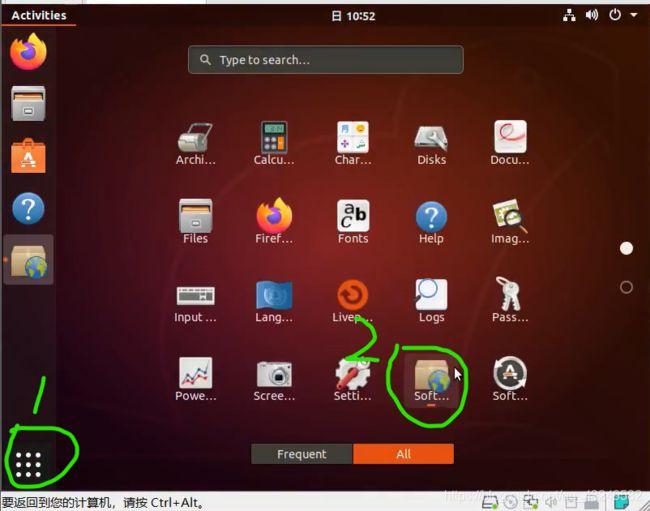

2.下载安装Vmware Tools
由于我已经安装过了,所以我这里显示的是重新安装,你们显示的是安装Vmware Tools,点击就好。Vmware Tools的作用:一个是可以直接从主机拖拽文件到虚拟机;一个是界面大小能够自适应。
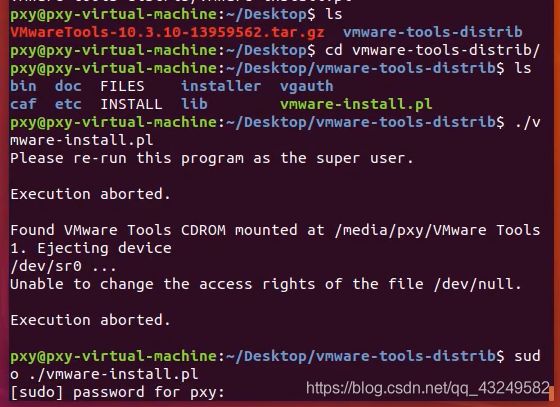
鼠标右键打开terminal,敲入如下命令,回车。(tips:可以使用tab键补全命令)

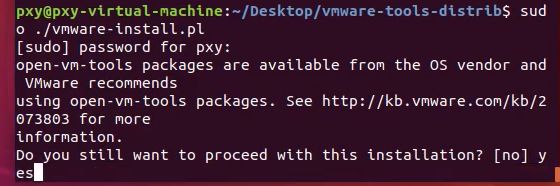
输入一个yes后,一直回车相当于默认每一个选项。
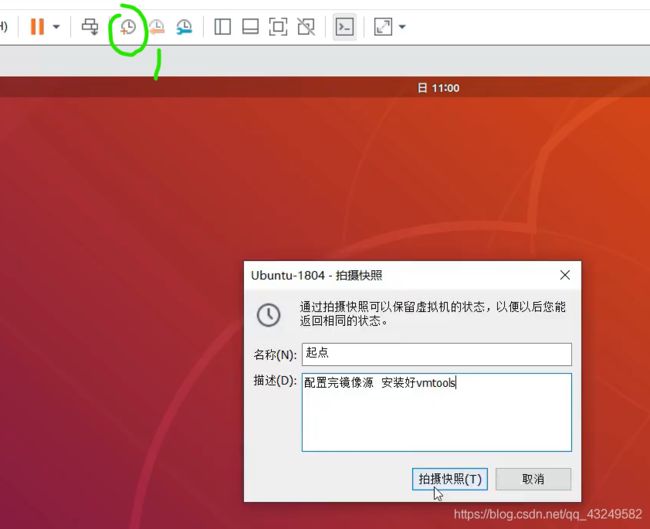
至此镜像源和Vmware Tools已经配置好了,我们最好保存一个快照养成习惯,如果出现问题随时都可以系统到这个位置。
三、安装Hadoop
搜索引擎能翻出去就用Google,不能就用必应。下载链接:https://hadoop.apache.org/release/2.9.2.html
在等待下载的过程中,我们可以先干点别的,按ctrl +alt+t打开终端窗口,执行:sudo apt-get update命令,更新apt,后续我们使用apt安装软件,如果没有更新可能一些软件安装不了。
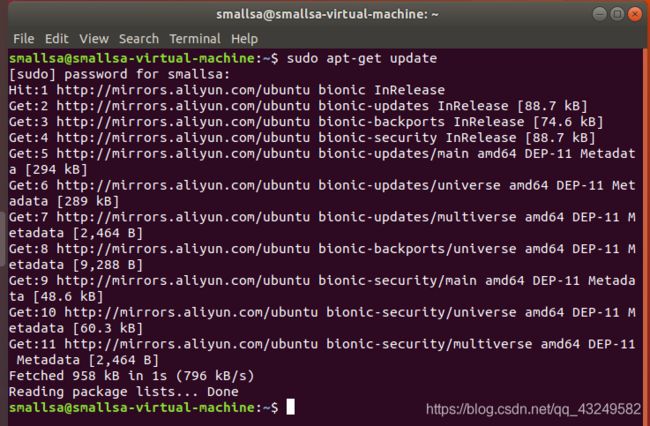
执行:sudo apt-get install vim命令,安装vim,后续使用vim更改一些配置文件。(如果实在不会用vi/vim,请将后面用到vim的地方改为gredit,这样可以使用文本编辑器进行修改,并且每次文件更改完成后请关闭整个gredit程序,否则会占用终端)
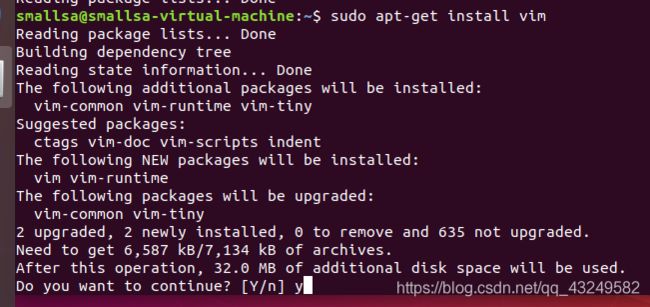
安装SSH、配置SSH无密码登录。集群、单节点模式都需要用到SSH登录,Ubuntu默认已安装了SSH client,此外还需要安装SSH server,执行:sudo apt-get install openssh-server
安装后可以使用如下命令登录本机:
ssh localhost如果有如下提示(SSH首次登录提示),输入yes,然后按提示输入密码,这样就登录到本机了。

但是这样登录是每次需要输入密码的,我们需要配置成SSH无密码登录比较方便。
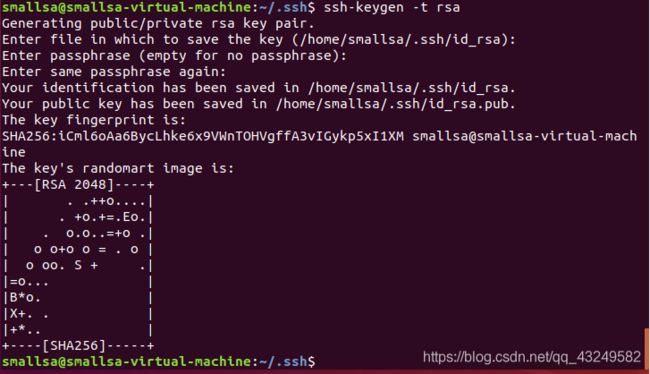
首先退出刚才的ssh,就回到了我们原先的终端窗口,然后利用ssh-keygen生成密钥,并将密钥加入到授权中。
eixt #退出刚刚的ssh localhost
cd ~/.ssh/ #若没有该目录,请先执行
ssh-keygen -t rsa #会有提示,都按回车即可
cat ./id_rsa.pub >> ./authorized_keys #加入授权注意:在执行ssh-keygen -t rsa命令时,敲三下回车。
执行以下命令,安装jdk
sudo apt-get install openjdk-8-jre openjdk-8-jdk
sudo vim ~/.bashrc
按i进入编辑模式,配置JAVA_HOME在圈起来的地方添加
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64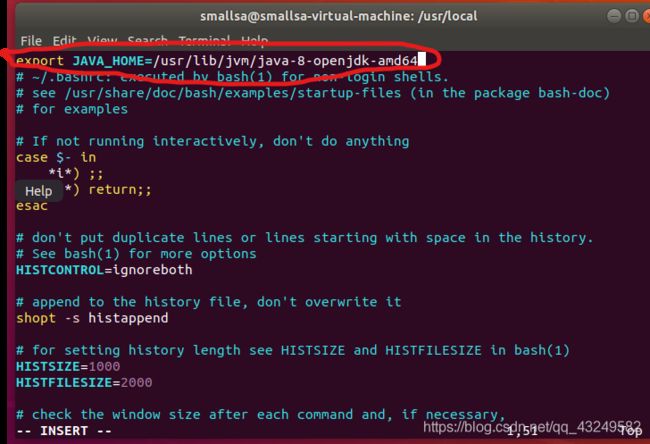
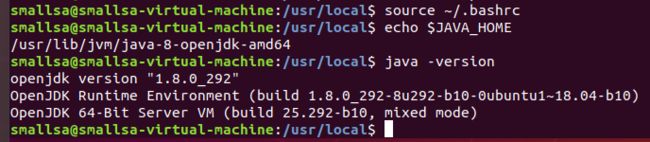
然后按Esc退出编辑模式,然后按冒号“:”,输入wq,即可保存退出。
输入下图中的命令行验证,如果没有错误,则jdk安装成功
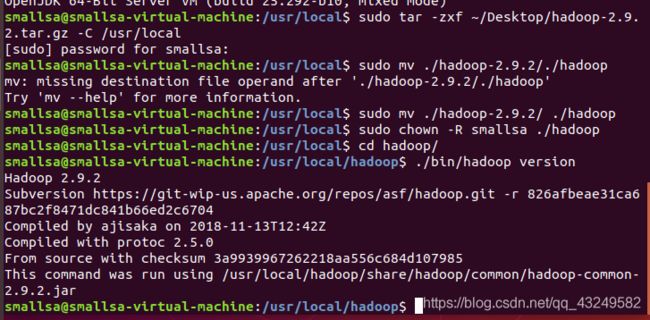
把之前下载的Hadoop安装包拖拽到虚拟机桌面,执行如下命令:
sudo tar -zxf ~/Desktop/hadoop-2.9.2.tar.gz -C /usr/local
sudo mv ./hadoop-2.9.2/./hadoop
sudo chown -R smallsa ./hadoop
cd hadoop/
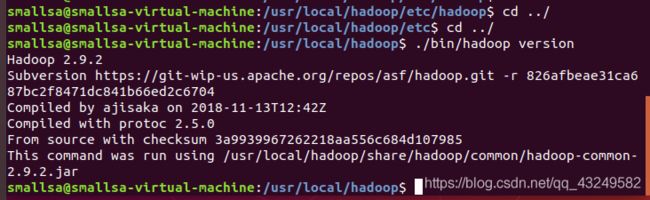
./bin/hadoop version单机版Hadoop安装成功
安装Hadoop伪分布版本
执行以下命令:
ls
cd etc
ls
cd hadoop
ls
vim hadoop-env-sh
将如下命令添加到第一行
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64执行命令:
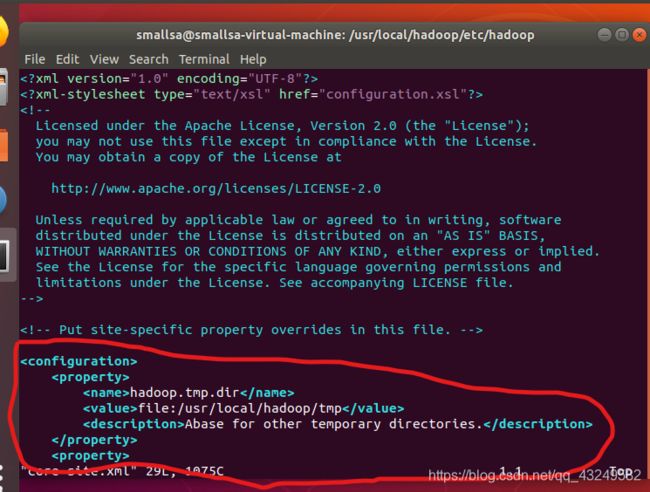
vim core-site.xml添加如下代码到图中的位置:
hadoop.tmp.dir
file:/usr/local/hadoop/tmp
Abase for other temporary directories.
fs.defaultFS
hdfs://localhost:9000
执行命令:
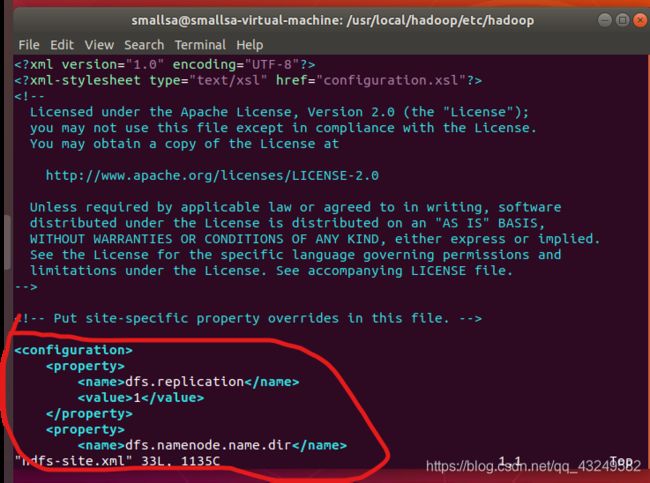
vim hdfs-site.xml添加如下代码到图中位置
dfs.replication
1
dfs.namenode.name.dir
file:/usr/local/hadoop/tmp/dfs/name
dfs.datanode.data.dir
file:/usr/local/hadoop/tmp/dfs/data
测试hadoop
在以伪分布安装完成Hadoop之后,操作流程如下:
1.运行jps,查看当前有哪些进程。
配置完以后,第一次需要格式化,以后就不需要。

2.运行Hadoop
执行命令行:
./sbin/start-dfs.sh #启动hadoop dfs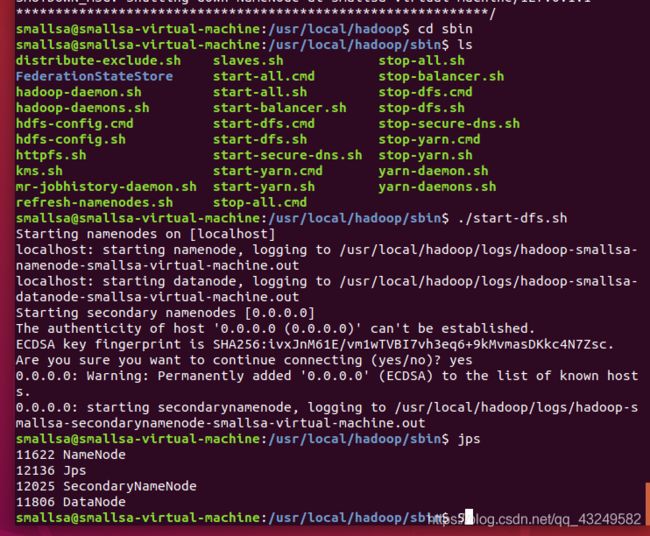
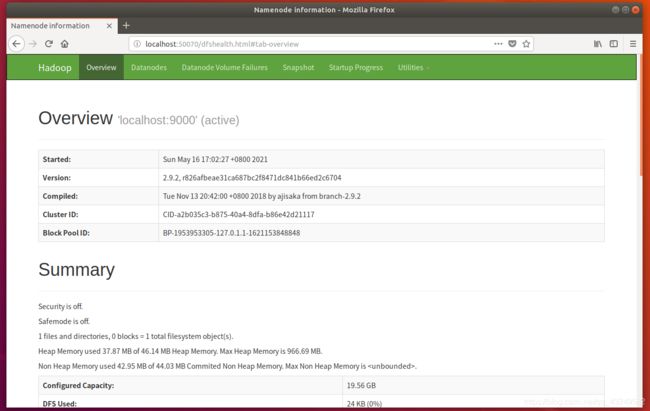
启动完成,jps查看进程,以及网页登陆
快照保存hadoop安装成功的时候,之后会进行spark的安装。