Python之反爬虫手段(User-Agent,Cookie,Referer,time.sleep(),IP代理池)
现在的爬虫越来越难,各大网站为了预防不间断的网络爬虫,都相应地做出了不同的反爬机制,那么如何能够在不被封IP的情况,尽可能多得爬取数据呢?这里主要介绍到一些通用的反爬措施,虽然不一定适合所有网站,但是大部分网站的爬取,个人认为还是可以的。本文主要介绍到User-Agent,Cookie,Referer,time.sleep()设置睡眠间隔,ProxyPool之IP池的搭建,小伙伴们各取所需!
由于后续爬虫案例都默认自带这些反爬技术,所以这里就统一详细介绍下,后续案例就不再过多涉及,废话不多说,开始展开!
1. user-agent
user-agent:是识别浏览器的一串字符串,相当于浏览器的身份证,在利用爬虫爬取网站数据时,频繁更换User-agent可以避免触发相应的反爬机制;
这里,就用到了fake-useragent包,这个包对频繁更换User-agent提供了很好的支持,可谓防反爬利器,那么它如何使用呢?
(1)安装:直接在anaconda控制台安装fake-useragent包即可;
pip install fake-useragent(2)具体代码使用:
form fake-useragent import UserAgent
ua = UserAgent()
headers = {
'User-Agent' : ua.random #随机生成一个UserAgent
}
url = 'https://www.baidu.com/'
page = requests.get(url, headers=headers)2. cookie,referer设置
(1)Cookie
在我们每次访问网站服务器的时候,服务器都会为在我们本地设置cookie,为什么要设置cookie呢?因为服务器要了解我们的身份。在我们下一次访问该服务器的时候,都会带上这个cookie,表明我们的身份。(例如我们在登陆某个网站的时候,在一段时候内再次进行访问,就不需要二次登录)
那么,每个网站的Cookie都不一样,如何找到自己需要的呢?
首先,打开一个特定的网站,比如58同城二手房https://bj.58.com/ershoufang/;在网页空白处右键(最好是chrome或者Firefox),点击【检查】,出现如下图所示的框(右边即为浏览器检查界面)。
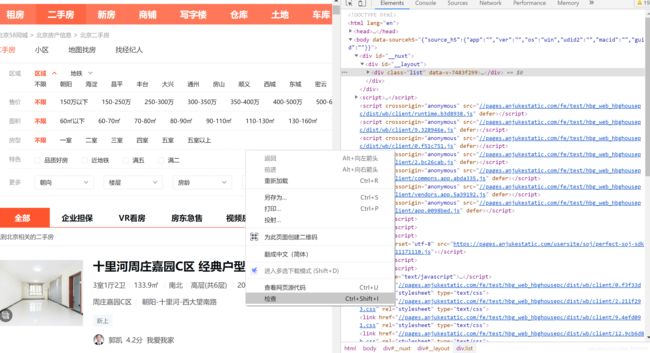
4步走:① 选择【Network】②选择【XHR】③点击浏览器刷新按钮④找到对应的网站请求,点击打开即可。
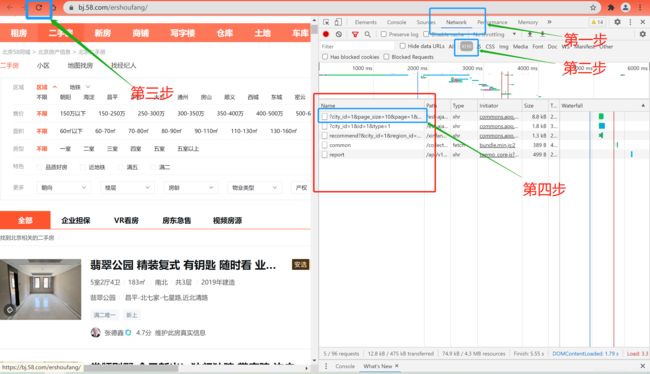

(2)Referer
这个请求参数的作用主要是标识请求是从哪个页面过来的。例如:在登陆某个网站的时候,登陆成功会跳转到个人中心。那么Referer的值就会是登录界面的url。应用场景:来源统计,防盗链处理等;Referer的获取同Cookie,具体如下图所示;个人感觉也可以统一将第一页url作为referer!

3. time.sleep():设置访问时间间隔
很多网站的反爬虫机制都设置了访问间隔时间,一个IP如果短时间内超过了指定的次数就会进入“冷却CD”,所以除了轮换IP和user_agent,可以设置访问的时间间间隔长一点,比如每抓取一个页面休眠一个随机时间:
相对来说,这是一个比较可靠的做法。 因为本来爬虫就可能会给对方网站造成访问的负载压力,所以这种防范既可以从一定程度上防止被封,还可以降低网站的访问压力。如果访问过于频繁,有些网站会直接封掉IP,让你再也无法访问其数据。所以为了保险起见,最好设置下睡眠时间。
那么如何设置访问时间间隔呢?代码很简单,只需在爬取时加到循环里就可以。
import time
import random
time.sleep(random.randint(5,10))
#具体的随机数,可以自行设置,太小的话,作用不大,太大的话,代码运行时间会加长;4. ProxyPool之IP池的搭建
如果一个固定的IP在短暂时间内,快速大量的访问一个网站,那自然会引起管理员注意,于是管理员通过一些手段就会把这个IP给封了,让你爬不到其网站任何数据。目前,解决这个问题比较成熟的方式就是使用IP代理池。简单的说,就是通过IP代理,用不同的IP进行访问,这样在一定程度上就避免封掉IP的风险了。可是IP代理的获取比较麻烦,网上有免费和付费的,但是质量都层次不齐。如果是企业里需要的话,可以通过自己购买集群云服务来自建代理池。那么对于个人户的我们,如何搭建IP代理池呢?
前段时间,在查阅相关资料的时候,发现了一个很好用的IP代理池ProxyPool,关于ProxyPool使用的详细流程见下。
(1)ProxyPool下载
具体的Github下载地址:https://github.com/Python3WebSpider/ProxyPool.git
下载完解压到本地,用Pycharm打开;
(2)ProxyPool使用
① 如果已安装redis数据库,按照下图所示,找到settings.py文件,修改PASSWORD为redis数据库的密码,如果为空,则设置为None。(新安装的redis数据库一般默认没有密码)

② 如果未安装redis数据库,则需要先安装redis数据库,然后才能使用ProxyPool包搭建IP代理池。(Redis数据库安装见文末链接)
(3)安装ProxyPool相关依赖包
在已下载好的ProxyPool-master目录里,找到requirements.txt(很重要),在这个txt文件中,有很多ProxyPool的依赖的Python包。
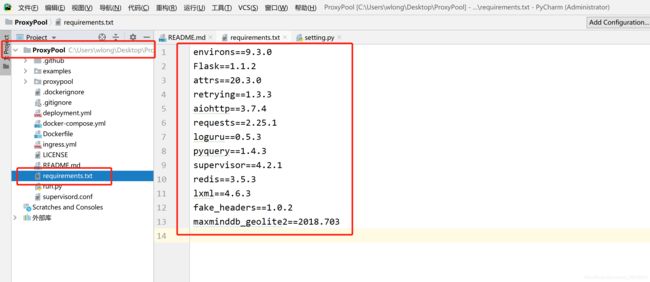
安装方式:三种,经验所谈。(当初在这出了不少错,花费不少时间安装依赖包)
① 如果你的Pycharm是正版的,可以在pycharm直接安装这些包,非常方便;如果不能直接在Pycharm中安装,可以在anaconda或者python的控制台去安装;
② 官网给出的安装方式:(这代码需要稍微更改下,当初这句代码一直运行不了,主要是这个txt当初没找到,找到后也没有运行成功,后来认真想了想,发现是路径的问题),下面这句代码需改成:pip install -r 绝对路径/requirements.txt (其中,绝对路径根据自己所放的地方来,文件就在ProxyPool-master的目录里);

③ 如果前两种方法都不能运行的话,还有一种相对比较麻烦的方法,就是在anaconda控制台,将文件里的这些包通过pip一个个的安装,例如:pip install environs=9.3.0;
(4)开启Redis服务器
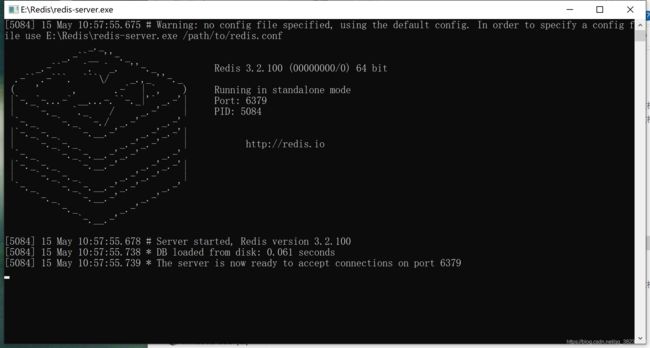
找到Redis的下载目录,直接双击打开redis-server.exe,出现如下图所示界面,即表示Redis服务器开启成功,Redis的默认端口为6379。
(5)运行ProxyPool-master目录中的run.py文件
在Pycharm中,找到ProxyPool-master项目目录下的run.py文件,然后运行该python文件
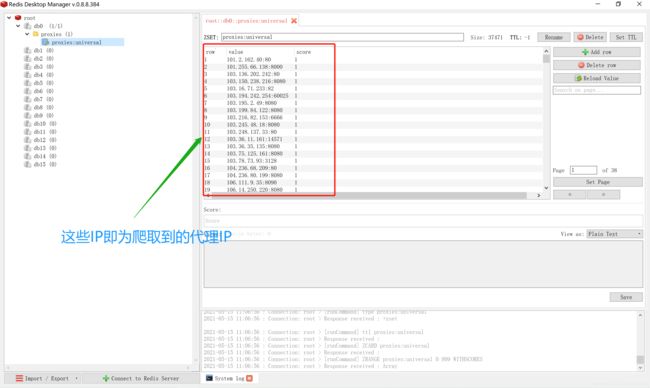
运行run.py后,不要停止项目,这时可以打开redis管理工具(RedisDesktopManager,这个管理工具也需要下载,下载后需连接到Redis数据库,安装教程见文末链接),从中能够查看爬取到的所有代理IP。
ProxyPool-master项目运行过程中,千万不要点击【停止运行】按钮,如果项目停止了,就无法访问代理池了。那么如何访问并获取到Redis数据库存的这些IP呢?
(6)访问并获取Redis数据库中的代理IP
在项目刚开始运行时,我们可以看到运行窗口如下图。
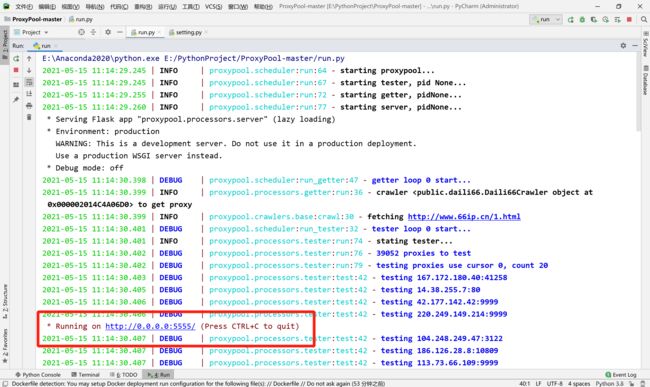
在上图中,我们可以看到有如下这么一行语句,这句话告诉我们随机访问地址URL是多少。
Running on http://0.0.0.0:5555/ (Press CTRL+C to quit)
我们在浏览器地址栏中,输入:
http://0.0.0.0:5555/random出现错误,该网址无法访问!为什么出错呢?

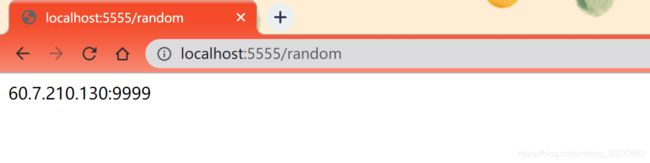
后来根据自己理解想了想,这个0.0.0.0可能与本地地址有关,于是我将0.0.0.0换成localhost试了试,网址如下。
http://localhost:5555/random运行成功!随机获取到了Redis数据库中的一个IP,但是关于0.0.0.0无法访问,而localhost可以访问,具体原因我还是不太清楚,希望后续查阅相关资料,再来作详细说明,如果有小伙伴知道,可以在后续留言哦,一起学习。
(7)最终,如何将从IP代理池随机获取到的IP应用到爬虫程序中呢?
以爬取安居客二手房小区名称为例,应用UserAgent,Cookie,referer,ProxyPool这些反爬手段,并作简要说明。
(注:该案例只是为了应用反爬技术,至于更详细的步骤见后续爬虫案例。)
# 以爬取安居客二手房小区名称为例
import requests
from fake_useragent import UserAgent
from lxml import etree
ua = UserAgent()
headers = {
"user-agent" : ua.random, #随机生成User-Agent;
"cookie" : "xxx",# 根据自己浏览器自行获取,方法见上;
"referer" : "https://www.anjuke.com/", #设置从何网页跳转过来的
}
#从代理IP池中随机获取一个IP
def get_proxy():
try:
PROXY_POOL_URL = 'http://localhost:5555/random'
response = requests.get(PROXY_POOL_URL)
if response.status_code == 200:
return response.text
except ConnectionError:
return None
url = 'https://sjz.anjuke.com/community' # 以安居客二手房为例
text = requests.get(url=url, headers=headers, proxies={"http": "http://{}".format(get_proxy())}).text
html = etree.HTML(text)
community_name = html.xpath('.//div[@class="comm-title"]/h1/text()')
print(community_name)
好了,到此有关反爬虫手段就讲解结束了,如果哪里有不完善或者出错的地方,欢迎大家帮忙指正,我会继续完善的!关于上文中未提到的Redis数据库以及RedisDesktopManager管理工具的下载与安装,这里就不详细去介绍了,因为我也是从各大博客中摸索的,这里就先把我找的资料放在这,大家各取所需哈,望体谅,如果后续关于这方面,自己有更深的理解,或许会写篇博客记录下。
参考资料如下:
(1)Redis数据库:
Redis的安装教程(Windows+Linux)【超详细】:
https://blog.csdn.net/weixin_43883917/article/details/114632709
本地redis服务安装:
https://blog.csdn.net/qiucheng_198806/article/details/90479813(2)Redis Desktop Manager管理工具:
Redis Desktop Manager的下载及安装:
https://www.jianshu.com/p/6895384d2b9e(3)关于安装ProxyPool参考资料:
教你自己搭建一个ip池(绝对超好用!!!!):
https://blog.csdn.net/weixin_44517301/article/details/103393145 #文末也讲解了Redis Desktop Manager安装教程
python爬虫添加代理ip池ProxyPool (Windows):
https://blog.csdn.net/qq_34442867/article/details/110817267
python爬虫18 | 就算你被封了也能继续爬,使用IP代理池伪装你的IP地址,让IP飘一会
https://zhuanlan.zhihu.com/p/59951949
如何使用 — ProxyPool 2.1.0 文档:
https://proxy-pool.readthedocs.io/zh/latest/user/how_to_use.html这一小节结束,后续就会开始各大网站的爬虫案例啦,内容较多,慢慢更新哈,奥里给,冲冲冲!
来都来了,确定不留下点什么嘛,嘻嘻~
