迁移到其他机器_有赞大数据离线集群迁移实战

点击关注“有赞coder”
获取更多技术干货哦~
 作 者:郭理想 & 任海潮 部门:数据中台
作 者:郭理想 & 任海潮 部门:数据中台
一、背景
有赞是一家商家服务公司,向商家提供强大的基于社交网络的,全渠道经营的 SaaS 系统和一体化新零售解决方案。随着近年来社交电商的火爆,有赞大数据集群一直处于快速增长的状态。在 2019 年下半年,原有云厂商的机房已经不能满足未来几年的持续扩容的需要,同时考虑到提升机器扩容的效率(减少等待机器到位的时间)以及支持弹性伸缩容的能力,我们决定将大数据离线 Hadoop 集群整体迁移到其他云厂商。 在迁移前我们的离线集群规模已经达到 200+ 物理机器,每天 40000+ 调度任务,本次迁移的目标如下:- 将 Hadoop 上的数据从原有机房在有限时间内全量迁移到新的机房
- 如果全量迁移数据期间有新增或者更新的数据,需要识别出来并增量迁移
- 对迁移前后的数据,要能对比验证一致性(不能出现数据缺失、脏数据等情况)
- 迁移期间(可能持续几个月),保证上层运行任务的成功和结果数据的正确
有赞大数据离线平台技术架构
上文说了 Hadoop 集群迁移的背景和目的,我们回过头来再看下目前有赞大数据离线平台整体的技术架构,如图1.1所示,从低往上看依次包括: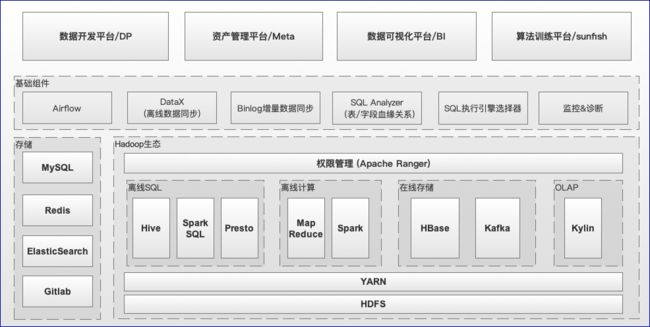 图1.1 有赞大数据离线平台的技术架构
图1.1 有赞大数据离线平台的技术架构
- Hadoop 生态相关基础设施,包括 HDFS、YARN、Spark、Hive、Presto、HBase、Kafka、Kylin等
- 基础组件,包括 Airflow (调度)、DataX (离线数据同步)、基于binlog的增量数据同步、SQL解析/执行引擎选择服务、监控&诊断等
- 平台层面,包括: 数据开发平台(下文简称DP)、资产管理平台、数据可视化平台、算法训练平台等
二、方案调研
在开始迁移之前,我们调研了业界在迁移 Hadoop 集群时,常用的几种方案:2.1 单集群
两个机房公用一个 Hadoop 集群(同一个Active NameNode,DataNode节点进行双机房部署),具体来讲有两种实现方式:- (记为方案A) 新机房DataNode节点逐步扩容,老机房DataNode节点逐步缩容,缩容之后通过 HDFS 原生工具 Balancer 实现 HDFS Block 副本的动态均衡,最后将Active NameNode切换到新机房部署,完成迁移。这种方式最为简单,但是存在跨机房拉取 Shuffle 数据、HDFS 文件读取等导致的专线带宽耗尽的风险,如图2.1所示
- (记为方案B) 方案 A 由于两个机房之间有大量的网络传输,实际跨机房专线带宽较少情况下一般不会采纳,另外一种带宽更加友好的方案是:
- 通过Hadoop 的 Rack Awareness 来实现 HDFS Block N副本双机房按比例分布(通过调整 HDFS 数据块副本放置策略,比如常用3副本,两个机房比例为1:2)
- 通过工具(需要自研)来保证 HDFS Block 副本按比例在两个机房间的分布(思路是:通过 NameNode 拉取 FSImage,读取每个 HDFS Block 副本的机房分布情况,然后在预定限速下,实现副本的均衡)
 图2.1 单集群迁移方案
优点:
图2.1 单集群迁移方案
优点:
- 对用户透明,基本无需业务方投入
- 数据一致性好
- 相比多集群,机器成本比较低
- 需要比较大的跨机房专线带宽,保证每天增量数据的同步和 Shuffle 数据拉取的需要
- 需要改造基础组件(Hadoop/Spark)来支持本机房优先读写、在限速下实现跨机房副本按比例分布等
- 最后在完成迁移之前,需要集中进行 Namenode、ResourceManager 等切换,有变更风险
2.2 多集群
在新机房搭建一套新的 Hadoop 集群,第一次将全量 HDFS 数据通过 Distcp 拷贝到新集群,之后保证增量的数据拷贝直至两边的数据完全一致,完成切换并把老的集群下线,如图2.2所示。 这种场景也有两种不同的实施方式:- (记为方案C) 两边 HDFS 数据完全一致后,一键全部切换(比如通过在DP上配置改成指向新集群),优点是用户基本无感知,缺点也比较明显,一键迁移的风险极大(怎么保证两边完全一致、怎么快速识别&快速回滚)
- (记为方案D) 按照DP上的任务血缘关系,分层(比如按照数据仓库分层依次迁移 ODS / DW / DM 层数据)、分不同业务线迁移,优点是风险较低(分治)且可控,缺点是用户感知较为明显
 图2.2 多集群迁移方案
优点:
图2.2 多集群迁移方案
优点:
- 跨机房专线带宽要求不高(第一次全量同步期间不跑任务,后续增量数据同步,两边双跑任务不存在跨机房 Shuffle 问题)
- 风险可控,可以分阶段(ODS / DW / DM)依次迁移,每个阶段可以验证数据一致性后再开始下一阶段的迁移
- 不需要改造基础组件(Hadoop/Spark)
- 对用户不透明,需要业务方配合
- 在平台层需要提供工具,来实现低成本迁移、数据一致性校验等
2.3 方案评估
从用户感知透明度来考虑,我们肯定会优先考虑单集群方案,因为单集群在迁移过程中,能做到基本对用户无感知的状态,但是考虑到如下几个方面的因素,我们最终还是选择了多集群方案:- (主因)跨机房的专线带宽大小不足。上述单集群的方案 A 在 Shuffle 过程中需要大量的带宽使用;方案 B 虽然带宽更加可控些,但副本跨机房复制还是需要不少带宽,同时前期的基础设施改造成本较大
- (次因)平台上的任务类型众多,之前也没系统性梳理过,透明的一键迁移可能会产生稳定性问题,同时较难做回滚操作
三、实施过程
在方案确定后,我们便开始了有条不紊的迁移工作,整体的流程如图3.1所示 图3.1 离线Hadoop多集群跨机房迁移流程图 上述迁移流程中,核心要解决几个问题:
图3.1 离线Hadoop多集群跨机房迁移流程图 上述迁移流程中,核心要解决几个问题:
- 第一次全量Hadoop数据复制到新集群,如何保证过程的可控(有限时间内完成、限速、数据一致、识别更新数据)?(工具保证)
- 离线任务的迁移,如何做到较低的迁移成本,且保障迁移期间任务代码、数据完全一致?(平台保证)
- 完全迁移的条件怎么确定?如何降低整体的风险?(重要考虑点)
3.1 Hadoop 全量数据复制
首先我们在新机房搭建了一套 Hadoop 集群,在进行了性能压测和容量评估后,使用 DistCp 工具在老集群资源相对空闲的时间段做了 HDFS 数据的全量复制,此次复制 HDFS 数据时新集群只开启了单副本,整个全量同步持续了两周。基于 DistCp 本身的特性(带宽限制:-bandwidth / 基于修改时间和大小的比较和更新:-update)较好的满足全量数据复制以及后续的增量更新的需求。3.2 离线任务的迁移
目前有赞所有的大数据离线任务都是通过 DP 平台来开发和调度的,由于底层采用了两套 Hadoop 集群的方案,所以迁移的核心工作变成了怎么把 DP 平台上任务迁移到新集群。3.2.1 DP 平台介绍
有赞的 DP 平台是提供用户大数据离线开发所需的环境、工具以及数据的一站式平台(更详细的介绍请参考另一篇 博客 ),目前支持的任务主要包括:- 离线导入任务( MySQL 全量/增量导入到 Hive)
- 基于binlog的增量导入 (数据流:binlog -> Canal -> NSQ -> Flume -> HDFS -> Hive)
- 导出任务(Hive -> MySQL、Hive -> ElasticSearch、Hive -> HBase 等)
- Hive SQL、Spark SQL 任务
- Spark Jar、MapReduce 任务
- 其他:比如脚本任务
3.2.2 DP 任务状态一致性保证
在新旧两套 DP 平台都允许用户创建和更新任务的前提下,如何保证两边任务状态一致呢(任务状态不限于MySQL的数据、Gitlab的调度文件等,因此不能简单使用MySQL自带的主从复制功能)?我们采取的方案是通过事件机制来实现任务操作时间的重放,展开来讲:- 用户在老 DP 产生的操作(包括新建/更新任务配置、任务测试/发布/暂停等),通过事件总线产生事件消息发送到 Kafka,新系统通过订阅 Kafka 消息来实现事件的回放,如图 3.2 所示。
 图3.2 通过事件机制,来保证两个平台之间的任务状态一致
图3.2 通过事件机制,来保证两个平台之间的任务状态一致
3.2.3 DP 任务迁移状态机设计
DP 底层的改造对用户来说是透明的,最终暴露给用户的仅是一个迁移界面,每个工作流的迁移动作由用户来触发。工作流的迁移分为两个阶段:双跑和全部迁移,状态流转如图 3.3 所示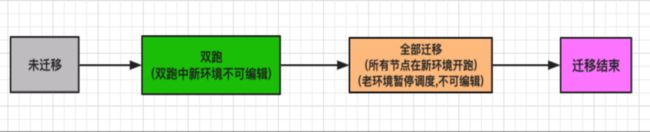 图 3.3 工作流迁移状态流转
图 3.3 工作流迁移状态流转
双跑
工作流的初始状态为未迁移,然后用户点击迁移按钮,会弹出迁移界面,如图 3.4 所示,用户可以指定工作流的任意子任务的运行方式,主要选项如下:两边都跑:任务在新老环境都进行调度
老环境跑:任务只在老环境进行调度
新环境跑:任务只在新环境进行调度
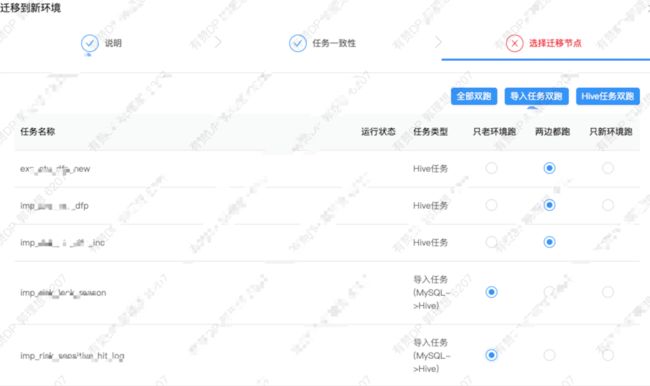
导入任务 (MySQL -> Hive):通常是双跑,也就是两个集群在调度期间都会从业务方的 MySQL 拉取数据(由于拉取的是 Slave 库,且全量拉取的一般是数据量不太大的表)
Hive、SparkSQL 任务:通常也是双跑,双跑时新老集群都会进行计算。
MapReduce、Spark Jar 任务:需要业务方自行判断:任务的输出是否是幂等的、代码中是否配置了指向老集群的地址信息等
导出任务:一般而言无法双跑,如果两个环境的任务同时向同一个 MySQL表(或者 同一个ElasticSearch 索引)写入/更新数据,容易造成数据不一致,建议在验证了上游 Hive 表数据在两个集群一致性后进行切换(只在新环境跑)。
同时处于用户容易误操作导致问题的考虑,DP 平台在用户设置任务运行方式后,进行必要的规则校验:
如果任务状态是双跑,则任务依赖的上游必须处于双跑的状态,否则进行报错。
如果任务是第一次双跑,会使用 Distcp 将其产出的 Hive 表同步到新集群,基于 Distcp 本身的特性,实际上只同步了在第一次同步之后的增量/修改数据。
- 如果工作流要全部迁移(老环境不跑了),则工作流的下游必须已经全部迁移完。

图 3.5 DP 任务双跑期间数据流向
迁移过程中工作流操作的限制规则
由于某个工作流迁移的持续时间可能会比较长(比如DW层任务需要等到所有DM层任务全部迁移完),因此我们既要保证在迁移期间工作流可以继续开发,同时也要做好预防误操作的限制,具体规则如下:- 迁移中的工作流在老环境可以进行修改和发布的,新环境则禁止
- 工作流在老环境修改发布后,会将修改的元数据同步到新环境,同时对新环境中的工作流进行发布。
- 工作流全部迁移,需要所有的下游已经完成全部迁移。
3.3 有序推动业务方迁移
工具都已经开发好了,接下来就是推动 DP 上的业务方进行迁移,DP 上任务数量大、种类多、依赖复杂,推动业务方需要一定的策略和顺序。有赞的数据仓库设计是有一定规范的,所以我们可以按照任务依赖的上下游关系进行推动:- 导入任务( MySQL 全量/增量导入 Hive) 一般属于数据仓库的 ODS 层,可以进行全量双跑。
- 数仓中间层任务主要是 Hive / Spark SQL 任务,也可以全量双跑,在验证了新老集群的 Hive 表一致性后,开始推动数仓业务方进行迁移。
- 数仓业务方的任务一般是 Hive / Spark SQL 任务和导出任务,先将自己的 Hive 任务双跑,验证数据一致性没有问题后,用户可以选择对工作流进行全部迁移,此操作将整个工作流在新环境开始调度,老环境暂停调度。
- 数仓业务方的工作流全部迁移完成后,将导入任务和数仓中间层任务统一在老环境暂停调度。
- 其他任务主要是 MapReduce、Spark Jar、脚本任务,需要责任人自行评估。
3.4 过程保障
工具已经开发好,迁移计划也已经确定,是不是可以让业务进行迁移了呢?慢着,我们还少了一个很重要的环节,如何保证迁移的稳定呢?在迁移期间一旦出现 bug 那必将是一个很严重的故障。因此如何保证迁移的稳定性也是需要着重考虑的,经过仔细思考我们发现问题可以分为三类,迁移工具的稳定,数据一致性和快速回滚。迁移工具稳定
- 新 DP 的元数据同步不及时或出现 Bug,导致新老环境元数据不一致,最终跑出来的数据必定天差地别。
- 应对措施:通过离线任务比对两套 DP 中的元数据,如果出现不一致,及时报警。
- 工作流在老 DP 修改发布后,新 DP 工作流没发布成功,导致两边调度的 airflow 脚本不一致。
- 应对措施:通过离线任务来比对 airflow 的脚本,如果出现不一致,及时报警。
- 全部迁移后老环境 DP 没有暂定调度,导致导出任务生成脏数据。
- 应对措施:定时检测全部迁移的工作流是否暂停调度。
- 用户设置的运行状态和实际 airflow 脚本的运行状态不一致,比如用户期望新环境空跑,但由于程序 bug 导致新环境没有空跑。
- 应对措施:通过离线任务来比对 airflow 的脚本运行状态和数据库设置的状态。
Hive 表数据一致性
Hive 表数据一致性指的是,双跑任务产出的 Hive 表数据,如何检查数据一致性以及识别出来不一致的数据的内容,具体方案如下(如图3.6所示):- 双跑的任务在每次调度运行完成后,我们会上报 信息,用于数据质量校验(DQC),等两个集群产出的表A都准备好了,就触发数据一致性对比
- 根据 参数提交一个 MapReduce Job,由于我们的 Hive 表格式都是以 Orc格式存储,提交的 MapReduce Job 在 MapTask 中会读取表的任意一个 Orc 文件并得到 Orc Struct 信息,根据用户指定的表唯一键,来作为 Shuffle Key,这样新老表的同一条记录就会在同一个 ReduceTask 中处理,计算得到数据是否相同,如果不同则打印出差异的数据
- 表数据比对不一致的结果会发送给表的负责人,及时发现和定位问题
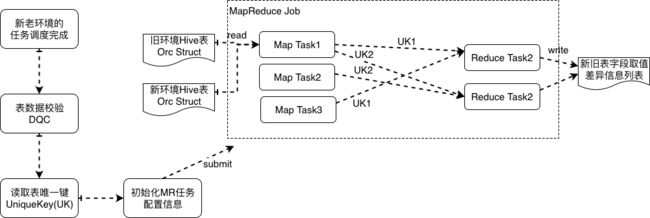
图 3.6 Hive表新老集群数据一致性校验方案
四、迁移过程中的问题总结
- 使用 DistCp 同步 HDFS 数据时漏配参数(-p),导致 HDFS 文件 owner 信息不一致。
- 使用 DistCp 同步 HDFS 数据时覆盖了 HBase 的 clusterId,导致 Hbase 两个集群之间同步数据时发生问题。
- 在迁移开始后,新集群的 Hive 表通过 export import 表结构来创建,再使用 DistCp 同步表的数据。导致 Hive meta 信息丢失了 totalSize 属性,造成了 Spark SQL 由于读取不到文件大小信息无法做 broadcast join,解决方案是在 DistCp 同步表数据之后,执行 Hive 命令 ANALYZE TABLE TABLE_NAME COMPUTE STATISTICS 来生成表相关属性。
- 迁移期间由于在夜间启动了大量的 MapReduce 任务,进行 Hive 表数据比对,占用太多离线集群的计算资源,导致任务出现了延迟,最后将数据比对任务放在资源相对空闲的时间段。
- 工作流之间存在循环依赖,导致双跑-全部迁移的流程走不下去,所以数仓建设的规范很重要,解决方案就是要么让用户对任务重新组织,来重构工作流的依赖关系,要么两个工作流双跑后,一起全部迁移。
- 迁移期间在部分下游已经全部迁移的情况下,上游出现了问题需要重刷所有下游,由于只操作了老 DP,导致新环境没有重刷,使迁移到新环境的下游任务受到了影响。
- MapReduce 和 Spark Jar 类型的任务无法通过代码来检测生成的上下游依赖关系,导致这类任务只能由用户自己来判断,存在一定的风险,后续会要求用户对这类任务也配上依赖的 Hive 表和产出的 Hive 表。
五、总结与展望
本次的大数据离线集群跨机房迁移工作,时间跨度近6个月(包括4个月的准备工作和2个月的迁移),涉及PB+的数据量和4万日均调度任务。虽然整个过程比较复杂(体现在涉及的组件众多、任务种类和实现复杂、时间跨度长和参与人员众多),但通过前期的充分调研和探讨、中期的良好迁移工具设计、后期的可控推进和问题修复,我们做到了整体比较平稳的推进和落地。同时针对迁移过程中遇到的问题,在后续的类似工作中我们可以做的更好:- 做好平台的治理,比如代码不能对当前环境配置有耦合
- 完善迁移工具,尽量让上层用户无感知
- 单 Hadoop 集群方案的能力储备,主要解决跨机房带宽的受控使用
有赞埋点实践
有赞埋点质量保障
Flink 滑动窗口优化
基于时间加权的用户购买类目意愿计算
有赞推荐系统关键技术
有赞数据中台建设实践
数据资产,赞之治理
SparkSQL在有赞大数据的实践(二)
HBase Bulkload 实践探讨
Vol.323
最后打个小广告:
有赞数据中台团队长期招人
期待你的加入~
大数据开发、数据仓库、数据产品、
算法、基础组件
欢迎投递简历:
加入我们,一起enjoy~
