pyechart数据可视化丨制作桑基图(sankey)的最简单方法
前言
最近在分析超期库存数据, 每天4万条左右, 数据的特点是有很多分类变量, 为了展现这些变量的关系, 想到了桑吉图。
Pyechart官网上有关于桑基图的案例, 但是如何用日常使用的excel数据整理成作图的数据, 却没有说明, 今天我们介绍下制作桑吉图的4个步骤。
本案例以泰坦尼克号乘客数据为例, 效果图如下:


目录
-
- 1 读取数据
- 2 整理成3列数据
- 3 生成作图数据
- 4 作图
- 5 注意点
1 读取数据
数据为excel表格, 前几列都为分类变量, 最后一列是需要计数或者求和的变量,在桑基图上显示为流量大小。
from pyecharts import options as opts
from pyecharts.charts import Sankey
import pandas as pd
import numpy as np
import json
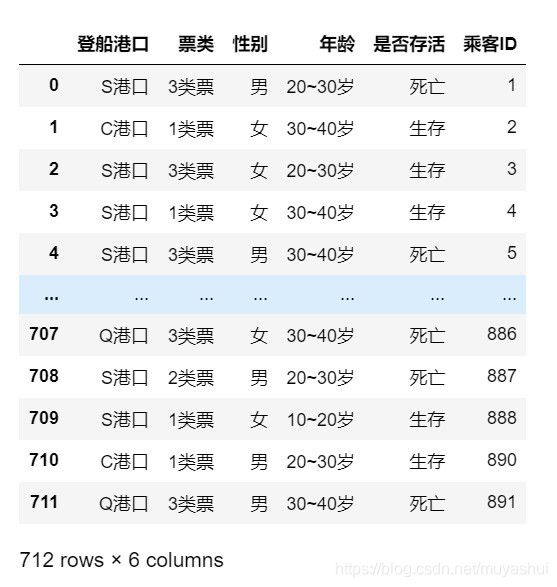
data1 = pd.read_excel('./泰坦尼克数据.xlsx')
data1
2 整理成3列数据
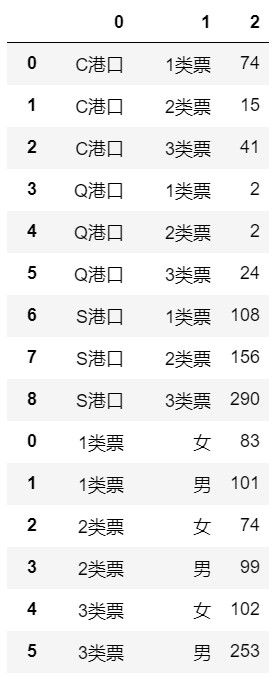
数据转换成 父类→子类→值 这种格式;
从父类到子类, 每相邻的两个分类变量都需要计算. 使用pandas中数据透视表(pivot_table)方法, 计算后的数据纵向合并
# 名称列表
lis = data1.columns.tolist()[:-1]
# 两个子list
lis1 = lis[:-1]
lis2 = lis[1:]
data2 = pd.DataFrame()
for i in zip(lis1,lis2):
datai = data1.pivot_table('乘客ID',index=list(i),aggfunc='count').reset_index()
datai.columns=[0,1,2]
data2 = data2.append(datai)
data2
3 生成作图数据
网上有很多资料说nodes和links需要是json格式, 在这里面实际上就是一个列表(list), 列表中每个元素都是一个字典;
重点注意: 需要将所有的节点都添加上. 而根据上面转换后的数据, 数据的第2列(列名称为1)有所有的节点名称除了顶级节点(原数据中第1列的分类), 此数据中顶级节点包括3个(C港口、Q港口、S港口)
数据转换思路: 构造一个空的列表(list); for循环; 构造一个空的字典(dict)并添加数据; 字典添加到列表中
3.1 生成nodes数据
# 生成nodes
nodes = []
# 先添加几个顶级的父节点
nodes.append({
'name':'C港口'})
nodes.append({
'name':'Q港口'})
nodes.append({
'name':'S港口'})
# 添加其他节点
for i in data2[1].unique():
dic = {
}
dic['name'] = i
nodes.append(dic)
nodes

3.2 生成linkds数据
links = []
for i in data2.values:
dic = {
}
dic['source'] = i[0]
dic['target'] = i[1]
dic['value'] = i[2]
links.append(dic)

4 作图
调用Sankey; 通过init_opts 设置图表大小和图表主题
c = (
Sankey(init_opts=opts.InitOpts(width="1200px", height="800px",theme='westeros'))
.add(
"",
nodes=nodes, # 结点
links=links, # 联系
linestyle_opt=opts.LineStyleOpts(opacity=0.2, curve=0.5, color="source"),
label_opts=opts.LabelOpts(position="right"),
)
.set_global_opts(title_opts=opts.TitleOpts(title="泰坦尼克号数据可视化"))
.render("C:/Users/yyz/desktop/ABC.html")
)
5 注意点
- 原数据中, 不同分类变量之间的名称(节点名)不能相同, 如果相同可在名称前用数字编号区别
- 节点不能太多
- 本例是将需要计数或者求和的变量放在了最后面, 分类变量在前
如果对你帮助, 欢迎点赞、关注!
相关阅读:
pyechart可视化18式丨从柱形图的变化, 搞懂pyechart作图套路
懂点excel作图, 怎么让pyechart作的图更具“职场范“呢?
8个常用的python办公室自动化技巧,学会了同事都找你!
学习python数据分析的30个练手数据+4个数据集网站
[工作必备]pandas数据分析处理52个常用技巧