c++vstextouta怎么用_计算机自制操作系统(十二):用C语言开发内核,详析C语言机制...
一、为什么要用C语言
我曾经的理想是一直用汇编语言来编写操作系统,因为只有用汇编语言才能感觉到自己是下沉到计算机的最底层来控制它,一旦动用了其它的更高级的语言(如C语言),会让自己觉得自己的工作再也不那么“纯粹”了。因为高级语言是建立在已有操作系统和别的编译器基础之上的。我们的目标本来就是从0开始造一个操作系统,可是还没写出来之前就先用了别人的操作系统和工具了,这样的感觉让人感到气馁。
但是,换个角度想就完全有不同的感受了。难道用汇编语言来写操作系统就没有建立在别人的工作基础之上吗?一样的需要汇编语言汇编器啊,别人同样为你做了很多的工作。我们在前面写汇编语言编写操作系统的过程中,用了无数的工具、软件和API(如BIOS中断)等,这些全都是建立在别人的工作基础上的。哪怕是你用纯粹的机器代码来写操作系统,最后把机器代码写进启动设备的时候,还得借用别人做好的工具呢。就算你有办法把机器代码弄进设备里面,计算机识别机器代码并正确执行还需要硬件电路支持呢;硬件电路需要数字电路,数字电路需要电子设备,电子设备需要半导体,半导体需要物理材料......因此,你究竟觉得应该从哪里做起才叫从0开始呢?这显然是没有止境的。
但是,这个世界确实有只用汇编语言来编写的操作系统。大名鼎鼎的MenuetOS就是:
MenuetOSwww.menuetos.net而且这个操作系统的优秀让人吃惊:像WINDOWS一样的一个包含各种功能的视窗操作系统,它的安装镜像全部加起来只有一张软盘(1.44MB)大小,所以汇编语言的优势是十分明显的。虽然仅用汇编语言编写且容量如此渺小,但是这个操作系统可以打游戏、办公、上网、看电影等,是两个国外的牛人坚持了数10年之久完成的杰作。惊叹于他们的这份毅力和坚持,是我一直崇拜的偶像。从某种程度上讲,此专栏的诞生就是受到他们的启发而作。
但是,我在自制操作系统进入到32位之后,坚持用汇编语言的想法却一下就改变了。在16位的实模式下,操作系统主要涉及MBR启动、磁盘读写、BIOS中断、内核装载LOADER、进入保护模式等流程,这些都是汇编语言的强项,因此操作系统在进入32位保护模式前,用汇编语言是最好的选择。但是在进入32位之后,重点的工作就是开发操作系统内核了,开发内核涉及的工作就太多了。保护模式下,BIOS中断再也不能使用了,一切计算机硬件设备的控制都需要自己来编程,硬件涉及显卡、键盘、鼠标、硬盘......软件涉及进程、任务、调度。这些工作的完成如果再用汇编语言的话,工程量就太大了。
这是因为汇编语言最大的劣势是缺乏足够的封装,一切的运算和操作都需要自己来设计,这就要求开发人员必须要非常的熟悉处理器的指令手册(比如INTEL系列CPU指令手册),一份指令手册动辄就是几百个指令集。说实话,要不是长期做CPU底层方面的特殊开发工作,普通的计算机学习和应用者又会有几人能很专业的掌握呢。
比如现在我们需要一个计算:a=x/y;b=x%y的过程,用汇编语言实现,步骤的步骤如下:
1.查询INTEL系列CPU指令手册,手册上写的指令格式是:DIV r/m32。
2.放操作数:
2.1 x必须要放进EAX:mov eax,x
2.2 y可以有一些选择(如EBX、EDX),我们可以把它放进EBX:mov ebx, y
3.指令执行:DIV EBX。
4.取操作结果:
4.1 商必须要从EAX 中取: mov a,eax
4.2 余数必须要从EDX 中取: mov b,edx
就这简单的一个除法,就必须动用以上复杂的过程。其实倒不是说汇编语言有多么的烧脑和复杂,主要是它非常的繁琐,繁琐得你今天学会了这个除法写法,但后天就会忘记了,所以下次遇到还必须得重新重复以上过程。这样一来,用汇编语言编程,大量的时间和精力都会花在这些细枝末节上面,主体的工作反而会进展得非常的缓慢,这样就会逐渐消除编程者的信心和成就感,偏离我们的学习目标。
我们是在开发操作系统,编码量得多大啊。所以这个时候,C语言的优势体现就毫无疑问:上面的问题,只需两句语句a=x/y;b=x%y就解决,根本不需要开发者关心和掌握哪些寄存器参与了,然后从哪些寄存器取结果。这些过程,C语言编译器都替你完成了。
结论:以后的工作就必须要使用C语言了。
但我要再一次向坚持使用纯汇编语言的大神们致敬!
二、怎么使用C语言
先来回顾一下,到目前为止,我们的操作系统进展到什么程度:
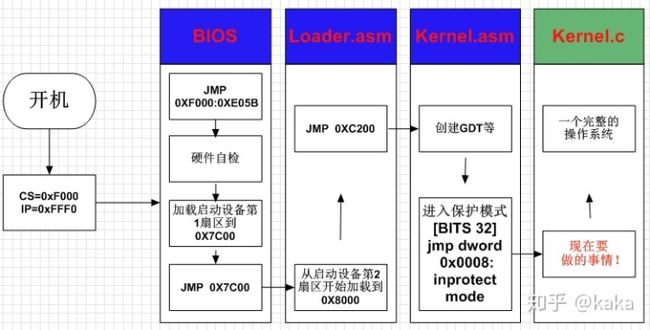
其中,Loader.asm和Kernel.asm的完整程序代码在前面的章节中已经贴出。目前由于开发工作遇到了效率瓶颈,现在我们就需要用C语言来继续进行我们的工作---操作系统内核的编写。其实,从上图中可以看到我们进入保护模式的时候,程序都不应该叫做内核,顶多叫做装载而已,名字明显起早了。但是,当时一步步的学习,不是有很多不懂的地方嘛,也没关系,就姑且这样吧。那我们以后的工作就是集中精力编写Kernel.c这个程序,终极目标就是让它变成一个完整的操作系统。
图中可以看出,操作系统完整的程序执行过程:Loader.asm--->Kernel.asm--->Kernel.c。那我们现在就只需要把Kernel.c在内存上顺序的布置在Kernel.asm的后面即可。那怎么才能把Kernel.c贴在Kernel.asm的屁股后面呢,方法就是把Kernel.asm编译成的二进制文件(Kernela.bin)和Kernel.c编译成的二进制文件(Kernelc.bin)连接在一起嘛:
copy /b Kernela.bin+Kernelc.bin Kernel.bin
这样得到新的Kernel.bin文件就可以利用Loader.asm进行装载了。Kernela.bin倒是非常的简单,直接一条NASM编译命令就可,前面都已经完成该项工作了,本章我们就来研究怎么才能得到Kernel.c编译之后的二进制文件。
- 传统的C编译器不适合
假设我们现在的任务是要在屏幕上显示一个红色的字母"C",汇编程序应该是这样写:
;保护模式下,此程序正常运行的前提是DS要先映射到物理地址:0Xb8000.
mov byte [00],'C' ;显示字符
mov byte [01],0x0c;红色将这段代码编译之后,机器码如下,我们需要记住这段机器码。

现在我们换成用C语言来编写,最小格式如下:
/* file:zh.c */
int main()
{
*(char *)(00) = 'C';
*(char *)(01)= 0x0c;
stop:goto stop;
return 0;
}程序中,我们必须定义main函数,否则无法通过C编译器编译。最有名的C编译器无疑是GCC,某种意义上讲GCC是UNIX的代表,但是由于我这次一直是在WINDOWS的环境下开发的,没有借助于任何的UNIX系统,因此还需安装WINDOWS版本的GCC编译器---MinGW。用GCC编译上面程序:
就可以得到C语言编译之后的二进制目标程序:zh.o,我们打开该文件看看:

可以看出,这个和汇编语言NASM编译出来的机器代码并不一样,我们只找到了JMP $这条指令对应的机器代码,但是我们能隐约地感觉到前面两句应该就是我们需要的机器代码。
这样,我们将zh.o文件再反汇编来看一下:
可以看到这前面两句的汇编代码是:
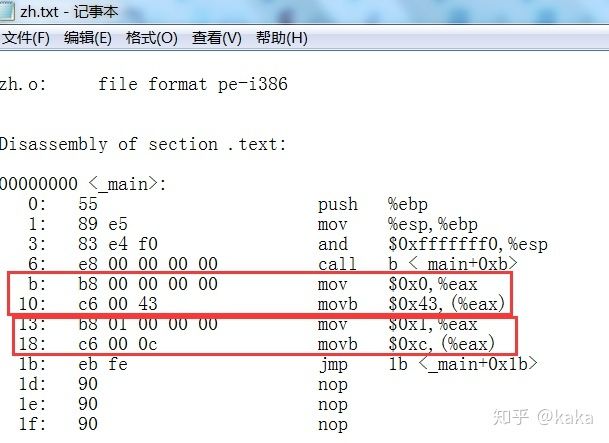
这个是GCC内置的AT&T格式汇编语言程序,明显它和我们的NASM两句汇编程序功能上是等价的。只不过它往内存写数据的时候,通过了寄存器EAX进行中转,所以它的机器代码是8个字节,我们的NASM机器代码只有5个字节。
由于AT&T格式汇编语言和NASM汇编语言格式相差较大,那我们再找一个和NASM相近的MASM看看呢,我们再用微软公司VS的C编译器编译来试试:

看看编译后的二进制目标文件代码:
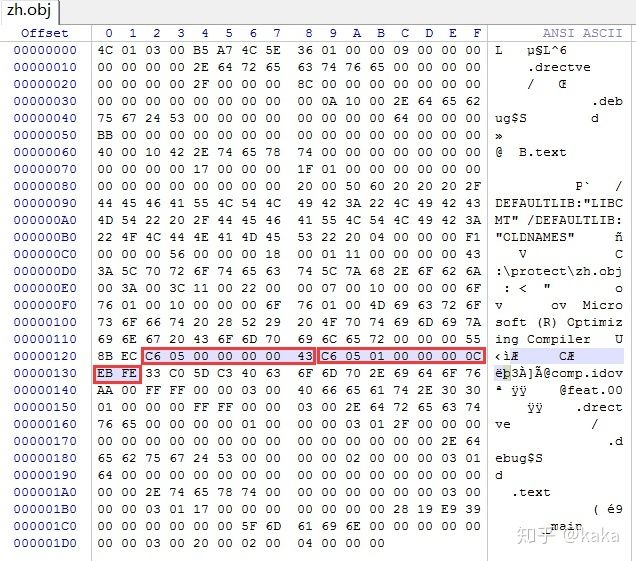
这下都不用反汇编,这个机器代码和NASM编译后的机器代码几乎一模一样(一个是C606,一个是C605,我不清楚二者的区别在哪里)。
从上面的过程可以看出,无论用何种C编译器,最终都能实现将C语言源程序编译得到我们需要的机器代码,从而达到汇编语言编程的目的,这就是我们使用C语言的初衷。
现在我们已经得到了C语言的二进制目标文件,机器代码已经摆在面前,但是我们需要的只是那两句显示字符的代码,而C语言编译器为了其他任务(编译之后的“链接”需要)在这个目标文件里添加了一大堆我们不需要的代码,那我们该怎么办呢?
我们先试试忽略目标文件中的其它代码,把这个目标文件代码加入到我们的源程序后面看能否正常运行。为此,将上面的C程序“粘贴”在我们的源程序屁股后面,源程序来自于本专栏“计算机自制操作系统(十):32位保护模式”中,将其文件名取为protect.asm(需要稍作修改,把DS描述符的线性基地址设置为0x000b8000),用NASM编译成protect.bin,和上面的C程序编译之后的目标文件进行连接:
copy /B protect.bin+zh.o test.img
或者
copy /B protect.bin+zh.obj test.img然后,把test.img装入虚拟机用来启动。很遗憾,我们没能得到C程序中显示红色字符"C"的效果,失败了。说明一个道理:我们不能忽略C编译之后目标文件的其它代码,它的运行(或者或根本无法运行导致宕机等)会给我们的系统带来问题。不奇怪,因为传统的C语言编译器都是为宿主操作系统服务的,没有一个C编译器能编译给写操作系统的人用。
所以,我们现在需要正确解锁的姿势是:将所需机器代码从C语言编译后的目标文件(obj)里抽取出来,怎么抽取呢?我通过翻阅资料,找到了方法:那就是利用别人的第3方工具,这个工具就是日本人那本书---《30 天自制操作系统》里面的工具。
2.借助3方C编译器和工具
《30 天自制操作系统》这本书里有这么一段:

刚开始接触这本书的时候,我也很疑惑怎么这么多的过程和文件。直到我遇到上面的问题之后,就妥协了。对于这个原因,作者也给出了解释:

所以,我们需要的工具是:cc1.exe,gas2nask.exe,nask.exe,obj2bim.exe等,下面我就用这些工具来演示整个过程。
这次我们把C语言源程序命名为:Kernelc.c,打算显示6个红色的'C',源程序如下:
/* file:Kernelc.c */
/* 该程序正常运行的前提是进入32位保护模式,且DS的线性基地址为0x0.
void HariMain(void)
{
int i=0;
for (i=0;i<=10;i++)
{
*(char *)(0xb8000+23*160+i) = 'C'; /*显示位置为第23行
*(char *)(0xb8000+23*160+1+i)= 0x0c;
i++;
}
stop:
goto stop;
}利用这些工具一口气编译和转换如下(这么多步骤,后面可以做成makefile):
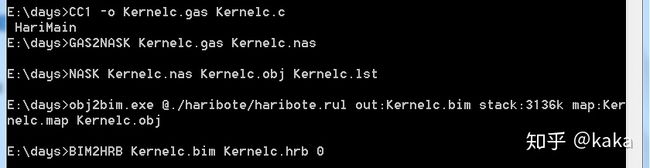
最后来看看我们得到的最终二进制文件Kernelc.hrb内容:
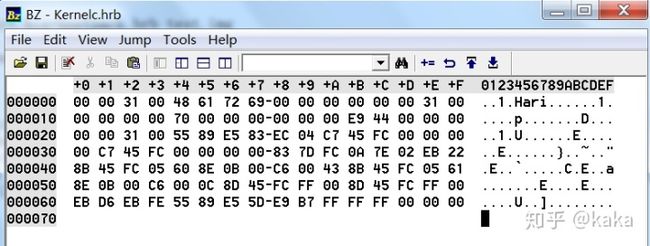
看到没?这个二进制文件比上一章中GCC或VS编译器编译出的目标代码小多了,只是在文件的前面增加了一些类似"Hari"的备注代码,我们姑且叫它"头数据”。可以理解为我们几乎就已经抽取出来了所需的目标代码,哪些代码才是我们的C程序真正产生的目标代码呢?我们不妨分析中间过程产生的汇编程序Kernelc.nas:
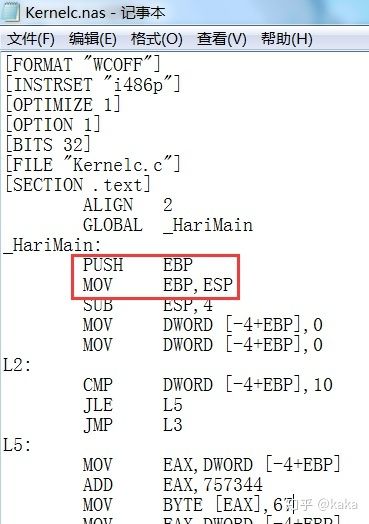
显然这就是我们非常熟悉的NASM代码,这些工具能够把C程序编译和转换成成规范的NASM程序,这是比较方便的地方。我们只需要根据这个汇编程序中前2条指令的机器代码就可以提取出我们的C语言最终二进制机器代码。为此,我们把这个汇编程序做一次编译:
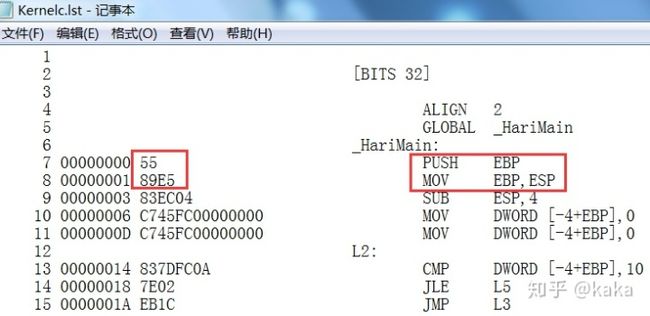
汇编语言编译之后产生的机器代码开头是:5589E5,我们在上面C语言编译后的二进制文件中一下就找到了:
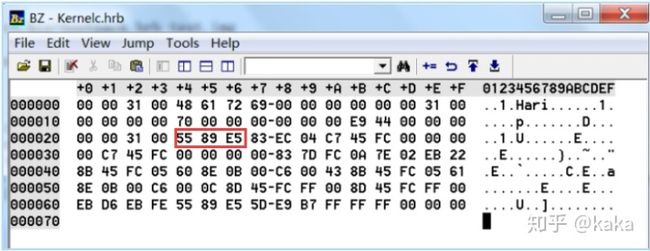
那我们就跨过“头数据”从“5589E5”开始,把所有的代码全部拷贝出来,然后新建一个二进制文件,取名Kernelc.bin,把它放在“计算机自制操作系统(十):32位保护模式”中汇编程序编译之后的二进制文件protect.bin的屁股后面:
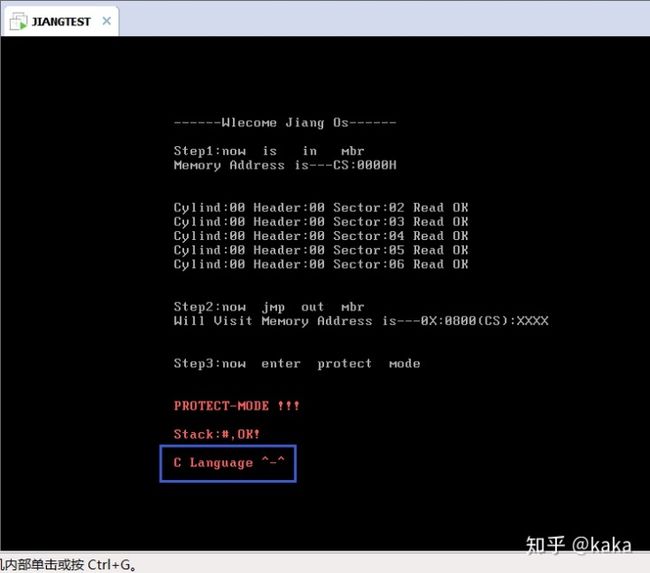
copy /B protect.bin+Kernelc.hrb testc.img现在就用镜像文件testc.img来启动计算机。结果成功达到目标:

屏幕的显示说明我们完成了在C语言中的任务,用C语言进行操作系统开发的工具算是找到。
OK,经过测试目标已经达到,我们最后就来规范一下操作步骤:
(1) 汇编源程序编译:源程序为“计算机自制操作系统(十):32位保护模式”中的汇编程序,但我们需要对这个程序做一个小动作:将程序的最后一句指令"jmp $"修改为: jmp over+0x24,显然它的目的是让CPU执行过程中跳过C语言编译过后的“头数据"而直达目标代码。修改后的程序改名为:Kernela.asm,用以下命令编译输出Kernela.bin:
Nasm Kernela.asm -o Kernela.bin(2) C语言源程序编译:源程序取名Kernelc.c,这次要打印一个字符串,详细内容如下:
/* filename: Kernelc.c */
void HariMain(void)
{
int i=0;
*(char *)(0xb8000+24*160+i) = 'C';
*(char *)(0xb8000+24*160+i+2) = ' ';
*(char *)(0xb8000+24*160+i+4) = 'L';
*(char *)(0xb8000+24*160+i+6) = 'a';
*(char *)(0xb8000+24*160+i+8) = 'n';
*(char *)(0xb8000+24*160+i+10) = 'g';
*(char *)(0xb8000+24*160+i+12) = 'u';
*(char *)(0xb8000+24*160+i+14) = 'a';
*(char *)(0xb8000+24*160+i+16) = 'g';
*(char *)(0xb8000+24*160+i+18) = 'e';
*(char *)(0xb8000+24*160+i+20) = ' ';
*(char *)(0xb8000+24*160+i+22) = '^';
*(char *)(0xb8000+24*160+i+24) = '-';
*(char *)(0xb8000+24*160+i+26) = '^';
for (i=0;i<=28;i++)
{
*(char *)(0xb8000+24*160+i+1)= 0x0c;
i++;
}
while (1)
{;}
}这里我们需要如下命令用一系列的工具进行编译和格式转化,最后输出文件Kernelc.hrb:
CC1 -o Kernelc.gas Kernelc.c
GAS2NASK Kernelc.gas Kernelc.nas
NASK Kernelc.nas Kernelc.obj Kernelc.lst
obj2bim.exe @./haribote/haribote.rul out:Kernelc.bim stack:3136k map:Kernelc.map Kernelc.obj
BIM2HRB Kernelc.bim Kernelc.hrb 0(3) 汇编程序和C语言程序的机器代码相连接
copy /B Kernela.bin+Kernelc.hrb Kernel.bin最后就用Kernel.bin来启动计算机,我们一开始设想的总目标就算达到:
三、深入理解C语言运行机制
从上一章的实践中,我们可以看到相比汇编语言,C语言编程应用起来确实厉害多了,可以简单明了的实现目标。那么C语言是怎么完成这种任务的呢?我们现在来分析一下。
先写一个二重循环的简单程序study.c,这个程序的功能是打印一个3*5(3行5列)的字符矩阵
void HariMain(void)
{
int i=0;
int j=0;
for (i=0;i<=2;i++)
{
for (j=0;j<=8;j++)
{
*(char *)(0xb8000+i*160+j) = 'C';
j++;
}
}
while (1)
{;}
}别看用C语言写1分钟不到,但是用汇编语言来编写和调试的话,一般情况还是得折腾半个小时以上,因为涉及乘法和循环等,需要不断的在AX,BX,CX,DX等上面摩擦和判断。那么C语言是怎么做到的呢?我们把它编译之后的汇编语言study.nas文件拿出来看:
[FORMAT "WCOFF"]
[INSTRSET "i486p"]
[OPTIMIZE 1]
[OPTION 1]
[BITS 32]
[FILE "study.c"]
[SECTION .text]
ALIGN 2
GLOBAL _HariMain
_HariMain:
PUSH EBP
MOV EBP,ESP
SUB ESP,8
MOV DWORD [-4+EBP],0
MOV DWORD [-8+EBP],0
MOV DWORD [-4+EBP],0
L2:
CMP DWORD [-4+EBP],3
JLE L5
JMP L3
L5:
MOV DWORD [-8+EBP],0
L6:
CMP DWORD [-8+EBP],8
JLE L9
JMP L4
L9:
MOV EDX,DWORD [-4+EBP]
MOV EAX,EDX
SAL EAX,2
ADD EAX,EDX
SAL EAX,5
ADD EAX,DWORD [-8+EBP]
ADD EAX,753664
MOV BYTE [EAX],67
LEA EAX,DWORD [-8+EBP]
INC DWORD [EAX]
LEA EAX,DWORD [-8+EBP]
INC DWORD [EAX]
JMP L6
L4:
LEA EAX,DWORD [-4+EBP]
INC DWORD [EAX]
JMP L2
L3:
L10:
JMP L10
变量机制:C程序中开头两句的临时变量i和j,在汇编语言中是如下实现的:
PUSH EBP
MOV EBP,ESP
SUB ESP,8
MOV DWORD [-4+EBP],0
MOV DWORD [-8+EBP],0这是什么意思?显然是把i和j的初始值0分别存进了内存区域 [-4+EBP],[-8+EBP],内存[-4+EBP],[-8+EBP]默认的访问方式是:SS:-4+EBP和SS:-8+EBP,而EBP的值是程序开始的时候ESP之值,所以等价于SS:-4+ESP,SS:-8+ESP,要把变量放进栈顶下面的2个地方,这显然是对对i和j进行了入栈操作:一个变量占4字节,所以入栈之后栈顶还需要向下移动8个字节:SUB ESP,8。这样后面程序中对i和j的操作全都是对栈内空间[-4+EBP],[-8+EBP]两处进行操作,比如文件中这两条指令就是判断内和外循环是否完毕。
CMP DWORD [-4+EBP],3
......
CMP DWORD [-8+EBP],8这里有一个问题,既然是入栈操作,那为什么不用指令呢?这就是C编译器的选择了,因为它对入栈机制掌握得很深刻。之前我在“计算机自制操作系统(十):32位保护模式”一文中曾经详细说明了入栈操作有一个和push指令等价的指令,这里C编译器显然是选择了等价的方式。其实,这里完全可以用push指令,换成如下指令即可:
MOV EDX,0
PUSH EDX ;i入栈
PUSH EDX ;j入栈但由于PUSH指令会自动操作栈顶指针移动,这样一来就必须删除上面的指令:SUB ESP,8。
那么这里程序一开始的时候,栈顶地址:SS:ESP究竟是多少呢?这就取决于编程者的设置了,比如我是把这段C程序编译之后嵌入到我的系统中,那么它的值就是我进入保护模式之后设置的栈顶0x00007c00。如果这个C程序是WINDOWS下面的C程序编译和运行环境,那就是WINDOWS负责给它设置好。
从这里可以明显得出结论:C语言中的变量其实都是在保存在栈内的。但是如果你只是学习高级语言编程就很难深刻理解这句话,所以加强计算机底层实现的学习还是比较重要的。
我们回到程序主结构,显然汇编语言也是用了两层循环:内循环标号L6,外循环L2,对i++和j++的操作通过以下指令:
LEA EAX,DWORD [-8+EBP]
INC DWORD [EAX]
.........................
LEA EAX,DWORD [-4+EBP]
INC DWORD [EAX]这里就有一个很重要的问题:指令INC DWORD [EAX] 是直接对内存进行寻址操作,内存直接寻址默认的寄存器应该是DS,所以这个数据访问寻址实际上是:DS:-4+EBP(LEA指令的作用是取偏移地址,这里LEA EAX,DWORD [-4+EBP]实际上等效于mov eax,-4+EBP,只不过nasm语法要求必须要加[])。EBP最开始的时候取自于ESP,ESP取决于我们的系统设置,在我的系统中我设置的是0x00007c00。所以,变量i的绝对地址:-4+EBP=0x00007bfc。那么现在我们要用DS:-4+EBP访问0x00007bfc必须要确保DS=0才行!故为了C语言编译后的程序能在我们的系统中正常运行,就必须要在进入保护模式之后在GDT中把DS段描述符的线性基地址映射成0x00000000。否则,C语言程序就无法集成到你的系统中。这一点就太重要了,因为我在调试过程中,当时没有注意到这一点运行过程中老是蓝屏宕机,折腾了2天才弄通!
四、C语言变量原理
在上一小节中,我们当时得出了一个重要的结论:C语言中的变量其实都是在保存在栈内的。这,其实并不是一个准确的描述,因为我们目前还只是见识到了一种变量而已。实际上,C语言变量根据生命周期不同进行分类是存在多种类型的,变量是每一种计算机语言的核心,搞清楚了变量原理就相当于掌握了某种语言。本小节,我们就来彻底搞清楚C语言的变量原理。
(一)变量类型
变量根据作用域属性可以分为:全局变量和局部变量;根据生命周期属性可以分为:静态变量和非静态变量。那么这两种类交叉无疑就会形成:全局静态变量、全局非静态变量、局部静态变量、局部非静态变量。事实上C语言这几种分类方法有点绕,相互之间的含义也有交叉,所以大概最终区分如下:
全局非静态变量:在整个工程文件内都有效,无论多少个源程序文件。这类变量在编译之后在汇编程序里是GLOBAL属性,也即可以被其它源程序调用。
全局静态变量:只在当前C程序中有效,无法被其它源程序调用。
局部静态变量:只在定义它的函数内有效且程序仅分配一次内存,函数返回后该变量不会消失.
局部非静态变量:局部变量在定义它的函数内有效,但是函数返回后失效。
全局与局部:在Main函数之前位置定义变量就是全局,Main函数之内定义变量就是局部。当然全局与局部还有相对的概念,如Main函数下面还有子函数fun(),那么在fun()内部定义的变量就是局部,在fun()前面定义变量就是全局。
静态与非静态:使用关键词---static,static有两大作用:
1.首先最主要功能是隐藏:如在Main函数前面用了static定义变量,则这个变量是不能在别的C程序里使用的,相当于是隐藏起来。这个属性是静态用在全局变量中的主要原因。
2.其次因为static变量存放在静态存储区,可以保持变量内容的永久有效。比如我有一个很重要的变量,而在Main函数里面有很多个函数fun1()、fun2()、funn()都需要用到它,那这个是时候定义static变量就最适合不过了。这个属性是静态用在局部变量中的主要原因。
(二)变量类型内存分配
- 需要专门分配内存空间的变量:全局非静态变量、全局静态变量和局部静态变量。
1.1 局部静态变量:放在段.data中。它虽然是局部的,但是在程序整个生命周期中存在。
1.2 初始化了的全局静态变量:放在段.data中。
1.3 未初始化的全局静态变量:放在段.bss中。
也即局部静态变量直接放在.data,只有全局变量才区分放在.data还是.bss,而区分的依据就和static属性没有关系了,唯一的依据是看初始化与否。
为什么要这么做呢?这就是C编译器做出的优化之处。我们知道未初始化的全局变量默认值都为0,如果全部将他们和已经初始化了的全局变量一起放在.data段中,这样一来生成可执行文件的时候(如Linux下的ELF),这个可执行文件的数据区部分就必须要包含整个全局变量的内存空间。但是如果那些未初始化量默认值都为0的全局变量空间特别的大,那生产ELF文件的时候就可以采用一种类似"压缩"的算法,把这部分文件空间省去。方法是我们在ELF文件的某个地方约定填写未初始化全局变量的长度,ELF只需要存储这个长度的信息就行了,文件就很可能变得非常的小。如有一个未初始化全局变量数组 char a[256],实际运行需要的内存空间是256B,但现在我们只需要用一字节内容:0XFF就能表示其长度,那么ELF文件就可以省掉255B的大小。编译器为了将这个长度数据写进ELF,就专门将未初始化的全局变量的空间全部放到一个专门的地方叫:bss段,放好之后链接器链接的时候自己去bss段数一下0的个数就知道有多长了。
但是程序真正运行的时候它们的确是要占内存空间的,所以可执行文件必须要记录好所有未初始化的全局变量的大小,记为.bss段。程序真正运行的时候就需要分配出相应大小的内存空间,而且这部分内存空间会紧随.data的后面。所以.bss段只是编译器在目标文件中为未初始化的全局变量预留位置而已,它告诉链接器在生成可执行文件时,究竟能压缩多少的文件空间。
这个和我们现在开发操作系统的关系不大,因为它主要是用在已有操作系统上进行C程序开发编程的应用上面。现在我们自己来写操作系统和使用C程序,就必须在编译器工作之前要对data段和bss段数据的最终存放物理内存地址做出明确的指派,相当于要定义好数据区,这个任务需要在进行C程序之前的汇编程序中完成。一般我们可以把这个数据区安排在栈的上面(也可以在别的位置),以堆栈的栈底内存地址做分界线,线上叫堆,线下叫栈,结构如图:
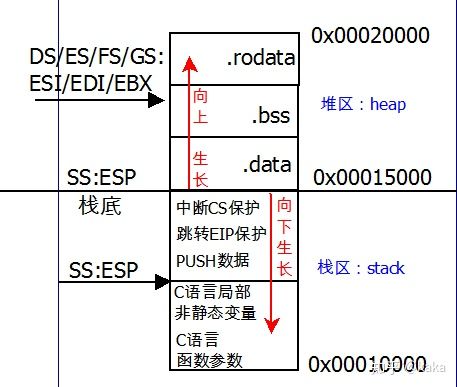
所以,堆和栈其实是两个不同的概念,我们一般的情况下容易混淆并对二者含糊不清。在前面我的部分章节中,也都把栈区叫做了堆栈,严格意义上讲都是不准确的。
2.不需要分配内存空间而在栈空间中暂存的的变量:局部非静态变量,编译器会在这类变量初始化的时候,给它在栈空间内分配一个临时空间push入栈,随着函数运行的结束自动就失效了。所以这类变量的生存周期很短,只是做了一个入栈的临时性暂存动作而已。典型就是我们上一节的遇到的情况。
(三) 程序验证
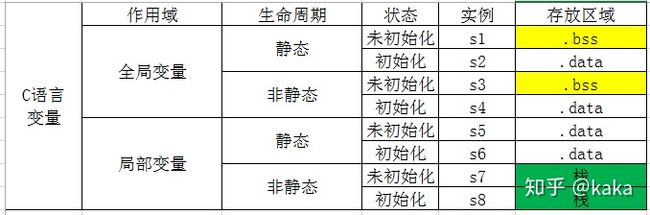
针对上面分析的C语言不同变量类型的实现原理,下面用具体的程序来演示说明。
/* filename: Kernelc.c */
static char s1;
static char s2='B';
char s3;
char s4='D';
void Main(void)
{
s1='A';
s3='C';
static char s5;
static char s6='F';
char s7;
char s8='H';
s5='E';
s7='G';
*(char *)(0xb8000+24*160+0) = s1;
*(char *)(0xb8000+24*160+2) = s2;
*(char *)(0xb8000+24*160+4) = s3;
*(char *)(0xb8000+24*160+6) = s4;
*(char *)(0xb8000+24*160+8) = s5;
*(char *)(0xb8000+24*160+10) = s6;
*(char *)(0xb8000+24*160+12) = s7;
*(char *)(0xb8000+24*160+14) = s8;
while (1)
{;}
}我们针对每种变量类型在程序中都定义了,具体见下表:
我们分析编译之后生产的汇编程序,分为以下3种情况:
1.可以看到上s2,4,5,6都在.text代码段的前面,也即:.data段。
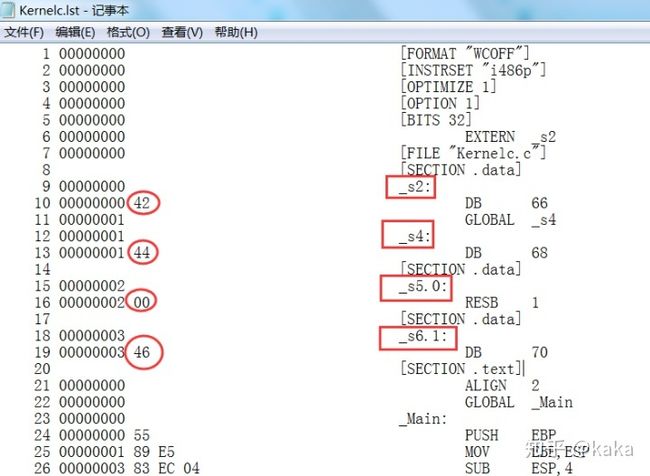
2.两个未初始化的全局变量s1,3被编译器默认置0,放在了.text代码段的后面,也即.bss段。同时检查汇编程序的GLOBAL属性会发现,只有两个全局非静态变量:s3,4才有。

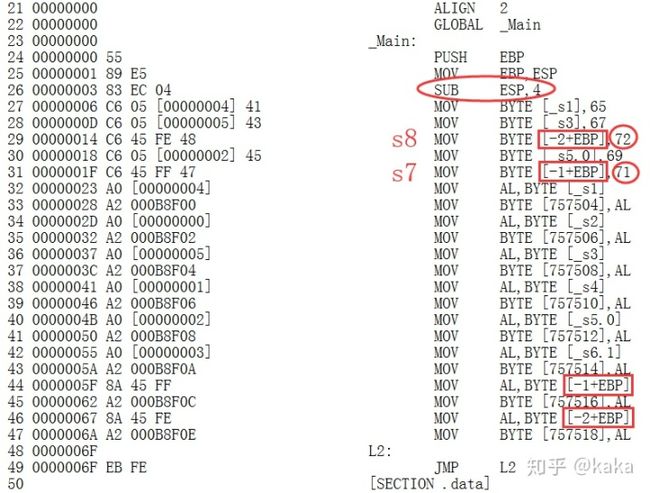
3.两个局部非静态变量s7,8的赋值放在了程序段里面:初始化时先后分别进行了入栈,存在了栈空间内存的[EBP-2]和[EBP-1]位置处。我们看到,为了将这两个局部变量入栈,栈顶指针提前就已经挪动了4B位置 (SUB 4),其实就相当于做了一次push s7,8的操作。但是令人疑惑的是为什么这个程序到结束的时候都没有对这入栈的数据---s7,s8以及EBP做出栈操作呢?
来看最后生成的真正要运行在计算机上的机器代码:
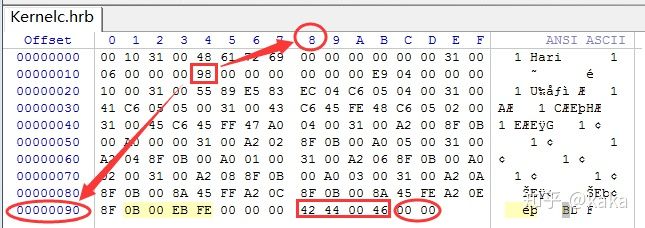
可以看到,变量值全部都放在了二进制机器代码的文件末尾:2个放在.bss段的变量紧随在4个放在.data段的变量之后。从这里明显可以看出,C语言的变量无论是否初始化,最后装进内存的时候都是需要真正分配空间的,这个时候不再会区分data段变量和bss段变量。故data段和和bss段只是编译阶段产生目标文件的中间物,供链接需要而已。
那么,这里有一个很重要的问题:程序运行的时候,是怎么定位这些变量在内存中的真实物理地址呢?也即程序怎么才能正常访问到它们吗?通过图上可以看到,在最终的二进制机器代码文件开头部分(可以理解为文件头)数字:98,它就是用来定位这个机器代码文件里面哪里是“变量数据”,那么操作系统就需要应该根据这个定位信息来提前把“变量数据”先加载到内存真正的“数据区”,否则这些变量就无法使用。所以,到这里我们才能完全理解为什么在我们的C程序编译之后,总会有一个0x24长度的文件头!
4.程序运行:
我们按本章前面的方法,把这个Kernelc.c运行起来看一下效果,是否8个变量都能成功的打印在屏幕上:
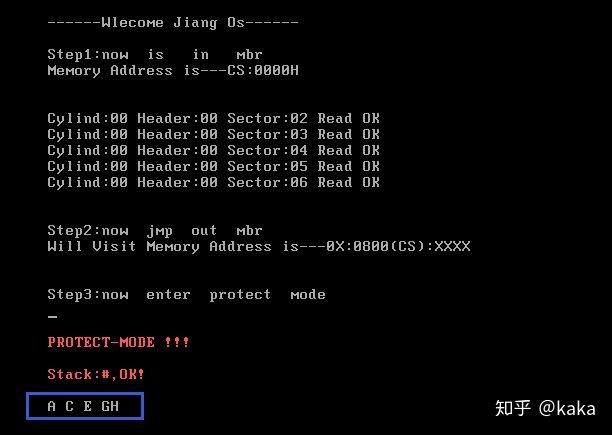
可以看到,成功了5个变量,有3个变量失败了:s2,4,6,这3个全部都是声明的时候就同步做了初始化工作的变量,我们来看3个失败变量的汇编程序:
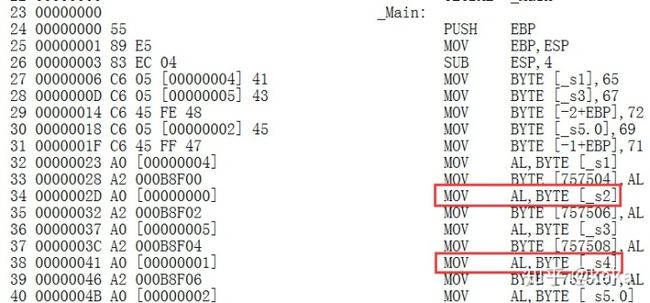
这是内存直接寻址方式,这2条指令能取得正确变量数据的前提是---数据寄存器DS:数据偏移地址指向的内存地址处存有变量数据。
为了找到变量的数据偏移地址,我们需要看一下在链接程序生成的最终机器代码文件中,这些变量在链接程序看来,应该去取的内存地址偏移地址是多少:
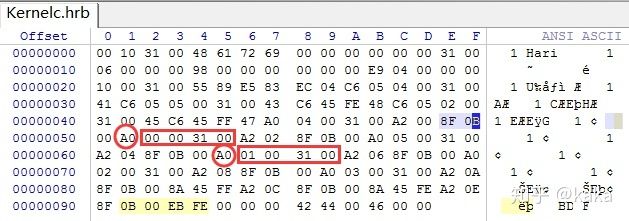
可以看出,机器指令取变量s2,4的时候,都是在汇编程序里变量偏移地址的基础上加了一个统一的基地址:0X00310000(这个值是可以通过链接器进行配置的)。这个就是相当于链接程序对变量进行了重定位。现在我们就有2项工作是必须要准备好的:
1.DS指向物理基地址:0。
2.把机器程序文件里面的所有变量数据,提前写到物理地址:0X00310000开始的缓冲区。
显然,第2项工作,我们并没有做,所以这些变量的访问就会失败!
4.变量数据区准备
那针对上面的问题,在我的操作系统中,程序是这样来做的:
4.1 定义变量数据的真实物理地址:这个在链接器配置文件中实现,具体是我将上面的0X00310000做了一下调整,我用的是:0X00100000,也即把1MB开始的最低处内存用来当做变量数据区:
Kernelc.bim : Kernelc.obj naskfunc.obj Makefile
$(OBJ2BIM) @$(RULEFILE) out:Kernelc.bim stack:1024k map:Kernelc.map Kernelc.obj naskfunc.obj4.2 将变量写进变量数据区:这个工作需要在C程序引用变量之前完成,因此C程序开始的第一件事就是它,具体我们需要把变量数据写进目标地址:0X00100000开始的缓冲区。而源数据的定位比较复杂,需要二次指针的过程:先依靠Kernelc.hrb中的“头文件”找到变量的逻辑定位,实际我们还需要根据它的逻辑定位在内存中找到绝对的物理地址才能实现数据迁移。所以这里需要分为两步:(1) 找到Kernelc.hrb中存放变量位置和长度的内存物理地址。(2)。在上一个物理地址中找到真正存放变量的物理地址。
具体的实现过程有点复杂,这部分内容为了连贯性,我把它放在了本专栏“计算机自制操作系统(十八):规范开发模式”中“C语言实现变量编程设计”之处,那里可以看到详细的C语言实现变量编程的全部设计过程和源程序。
四、C语言总结
本章对于C语言的运行机制做了一个详细的解析,可以看出,只有深入计算机底层部分,才可能对C语言有一个彻底的掌握。对于没有接触过这些的人说,学习C语言的指针永远都是一个跨不过的难题。但我们经过汇编语言和机器码层级的分析,发现指针的难度简直不值得一提。
我们跨过汇编语言之后的第一步使用的就是C语言,说明C语言在计算机技术中有其他任何高级语言不同替代的作用。所谓“0/1生汇编,汇编生C,C生万物,乃编程之本”,任何想立志学好计算机的人都不可能跨过C语言:

最后,用在知乎上看到一个网友对C语言的定位来结束本章:

我觉得这个比喻非常到位。如果说C语言相当于在城市里买了房子,那么汇编语言无疑就是有无数套房子的包租婆!