信息论复习笔记
- Author:ZERO-A-ONE
- Date:2021-01-04
题型:
- 25分:5题概念解释 如:基本概念,公式
- 35分:5题简述题 如:注水原理
- 40分:4题计算题 一章一题,来源:书上例题+书后练习
全书概况:

一、绪论
1.1 概念
- 信息:是指各个事物运动的状态以及状态变化的方式
- 消息:是指包含信息的语言、文字和图像
- 在通信中,消息是指负担传送信息任务的单个符号或符号序列
- 信号:是消息的物理体现,示消息的物理量
- 总结:消息是信息的数学载体、信号是信息的物理载体
- 通信系统模型:
-
基本单元:信源、信道、信宿
-
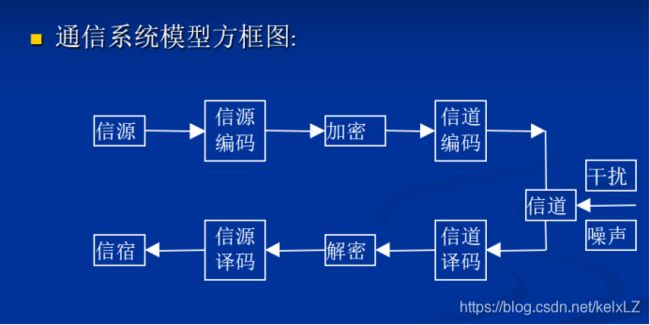
-
信源:是向通信系统提供消息 u u u的人和机器
- 离散消息:由字母、文字、数字等符号组成的符号序列,或者单个符号
- 连续消息:例如语音、图像和在时间上连续变化的电参数等
- 研究问题:包含的信息到底有多少,怎样将信息定量地表示出来,即如何确定信息量
-
信道:是传递消息的通道,又是传送物理信号的设施
- 研究问题:信道能够传送多少信息,即信道容量的大小
-
信宿:是消息传递的对象,即接收消息的人或机器
- 研究问题:能接收到或提取多少信息
-
干扰源:是整个通信系统中各个干扰的集中反应,用来表示消息在信道中传输时遭受干扰的情况
-
信源编码器:对信源输出进行变换,求得有效性
-
信道编码器:对信源编码输出进行变换,提高抗干扰性,求得可靠性
-
调制器:将信道编码输出变成适合信道传输的方式
-
译码器:编码器的逆变化过程
-
- 通信系统的性能指标:
- 有效性
- 可靠性
- 安全性
- 经济性
- 信息论应用:
- 生物学中的应用
- 生物信息的收集、储存、管理和提供
- 基因组序列信息的提取和分析
- 功能基因组相关信息分析
- 生物大分子结构模拟和药物设计
- 生物信息分析的技术与方法研究
- 应用与发展研究
- 医学中的应用
- 管理科学中的应用
- 经济学中的应用
- 不完全信息经济学
- 信息转换经济学
- 信息的经济研究
- 信息经济的研究
- 信息经济的社会学研究
- 生物学中的应用
二、信源与信息熵
2.1 信源分类
| 分类 | 类型1 | 类型2 |
|---|---|---|
| 时间 | 离散 | 连续 |
| 幅度 | 离散 | 连续 |
| 记忆 | 有 | 无 |
三大类:
- 单符号离散信源
- 符号序列信源
- 有记忆
- 无记忆
- 连续信源
符号集:
所谓符号集很好理解,就是你这个信源可能会发出符号有哪些。比如说{0,1},这里其实{}里面的东西可以任何可以代表符号的东西
状态:
而状态可以这样理解,它是这些符号集的一些组合,比如说{00,01,10,11}
- 信源输出随机信号序列(符号用 x x x来表示): x 1 , x 2 , . . . , x n x_1,x_2,...,x_n x1,x2,...,xn
- 信源的状态序列是(状态用 S S S来表示): S 1 , S 2 , . . . , S n S_1,S_2,...,S_n S1,S2,...,Sn
2.1.1 单符号离散信源
概念:
- 这些信源输出的都是单个符号的消息,出现的消息数是有限的,且只可能是符号集中的一种,所以信源出现的符号及其概率分布就决定了信源
概率空间表示:
[ X P ] = [ a 1 a 2 . . . a n p ( a 1 ) p ( a 2 ) . . . p ( a n ) ] \begin{bmatrix} X\\ P \end{bmatrix}=\begin{bmatrix} a_1 & a_2 & ...& a_n\\ p(a_1)& p(a_2) &... &p(a_n) \end{bmatrix} [XP]=[a1p(a1)a2p(a2)......anp(an)]
其中符号集 A = { a 1 a 2 . . . a n } A=\begin{Bmatrix} a_1 & a_2 & ... & a_n \end{Bmatrix} A={ a1a2...an}, X ∈ A X\in A X∈A,显然有 p ( a i ) ⩾ 0 p(a_i)\geqslant 0 p(ai)⩾0, ∑ i = 1 n p ( a i ) = 1 \sum_{i=1}^{n}p(a_i)=1 ∑i=1np(ai)=1
2.1.2 符号序列信源
概念:
- 很多实际信源输出的消息往往是由一系列符号组成的,每次发出一组含2个或以上符号的序号序列来表示一个消息的信源称为发出序号序列的信源
表示:
- 需要用随机序列(或随机矢量)来描述信源输出的消息
- 用联合概率分布来表示信源特性
表示:
[ X = X L P ( X ) ] = [ X = x 1 X = x 2 . . . X = x n L p ( x 1 ) p ( x 2 ) . . . p ( x n L ) ] \begin{bmatrix} X=X^L\\ P(X) \end{bmatrix}=\begin{bmatrix} X=x_1 & X=x_2 & ...& X=x_{n^L}\\ p(x_1)& p(x_2) &... &p(x_{n^L}) \end{bmatrix} [X=XLP(X)]=[X=x1p(x1)X=x2p(x2)......X=xnLp(xnL)]
X L = X 1 , X 2 , . . . , X L X^L=X_1,X_2,...,X_L XL=X1,X2,...,XL
最简单的符号序列信源是L为2的情况,此时信源 X = ( X 1 , X 2 ) X=(X_1,X_2) X=(X1,X2),其信源的概率空间为:
[ X P ] = [ a 1 , a 1 a 1 , a 2 . . . a n , a n p ( a 1 , a 1 ) p ( a 1 , a 2 ) . . . p ( a n , a n ) ] \begin{bmatrix} X\\ P \end{bmatrix}=\begin{bmatrix} a_1,a_1 & a_1,a_2 & ...& a_n,a_n\\ p(a_1,a_1)& p(a_1,a_2) &... &p(a_n,a_n) \end{bmatrix} [XP]=[a1,a1p(a1,a1)a1,a2p(a1,a2)......an,anp(an,an)]
显然有 p ( a i , a j ) ⩾ 0 p(a_i,a_j)\geqslant 0 p(ai,aj)⩾0, ∑ i , j = 1 n p ( a i , a j ) = 1 \sum_{i,j=1}^{n}p(a_i,a_j)=1 ∑i,j=1np(ai,aj)=1
2.1.2.1 离散无记忆序列信源
概念:
这种信源发出的符号序列中的各个符号之间没有统计关联性,各个符号的出现概率是它自身的先验概率,称为发出符号序列的无记忆信源
- 这个概率是统计得到的,或者你自身依据经验给出的一个概率值,我们称其为先验概率(prior probability)
- 后验概率,即它获得是在观察到事件Y发生后得到的
例子:
- 布袋摸球实验,每次取出两个球,由两个球的颜色组成的消息就是符号序列
- 若先取出一个球,记下颜色放回布袋,再取第二个球
表示:
联合概率: p ( X 1 , X 2 , . . . , X L ) = p ( X 1 ) p ( X 2 / X 1 ) p ( X 3 / X 1 X 2 ) . . . p ( X L / X 1 . . . X L − 1 ) = p ( X 1 ) p ( X 2 ) . . . p ( X L ) p(X_1,X_2,...,X_L)=p(X_1)p(X_2/X_1)p(X_3/X_1X_2)...p(X_L/X_1...X_{L-1})=p(X_1)p(X_2)...p(X_L) p(X1,X2,...,XL)=p(X1)p(X2/X1)p(X3/X1X2)...p(XL/X1...XL−1)=p(X1)p(X2)...p(XL)
以3位PCM信源为例子(无记忆):
[ X P ] = [ X = 000 X = 001 . . . X = 111 p 0 3 p 0 2 p 1 . . . p 1 3 ] \begin{bmatrix} X\\ P \end{bmatrix}=\begin{bmatrix} X=000 & X=001 & ...& X=111\\ p_0^3& p_0^2p_1 &... &p_1^3 \end{bmatrix} [XP]=[X=000p03X=001p02p1......X=111p13]
当 p 0 = p 1 = 1 / 2 p_0=p_1=1/2 p0=p1=1/2:
[ X P ] = [ X = 000 X = 001 . . . X = 111 1 / 8 1 / 8 . . . 1 / 8 ] \begin{bmatrix} X\\ P \end{bmatrix}=\begin{bmatrix} X=000 & X=001 & ...& X=111\\ 1/8& 1/8 &... &1/8 \end{bmatrix} [XP]=[X=0001/8X=0011/8......X=1111/8]
独立同分布信源:
在离散无记忆信源中,信源输出的每个符号是统计独立的,且具有相同的概率空间,既有 p 1 ( X 1 ) = p ( X 1 ) = p ( X i ) p_1(X_1)=p(X_1)=p(X_i) p1(X1)=p(X1)=p(Xi),则该信源是离散平稳无记忆信源,亦称为独立同分布(i.i.d.)
2.1.2.2 离散有记忆序列信源
概念:
- 当信源输出的随机矢量中各个分量之间不相互独立而可以是任意相关的,则称此类信源为有记忆信源
例子:
- 布袋摸球实验,每次取出两个球,由两个球的颜色组成的消息就是符号序列
- 若先取出一个球,记下颜色不放回布袋,再取第二个球
p ( X 1 , X 2 , . . . , X L ) = p ( X 1 ) p ( X 2 / X 1 ) . . . p ( X L / X 1 . . . X L − 1 ) p(X_1,X_2,...,X_L)=p(X_1)p(X_2/X_1)...p(X_L/X_1...X_{L-1}) p(X1,X2,...,XL)=p(X1)p(X2/X1)...p(XL/X1...XL−1)
2.1.3 马尔可夫信源
概念:
- 这个信源发出的符号只与当前状态有关,与前面的状态和输出的符号无关
- 当前信源的状态可以有当前发出的符号和前一状态所唯一确定
马尔可夫信源是通过符号之间的转移概率来描述这种关系的,也就是条件概率。换句话来说,就是马尔科夫信源是通过状态转移概率来发出每一个符号的。而转移概率的大小取决于它与前面符号的关联性
转移概率的表现形式是 P ( x i ∣ S j ) P(x_i | S_j) P(xi∣Sj)。也就是说已知某个状态,它接下来发出某个符号的概率
状态转移矩阵就是由这些每种状态下的转移概率所组成的,每一行加起来都会是1。这里的状态转移矩阵就是一种变换,它可以让你从一个状态转换成另外一个状态。每成一次矩阵,或者说每进行一次变换,就是一步转移
2.2 离散信息源熵和互信息量
信息的特征是不确定性
2.2.1 自信息量
概念:
- 自信息量指的是该符号出现后,提供给收信者得信息量。符号出现的概率越小,不确定性就越大,一旦出现,接收者获得的信息量就越大,符号出现的概率与信息量是单调递减关系
- 度量某一事件、信源某一具体符号的不确定性
公式:
定义具有概率为 p ( x i ) p(x_i) p(xi)的符号 x i x_i xi的自信息量为: I ( x i ) = − l o g p ( x i ) I(x_i)=-logp(x_i) I(xi)=−logp(xi)
自信息量的单位与所用的对数底有关:
- 在信息论中常用的对数底数是2,信息量的单位为比特(bit)
- 若取自然对数,则信息量的单位为奈特(nat)
- 若以10为对数底,则信息量的单位为笛特(det)
这三个信息量单位之间的转换关系如下:
- 1 n a t = l o n g 2 e ≈ 1.433 b i t 1\,nat = long_2e \approx 1.433\,bit 1nat=long2e≈1.433bit
- 1 d e t = l o g 2 10 ≈ 3.322 b i t 1\, det=log_210 \approx 3.322\,bit 1det=log210≈3.322bit
特性:
-
p ( x i ) = 1 , I ( x i ) = 0 p(x_i)=1,I(x_i)=0 p(xi)=1,I(xi)=0,不确定度越小,概率越大
-
p ( x i ) = 0 , I ( x i ) = 1 p(x_i)=0,I(x_i)=1 p(xi)=0,I(xi)=1,不确定度越大,概率越小
-
非负性:由于一个符号出现的概率总是在闭区间[0,1]内,所以自信息量为非负值
-
单调递减性:若 p ( x 1 ) < p ( x 2 ) p(x_1)
-
可加性:若有两个符号 x i , y j x_i,y_j xi,yj同时出现,可用联合概率 p ( x i , y j ) p(x_i,y_j) p(xi,yj)来表示,这时的自信息量为 I ( x i , y j ) = − l o g p ( x i , y j ) I(x_i,y_j)=-logp(x_i,y_j) I(xi,yj)=−logp(xi,yj),当 x i x_i xi和 y j y_j yj相互独立时有: p ( x i , y j ) = p ( x i ) ( y j ) , I ( x i , y j ) = I ( x i ) + I ( y j ) p(x_i,y_j)=p(x_i)(y_j),I(x_i,y_j)=I(x_i)+I(y_j) p(xi,yj)=p(xi)(yj),I(xi,yj)=I(xi)+I(yj)
- 若两个符号出现不是独立时,有: I ( x i ∣ y j ) = − l o g p ( x i ∣ y j ) I(x_i|y_j)=-logp(x_i|y_j) I(xi∣yj)=−logp(xi∣yj)
-
联合概率空间中任一联合事件的联合(自)信息量为: I ( x i , y j ) = − l o g p ( x i , y j ) = l o g 1 p ( x i , y j ) I(x_i,y_j)=-logp(x_i,y_j)=log\frac{1}{p(x_i,y_j)} I(xi,yj)=−logp(xi,yj)=logp(xi,yj)1
-
联合概率空间中,事件x在事件y给定条件下的条件(自)信息量为: I ( x i / y j ) = − l o g p ( x i / y j ) = l o g 1 p ( x i / y j ) I(x_i/y_j)=-logp(x_i/y_j)=log\frac{1}{p(x_i/y_j)} I(xi/yj)=−logp(xi/yj)=logp(xi/yj)1
2.2.2 信源熵
定义:
-
信源熵即表示信源的平均不确定度,它是在总体平均意义上的信源不确定度
-
平均自信息量即平均每个符号所能提供的信息量,它只与信源各符号出现的概率有关,可以用来表征信源输出信息的总体特征,它是信源中各个符号自信息量的数学期望
-
信源的平均不确定度
意义:
- 信源熵 H ( x ) H(x) H(x)表示信源输出前,信源的平均不确定性
- 信源熵 H ( x ) H(x) H(x)表示信源输出后每个消息(或符号)所提供的平均信息量
- 信源熵 H ( x ) H(x) H(x)可表征随机变量x的随机性:
- 当 p 0 = p 1 = 1 / 2 , H ( X ) = 1 比 特 / 符 号 p_0=p_1=1/2,H(X)=1比特/符号 p0=p1=1/2,H(X)=1比特/符号
- 当 p 0 = p 1 = p 2 = p 3 = 1 / 4 , H ( X ) = 2 比 特 / 符 号 p_0=p_1=p_2=p_3=1/4,H(X)=2比特/符号 p0=p1=p2=p3=1/4,H(X)=2比特/符号
- H ( X ) H(X) H(X)是完全表示信源X所需的最少的每符号比特数,这就是研究信源信息熵的目的
特性:
- 若对信源一无所知,X的符号数、概率等—— H ( X ) H(X) H(X)无穷大
- 已知X的符号数,但不知概率,假设等概率—— H ( X ) = l o g M H(X)=logM H(X)=logM
- 已知信源的概率空间,不等概率时 H ( X ) H(X) H(X)进一步变小
- 说明获得信息能使对信源的不确定度减少
2.2.2.1 单符号离散信源熵
定义:
对于给定离散概率空间表示的信源所定义的随机变量 I I I的数学期望为信源的信息熵,单位为比特/符号
公式:
H ( X ) = E ( I ( X ) ) = − ∑ i p ( x i ) l o g p ( x i ) H(X)=E(I(X))=-\sum_{i}^{}p(x_i)logp(x_i) H(X)=E(I(X))=−∑ip(xi)logp(xi)
2.2.2.2 离散信源条件熵
定义:
- 对于给定离散概率空间表示的信源所定义的随机变量 I ( x / y ) I(x/y) I(x/y)在集合X上的数学期望为给定y条件下信源的条件熵,单位为比特/序列
- 已知X后,关于Y的平均不确定度
公式:
H ( Y ∣ X ) = − ∑ i j p ( x i , y j ) l o g p ( y j ∣ x i ) H(Y|X)=-\sum_{ij}p(x_i,y_j)logp(y_j|x_i) H(Y∣X)=−∑ijp(xi,yj)logp(yj∣xi)
2.2.2.3 离散信源联合熵
定义:
- 对于给定离散概率空间表示的信源所定义的随机变量 I ( x / y ) I(x/y) I(x/y)的数学期望为集合X和集合Y的信源联合熵,单位为比特/序列
- 表示X和Y同时发生的不确定度
公式:
H ( X , Y ) = − ∑ i j p ( x i , y j ) l o g p ( x i , y j ) H(X,Y)=-\sum_{ij}p(x_i,y_j)logp(x_i,y_j) H(X,Y)=−∑ijp(xi,yj)logp(xi,yj)
2.2.2.4 联合熵、条件熵与熵的关系
H ( X , Y ) = H ( X ) + H ( Y ∣ X ) = H ( Y ) + H ( X ∣ Y ) H(X,Y)=H(X)+H(Y|X)=H(Y)+H(X|Y) H(X,Y)=H(X)+H(Y∣X)=H(Y)+H(X∣Y)
2.2.3 互信息量
定义:
- 不确定度的减少量就是接收者通过信道传输收到的信源X的信息量,称为X和Y的互信息量
- 已知某一条件Y,使得对X的不确定度减少了。衡量条件Y提供了多少关于X的信息量
公式:
I ( x i ; y j ) = l o g p ( x i ∣ y j ) p ( x i ) = l o g 后 验 概 率 先 验 概 率 ( i = 1 , 2 , . . , n , j = 1 , . . . , m ) I(x_i;y_j)=log\frac{p(x_i|y_j)}{p(x_i)}=log\frac{后验概率}{先验概率}(i=1,2,..,n,j=1,...,m) I(xi;yj)=logp(xi)p(xi∣yj)=log先验概率后验概率(i=1,2,..,n,j=1,...,m)
性质:
- 对称性: I ( x i ; y j ) = I ( y j ; x i ) I(x_i;y_j)=I(y_j;x_i) I(xi;yj)=I(yj;xi)
- 当 x i x_i xi和 y j y_j yj相互独立时,互信息量为0
- 互信息量可为正值或负值
2.2.3.1 平均互信息量
定义:
- 平均意义上的互信息量
公式:
- I ( X ; Y ) = ∑ i , j p ( x i , y j ) l o g p ( x i / y j ) p ( x i ) I(X;Y)=\sum_{i,j}p(x_i,y_j)log\frac{p(xi/y_j)}{p(x_i)} I(X;Y)=∑i,jp(xi,yj)logp(xi)p(xi/yj)
- I ( X ; Y ) = H ( X ) − H ( X / Y ) I(X;Y)=H(X)-H(X/Y) I(X;Y)=H(X)−H(X/Y)
- I ( Y ; X ) = H ( Y ) − H ( Y ∣ X ) I(Y;X)=H(Y)-H(Y|X) I(Y;X)=H(Y)−H(Y∣X)
物理意义:
- 收到Y后,消除了关于X的不确定度
- 收到Y后,获得了关于X的信息量
性质:
- 对称性: I ( X ; Y ) = I ( Y ; X ) I(X;Y)=I(Y;X) I(X;Y)=I(Y;X)
- 非负性: I ( X ; Y ) ⩾ 0 I(X;Y)\geqslant 0 I(X;Y)⩾0
- 极值性:
- I ( X ; Y ) ⩽ H ( X ) I(X;Y)\leqslant H(X) I(X;Y)⩽H(X)
- I ( Y ; X ) ⩽ H ( Y ) I(Y;X)\leqslant H(Y) I(Y;X)⩽H(Y)
- 凸函数性
2.2.3.2 条件互信息量
- 是在给定 z k z_k zk条件下, x i x_i xi与 y j y_j yj之间的互信息量,定义为:
- I ( x i ; y j ∣ z k ) = l o g p ( x i ∣ y j , z k ) p ( x i ∣ z k ) I(x_i;y_j|z_k)=log\frac{p(x_i|y_j,z_k)}{p(x_i|z_k)} I(xi;yj∣zk)=logp(xi∣zk)p(xi∣yj,zk)
- I ( x i ; y j ∣ z k ) = I ( x i ; z k ) + I ( x i ; y j ∣ z k ) I(x_i;y_j|z_k)=I(x_i;z_k)+I(x_i;y_j|z_k) I(xi;yj∣zk)=I(xi;zk)+I(xi;yj∣zk)
2.3 熵的性质
- 非负性
- H ( X ) = H ( p 1 , p 2 , . . . , p n ) ⩾ 0 H(X)=H(p_1,p_2,...,p_n)\geqslant0 H(X)=H(p1,p2,...,pn)⩾0
- 确定性
- H ( 0 , 1 ) = H ( 1 , 0 , 0 , . . , 0 ) = 0 H(0,1)=H(1,0,0,..,0)=0 H(0,1)=H(1,0,0,..,0)=0
- 只要信源符号表中,有一个符号的出现概率为1,信源熵就等于零
- 在概率空间中,如果有两个基本事件,其中一个是必然事件,另一个则是不可能事件,因为没有不肯定性,熵必为零
- 对称性
- 熵函数所有变元可以互换,而不影响函数值,即
- H ( p 1 , p 2 , . . . , p n ) = H ( p 2 , p 1 , . . . , p n ) H(p_1,p_2,...,p_n)=H(p_2,p_1,...,p_n) H(p1,p2,...,pn)=H(p2,p1,...,pn)
- 香农辅助定理(极值性)
- 任意一个概率分布对其他的概率分布的自信息量取数学期望必大于本身的熵
- 最大熵定理
- 离散无记忆信源输出M个不同的信息符号,当且仅当各个符号出现概率相等时,熵最大
- 条件熵小于无条件熵
- 加了条件就可消除一定的不确定度
- 拓展性
- 可加性
- H ( X , Y ) = H ( X ) + H ( Y ∣ X ) H(X,Y)=H(X)+H(Y|X) H(X,Y)=H(X)+H(Y∣X),X和Y独立的时候有: H ( X , Y ) = H ( X ) + H ( Y ) H(X,Y)=H(X)+H(Y) H(X,Y)=H(X)+H(Y)
- 递增性
- 一个符号划分成了m个元素,新符号的熵会增加
2.4 序列熵
-
离散无记忆信源的序列熵
- 序列熵:
- 独立但非同分布: H ( X ) = ∑ l = 1 L H ( X l ) H(X)=\sum_{l=1}^{L}H(X_l) H(X)=∑l=1LH(Xl)
- 独立同分布: H ( X ) = L H ( X ) H(X)=LH(X) H(X)=LH(X)
- 消息熵:
- 平均每个符号熵: H L ( X ) = 1 L H ( X ) = H ( X ) H_L(X)=\frac{1}{L}H(X)=H(X) HL(X)=L1H(X)=H(X)
- 单位:比特/符号
- 序列熵:
-
离散有记忆信源的序列熵
- 序列熵: H ( X ) = H ( X 1 ) + H ( X 2 / X 1 ) + . . . + H ( X L / X 1 . . . X L − 1 ) = ∑ l = 1 L H ( X i / X ( l − 1 ) ) H(X)=H(X_1)+H(X_2/X_1)+...+H(X_L/X_1...X_{L-1})=\sum_{l=1}^{L}H(X_i/X^(l-1)) H(X)=H(X1)+H(X2/X1)+...+H(XL/X1...XL−1)=∑l=1LH(Xi/X(l−1))
- 消息熵: H L ( X ) = 1 L H ( X ) = 1 L ∑ l = 1 L H ( X l / X ( l − 1 ) ) H_L(X)=\frac{1}{L}H(X)=\frac{1}{L}\sum_{l=1}^{L}H(X_l/X^(l-1)) HL(X)=L1H(X)=L1∑l=1LH(Xl/X(l−1))
-
马尔可夫信源与一般有记忆L长信源之间的区别:
- 马尔可夫信源发出的是一个个符号,而L长有记忆信源发出的是一组组序列
- L长有记忆信源有联合概率描述符号键的关联关系,而马尔可夫信源用条件概率描述符号间的关联关系
- 马尔可夫信源虽然记忆长度有限,但是依赖关系延伸到无穷远,而L长的有记忆信源符号间的依赖关系仅限于序列内部,序列间没有依赖关系
三、信道与信道容量
3.1 信道的基本概念
3.1.1 信道的分类
-
根据用户数量可以分为:单用户信道和多用户信道
-
根据信道输入端和输出端可分为:无反馈信道和反馈信道
-
根据信道参数与时间可分为:固定参数信道和时变参数信道
-
根据信道中所受噪声种类可分为:随机差错信道和突发差错信道
-
根据输入、输出信号的特点可分为:离散信道、连续信道、半离散半连续信道、波形信道等
3.1.2 信道容量
定义:
- 信道所能传送的最大信息量
公式:
- C = m a x I ( X ; Y ) , p ( x i ) C=maxI(X;Y),p(x_i) C=maxI(X;Y),p(xi)
3.1.2.1 单位时间的信道容量
定义:
- 单位时间内信道所能传送的最大信息量
公式:
- C t = 1 t m a x I ( X ; Y ) , p ( x i ) C_t=\frac{1}{t}maxI(X;Y),p(x_i) Ct=t1maxI(X;Y),p(xi)
3.1.3 离散单个符号信道及其容量
3.1.3.1 对称DMC信道
定义:
- 如果转移概率矩阵P的每一行都是第一行的置换(即包含同样元素),称该矩阵是输入对称的
- 如果转移概率矩阵P的每一列都是第一列的置换(即包含同样元素),称该矩阵是输出对称的
- 输入输出都对称的离散无记忆信道称为对称DMC信道
信道容量:
-
C = l o g m − H ( Y ∣ x i ) = l o g m + ∑ j = 1 m p i j l o g p i j C=logm-H(Y|x_i)=logm+\sum_{j=1}^{m}p_{ij}logp_{ij} C=logm−H(Y∣xi)=logm+∑j=1mpijlogpij
-
m为信道输出符号集个数(即矩阵的列数)
3.1.3.2 准对阵DMC(离散无记忆信道)
定义:
- 只有输入对称,输出不对称
计算:
- 使用拉格朗日乘子法
- 把准对称DMC信道划分为多个对称DMC信道,带入公式:
- C = l o g n − H ( P 1 , P 2 , P 3 . . . ) − ∑ K = 1 r N k l o g M k C=logn-H(P_1,P_2,P_3...)-\sum_{K=1}^{r}N_klogM_k C=logn−H(P1,P2,P3...)−∑K=1rNklogMk
- n n n表示输入符号集个数(即矩阵的行数)
- H ( P 1 , P 2 , P 3 . . . ) H(P_1,P_2,P_3...) H(P1,P2,P3...)是转移概率矩阵P中一行的元素
- N k N_k Nk是第k个矩阵的行元素之和
- M k M_k Mk是第K个矩阵的列元素之和
3.1.4 串联信道
- 多个相同的信道串接一起组成串联信道,根据信息不增性可知,后面的互信息比之前的更小,新的串联信道的转移概率矩阵等于各个部分的信道转移概率矩阵相乘得到
- 串接的信道越多,其信道容量可能会越小,当串接信道数无限大时,信道容量就有可能趋于零
3.1.5 扩展信道
- 对离散单符号信道进行L次扩展,就形成了L次离散无记忆序列信道,计算扩展信道的信道容量的前提是把序列转移概率计算出来,后面使用对称信道容量的计算方法即可计算出信道容量
3.1.6 信噪比
- 信号功率与噪声功率之比
3.1.7 一般离散无记忆信道的充要条件
- 输入符号概率集中每一个符号 a i a_i ai对输出端 Y Y Y提供相同的互信息,概率为零的符号除外
3.1.8 连续信道容量的上下界
对于加性均值为零、平均功率为 σ 2 \sigma ^2 σ2的非高斯噪声信道的信道容量有上下界:
1 2 l o g ( 1 + S σ 2 ) ⩽ C ⩽ 1 2 l o g 2 π e P − H c ( n ) \frac{1}{2}log(1+\frac{S}{\sigma ^2})\leqslant C\leqslant \frac{1}{2}log2\pi eP-H_c(n) 21log(1+σ2S)⩽C⩽21log2πeP−Hc(n)
- σ 2 \sigma ^2 σ2为噪声功率
- S S S为信号功率
- P P P为输出功率,等于噪声功率+信号功率
- H c ( n ) H_c(n) Hc(n)为噪声熵
3.1.9 注水原理
- 设一个常数$\gamma 等 于 各 个 时 刻 信 号 平 均 功 率 与 噪 声 功 率 之 和 取 平 均 , 则 各 个 单 元 的 输 入 信 号 的 平 均 功 率 等 于 常 数 减 去 此 信 道 的 的 噪 声 功 率 , 如 果 某 个 单 元 时 刻 的 噪 声 大 于 常 数 等于各个时刻信号平均功率与噪声功率之和取平均,则各个单元的输入信号的平均功率等于常数减去此信道的的噪声功率,如果某个单元时刻的噪声大于常数 等于各个时刻信号平均功率与噪声功率之和取平均,则各个单元的输入信号的平均功率等于常数减去此信道的的噪声功率,如果某个单元时刻的噪声大于常数\gamma$,则分配的信号功率为零
3.1.10 香农公式
-
公式:
- C = W t B l o g ( 1 + P S N 0 W ) C=W_{t_B}log(1+\frac{P_S}{N_0W}) C=WtBlog(1+N0WPS)
- C t = W l o g ( 1 + P S N 0 W ) b i t / s C_t=Wlog(1+\frac{P_S}{N_0W})bit/s Ct=Wlog(1+N0WPS)bit/s
- AWGN信道的信道容量: C = W l o g ( 1 + S N R ) = W l o g ( 1 + P S N 0 W ) C=Wlog(1+SNR)=Wlog(1+\frac{P_S}{N_0W}) C=Wlog(1+SNR)=Wlog(1+N0WPS)
- W:信道频带宽度,简称带宽,单位Hz
- SNR:signal to noise ratio,信噪比,是信号功率(单位为W)与噪声功率(单位为W)的比值
- P s P_s Ps:信号发射功率
- N 0 N_0 N0:高斯白噪声的单边功率谱密度
-
提高信道容量的方式:
- 提升信道带宽
- 提升信噪比
- 提升发射功率
- 降低信道噪声
-
香农限:当带宽不受限制时,传送1比特信息,信噪比最低只需-1.6dB
-
对香农公式的讨论,说明增加信道容量的途径:
- C一定时,带宽W增加,信噪比SNR降低
- 当带宽W一定时,信噪比SNR与信道容量C呈对数关系,SNR增大,C就增大,但增大到一定程度之后趋于缓慢
- 当输入信号功率P一定,增加信道带宽,容量可以增加,但到一定阶段后增加变得缓慢。且带宽无限,信道容量仍是有限的
四、信息率失真函数
4.1 失真与失真矩阵
在现实生活中是有一定的失真的,某一信源,输出样值设为 X X X,经过有失真的编码器之后的输出样值设为 Y Y Y,两者的大小用一个失真函数 d ( x , y ) d(x,y) d(x,y)表示,把所有的函数 d ( x , y ) d(x,y) d(x,y)排列起来用矩阵表示,即失真矩阵
4.2 平均失真
- 失真函数的数学期望
- 引入原因:因为失真函数d(x,y)中x与y是随机变量,所以要分析整个信源的失真大小要用数学期望来表示
4.3 信息率失真函数R(D)
-
是关于平均失真的一个函数,信息传输率R越小,引起的平均失真D就越大
-
物理意义:对于给定信源,在平均失真不超过失真限度D的条件下,信息率容许压缩的最小值R(D)
-
重要结论:
- R ( D ) R(D) R(D)是非负的实数,即 R ( D ) ⩾ 0 R(D)\geqslant0 R(D)⩾0,其定义域为 0 D m a x 0~D_{max} 0 Dmax,其值为 0 H ( X ) 0~H(X) 0 H(X)。当 D > D m a x D>D_{max} D>Dmax时, R ( D ) ≡ 0 R(D)\equiv 0 R(D)≡0
- R ( D ) R(D) R(D)是关于D的下凸函数,因而是关于D的连续函数
- R ( D ) R(D) R(D)是关于D的严格递减函数
4.4 信息率失真函数与信道容量的比较
R ( D ) R(D) R(D)与 C C C的比较
| 类别 | 信道容量 C C C | 率失真函数 R ( D ) R(D) R(D) |
|---|---|---|
| 研究对象 | 信道 | 信源 |
| 给定条件 | 信道转移概率$p(y | x)$ |
| 选择参数 | 信源分布 p ( x ) p(x) p(x) | 信源编码器编码方法$p(y |
| 结论 | C = m a x I ( X ; Y ) , p ( x ) C=maxI(X;Y),p(x) C=maxI(X;Y),p(x) | R ( D ) = m i n I ( X ; Y ) , P D R(D)=minI(X;Y),P_D R(D)=minI(X;Y),PD |
| $H(X | Y)=H(X)-I(X;Y)$ | 噪声干扰丢失的信息量 |
五、信源编码
目的:提高通信系统的有效性
5.1 基本途径
- 使序列中的各个符号尽可能地相互独立,解除相关性
- 使编码中各个符号出现的概率尽可能相等,概率均匀化
5.2 信源编码的作用
- 符号变换:使信源的输出符号与信道的输入符号相匹配
- 信息匹配:使信息传输率达到信道容量
- 冗余度压缩:使编码效率等于或接近100%
5.3 码的分类
- 分组码与非分组码:把信源消息分成若干组,即符号序列 X i X_i Xi,序列中的每个符号取自符号集 A A A,每个符号依照固定的码表进行映射,这样的码称为分组码
- 奇异码和非奇异码:分组码中信源符号和码字是一一对应的称为非奇异码,反之为奇异码
- 唯一可译码和非唯一可译码:非奇异码中任意有限长的码元序列,只能被唯一地分割成一个个的码字,其他的分割都会产生一些非定义的码字称为唯一可译码
- 非即时码和即时码:唯一可译码中接收端接收到一个完整的码字之后,不能立即译码,还需要等待下一个码字开始接收后才可以判断是否可以译码称为非即时码。如果不需要等待下一个码字开始接收就可以开始译码称为即时码,也称非延时码
5.4 克劳夫特不等式
-
码数的作用:
- 用来构造即时码
- 用来检验一个唯一可译码是否为即时码
-
用树的概念可导出唯一可译码存在的充要条件是各码字的长度K要符合克劳夫特不等式,并不是唯一可译码的充要条件
-
∑ i = 1 n m − K i ⩽ 1 \sum^{n}_{i=1}m^{-K_i}\leqslant 1 ∑i=1nm−Ki⩽1
- m m m为进制数
- n n n为信源符号数
- K i K_i Ki为各码字的长度
5.5 编码定理
5.5.1 常见参数解析
- L L L:输入编码器的信息位长度
- m m m:进制数
- K L K_L KL:编码后的码字长度
- 定长编码中, K L K_L KL是定值
- 变长编码中, K L ‾ \overline{K_L} KL是码字平均长度
- $\eta $:编码前后的信息量比值
- 平均码长 K ‾ \overline{K} K:每一个信息位用几位编码来表示
- L = 1 L=1 L=1、二进制的情况下, K L ‾ = K ‾ \overline{K_L}=\overline{K} KL=K
5.5.2 无失真信源编码
- 定长编码
- 无失真条件: R ⩾ H ( X ) R\geqslant H(X) R⩾H(X)
- 输出信息率: R = K L L l o g m R=\frac{K_L}{L}logm R=LKLlogm
- 编码效率: η = H ( X ) R \eta =\frac{H(X)}{R} η=RH(X)
5.5.3 哈夫曼编码
- 变长编码
- 无失真条件: H ( X ) ⩽ R ‾ ⩽ H ( X ) + l o g m L H(X)\leqslant \overline{R} \leqslant H(X)+\frac{logm}{L} H(X)⩽R⩽H(X)+Llogm
- 平均输出信息率: R ‾ = K L ‾ L l o g m \overline{R}=\frac{\overline{K_L}}{L}logm R=LKLlogm
- 编码效率: η = H ( X ) R ‾ \eta=\frac{H(X)}{\overline{R}} η=RH(X)
- 码字平均长度: K L ‾ = ∑ i p ( x i ) K i \overline{K_L}=\sum_{i}p(x_i)K_i KL=∑ip(xi)Ki
- 平均码长: K ‾ = K L ‾ / L \overline{K}=\overline{K_L}/L K=KL/L