HtmlParser基础教程
1、相关资料
官方文档:http://htmlparser.sourceforge.net/samples.html
API:http://htmlparser.sourceforge.net/javadoc/index.html
其它HTML 解释器:jsoup等。由于HtmlParser自2006年以后就再没更新,目前很多人推荐使用jsoup代替它。
2、使用HtmlPaser的关键步骤
(1)通过Parser类创建一个解释器
(2)创建Filter或者Visitor
(3)使用parser根据filter或者visitor来取得所有符合条件的节点
(4)对节点内容进行处理
3、使用Parser的构造函数创建解释器
Parser() Zero argument constructor. |
Parser(Lexer lexer) Construct a parser using the provided lexer. |
Parser(Lexer lexer, ParserFeedback fb) Construct a parser using the provided lexer and feedback object. |
Parser(String resource) Creates a Parser object with the location of the resource (URL or file). |
Parser(String resource, ParserFeedback feedback) Creates a Parser object with the location of the resource (URL or file) You would typically create a DefaultHTMLParserFeedback object and pass it in. |
Parser(URLConnection connection) Construct a parser using the provided URLConnection. |
Parser(URLConnection connection, ParserFeedback fb) Constructor for custom HTTP access. |
这里比较有趣的一点是,如果需要设置页面的编码方式的话,不使用Lexer就只有静态函数一个方法了。对于大多数中文页面来说,好像这是应该用得比较多的一个方法。
4、HtmlPaser使用Node对象保存各节点信息
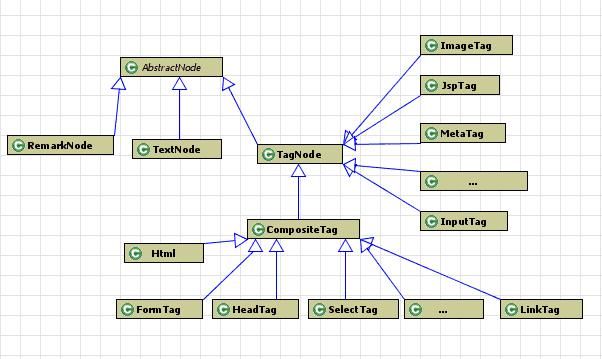
(1)访问各个节点的方法
Node getParent ():取得父节点
NodeList getChildren ():取得子节点的列表
Node getFirstChild ():取得第一个子节点
Node getLastChild ():取得最后一个子节点
Node getPreviousSibling ():取得前一个兄弟(不好意思,英文是兄弟姐妹,直译太麻烦而且不符合习惯,对不起女同胞了)
Node getNextSibling ():取得下一个兄弟节点
(2)取得Node内容的函数
String getText ():取得文本
String toPlainTextString():取得纯文本信息。
String toHtml () :取得HTML信息(原始HTML)
String toHtml (boolean verbatim):取得HTML信息(原始HTML)
String toString ():取得字符串信息(原始HTML)
Page getPage ():取得这个Node对应的Page对象
int getStartPosition ():取得这个Node在HTML页面中的起始位置
int getEndPosition ():取得这个Node在HTML页面中的结束位置
5、使用Filter访问Node节点及其内容
(1)Filter的种类
顾名思义,Filter就是对于结果进行过滤,取得需要的内容。
所有的Filter均实现了NodeFilter接口,此接口只有一个方法Boolean accept(Node node),用于确定某个节点是否属于此Filter过滤的范围。
HTMLParser在org.htmlparser.filters包之内一共定义了16个不同的Filter,也可以分为几类。
判断类Filter:
TagNameFilter
HasAttributeFilter
HasChildFilter
HasParentFilter
HasSiblingFilter
IsEqualFilter
逻辑运算Filter:
AndFilter
NotFilter
OrFilter
XorFilter
其他Filter:
NodeClassFilter
StringFilter
LinkStringFilter
LinkRegexFilter
RegexFilter
CssSelectorNodeFilter
除此以外,可以自定义一些Filter,用于完成特殊需求的过滤。
(2)Filter的使用示例
以下示例用于提取HTML文件中的链接
- package org.ljh.search.html;
- import java.util.HashSet;
- import java.util.Set;
- import org.htmlparser.Node;
- import org.htmlparser.NodeFilter;
- import org.htmlparser.Parser;
- import org.htmlparser.filters.NodeClassFilter;
- import org.htmlparser.filters.OrFilter;
- import org.htmlparser.tags.LinkTag;
- import org.htmlparser.util.NodeList;
- import org.htmlparser.util.ParserException;
- //本类创建用于HTML文件解释工具
- public class HtmlParserTool {
- // 本方法用于提取某个html文档中内嵌的链接
- public static Set<String> extractLinks(String url, LinkFilter filter) {
- Set<String> links = new HashSet<String>();
- try {
- // 1、构造一个Parser,并设置相关的属性
- Parser parser = new Parser(url);
- parser.setEncoding("gb2312");
- // 2.1、自定义一个Filter,用于过滤<Frame >标签,然后取得标签中的src属性值
- NodeFilter frameNodeFilter = new NodeFilter() {
- @Override
- public boolean accept(Node node) {
- if (node.getText().startsWith("frame src=")) {
- return true;
- } else {
- return false;
- }
- }
- };
- //2.2、创建第二个Filter,过滤<a>标签
- NodeFilter aNodeFilter = new NodeClassFilter(LinkTag.class);
- //2.3、净土上述2个Filter形成一个组合逻辑Filter。
- OrFilter linkFilter = new OrFilter(frameNodeFilter, aNodeFilter);
- //3、使用parser根据filter来取得所有符合条件的节点
- NodeList nodeList = parser.extractAllNodesThatMatch(linkFilter);
- //4、对取得的Node进行处理
- for(int i = 0; i<nodeList.size();i++){
- Node node = nodeList.elementAt(i);
- String linkURL = "";
- //如果链接类型为<a />
- if(node instanceof LinkTag){
- LinkTag link = (LinkTag)node;
- linkURL= link.getLink();
- }else{
- //如果类型为<frame />
- String nodeText = node.getText();
- int beginPosition = nodeText.indexOf("src=");
- nodeText = nodeText.substring(beginPosition);
- int endPosition = nodeText.indexOf(" ");
- if(endPosition == -1){
- endPosition = nodeText.indexOf(">");
- }
- linkURL = nodeText.substring(5, endPosition - 1);
- }
- //判断是否属于本次搜索范围的url
- if(filter.accept(linkURL)){
- links.add(linkURL);
- }
- }
- } catch (ParserException e) {
- e.printStackTrace();
- }
- return links;
- }
- }
程序中的一些说明:
(1)通过Node#getText()取得节点的String。
(2)node instanceof TagLink,即<a/>节点,其它还有很多的类似节点,如tableTag等,基本上每个常见的html标签均会对应一个tag。官方文档说明如下:
| org.htmlparser.nodes | The nodes package has the concrete node implementations. |
| org.htmlparser.tags | The tags package contains specific tags. |
其中用到的LinkFilter接口定义如下:
- package org.ljh.search.html;
- //本接口所定义的过滤器,用于判断url是否属于本次搜索范围。
- public interface LinkFilter {
- public boolean accept(String url);
- }
测试程序如下:
- package org.ljh.search.html;
- import java.util.Iterator;
- import java.util.Set;
- import org.junit.Test;
- public class HtmlParserToolTest {
- @Test
- public void testExtractLinks() {
- String url = "http://www.baidu.com";
- LinkFilter linkFilter = new LinkFilter(){
- @Override
- public boolean accept(String url) {
- if(url.contains("baidu")){
- return true;
- }else{
- return false;
- }
- }
- };
- Set<String> urlSet = HtmlParserTool.extractLinks(url, linkFilter);
- Iterator<String> it = urlSet.iterator();
- while(it.hasNext()){
- System.out.println(it.next());
- }
- }
- }
http://www.hao123.com
http://www.baidu.com/
http://www.baidu.com/duty/
http://v.baidu.com/v?ct=301989888&rn=20&pn=0&db=0&s=25&word=
http://music.baidu.com
http://ir.baidu.com
http://www.baidu.com/gaoji/preferences.html
http://news.baidu.com
http://map.baidu.com
http://music.baidu.com/search?fr=ps&key=
http://image.baidu.com
http://zhidao.baidu.com
http://image.baidu.com/i?tn=baiduimage&ct=201326592&lm=-1&cl=2&nc=1&word=
http://www.baidu.com/more/
http://shouji.baidu.com/baidusearch/mobisearch.html?ref=pcjg&from=1000139w
http://wenku.baidu.com
http://news.baidu.com/ns?cl=2&rn=20&tn=news&word=
https://passport.baidu.com/v2/?login&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2F
http://www.baidu.com/cache/sethelp/index.html
http://zhidao.baidu.com/q?ct=17&pn=0&tn=ikaslist&rn=10&word=&fr=wwwt
http://tieba.baidu.com/f?kw=&fr=wwwt
http://home.baidu.com
https://passport.baidu.com/v2/?reg®Type=1&tpl=mn&u=http%3A%2F%2Fwww.baidu.com%2F
http://v.baidu.com
http://e.baidu.com/?refer=888
;
http://tieba.baidu.com
http://baike.baidu.com
http://wenku.baidu.com/search?word=&lm=0&od=0
http://top.baidu.com
http://map.baidu.com/m?word=&fr=ps01000