Cloudera Impala是一种为Hadoop生态系统打造的开源MPP(massive parallel processing)数据库,它主要为分析型查询负载而设计,而非OLTP。Impala能最大限度地利用现代硬件和高效查询执行的最新技术。LLVM下的运行时代码生成就是用来提升执行性能的技术之一。
LLVM简介
LLVM是一个编译器及相关工具的库(toolchain),它不同于独立应用式(stand-alone)的传统编译器,LLVM是模块化且可重用的。它允许Impala这样的应用在运行的进程内执行JIT(just-in-time)编译。尽管LLVM因一些特殊的能力以及著名的工具,如比GCC更优的Clang编译器,但真正使LLVM区别于其他编译器的是它的内部架构。
经典静态编译器(像多数C编译器)中,最流行的设计是前端、优化器、后端组成的三阶段设计。前端解析源码并生成抽象语法树(AST,Abstract Syntax Tree)。优化器会做很多优化来提升代码性能。后端(或称代码生成器)将代码转换成目标平台的指令集。这种模型对解释器、JIT编译器。JVM也是这种模型的一种实现,它使用字节码作为前端和优化器之间的接口。

这种经典设计对于多语言(包括源语言和目标语言)支持非常重要。只要优化器内部使用一种公共代码表示,前端和后端就能够编译任意的语言。当需要移植(porting)编译器来支持一种新语言时,只需实现一个新前端,而优化器和后端都可以重用。否则就要重新实现整个编译器,支持M种源语言*N种目标语言。
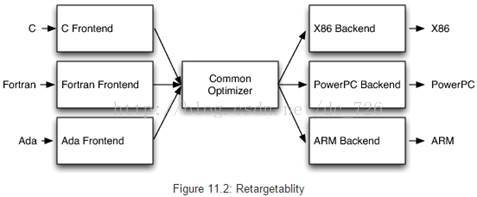
尽管各种编译器教科书中都讲到三阶段设计的种种优点,但实际上它从未被实现过。像Perl、Python、Ruby和Java的编译器实现并没有共享任何代码。此外,还有各种各样的特殊用途的编译器,例如图像处理、正则表达式等CPU密集型的子领域的JIT编译器。GCC由于混乱的代码结构而无法提取出可重用的组件,例如前端和后端重用了某些全局变量等,所以我们无法将GCC嵌入到应用程序中。下图是LLVM对三阶段设计的实现。
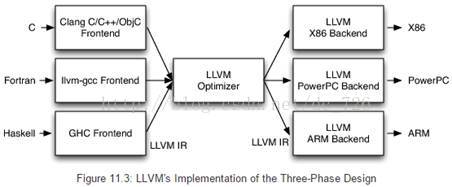
Impala中的LLVM
Impala使用LLVM在运行时产生完全优化并且查询特定的函数,这比通用的预编译函数有更好的性能。尤其是会在一次查询中执行许多次的内层循环(inner loop)的函数。例如,一个用来解析文件记录并装载进Impala内存元组的函数,在每个文件的每一条记录被扫描时都会被调用。对于这种函数,即使只是简单的移除一些指令也会得到速度上的巨大提升。
如果没有运行时的代码生成,为了处理编译时未知的运行时数据,函数中总是会包含低效的代码。例如,仅仅处理整数的记录解析函数,在处理只有整数的文件时,会比处理各种数据类型的通用函数要快得多。然而要扫描的文件schema在编译时是未知的,所以这种通用的函数尽管低效,却也是必要的。
下图1中的代码示例。编译时记录个数和类型都是未知的,所以处理函数要写的尽可能通用,避免发生未考虑到的情况。但JIT与这种思路完全相反,函数在运行时被完全编译成对当前数据最高效的写法。这在我们平时看来甚至都不能算作函数,因为完全不通用,逻辑都用常量固定写死了,但这正是JIT的策略!所以像下面的动态生成的MaterializeTuple对于不同的运行时信息(如不同的查询)会有完全不同的生成版本。

代码生成中的常用优化技术:
Ø 移除条件分支:因为已知运行时信息,所以可以优化if/switch语句。这是最简单有效的方式,因为最终机器码中的分支指令会阻止指令的管道化(instruction pipelining)和并行执行(instruction-level parallelism)。同时,通过展开for循环(因为我们已经知道循环次数)和解析数据类型,分支指令能被一起移除。
Ø 移除内存加载:从内存加载数据是开销很大而且阻止管道化的操作。如果每次加载的结果都一样的话,我们就可以使用代码生成来替代数据加载。例如,之前图1中的数组offsets_和types_在每次查询开始时创建而不会改变,于是在代码生成的函数版本中,展开for循环后,这些数组中的值可以直接内联化。
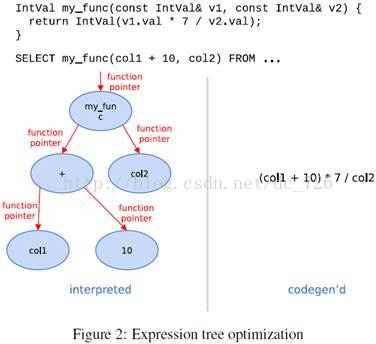
Ø 内联虚函数调用:虚函数对性能的影响很大,尤其是函数很小很简单,因为它无法内联化。因此当对象实例的类型在运行时可知时,我们可以使用代码生成来取代虚函数的调用,并做内联化。这对于表达式树的求值尤为有价值。在Impala中,表达式由操作和函数的树组成,例如下图2。树中出现的每种表达式都是覆盖(override)表达式基类的函数来实现的,基类会递归地调用各个子表达式。许多表达式函数都是非常简单的,例如两数相加,于是虚函数调用的开销甚至大过表达式求值的开销。通过代码生成移除虚函数并内联化,表达式可以无需函数调用而直接求值。此外,内联后的函数使编译器做进一步的优化,例如子表达式消除等。
用LLVM生成代码
当Impala受到查询计划(query plan,由Impala的Java前端负责生成)时,LLVM会被用来在查询执行开始前,生成并编译对性能至关重要的函数的查询特定版本。LLVM主要使用IR(intermediate representation)来生成代码,例如LLVM的前端Clang C++编译器生成IR,LLVM优化IR并将其编译成机器码。IR类似于汇编语言,由一些简单的、能够直接映射成机器码的指令组成。在Impala中有两种技术来生成IR函数:使用LLVM的IRBuilder API来编程式地生成IR指令;使用CLang将C++函数交叉编译成IR。
下图是IR的例子。可以看出,IR是一种类RISC的虚拟指令集。它支持加减、比较、分支等指令。此外,IR还支持标签。但与多数RISC不同的是:
Ø LLVM是强类型的,它有一套简单的类型系统,例如i32, i32**,add i32。
Ø LLVM IR支持无限的临时寄存器,以%开头。
因为优化器不受源语言和目标平台限制,所以IR的设计也要遵守这个原则。

在LLVM中,优化器被组织成优化pass的管道,常见的pass有内联化、表达式重组、循环不变量移动等。每个pass都作为继承Pass类的C++类,并定义在一个私有的匿名namespace中,同时提供一个让外界获得到pass的函数。

我们可以决定pass的执行顺序甚至是否执行。当我们实现一种图像处理语言的JIT编译器时,我们可以去掉没用的pass。例如,如果通常都是大函数的话,就没必要浪费时间内联。如果指针很少的话,那么别名分析和内存优化就变得可有可无。但是LLVM不是万能的,PassManager本身也并不知道每个pass内部的逻辑,所以这还是由我们实现者来确定的。
参考资料
1 Runtime Code Generation in Cloudera Impala
2 The Architecture of Open Source Application
http://www.aosabook.org/en/llvm.html