hadoop大数据平台的简介及搭建
Hadoop
- 1.简介
- 2.hadoop的优点
- 3.hadoop核心架构
- 4.hadoop应用场景
- 5.hadoop工作模式
-
- 5.1单机模式(Local (Standalone) Mode)
- 5.2Pseudo-Distributed Mode伪分布式
-
- 5.2.1配置
- 5.2.2测试
- 5.3完全分布式
-
- 5.3.1部署
- 5.3.2测试
- 6.双机热备
-
- 6.1节点扩容
-
- 6.1.1配置
- 6.1.2效果
- 6.1.3上传文件
- 6.2缩减节点
- 7.hdfs高可用
-
- 7.1清理环境,安装zookeeper
- 7.2在各节点启动服务
- 7.3hadoop配置参数
- 7.4启动hdfs集群(按顺序启动)
-
- 7.4.1配置server5并加入集群
- 7.4.2在三个 DN 上依次启动 zookeeper 集群(三台操作一致)
- 7.4.3 在三个 DN 上依次启动 journalnode(第一次启动 hdfs 必须先启动 journalnode)
- 7.4.4 格式化 HDFS 集群
- 7.4.5 启动 hdfs 集群(只需在 h1 上执行即可)
- 7.4.6 查看各节点状态
- 7.5测试故障自动切换
- 8.yarn 的高可用
-
- 8.1配置
- 8.2启动
- 8.3测试
1.简介
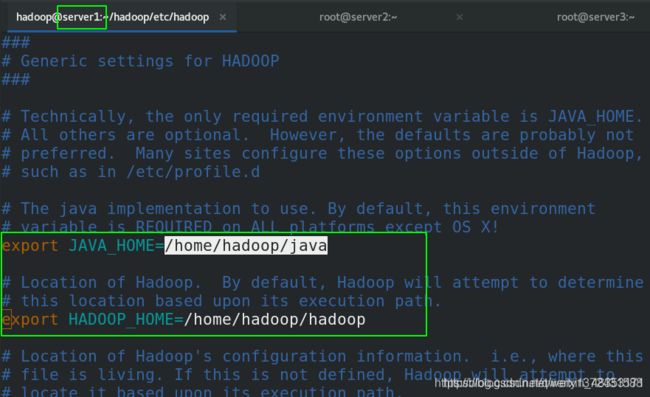
- Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
- Hadoop实现了一个分布式文件系统( Distributed File System),其中一个组件是HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large dataset)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
- Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算。
- Hadoop框架包括以下四个模块:
Hadoop Common: 这些是其他Hadoop模块所需的Java库和实用程序。这些库提供文件系统和操作系统级抽象,并包含启动Hadoop所需的Java文件和脚本。
Hadoop YARN: 这是一个用于作业调度和集群资源管理的框架。
Hadoop Distributed File System (HDFS): 分布式文件系统,提供对应用程序数据的高吞吐量访问。
Hadoop MapReduce:这是基于YARN的用于并行处理大数据集的系统。 - HDFS属于Master与Slave结构。一个集群中只有一个NameNode,可以有多个DataNode。
- HDFS存储机制保存了多个副本,当写入1T文件时,我们需要3T的存储,3T的网络流量带宽;系统提供容错机制,副本丢失或宕机可自动恢复,保证系统高可用性。
HDFS默认会将文件分割成block。然后将block按键值对存储在HDFS上,并将键值对的映射存到内存中。如果小文件太多,会导致内存的负担很重。 - HDFS采用的是一次写入多次读取的文件访问模型。一个文件经过创建、写入和关闭之后就不需要改变。这一假设简化了数据一致性问题,并且使高吞吐量的数据访问成为可能。
HDFS存储理念是以最少的钱买最烂的机器并实现最安全、难度高的分布式文件系统(高容错性低成本),HDFS认为机器故障是种常态,所以在设计时充分考虑到单个机器故障,单个磁盘故障,单个文件丢失等情况。
2.hadoop的优点
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。它主要有以下几个优点:
- 高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
- 高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
- 高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
- 高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
节点失败监测机制:DN每隔3秒向NN发送心跳信号,10分钟收不到,认为DN宕机。
通信故障监测机制:只要发送了数据,接收方就会返回确认码。
数据错误监测机制:在传输数据时,同时会发送总和校验码。 - 低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
- Hadoop带有用Java语言编写的框架,因此运行在 Linux 生产平台上是非常理想的。Hadoop 上的应用程序也可以使用其他语言编写,比如 C++。
3.hadoop核心架构
Hadoop 由许多元素构成。其最底部是 Hadoop Distributed File System(HDFS),它存储 Hadoop 集群中所有存储节点上的文件。HDFS的上一层是MapReduce 引擎,该引擎由 JobTrackers 和 TaskTrackers 组成。通过对Hadoop分布式计算平台最核心的分布式文件系统HDFS、MapReduce处理过程,以及数据仓库工具Hive和分布式数据库Hbase的介绍,基本涵盖了Hadoop分布式平台的所有技术核心。
- HDFS
对外部客户机而言,HDFS就像一个传统的分级文件系统。可以创建、删除、移动或重命名文件,等等。但是 HDFS 的架构是基于一组特定的节点构建的(参见图 1),这是由它自身的特点决定的。这些节点包括 NameNode(仅一个),它在 HDFS 内部提供元数据服务;DataNode,它为 HDFS 提供存储块。由于仅存在一个 NameNode,因此这是 HDFS 1.x版本的一个缺点(单点失败)。在Hadoop 2.x版本可以存在两个NameNode,解决了单节点故障问题。
存储在 HDFS 中的文件被分成块,然后将这些块复制到多个计算机中(DataNode)。这与传统的 RAID 架构大不相同。块的大小(1.x版本默认为 64MB,2.x版本默认为128MB)和复制的块数量在创建文件时由客户机决定。NameNode 可以控制所有文件操作。HDFS 内部的所有通信都基于标准的 TCP/IP 协议。

- NameNode
NameNode 是一个通常在 HDFS 实例中的单独机器上运行的软件。它负责管理文件系统名称空间和控制外部客户机的访问。NameNode 决定是否将文件映射到 DataNode 上的复制块上。对于最常见的 3 个复制块,第一个复制块存储在同一机架的不同节点上,最后一个复制块存储在不同机架的某个节点上。
实际的 I/O事务并没有经过 NameNode,只有表示 DataNode 和块的文件映射的元数据经过 NameNode。当外部客户机发送请求要求创建文件时,NameNode 会以块标识和该块的第一个副本的 DataNode IP 地址作为响应。这个 NameNode 还会通知其他将要接收该块的副本的 DataNode。
NameNode 在一个称为 FsImage 的文件中存储所有关于文件系统名称空间的信息。这个文件和一个包含所有事务的记录文件(这里是 EditLog)将存储在 NameNode 的本地文件系统上。FsImage 和 EditLog 文件也需要复制副本,以防文件损坏或 NameNode 系统丢失。
NameNode本身不可避免地具有SPOF(Single Point Of Failure)单点失效的风险,主备模式并不能解决这个问题,通过Hadoop Non-stop namenode才能实现100% uptime可用时间。 - DataNode
DataNode 也是一个通常在 HDFS实例中的单独机器上运行的软件。Hadoop 集群包含一个 NameNode 和大量 DataNode。DataNode 通常以机架的形式组织,机架通过一个交换机将所有系统连接起来。Hadoop 的一个假设是:机架内部节点之间的传输速度快于机架间节点的传输速度。
DataNode 响应来自 HDFS 客户机的读写请求。它们还响应来自 NameNode 的创建、删除和复制块的命令。NameNode 依赖来自每个 DataNode 的定期心跳(heartbeat)消息。每条消息都包含一个块报告,NameNode 可以根据这个报告验证块映射和其他文件系统元数据。如果 DataNode 不能发送心跳消息,NameNode 将采取修复措施,重新复制在该节点上丢失的块。 - 文件操作
可见,HDFS 并不是一个万能的文件系统。它的主要目的是支持以流的形式访问写入的大型文件。
如果客户机想将文件写到 HDFS 上,首先需要将该文件缓存到本地的临时存储。如果缓存的数据大于所需的 HDFS 块大小,创建文件的请求将发送给 NameNode。NameNode 将以 DataNode 标识和目标块响应客户机。
同时也通知将要保存文件块副本的 DataNode。当客户机开始将临时文件发送给第一个 DataNode 时,将立即通过管道方式将块内容转发给副本 DataNode。客户机也负责创建保存在相同 HDFS名称空间中的校验和(checksum)文件。
在最后的文件块发送之后,NameNode 将文件创建提交到它的持久化元数据存储(在 EditLog 和 FsImage 文件)。 - Linux 集群
Hadoop 框架可在单一的 Linux 平台上使用(开发和调试时),官方提供MiniCluster作为单元测试使用,不过使用存放在机架上的商业服务器才能发挥它的力量。这些机架组成一个 Hadoop 集群。它通过集群拓扑知识决定如何在整个集群中分配作业和文件。Hadoop 假定节点可能失败,因此采用本机方法处理单个计算机甚至所有机架的失败。
4.hadoop应用场景
- 在线旅游
- 移动数据
- 电子商务
- 能源开采与节能
- 基础架构管理
- 图像处理
- 诈骗检测
- IT安全
- 医疗保健
5.hadoop工作模式
5.1单机模式(Local (Standalone) Mode)
[root@server1 ~]# ls
hadoop-3.2.1.tar.gz jdk-8u181-linux-x64.tar.gz
[root@server1 ~]# useradd -u 1000 hadoop
[root@server1 ~]# mv * /home/hadoop/
[root@server1 ~]# su - hadoop
[root@server1 ~]# echo westos | passwd --stdin hadoop
[hadoop@server1 ~]$ tar zxf hadoop-3.2.1.tar.gz
[hadoop@server1 ~]$ tar zxf jdk-8u181-linux-x64.tar.gz
[hadoop@server1 ~]$ ln -s jdk1.8.0_181/ java
[hadoop@server1 ~]$ ln -s hadoop-3.2.1 hadoop
[hadoop@server1 ~]$ ls
hadoop hadoop-3.2.1.tar.gz jdk1.8.0_181
hadoop-3.2.1 java jdk-8u181-linux-x64.tar.gz
[hadoop@server1 ~]$ cd /home/hadoop/hadoop
[hadoop@server1 hadoop]$ ls
bin include libexec NOTICE.txt sbin
etc lib LICENSE.txt README.txt share
[hadoop@server1 hadoop]$ mkdir input
[hadoop@server1 hadoop]$ cp etc/hadoop/*.xml input
[hadoop@server1 hadoop]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar grep input output 'dfs[a-z.]+'
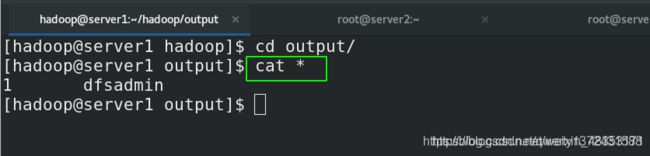
[hadoop@server1 hadoop]$ cd output/
[hadoop@server1 output]$ cat *
1 dfsadmin



5.2Pseudo-Distributed Mode伪分布式
5.2.1配置
- 副本数只能为1
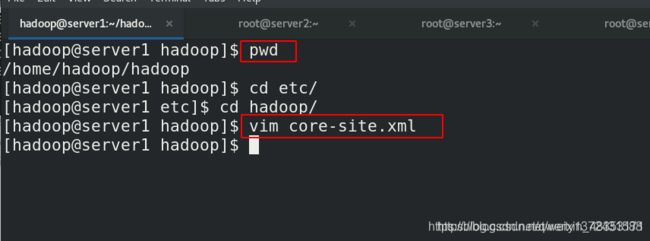
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ cd etc/
[hadoop@server1 etc]$ cd hadoop/
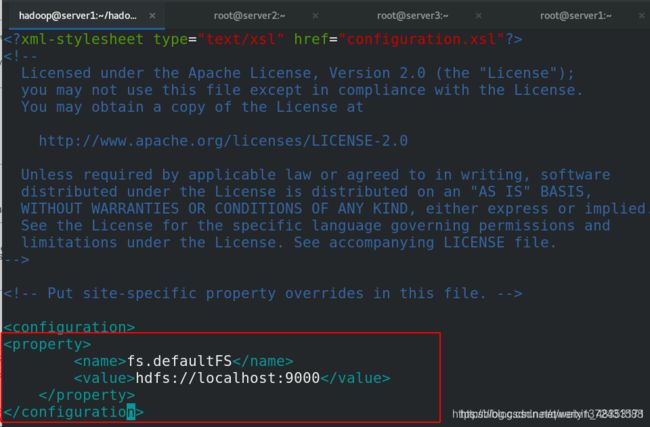
[hadoop@server1 hadoop]$ vim core-site.xml
[hadoop@server1 hadoop]$ vim hdfs-site.xml
[hadoop@server1 hadoop]$ ssh-keygen ##做免密
[hadoop@server1 hadoop]$ ssh-copy-id localhost
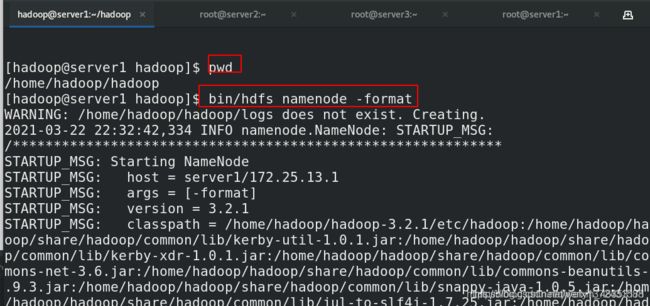
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ bin/hdfs namenode -format ##
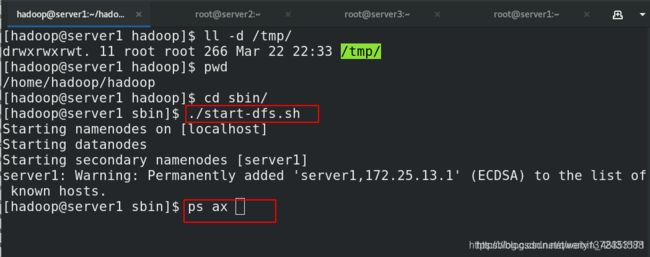
[hadoop@server1 hadoop]$ ll -d /tmp/
drwxrwxrwt. 11 root root 266 Mar 22 22:33 /tmp/
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ cd sbin/
[hadoop@server1 sbin]$ ./start-dfs.sh
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [server1]
server1: Warning: Permanently added 'server1,172.25.13.1' (ECDSA) to the list of known hosts.
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
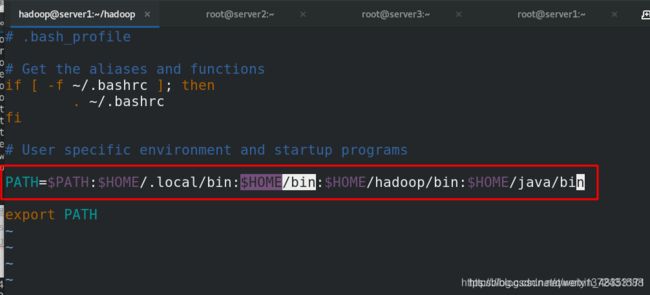
[hadoop@server1 hadoop]$ vim ~/.bash_profile
[hadoop@server1 hadoop]$ source ~/.bash_profile
[hadoop@server1 hadoop]$ grep hadoop ~/.bash_profile
PATH=$PATH:$HOME/.local/bin:$HOME/bin:$HOME/hadoop/bin:$HOME/java/bin
[hadoop@server1 hadoop]$ jps
14595 Jps
14453 SecondaryNameNode
14122 NameNode
14268 DataNode
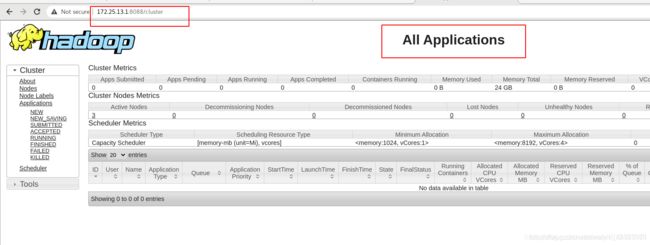
[hadoop@server1 hadoop]$ hdfs dfsadmin -report ##报告,可以不做,直接使用图形界面






5.2.2测试
[hadoop@server1 hadoop]$ hdfs dfs -ls /
[hadoop@server1 hadoop]$ hdfs dfs -ls
ls: `.': No such file or directory
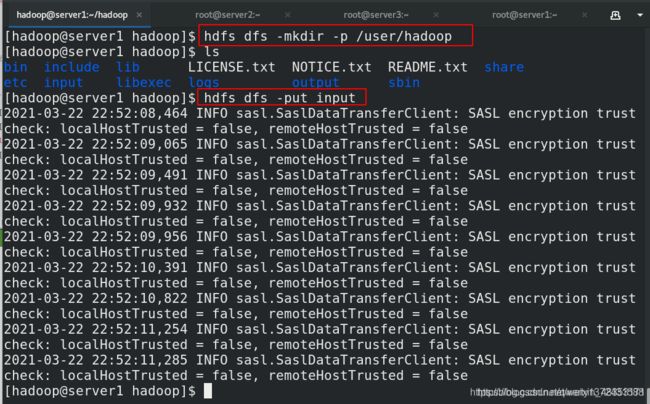
[hadoop@server1 hadoop]$ hdfs dfs -mkdir -p /user/hadoop ##建立目录,必须是user,默认的,用户和本地用户相匹配
[hadoop@server1 hadoop]$ hdfs dfs -put input ##建立文件夹
[hadoop@server1 hadoop]$ hdfs dfs -rm -r /usr/ ##删除命令
[hadoop@server1 hadoop]$ hdfs dfs -ls input ##查看文件
[hadoop@server1 sbin]$ ./stop-dfs.sh ##停止服务



5.3完全分布式
5.3.1部署
## 0.停止
[hadoop@server1 sbin]$ ./stop-dfs.sh ##必须保证关闭
[root@server1 ~]# yum install -y nfs-utils ##安装nfs共享文件系统,三个节点同时安装
## 1. server1操作
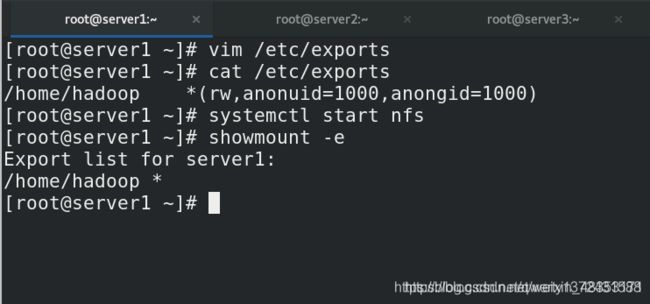
[root@server1 ~]# vim /etc/exports
[root@server1 ~]# cat /etc/exports
/home/hadoop *(rw,anonuid=1000,anongid=1000)
[root@server1 ~]# systemctl start nfs
[root@server1 ~]# showmount -e
Export list for server1:
/home/hadoop *
##2.server2操作(server3与之一样)
[root@server2 ~]# useradd -u 1000 hadoop
[root@server2 ~]# ll -d /home/hadoop/
drwx------ 2 hadoop hadoop 62 Mar 22 23:15 /home/hadoop/
[root@server2 ~]# mount 172.25.13.1:/home/hadoop/ /home/hadoop/
[root@server2 ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/rhel-root 17811456 1159784 16651672 7% /
devtmpfs 1011448 0 1011448 0% /dev
tmpfs 1023468 0 1023468 0% /dev/shm
tmpfs 1023468 16964 1006504 2% /run
tmpfs 1023468 0 1023468 0% /sys/fs/cgroup
/dev/vda1 1038336 167848 870488 17% /boot
tmpfs 204696 0 204696 0% /run/user/0
172.25.13.1:/home/hadoop 17811456 3033856 14777600 18% /home/hadoop
## 3. server1进行配置
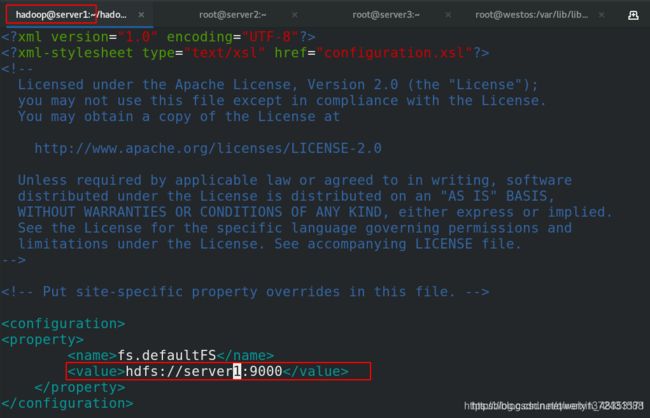
[hadoop@server1 hadoop]$ vim core-site.xml ##localhost改成server1
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
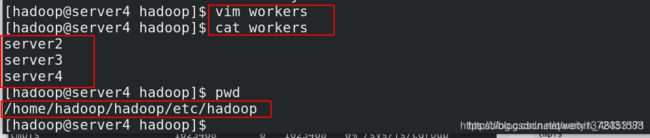
[hadoop@server1 hadoop]$ cat workers ##一定要有解析
server2
server3
[hadoop@server1 hadoop]$ vim hdfs-site.xml ##副本数改成2
[hadoop@server1 hadoop]$ hdfs namenode -format ##格式化
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ sbin/start-dfs.sh ##启动节点
Starting namenodes on [server1]
Starting datanodes
Starting secondary namenodes [server1]
[hadoop@server1 hadoop]$ jps ##只是作为master节点
16595 NameNode
16819 SecondaryNameNode
16939 Jps
[root@server2 ~]# su - hadoop ##server2和3作为数据节点,slave端
Last login: Mon Mar 22 23:18:07 EDT 2021 from server1 on pts/1
[hadoop@server2 ~]$ jps
13862 Jps
13767 DataNode






5.3.2测试
[hadoop@server1 hadoop]$ hdfs dfs -mkdir -p /user/hadoop
[hadoop@server1 hadoop]$ hdfs dfs -mkdir input
[hadoop@server1 hadoop]$ hdfs dfs -ls
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2021-03-22 23:39 input
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ cd etc/hadoop/
[hadoop@server1 hadoop]$ hdfs dfs -put * input


6.双机热备
6.1节点扩容
6.1.1配置
## 1. 创建一个新的机器
[root@server4 ~]# yum install -t nfs-utils
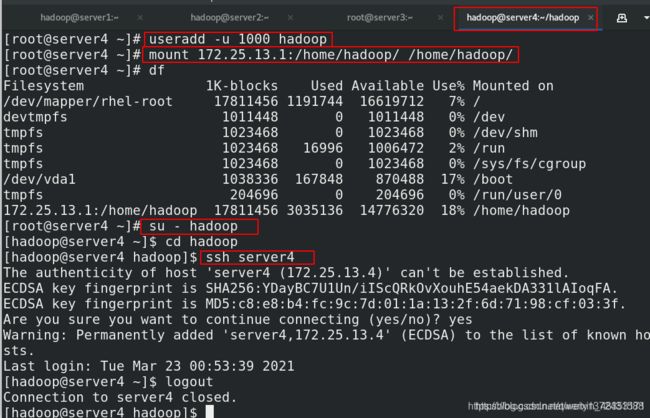
[root@server4 ~]# useradd -u 1000 hadoop
[root@server4 ~]# mount 172.25.13.1:/home/hadoop/ /home/hadoop/
[root@server4 ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/rhel-root 17811456 1191744 16619712 7% /
devtmpfs 1011448 0 1011448 0% /dev
tmpfs 1023468 0 1023468 0% /dev/shm
tmpfs 1023468 16996 1006472 2% /run
tmpfs 1023468 0 1023468 0% /sys/fs/cgroup
/dev/vda1 1038336 167848 870488 17% /boot
tmpfs 204696 0 204696 0% /run/user/0
172.25.13.1:/home/hadoop 17811456 3035136 14776320 18% /home/hadoop
[root@server4 ~]# su - hadoop
[hadoop@server4 ~]$ cd hadoop
[hadoop@server4 hadoop]$ ssh server4
The authenticity of host 'server4 (172.25.13.4)' can't be established.
ECDSA key fingerprint is SHA256:YDayBC7U1Un/iIScQRkOvXouhE54aekDA331lAIoqFA.
ECDSA key fingerprint is MD5:c8:e8:b4:fc:9c:7d:01:1a:13:2f:6d:71:98:cf:03:3f.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added 'server4,172.25.13.4' (ECDSA) to the list of known hosts.
Last login: Tue Mar 23 00:53:39 2021
[hadoop@server4 ~]$ logout
## 2. 修改配置文件
[hadoop@server4 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@server4 hadoop]$ cat workers
server2
server3
server4
## 3. 启动
[hadoop@server4 hadoop]$ cd /home/hadoop/hadoop/bin/
[hadoop@server4 bin]$ hdfs --daemon start datanode
[hadoop@server4 bin]$ ps ax


6.1.2效果


6.1.3上传文件
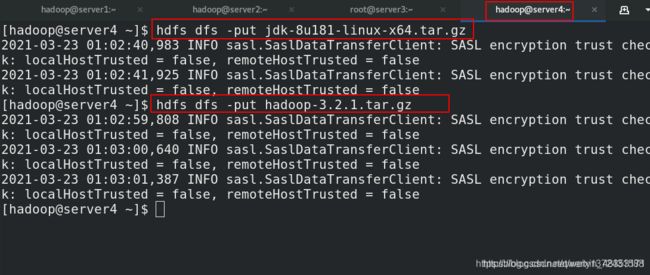
[hadoop@server4 ~]$ hdfs dfs -put jdk-8u181-linux-x64.tar.gz
[hadoop@server4 ~]$ hdfs dfs -put hadoop-3.2.1.tar.gz



6.2缩减节点
[hadoop@server1 sbin]$ pwd
/home/hadoop/hadoop/sbin
[hadoop@server1 sbin]$ ./stop-dfs.sh
Stopping namenodes on [server1]
Stopping datanodes
Stopping secondary namenodes [server1]
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@server1 hadoop]$ vim hdfs-site.xml
dfs.hosts.exclude</name>
/home/hadoop/hadoop/etc/hadoop/excludes</value>
</property>
[hadoop@server1 hadoop]$ cat excludes
server3
[hadoop@server1 sbin]$ ./start-dfs.sh
Starting namenodes on [server1]
Starting datanodes
Starting secondary namenodes [server1]
##至此随意修改excludes文件内容,就可以控制缩减哪个节点
[hadoop@server1 hadoop]$ hdfs dfsadmin -refreshNodes ##修改之后进行刷新



7.hdfs高可用
server1,server5作为master,server2,server3,server4作为日志节点
7.1清理环境,安装zookeeper
## 1. 清理环境并安装zookeeper
[hadoop@server1 ~]$ cd hadoop/sbin/
[hadoop@server1 sbin]$ ./stop-dfs.sh ##关掉集群
[hadoop@server1 sbin]$ ps ax
[hadoop@server1 ~]$ rm -fr /tmp/* ##删除/tmp/下的文件 ,不行就使用root用户
[hadoop@server1 ~]$ tar zxf zookeeper-3.4.9.tar.gz ##解压,做协调器
[hadoop@server2 ~]$ cd zookeeper-3.4.9/
[hadoop@server2 zookeeper-3.4.9]$ ls
bin dist-maven LICENSE.txt src
build.xml docs NOTICE.txt zookeeper-3.4.9.jar
CHANGES.txt ivysettings.xml README_packaging.txt zookeeper-3.4.9.jar.asc
conf ivy.xml README.txt zookeeper-3.4.9.jar.md5
contrib lib recipes zookeeper-3.4.9.jar.sha1
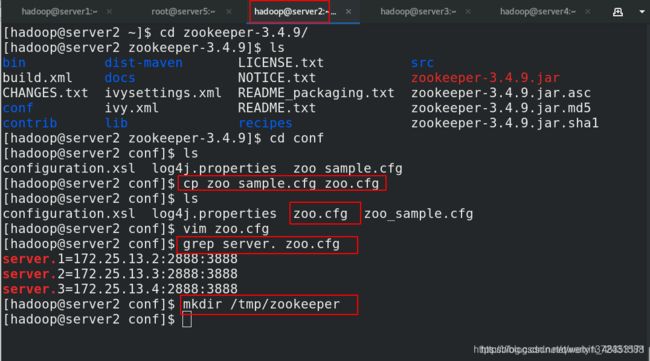
[hadoop@server2 zookeeper-3.4.9]$ cd conf
[hadoop@server2 conf]$ ls
configuration.xsl log4j.properties zoo_sample.cfg
[hadoop@server2 conf]$ cp zoo_sample.cfg zoo.cfg
[hadoop@server2 conf]$ ls
configuration.xsl log4j.properties zoo.cfg zoo_sample.cfg
[hadoop@server2 conf]$ vim zoo.cfg ##文件修改的内容如下,目录需要自己创建
[hadoop@server2 conf]$ grep server. zoo.cfg
server.1=172.25.13.2:2888:3888
server.2=172.25.13.3:2888:3888
server.3=172.25.13.4:2888:3888
[hadoop@server2 conf]$ mkdir /tmp/zookeeper
[hadoop@server2 conf]$ echo 1 > /tmp/zookeeper/myid ##写入id号,主机和文件中对应
[hadoop@server3 ~]$ mkdir /tmp/zookeeper
[hadoop@server3 ~]$ echo 2 > /tmp/zookeeper/myid
[hadoop@server4 ~]$ mkdir /tmp/zookeeper
[hadoop@server4 ~]$ echo 3 > /tmp/zookeeper/myid
7.2在各节点启动服务
[hadoop@server2 zookeeper-3.4.9]$ pwd
/home/hadoop/zookeeper-3.4.9
[hadoop@server2 zookeeper-3.4.9]$ bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.9/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@server3 ~]$ cd zookeeper-3.4.9/
[hadoop@server3 zookeeper-3.4.9]$ bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.9/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@server4 ~]$ cd zookeeper-3.4.9/
[hadoop@server4 zookeeper-3.4.9]$ bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.9/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
7.3hadoop配置参数
## 1. 编辑 core-site.xml 文件:
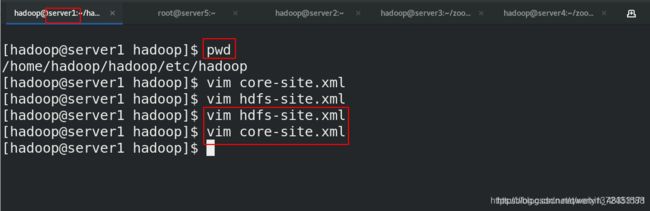
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@server1 hadoop]$ vim core-site.xml
<!-- 指定 hdfs 的 namenode 为 masters (名称可自定义)-->
fs.defaultFS</name>
hdfs://masters</value>
</property>
<!-- 指定 zookeeper 集群主机地址 -->
ha.zookeeper.quorum</name>
172.25.13.2:2181,172.25.13.3:2181,172.25.13.4:2181</value>
</property>
</configuration>
## 2. 编辑 hdfs-site.xml 文件
dfs.replication</name>
3</value>
</property>
dfs.permissions</name>
false</value>
</property>
<!-- 指定 hdfs 的 nameservices 为 masters,和 core-site.xml 文件中的设置保持一
致 -->
dfs.nameservices</name>
masters</value>
</property>
<!-- masters 下面有两个 namenode 节点,分别是 h1 和 h2 (名称可自定义)
-->
dfs.ha.namenodes.masters</name>
h1,h2</value>
</property>
<!-- 指定 h1 节点的 rpc 通信地址 -->
dfs.namenode.rpc-address.masters.h1</name>
172.25.0.1:9000</value>
</property>
<!-- 指定 h1 节点的 http 通信地址 -->
dfs.namenode.http-address.masters.h1</name>
172.25.0.1:50070</value>
</property>
<!-- 指定 h2 节点的 rpc 通信地址 -->
dfs.namenode.rpc-address.masters.h2</name>
172.25.0.5:9000</value>
</property>
<!-- 指定 h2 节点的 http 通信地址 -->
dfs.namenode.http-address.masters.h2</name>
172.25.0.5:50070</value>
</property>
<!-- 指定 NameNode 元数据在 JournalNode 上的存放位置 -->
dfs.namenode.shared.edits.dir</name>
qjournal://172.25.0.2:8485;172.25.0.3:8485;172.25.0.4:8485/masters</value>
</property>
<!-- 指定 JournalNode 在本地磁盘存放数据的位置 -->
dfs.journalnode.edits.dir</name>
/tmp/journaldata</value>
</property>
<!-- 开启 NameNode 失败自动切换 -->
dfs.ha.automatic-failover.enabled</name>
true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
dfs.client.failover.proxy.provider.masters</name>
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvid
er</value>
</property>
<!-- 配置隔离机制方法,每个机制占用一行-->
dfs.ha.fencing.methods</name>
sshfence
shell(/bin/true)
</value>
</property>
<!-- 使用 sshfence 隔离机制时需要 ssh 免密码 -->
dfs.ha.fencing.ssh.private-key-files</name>
/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 配置 sshfence 隔离机制超时时间 -->
dfs.ha.fencing.ssh.connect-timeout</name>
30000</value>
</property>
</configuration>
7.4启动hdfs集群(按顺序启动)
7.4.1配置server5并加入集群
[root@server5 ~]# yum install nfs-utils -y ##安装nfs
[root@server5 ~]# useradd -u 1000 hadoop
[root@server5 ~]# mount 172.25.13.1:/home/hadoop/ /home/hadoop/
[root@server5 ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/rhel-root 17811456 1159864 16651592 7% /
devtmpfs 1011448 0 1011448 0% /dev
tmpfs 1023468 0 1023468 0% /dev/shm
tmpfs 1023468 16964 1006504 2% /run
tmpfs 1023468 0 1023468 0% /sys/fs/cgroup
/dev/vda1 1038336 167848 870488 17% /boot
tmpfs 204696 0 204696 0% /run/user/0
172.25.13.1:/home/hadoop 17811456 3071232 14740224 18% /home/hadoop
[root@server5 ~]# su - hadoop

7.4.2在三个 DN 上依次启动 zookeeper 集群(三台操作一致)
##1)在三个 DN 上依次启动 zookeeper 集群(三台操作一致),现在server3是leader
[hadoop@server2 zookeeper-3.4.9]$ pwd
/home/hadoop/zookeeper-3.4.9
[hadoop@server2 zookeeper-3.4.9]$ bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.9/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
[hadoop@server2 zookeeper-3.4.9]$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /home/hadoop/zookeeper-3.4.9/bin/../conf/zoo.cfg
Mode: follower
1594 Jps3)格式化 HDFS 集群
$ bin/hdfs namenode -format
Namenode 数据默认存放在/tmp,需要把数据拷贝到 h2
$ scp -r /tmp/hadoop-hadoop 172.25.0.5:/tmp
3) 格式化 zookeeper (只需在 h1 上执行即可)
$ bin/hdfs zkfc -formatZK
(注意大小写)
4)启动 hdfs 集群(只需在 h1 上执行即可)
$ sbin/start-dfs.sh
5) 查看各节点状态
[hadoop@server1 hadoop]$ jps
1431 NameNode
1739 DFSZKFailoverController
2013 Jps
[hadoop@server5 ~]$ jps
1191 NameNode
1293 DFSZKFailoverController
1856 Jps
[hadoop@server2 ~]$ jps
1493 JournalNode
1222 QuorumPeerMain
1400 DataNode
1594 Jps
[hadoop@server3 ~]$ jps
1578 Jps
1176 QuorumPeerMain
1329 DataNode
1422 JournalNode
[hadoop@server4 ~]$ jps
1441 Jps
1153 QuorumPeerMain
1239 DataNode
1332 JournalNode

7.4.3 在三个 DN 上依次启动 journalnode(第一次启动 hdfs 必须先启动 journalnode)
[hadoop@server2 zookeeper-3.4.9]$ hdfs --daemon start journalnode ##server234一样
[hadoop@server2 zookeeper-3.4.9]$ jps
4304 Jps
4263 JournalNode
3918 QuorumPeerMain
7.4.4 格式化 HDFS 集群
[hadoop@server1 hadoop]$ hdfs namenode -format ##格式化
#Namenode 数据默认存放在/tmp,需要把数据拷贝到 h2
[hadoop@server1 hadoop]$ scp -r /tmp/hadoop-hadoop 172.25.13.5:/tmp
7.4.5 格式化 zookeeper (只需在 h1 上执行即可)
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ bin/hdfs zkfc -formatZK
[hadoop@server3 zookeeper-3.4.9]$ cd bin/
[hadoop@server3 bin]$ pwd
/home/hadoop/zookeeper-3.4.9/bin
[hadoop@server3 bin]$ ls
README.txt zkCli.cmd zkEnv.cmd zkServer.cmd
zkCleanup.sh zkCli.sh zkEnv.sh zkServer.sh
[hadoop@server3 bin]$ ./zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper, hadoop-ha]
[zk: localhost:2181(CONNECTED) 1] ls /hadoop-ha/masters
[]
[zk: localhost:2181(CONNECTED) 2] get /hadoop-ha/masters
cZxid = 0x300000003
ctime = Tue Mar 23 08:33:19 EDT 2021
mZxid = 0x300000003
mtime = Tue Mar 23 08:33:19 EDT 2021
pZxid = 0x300000003
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 0
[zk: localhost:2181(CONNECTED) 3]
7.4.5 启动 hdfs 集群(只需在 h1 上执行即可)
[hadoop@server1 sbin]$ pwd
/home/hadoop/hadoop/sbin
[hadoop@server1 sbin]$ ./start-dfs.sh
Starting namenodes on [server1 server5]
Starting datanodes
Starting journal nodes [server4 server3 server2]
server4: journalnode is running as process 4820. Stop it first.
server2: journalnode is running as process 5172. Stop it first.
server3: journalnode is running as process 4882. Stop it first.
Starting ZK Failover Controllers on NN hosts [server1 server5]

7.4.6 查看各节点状态

7.5测试故障自动切换
[hadoop@server1 hadoop]$ jps
1431 NameNode
2056 Jps
1739 DFSZKFailoverController
[hadoop@server1 hadoop]$ kill -9 1431
[hadoop@server1 hadoop]$ jps
1739 DFSZKFailoverController
2089 Jps
#杀掉 h1 主机的 namenode 进程后依然可以访问,此时 h2 转为 active 状态接管 namenode
[hadoop@server1 hadoop]$ sbin/hadoop-daemon.sh start namenode
启动 h1 上的 namenode,此时为 standby 状态。
8.yarn 的高可用
8.1配置
[hadoop@server1 hadoop]$ vim hadoop-env.sh
export HADOOP_MAPRED_HOME=/home/hadoop/hadoop
[hadoop@server1 hadoop]$ vim mapred-site.xml
mapreduce.application.classpath</name>
$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
1) 编辑 mapred-site.xml 文件
<!-- 指定 yarn 为 MapReduce 的框架 -->
mapreduce.framework.name</name>
yarn</value>
</property>
</configuration>
2)编辑 yarn-site.xml 文件
<!-- 配置可以在 nodemanager 上运行 mapreduce 程序 -->
yarn.nodemanager.aux-services</name>
mapreduce_shuffle</value>
</property>
<!-- 激活 RM 高可用 -->
yarn.resourcemanager.ha.enabled</name>
true</value>
</property><!-- 指定 RM 的集群 id -->
yarn.resourcemanager.cluster-id</name>
RM_CLUSTER</value>
</property>
<!-- 定义 RM 的节点-->
yarn.resourcemanager.ha.rm-ids</name>
rm1,rm2</value>
</property>
<!-- 指定 RM1 的地址 -->
yarn.resourcemanager.hostname.rm1</name>
172.25.0.1</value>
</property>
<!-- 指定 RM2 的地址 -->
yarn.resourcemanager.hostname.rm2</name>
172.25.0.5</value>
</property>
<!-- 激活 RM 自动恢复 -->
yarn.resourcemanager.recovery.enabled</name>
true</value>
</property>
<!-- 配置 RM 状态信息存储方式,有 MemStore 和 ZKStore-->
yarn.resourcemanager.store.class</name>
org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</
value>
</property>
<!-- 配置为 zookeeper 存储时,指定 zookeeper 集群的地址 -->
yarn.resourcemanager.zk-address</name>
172.25.0.2:2181,172.25.0.3:2181,172.25.0.4:2181</value>
</property>
8.2启动
[hadoop@server1 hadoop]$ pwd ##master端
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ sbin/start-yarn.sh ##启动
Starting resourcemanager
Starting nodemanagers
[hadoop@server1 hadoop]$ jps
8720 ResourceManager ##启动成功
4024 SecondaryNameNode
7069 NameNode
9038 Jps
7423 DFSZKFailoverController
[hadoop@server5 ~]$ yarn --daemon start resourcemanager ##server5这个master端需要手工启动
[hadoop@server5 ~]$ jps
4433 DFSZKFailoverController
4983 ResourceManager
4315 NameNode
5036 Jps
[hadoop@server2 zookeeper-3.4.9]$ jps ##slave端,如果NM起来掉线,可能是内存不足
5172 JournalNode
6004 NodeManager
5271 DataNode
4649 DFSZKFailoverController
6123 Jps
3918 QuorumPeerMain
8.3测试