实用教程丨使用自定义指标进行K8S自动弹性伸缩
Kubernetes自动弹性伸缩可以根据业务流量,自动增加或减少服务。这一功能在实际的业务场景中十分重要。在本文中,我们将了解Kubernetes如何针对应用产生的自定义指标实现自动伸缩。
为什么需要自定义指标?
应用程序的CPU或RAM的消耗并不一定能够正确表明是否需要进行扩展。例如,如果你有一个消息队列consumer,它每秒可以处理500条消息而不会导致崩溃。一旦该consumer的单个实例每秒处理接近500条消息,你可能希望将应用程序扩展到两个实例,以便将负载分布在两个实例上。测量CPU或RAM对于扩展这样的应用程序来说有点矫枉过正了,你需要寻找一个与应用程序性质更为密切相关的指标。一个实例在特定时间点处理的消息数量能更贴切地反映该应用的实际负载。同样,可能有一些应用的其他指标更有意义。这些可以使用Kubernetes中的自定义指标进行定义。
Metrics流水线
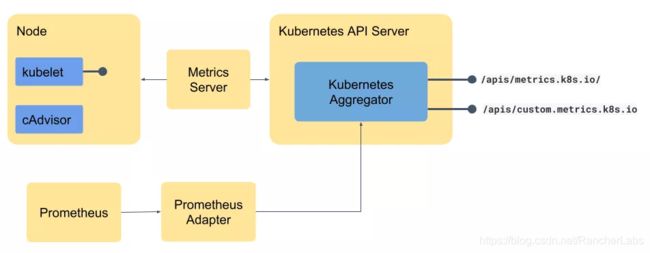
Metrics Server和API
最初,这些指标会通过Heapster暴露给用户,Heapster可以从每个kubelet中查询指标。Kubelet则与localhost上的cAdvisor对话,并检索出节点级和pod级的指标。Metric-server的引入是为了取代heapster,并使用Kubernetes API来暴露指标从而以Kubernetes API的方式提供指标。Metric server仅提供核心的指标,比如pod和节点的内存和CPU,对于其他指标,你需要构建完整的指标流水线。构建流水线和Kubernetes自动伸缩的机制将会保持不变。
Aggregation Layer
能够通过Kubernetes API层暴露指标的关键部分之一是Aggregation Layer。该aggregation layer允许在集群中安装额外的Kubernetes格式的API。这使得API像任何Kubernetes资源一样可用,但API的实际服务可以由外部服务完成,可能是一个部署到集群本身的Pod(如果没有在集群级别完成,你需要启用aggregation layer)。那么,这到底是如何发挥作用的呢?作为用户,用户需要提供API Provider(比如运行API服务的pod),然后使用APIService对象注册相同的API。
让我们以核心指标流水线为例来说明metrics server如何使用 API Aggregation layer注册自己。APIService对象如下:
apiVersion: apiregistration.k8s.io/v1
kind: APIService
metadata:
name: v1beta1.metrics.k8s.io
spec:
service:
name: metrics-server
namespace: kube-system
group: metrics.k8s.io
version: v1beta1
insecureSkipTLSVerify: true
groupPriorityMinimum: 100
versionPriority: 100
部署使用APIService注册API的metrics server之后,我们可以看到Kubernetes API中提供了指标API:

Metrics流水线:核心部分和完整流水线
我们已经了解了基本组件,让我们把它们放在一起组成核心metrics流水线。在核心流水线中,如果你已经恰当地安装了metrics server,它也将创建APIService将自己注册到Kubernetes API server上。正如我们在上一节中所了解到的那样,这些指标将在/apis/metrics.k8s.io中暴露,并被HPA使用。

大部分复杂的应用程序需要更多的指标,而不仅仅是内存和CPU,这也是大多数企业使用监控工具的原因,最常见的监控工具有Prometheus、Datadog以及Sysdig等。而不同的工具所使用的格式也有所区别。在我们可以使用Kubernetes API聚合来暴露endpoint之前,我们需要将指标转换为合适的格式。此时需要使用小型的adapter(适配器)——它可能是监控工具的一部分,也可能作为一个单独的组件,它在监控工具和Kubernetes API之间架起了一座桥梁。例如,Prometheus有专门的Prometheus adapter或者Datadog有Datadog Cluster Agent — 它们位于监控工具和API之间,并从一种格式转换到另一个种格式,如下图所示。这些指标在稍微不同的endpoint都可以使用。
Demo:Kubernetes自动伸缩
我们将演示如何使用自定义指标自动伸缩应用程序,并且借助Prometheus和Prometheus adapter。你可以继续阅读文章,或者直接访问Github repo开始构建demo:
https://github.com/infracloudio/kubernetes-autoscaling
设置Prometheus
为了让适配器可以使用指标,我们将使用Prometheus Operator来安装Prometheus。它创建CRD来在集群中部署Prometheus的组件。CRD是扩展Kubernetes资源的一种方式。使用Operator可以“以Kubernetes的方式”(通过在YAML文件中定义对象)轻松配置和维护Prometheus实例。由Prometheus Operator创建的CRD有:
-
AlertManager
-
ServiceMonitor
-
Prometheus
你可以根据下方链接的指导设置Prometheus:
https://github.com/infracloudio/kubernetes-autoscaling#installing-prometheus-operator-and-prometheus
部署Demo应用程序
为了生成指标,我们将部署一个简单的应用程序mockmetrics,它将在/metrics处生成total_hit_count值。这是一个用Go写的网络服务器。当URL被访问时,指标total_hit_count的值会不断增加。它使用Prometheus所要求的展示格式来显示指标。
根据以下链接来为这一应用程序创建deployment和服务,它同时也为应用程序创建ServiceMonitor和HPA:
https://github.com/infracloudio/kubernetes-autoscaling#deploying-the-mockmetrics-application
ServiceMonitor
ServiceMonitor为Prometheus创建了一个配置。它提到了服务的标签、路径、端口以及应该在什么时候抓取指标的时间间隔。在服务label的帮助下,选择了pods。Prometheus会从所有匹配的Pod中抓取指标。根据你的Prometheus配置,ServiceMonitor应该放在相应的命名空间中。在本例中,它和mockmetrics 在同一个命名空间。
部署和配置Prometheus Adapter
现在要为HPA提供custom.metrics.k8s.io API endpoint,我们将部署Prometheus Adapter。Adapter希望它的配置文件在Pod中可用。我们将创建一个configMap并将其挂载在pod内部。我们还将创建Service和APIService来创建API。APIService将**/api/custom.metrics.k8s.io/v1beta1 endpoint**添加到标准的Kubernetes APIs。你可以根据以下教程来实现这一目标:
https://github.com/infracloudio/kubernetes-autoscaling#deploying-the-custom-metrics-api-server-prometheus-adapter
接下来,我们看一下配置:
- seriesQuery用于查询Prometheus的资源,标签为“default“和”mockmetrics-service“。
- resources部分提到标签如何被映射到Kubernetes资源。针对我们的情况,它将“namespace“标签与Kubernetes的”namespace“进行映射,服务也是如此。
- metricsQuery又是一个Prometheus查询,它可以将指标导入adapter。我们使用的查询是获取2分钟内所有匹配regexmockmetrics-deploy-(.*)的pods的平均total_hit_count总和。
Kubernetes自动伸缩实践
一旦你根据下文中的步骤进行,指标值会不断增加。我们现在就来看HPA:
https://github.com/infracloudio/kubernetes-autoscaling#scaling-the-application
$ kubectl get hpa -w
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
mockmetrics-app-hpa Deployment/mockmetrics-deploy 0/100 1 10 1 11h
mockmetrics-app-hpa Deployment/mockmetrics-deploy 56/100 1 10 1 11h
mockmetrics-app-hpa Deployment/mockmetrics-deploy 110/100 1 10 1 11h
mockmetrics-app-hpa Deployment/mockmetrics-deploy 90/100 1 10 2 11h
mockmetrics-app-hpa Deployment/mockmetrics-deploy 126/100 1 10 2 11h
mockmetrics-app-hpa Deployment/mockmetrics-deploy 306/100 1 10 2 11h
mockmetrics-app-hpa Deployment/mockmetrics-deploy 171/100 1 10 4 11h
你可以看到当该值达到目标值时,副本数如何增加。
工作流程
自动伸缩的整体流程如下图所示:

图片来源: luxas/kubeadm-workshop
结 论
你可以从下方链接中了解更多相关项目和参考资料。在过去的几个版本中,Kubernetes中的监控流水线已经大有发展,而Kubernetes的自动伸缩主要基于该流水线工作。如果你不熟悉这个环境,很容易感到困惑和迷茫。
https://github.com/infracloudio/kubernetes-autoscaling#other-references-and-credits
原文链接:https://dzone.com/articles/kubernetes-autoscaling-with-custom-metrics-updated
About SUSE Rancher
Rancher是一个开源的企业级Kubernetes管理平台,实现了Kubernetes集群在混合云+本地数据中心的集中部署与管理。Rancher一向因操作体验的直观、极简备受用户青睐,被Forrester评为“2020年多云容器开发平台领导厂商”以及“2018年全球容器管理平台领导厂商”,被Gartner评为“2017年全球最酷的云基础设施供应商”。
目前Rancher在全球拥有超过三亿的核心镜像下载量,并拥有包括中国联通、中国平安、中国人寿、上汽集团、三星、施耐德电气、西门子、育碧游戏、LINE、WWK保险集团、澳电讯公司、德国铁路、厦门航空、新东方等全球著名企业在内的共40000家企业客户。
2020年12月,SUSE完成收购RancherLabs,Rancher成为了SUSE “创新无处不在(Innovate Everywhere)”企业愿景的关键组成部分。SUSE和Rancher共同为客户提供了无与伦比的自由和所向披靡的创新能力,通过混合云IT基础架构、云原生转型和IT运维解决方案,简化、现代化并加速企业数字化转型,推动创新无处不在。