pytorch搭建PyQt5界面实战:ResNet-18实现CLFAR-10图像分类,并进行界面显示
pytorch+PyQt5实战:ResNet-18实现CLFAR-10图像分类,并利用PyQt5进行人机界面显示
实验环境:
1.pytorch-1.6.0
2.python-3.7.9
3.window-10
4.pycharm
5.pyqt5(相应的QT Designer及工具包)
CLFAR-10的数据集
作为一个初学者,在官网下载CLFAR-10的数据集下载速度不仅慢,而且不是常用的图片格式,这里是转换后的数据集,有需要的可以直接百度云盘提取。
链接:https://pan.baidu.com/s/1l7wvWLCscPcGoKzRjggjRA
提取码:ht88
ResNet-18网络:
ResNet全名Residual Network残差网络。残差网络是由何凯明所提出的,他的《Deep Residual Learning for Image Recognition》获得了当年CVPR最佳论文。他提出的深度残差网络在2015年可以说是洗刷了图像方面的各大比赛,以绝对优势取得了多个比赛的冠军。而且它在保证网络精度的前提下,将网络的深度达到了152层,后来又进一步加到1000的深度。我们这里用到的是一个18 层的残差网络。
网络结构如下:

残差学习:一个构建单元

在pytorch上搭建ResNet-18模型
一、新建resnet.py文件
代码如下:
import torch.nn as nn
import torch.nn.functional as F
class ResidualBlock(nn.Module):
def __init__(self, inchannel, outchannel, stride=1):
super(ResidualBlock, self).__init__()
self.left = nn.Sequential(
nn.Conv2d(inchannel, outchannel, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(outchannel),
nn.ReLU(inplace=True),
nn.Conv2d(outchannel, outchannel, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(outchannel)
)
self.shortcut = nn.Sequential()
if stride != 1 or inchannel != outchannel:
self.shortcut = nn.Sequential(
nn.Conv2d(inchannel, outchannel, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(outchannel)
)
def forward(self, x):
out = self.left(x)
out += self.shortcut(x)
out = F.relu(out)
return out
class ResNet(nn.Module):
def __init__(self, ResidualBlock, num_classes=10):
super(ResNet, self).__init__()
self.inchannel = 64
self.conv1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(),
)
self.layer1 = self.make_layer(ResidualBlock, 64, 2, stride=1)
self.layer2 = self.make_layer(ResidualBlock, 128, 2, stride=2)
self.layer3 = self.make_layer(ResidualBlock, 256, 2, stride=2)
self.layer4 = self.make_layer(ResidualBlock, 512, 2, stride=2)
self.fc = nn.Linear(512, num_classes)
def make_layer(self, block, channels, num_blocks, stride):
strides = [stride] + [1] * (num_blocks - 1) #strides=[1,1]
layers = []
for stride in strides:
layers.append(block(self.inchannel, channels, stride))
self.inchannel = channels
return nn.Sequential(*layers)
def forward(self, x):
out = self.conv1(x)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = F.avg_pool2d(out, 4)
out = out.view(out.size(0), -1)
out = self.fc(out)
return out
def ResNet18():
return ResNet(ResidualBlock)
一开始没看懂下面代码的意思,后来看懂模型结构发现是真香,大家细品。
self.shortcut = nn.Sequential()
if stride != 1 or inchannel != outchannel:
self.shortcut = nn.Sequential(
nn.Conv2d(inchannel, outchannel, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(outchannel)
)二、新建train.py文件
代码如下:
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import argparse
from resnet import ResNet18
# 定义是否使用GPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 参数设置,使得我们能够手动输入命令行参数,就是让风格变得和Linux命令行差不多
parser = argparse.ArgumentParser(description='PyTorch CIFAR10 Training')
parser.add_argument('--outf', default='./model/', help='folder to output images and model checkpoints') #输出结果保存路径
parser.add_argument('--net', default='./model/Resnet18.pth', help="path to net (to continue training)") #恢复训练时的模型路径
args = parser.parse_args()
# 超参数设置
EPOCH = 200 #遍历数据集次数
pre_epoch = 0 # 定义已经遍历数据集的次数
BATCH_SIZE = 128 #批处理尺寸(batch_size)
LR = 0.001 #学习率
# 准备数据集并预处理
transform_train = transforms.Compose([
transforms.RandomCrop(32, padding=4), #先四周填充0,在吧图像随机裁剪成32*32
transforms.RandomHorizontalFlip(), #图像一半的概率翻转,一半的概率不翻转
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)), #R,G,B每层的归一化用到的均值和方差
])
transform_test = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
trainset = torchvision.datasets.ImageFolder(root='E:\\CLFAR-10+pyqt5\\data\\train', transform=transform_train) #训练数据集
trainloader = torch.utils.data.DataLoader(trainset, batch_size=BATCH_SIZE, shuffle=True, num_workers=2) #生成一个个batch进行批训练,组成batch的时候顺序打乱取
testset = torchvision.datasets.ImageFolder(root='E:\\CLFAR-10+pyqt5\\data\\test', transform=transform_test)
testloader = torch.utils.data.DataLoader(testset, batch_size=100, shuffle=True, num_workers=2)
# Cifar-10的标签
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
# 模型定义-ResNet
net = ResNet18().to(device)
# 定义损失函数和优化方式
criterion = nn.CrossEntropyLoss() #损失函数为交叉熵,多用于多分类问题
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9, weight_decay=5e-4) #优化方式为mini-batch momentum-SGD,并采用L2正则化(权重衰减)
# 训练
if __name__ == "__main__":
best_acc = 85 #2 初始化best test accuracy
print("Start Training, Resnet-18!") # 定义遍历数据集的次数
with open("acc.txt", "w") as f:
with open("log.txt", "w")as f2:
for epoch in range(pre_epoch, EPOCH):
print('\nEpoch: %d' % (epoch + 1))
net.train()
sum_loss = 0.0
correct = 0.0
total = 0.0
for i, data in enumerate(trainloader, 0):
# 准备数据
length = len(trainloader)
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device)
optimizer.zero_grad()
# forward + backward
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 每训练1个batch打印一次loss和准确率
sum_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += predicted.eq(labels.data).cpu().sum()
print('[epoch:%d, iter:%d] Loss: %.03f | Acc: %.3f%% '
% (epoch + 1, (i + 1 + epoch * length), sum_loss / (i + 1), 100. * correct / total))
f2.write('%03d %05d |Loss: %.03f | Acc: %.3f%% '
% (epoch + 1, (i + 1 + epoch * length), sum_loss / (i + 1), 100. * correct / total))
f2.write('\n')
f2.flush()
# 每训练完一个epoch测试一下准确率
print("Waiting Test!")
with torch.no_grad():
correct = 0
total = 0
for data in testloader:
net.eval()
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = net(images)
# 取得分最高的那个类 (outputs.data的索引号)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# result = torch.floor_divide(correct, total)
# print('测试分类准确率为:%.3f%%' % (100 * result))
acc = 100 * correct / total
print('测试分类准确率为:%.3f%%' % (acc))
# 将每次测试结果实时写入acc.txt文件中
print('Saving model......')
torch.save(net.state_dict(), '%s/net_%03d.pth' % (args.outf, epoch + 1))
f.write("EPOCH=%03d,Accuracy= %.3f%%" % (epoch + 1, acc))
f.write('\n')
f.flush()
# 记录最佳测试分类准确率并写入best_acc.txt文件中
if acc > best_acc:
f3 = open("best_acc.txt", "w")
f3.write("EPOCH=%d,best_acc= %.3f%%" % (epoch + 1, acc))
f3.close()
best_acc = acc
print("Training Finished, TotalEPOCH=%d" % EPOCH)
将训练过程记录在 log.txt中,将每个epoch的测试精度放在acc.txt中,最后通过if语句将最高精度记录在best_acc.txt中,best_acc.txt中保存的是最高测试准确率所对应的epoch。每次epoch的权重保存在model文件夹下

三、新建predict文件
为了让模型和PyQt5结合,写个预测脚本方便GUI文件调用
代码如下:
import torch
import torchvision.transforms as transforms
from resnet import ResNet18
from PIL import Image
def predict_(img):
data_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)),
])
#img =Image.open('E:\CLFAR-10+pyqt5\4.jpg')
img = data_transform(img)
img = torch.unsqueeze(img, dim=0)
model = ResNet18()
model_weight_pth = 'E:\\CLFAR-10+pyqt5\\model\\net_200.pth'
model.load_state_dict(torch.load(model_weight_pth))
model.eval()
classes = {
'0': '飞机', '1': '汽车', '2': '鸟', '3': '猫', '4': '鹿', '5': '狗', '6': '青蛙', '7': '马', '8': '船', '9': '卡车'}
with torch.no_grad():
output = torch.squeeze(model(img))
print(output)
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
return classes[str(predict_cla)], predict[predict_cla].item()
在上述训练过程完成后,通过查看best_acc.txt查看测试精度最好的一次所对应的epoch,在预测脚本中使用精度最高的epoch所对应的权重
model_weight_pth = 'E:\\CLFAR-10+pyqt5\\model\\net_200.pth'
model.load_state_dict(torch.load(model_weight_pth))
接下来测试一下预测代码:
打印一下output
img = Image.open('E:\\CLFAR-10+pyqt5\data\\test\\bird\\25.jpg')
net = predict_(img)
print(net)
结果:
tensor([ 1.2775, -3.7718, 6.0837, -0.4484, -4.9533, 3.0170, -4.3821, 3.7511,
1.8174, -2.6302])
('鸟', 0.8564958572387695)
tensor([19.7340, -4.3800, -3.0140, -3.5426, -2.8213, -2.6680, -3.8995, -4.8666,
4.2137, 0.3724])
Process finished with exit code 0
预测正确!
四、新建GUI.py文件
这里就是建立界面了,代码如下:
from PyQt5.QtWidgets import (QWidget,QLCDNumber,QSlider,QMainWindow,
QGridLayout,QApplication,QPushButton, QLabel, QLineEdit)
from PyQt5.QtGui import *
from PyQt5.QtCore import *
from PyQt5.QtWidgets import *
import sys
from PyQt5.QtCore import Qt
from predict import predict_
from PIL import Image
class Ui_example(QWidget):
def __init__(self):
super().__init__()
self.layout = QGridLayout(self)
self.label_image = QLabel(self)
self.label_predict_result = QLabel('识别结果',self)
self.label_predict_result_display = QLabel(self)
self.label_predict_acc = QLabel('识别准确率',self)
self.label_predict_acc_display = QLabel(self)
self.button_search_image = QPushButton('选择图片',self)
self.button_run = QPushButton('运行',self)
self.setLayout(self.layout)
self.initUi()
def initUi(self):
self.layout.addWidget(self.label_image,1,1,3,2)
self.layout.addWidget(self.button_search_image,1,3,1,2)
self.layout.addWidget(self.button_run,3,3,1,2)
self.layout.addWidget(self.label_predict_result,4,3,1,1)
self.layout.addWidget(self.label_predict_result_display,4,4,1,1)
self.layout.addWidget(self.label_predict_acc,5,3,1,1)
self.layout.addWidget(self.label_predict_acc_display,5,4,1,1)
self.button_search_image.clicked.connect(self.openimage)
self.button_run.clicked.connect(self.run)
self.setGeometry(300,300,300,300)
self.setWindowTitle('CLFAR-10十分类')
self.show()
def openimage(self):
global fname
imgName, imgType = QFileDialog.getOpenFileName(self, "选择图片", "", "*.jpg;;*.png;;All Files(*)")
jpg = QPixmap(imgName).scaled(self.label_image.width(), self.label_image.height())
self.label_image.setPixmap(jpg)
fname = imgName
def run(self):
global fname
file_name = str(fname)
img = Image.open(file_name)
a, b = predict_(img)
self.label_predict_result_display.setText(a)
self.label_predict_acc_display.setText(str(b))
if __name__ == '__main__':
app = QApplication(sys.argv)
ex = Ui_example()
sys.exit(app.exec_())结果演示

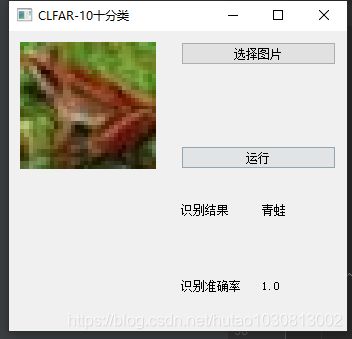
遇到的问题
我学习中遇到的一些问题,通过百度和博客解决了。
1》nn.Sequential(*layers)为什么需要加一个星号?
答:如果星号加在了是实参上,代表的是将输入迭代器拆成一个个元素。
2》net.train()和net.eval()区别?
答:使用PyTorch进行训练和测试时一定注意要把实例化的模型指定train/eval,eval()时,框架会自动把BN和DropOut固定住,不会取平均,而是用训练好的值,不然的话,一旦test的batch_size过小,很容易就会被BN层导致生成图片颜色失真极大。原因就是对于BN层来说,它在训练过程中,是对每一个batch去一个样本均值和方差,然后使用滑动指数平均所有的batch的均值和方差来近似整个样本的均值和方差。对于测试阶段,我们固定我们样本和方差,bn相当于一个线性的映射关系。所以说对于pytorch来说,在训练阶段我们net.train相当于打开滑动指数平均按钮,不断的更新;测试阶段我们关闭它,相当于一个线性映射关系。
3》correct += predicted.eq(labels.data).cpu().sum()是什么意思?
答:correct += predicted.eq(labels.data).cpu().sum()其实和correct += (predicted == labels).sum().item()是一个意思,.item()返回的是一个具体值,而.data返回的是一个tensor,要注意item()不能丢,不然返回的是tensor,而tensor不能相加。
如果对大家的学习有所帮助,希望大家帮我点个赞,让我觉得我的分享是有价值的,也欢迎大家和我交流
加了一个打包成可执行文件的过程
用pyinstaller将上述过程打包成exe的可执行文件
总结和引用
这篇文章大概算是我两个月来初学pytorch的总结,后面大概要去看tensorflow了。
参考文章:
1.Pytorch实战2:ResNet-18实现Cifar-10图像分类(测试集分类准确率95.170%)
2.PYQT5+Pytorch的猫狗分类(从数据集制作->网络模型搭建和训练->界面演示)