我们知道线性回归一般都用来解决回归类问题,例如房价预测,气温预测等。实际上,加上 Softmax 这样的技术,我们还可以使用线性回归来解决多分类问题。Softmax 是对网络结构中输出层的改造,其示意图如下:

Softmax 技术细节
上图中,x1、x2 和 x3 是输入层,它们分别通过两个线性回归模型来产生 y1 和 y2:
接着,把 y1 和 y2 输入到 Softmax 模块中,输出 y1' 和 y2',经过 Softmax 处理后的结果,是一个离散概率分布,即 y1' + y2' = 1。于是,我们可以用 y1' 和 y2' 来表示不同分类的预测概率。
Softmax 具体细节如下图所示:
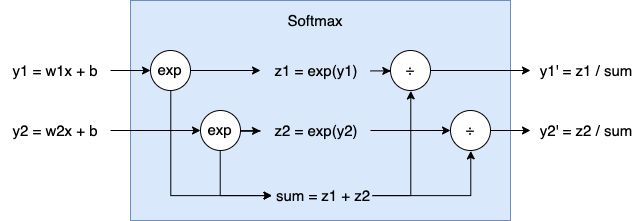
- 首先把输出结果做 e 的次方处理,得到 ,
- 将第 1 步的结果相加:sum = z1 + z2
- 最后,将第 1 步的结果除以 sum,得到 ,
因为对结果做了 e 的次方的处理,所以 Softmax 会强化较大的数——致使较大的结果的概率更大,这也是 Softmax 为什么要叫 Softmax,而不叫 max 的原因。
Softmax 分类的损失函数
Softmax 分类采用交叉熵(Cross Entropy)损失函数,仔细观察,交叉熵损失函数其实就是 Log Likelihood(见深入理解逻辑回归一文),它们的目标都是为了让正确分类的预测值最大化。

上图中,y1',y2' 和 y3' 为不同分类的预测概率,它是 Softmax 的输出结果;y1,y2 和 y3 是真实分类数据,在分类任务中,这三个数只有一个是 1,另外两个都是 0,所以 y1,y2 和 y3 也是一个概率分布。
那么我们的机器学习任务就变成了:让预测概率分布 不断接近真实概率分布 的优化问题。我们用交叉熵(cross entropy)来衡量两个概率分布的差异,交叉熵越小,这两个分布越接近,交叉熵的表示如下:
上式中,q 表示有 q 个分类, 为第 j 个分类的概率。把所有样本的交叉熵加起来,就是我们要的损失函数:
刚才说了,交叉熵又等效于 Log Likelihood,你可以从 Log Likelihood 的角度来理解它。除此之外,你还可以从信息论的角度来理解:
在信息论中,熵 用来描述系统中所蕴含的信息量的期望,其中 是自信息,表示概率为 的事件发生时所产生的信息量,自信息可以理解为,小概率事件会产生较大的信息量,相反,大概率事件产生的信息量较小。
而交叉熵 描述的是:要消除系统中的信息,需要付出的努力,且当分布 和 相等时,所付出的努力最小—— 达到最小值,机器学习使用交叉熵作为损失函数也正是因为这一点。
更详尽的解释可以参考这篇文章。
从零实现 Softmax
现在我们用 TF2.0 来从零实现 Softmax,步骤如下:
- 定义 Softmax 多分类模型
- 定义损失函数
- 训练,评估模型
定义 Softmax 多分类模型
线性回归的 Softmax 模型主要做两件事情:
一、将输入数据矩阵与参数矩阵做矩阵乘法,输入数据的行数为样本数 n,每行中的内容为每条样本的特征,设特征数为 d,则输入数据的形状为 n*d,一次训练多条数据,以此达到批量计算的目的;参数矩阵的维度为 d*q,d 依然为特征数,q 表示分类数,这样乘出来的结果为 n*q,意为这 n 条样本的每条样本在不同分类上的输出;
二、将第一步的结果做 Softmax 处理,得到每条样本的在不同分类上的预测结果。
def net(X):
'''
一层线性回归网络,输出 softmax 后的多分类结果
Args:
- X: n 条样本,每条样本有 d 个维度,即 n*d 维矩阵
- W: 全局参数,d*q 维矩阵,q 表示分类数
- b: bias,1*q 维向量
Return:
- softmax 后的多分类结果
'''
return softmax(tf.matmul(X, W) + b)
def softmax(y):
'''
对 n 个样本,每个样本有 q 种分类的数据做softmax
Args:
- y: n*q 维的矩阵
Return:
- n*q 维的 softmax 后的矩阵
Example:
>>> y = np.array([[0.1,0.2,0.8],[0.8,0.2,0.1]])
>>> softmax(y)
'''
return tf.exp(y) / tf.reduce_sum(tf.exp(y), axis=1, keepdims=True)
定义损失函数
观察交叉熵损失函数的公式,要实现它,就要先拿到正确分类对应的预测概率:
这里先用 one-hot 编码将目标向量转化为和预测结果一样的矩阵形式,如预测结果为 n*q 的矩阵(n 表示一次预测 n 条样本,q 表示分类数),那么 one-hot 编码会将目标向量也转化为 n*q 的矩阵;
接着再对预测矩阵和目标矩阵做一个“与操作” boolean_mask 就可以把正确分类对应的预测值取出来了;
最后对预测值求 -log ,再求和,就是这批样本的 Loss,代码如下:
def cross_entropy(y, y_hat):
'''
交叉熵损失函数
Args:
- y: n 条样本的目标值,n*1 向量
- y_hat: n 条样本的预测分布(softmax输出结果), n*q 矩阵
Return:
n 个样本的 -log(y_hat) 的和
Examples:
>>> y = np.array([[2],[1]])
>>> y_hat = np.array([[0.1,0.2,0.2],[0.3,0.9,0.2]])
>>> cross_entropy(y, y_hat)
'''
y_obs = tf.one_hot(y, depth=y_hat.shape[-1])
y_obs = tf.reshape(y_obs, y_hat.shape)
y_hat = tf.boolean_mask(y_hat, y_obs)
return tf.reduce_sum(-tf.math.log(y_hat))
评估模型
这次我们使用准确率(accuracy)来评估模型的效果,准确率意为预测正确数的占比。
评估模型时,要先对数据进行预测,再拿预测结果(概率值最大的分类)和正确分类做对比,以此统计正确的预测次数。这里使用的 tf.argmax 函数,表示在多个预测分类中,取最大的那个值作为预测结果:
def accuracy(x, y, num_inputs, batch_size):
'''
求数据集的准确率
Args:
- x: 数据集的特征
- y: 数据集的目标值,n*1 维矩阵
- num_inputs: 特征维度(输入层个数)
- batch_size: 每次预测的批次
'''
test_iter = tf.data.Dataset.from_tensor_slices((x, y)).batch(batch_size)
acc, n = 0, 0
for X, y in test_iter:
X = tf.reshape(X, (-1, num_inputs))
y = tf.cast(y, dtype=tf.int64)
acc += np.sum(tf.argmax(net(X), axis=1) == y)
n += y.shape[0]
return acc/n
训练
以上为模型训练、预测和评估所需要的通用方法,接下来我们就可以来训练模型了,本次我们使用的是 fashion_mnist 数据集,其中每个样本为一张 28*28 像素的图片,目标值 label 为这张图片所属的类别编号,数据集中一共有 10 个类别,如下所示:

我们的任务是,读到一张这样的图片,能预测其所属的分类。模型的输入可以是图片的每个像素值,因为有 28*28=784 个像素,每个像素的取值范围为 0-255,那么我们模型的输入层的节点个数便是 784;因为数据集总共只有 10 个分类,则模型的参数 W 的形状为 784*10 维矩阵,bias 的形状为 10*1,同时输出层的节点数也为 10 个。
把参数弄清楚后,剩下的就是模型迭代了,这一部分和上一篇线性回归中的训练代码大致一样,代码如下:
import tensorflow as tf
from tensorflow import keras
import numpy as np
import time
import sys
from tensorflow.keras.datasets import fashion_mnist
def train(W, b, lr, num_inputs):
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
# 数据归一化
x_train = tf.cast(x_train, tf.float32) / 255
x_test = tf.cast(x_test, tf.float32) / 255
batch_size = 256
num_epochs = 5
for i in range(num_epochs):
# 小批量迭代
train_iter = tf.data.Dataset.from_tensor_slices((x_train, y_train)).batch(batch_size)
train_acc_sum, loss_sum, n = 0, 0, 0
for X, y in train_iter:
X = tf.reshape(X, (-1, num_inputs))
y = tf.reshape(y, (-1, 1))
# 计算loss和梯度
with tf.GradientTape() as tape:
l = cross_entropy(y, net(X))
grads = tape.gradient(l, [W, b])
# 根据梯度调整参数
W.assign_sub(lr * grads[0])
b.assign_sub(lr * grads[1])
loss_sum += l.numpy() # 累加loss
n += y.shape[0] #累加训练样本个数
print("epoch %s, loss %s, train accuracy %s, test accuracy %s"
% (i+1, loss_sum/n,
accuracy(x_train, y_train, num_inputs, batch_size),
accuracy(x_test, y_test, num_inputs, batch_size)))
num_inputs = 784
num_outputs = 10
lr = 0.001
# 初始化模型参数
W = tf.Variable(tf.random.normal(shape=(num_inputs, num_outputs),
mean=0, stddev=0.01, dtype=tf.float32))
b = tf.Variable(tf.zeros(num_outputs, dtype=tf.float32))
train(W, b, lr, num_inputs)
下面是该训练的输出,可见使用线性回归这样简单的模型,也可以把 fashion_mnist 图片分类任务做到 0.85 的准确率。
epoch 1, loss 0.8956155544281006, train accuracy 0.82518, test accuracy 0.8144
epoch 2, loss 0.6048591234842936, train accuracy 0.83978, test accuracy 0.8272
epoch 3, loss 0.5516327695210774, train accuracy 0.84506, test accuracy 0.8306
epoch 4, loss 0.5295544961929322, train accuracy 0.84906, test accuracy 0.8343
epoch 5, loss 0.5141636388142904, train accuracy 0.85125, test accuracy 0.8348
简单的实现
照例,我们还要看下 Softmax 的简单实现版本:
# 加载数据集
(x_train, y_train), (x_test, y_test) = fashion_mnist.load_data()
x_train = x_train / 255
x_test = x_test / 255
# 配置模型
model = keras.Sequential([
keras.layers.Flatten(input_shape=(28, 28)), # 输入层
keras.layers.Dense(10, activation=tf.nn.softmax) # 输出层,激活函数使用的是 softmax
])
# 配置交叉熵损失函数
loss = 'sparse_categorical_crossentropy'
# 配置 SGD,学习率为 0.1
optimizer = tf.keras.optimizers.SGD(0.1)
model.compile(optimizer=optimizer,
loss = loss,
metrics=['accuracy']) # 使用准确率来评估模型
model.fit(x_train, y_train, epochs=5, batch_size=256)
依然是只需要配置,不用你写一行逻辑代码。
小结
本文我们一起学习了使用线性回归和 Softmax 来实现一个多分类模型,并实际的使用 fashion_mnist 数据集做了实验,得到了 0.85 一个还不赖的准确率结果,在本文中,有两点细节需要掌握
- Softmax 实现细节
- 交叉熵损失函数的原理
参考:
- 动手深度学习-softmax回归 (zh.gluon.ai/)
- 动手深度学习TF2.0版本-softmax回归
- 如何理解交叉熵和相对熵
相关文章:
- 深度理解逻辑回归算法
- 用TF2.0实现线性回归