ResNet网络(Deep Residual Learning for Image Recognition)总结
论文地址:https://arxiv.org/pdf/1512.03385.pdf
Github代码地址:https://github.com/KaimingHe/deep-residual-networks
1、文章概述
这篇文章是2015年的文章,主要解决的问题是如何将网络变得更深的同时,保证准确率不会下降。因为已经达成了一个共识:网络深度越深,提取到的特征越好。作者在Abstract中也提到,在CoCo数据集上有28%的效果提升,对比后来的检测算法在数据集上的mAP值的提升只有1%到2%,这个提升相当恐怖。在后面的研究中,ResNet已经有了很多的变式,而且很多网络的基础部分(或者特征提取部分)都是拿的ResNet做的,这篇文章的影响力是真的强。
后面的研究中用到的Resnet版本基本上是Resnet-101版本,101代表ResNet网络的层的数目;此外考虑到实验室的服务器性能,即内存大小,也有ResNet-50版本可以实现。
2、ResNet提出的背景及要解决的问题
自VGG提出开始,将网络变深几乎成了后面研究者的一致思路。随着网络层数的增加,“梯度消失/爆炸”问题出现,导致训练难以收敛,BN等一系列归一化手段很好地解决了这个问题,但有一点问题暴露出来,即“degradation”,退化问题。退化问题是:随着网络深度的增加,准确率达到饱和,然后迅速降低,并且在一个合理的深层模型中增加更多的层会带来更高的错误率。作者在文中指出退化问题不是由于过拟合导致的。
作者在文中指出,有一种方法可以解决上述问题:恒等映射(identity mapping)来构建层。恒等映射即f(x)=x,即输入x经过若干的非线性层后的输出依然是x。在这个背景下作者提出了将普通网络改为残差网络,来了令网络层去拟合恒等映射。
作者令H(x)为想要获得的映射,F(x)为多个非线性层能够逼近的复杂函数。依据上面的思路,H(x)=x是最好的,文中3.1部分第三段“If the optimal function is closer to an identity mapping than to a zero mapping, it should be easier for the solver to find the perturbations with reference to an identity mapping, than to learn the function as a new one”。;另一篇文章作者也证明了identity mapping是最好的,具体哪篇记不清了...因此全文都是在short connections是identity mapping(恒等映射)的前提下进行的。但是求解器在多个非线性层来模拟逼近identity mapping是很困难的,因此作者提出Resnet结构单元去更容易地通过非线性层逼近identity mappings。
3、Resnet结构单元的实现
作者换了一个思路,非线性层逼近identity mapping困难,就让非线性层逼近0。在第二页的第一段“To the extreme, if an identity mapping were optimal, it would be easier to push the residual to zero than to fit an identity mapping by a stack of nonlinear layers”。因此令 H(x) = F(x)+x,通过非线性层逼近的F(x)让其逼近为0,来达到 H(x)=x的目的。而且深层网络在迭代时权重最终都很接近于0,通过激活函数w*x后输出也接近0,这点与令 F(x)逼近0温和,可以说很合理,结构单元如下图所示:
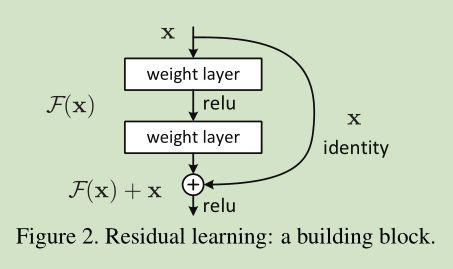
这里为了要求输入和输出的维度相同(即feature map 的channels数相同),引入了一个Ws权重矩阵,具体如下(摘自知乎:https://zhuanlan.zhihu.com/p/27082562):

Ws的处理方式有两种,其中第二个是用1*1卷积去匹配维度,其中1*1卷积核的个数就是最终想要得到的feature map的channels数。1*1卷积在后面很多算法里都起到了降维和维度匹配的作用。
4、将VGG改为Resnet版本
文中所谓的Plain Network,就是在VGG的基础上,遵循下面两条规则改进的:
(1)特征图大小一样的层有一样多数目的滤波器个数;
(2)特征图数目减半,则滤波器的个数翻倍,在交替之间的地方设置这样的层。
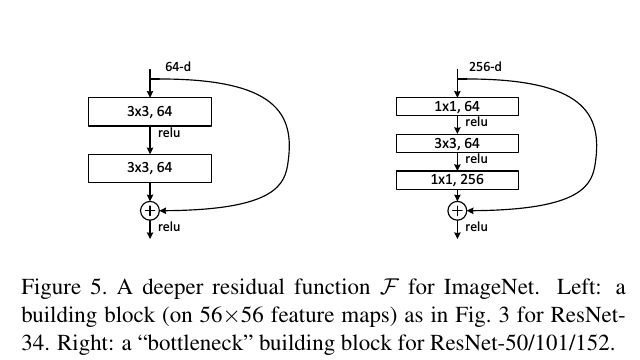
此外,Plain Network将VGG前面3个3*3卷积层用1个7*7的卷积层替代,且相同特征图大小的情况下,增加了3到4个相同的卷积层,由原来的19层增加到34层。Resnet-34则是每两个3*3卷积层构成一组“多层非线性层”,shortcut conncetions也是隔两个3*3卷积层才来一个的。ImageNet测试集上具体的残差模块如下图所示:
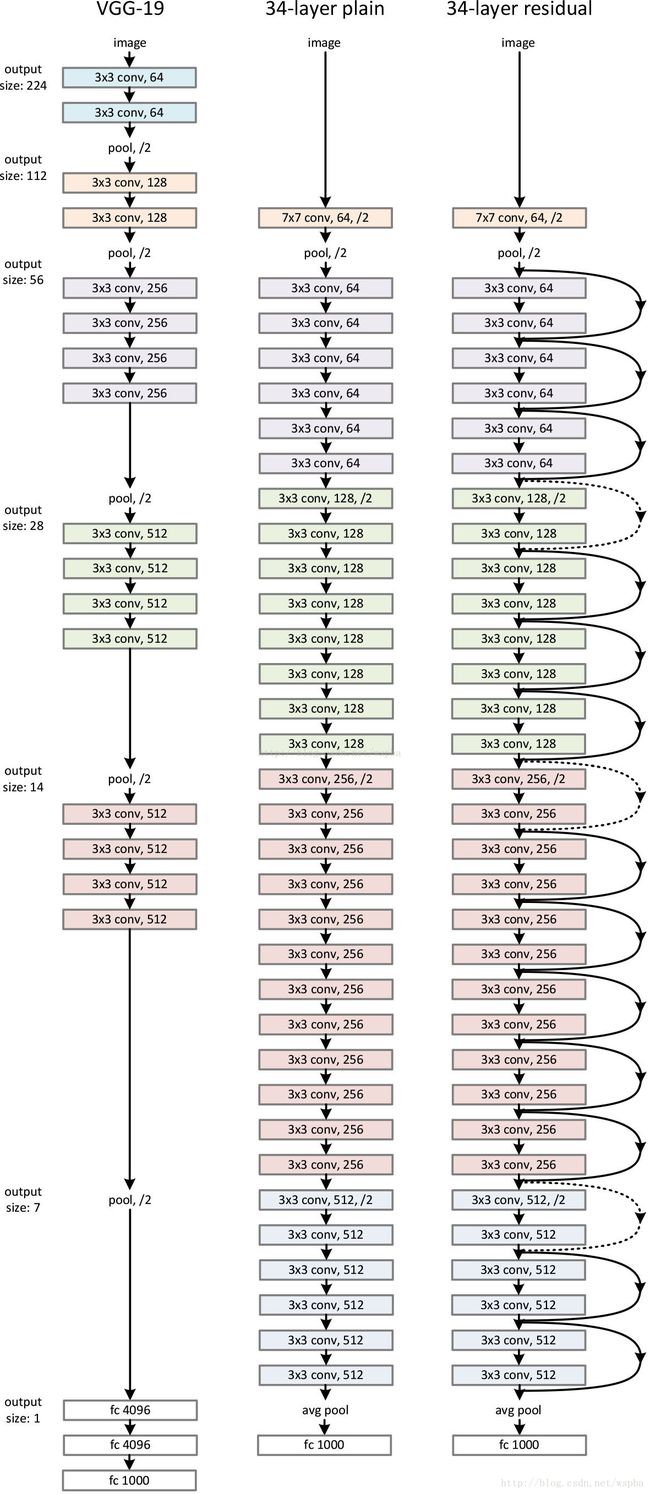
以34层为例的Resnet,与VGG的34层加强版的网络结构对比如下图:
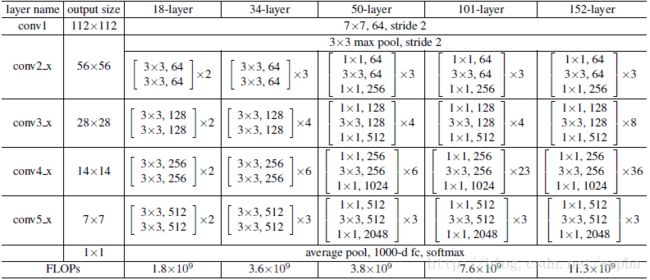
针对Resnet不同的层数,又提出了Resnet-18,Resnet-34,Resnet-50,Resnet-101,Resnet-152,其中数字代表Resnet网络的层数。理论研究中用的最多的是Resnet-101,但是50版本也是可以跑的(我们实验室11G的内存也就带的动50的,101想都不要想)。具体每个版本的结构如下图:
具体的实验结果分析和实现时的tricks请参见原文,这里只是讲一下网络结构。
参考博客:
https://zhuanlan.zhihu.com/p/27082562(这篇知乎的文章在残差模块的提出背景和原理解析部分很详细)