Spark作业性能调优总结
前段时间在集群上运行Spark作业,但是发现作业运行到某个stage之后就卡住了,之后也不再有日志输出。于是开始着手对作业进行调优,下面是遇到的问题和解决过程:
运行时错误
Out Of Memory: Java heap space / GC overhead limit exceeded
使用yarn logs -applicationId=appliation_xxx_xxx 命令查看Yarn收集的各个Executor的日志。
可以发现OOM的错误,以及一些retry 或waiting timeout的错误。这是因为发生Full GC时会造成stop-the-world,应用暂停运行等待垃圾回收结束。
Java heap space是指堆内存空间不足,而GC overhead limit exeeded是Hotspot VM 1.6的一个策略,通过统计GC时间来预测是否要OOM了,提前抛出异常,防止OOM发生。Sun官方给出的定义是“并行/并发回收器在GC回收时间过长会抛出OutOfMemory。过长的定义是,超过98%的时间用来做GC并且回收了不到2%的堆内存,用来避免内存过小造成应用不能正常工作”。这个策略会保存数据或保存现场(Heap Dump)
在代码设置Spark参数,将executor的堆栈信息打印出来
conf.set("spark.executor.extraJavaOptions", "-XX:+PrintGCDetails -XX:+PrintGCTimeStamps")
在运行后的日志中可以发现如下内容:
33.125: [GC DefNew: 16000K->16000K(16192K), 0.0000574 secs 18973K->2704K(32576K), 0.1015066 secs]100.667:[Full GC [Tenured: 0K->210K(10240K), 0.0149142 secs] 4603K->210K(19456K), [Perm : 2999K->2999K(21248K)], 0.0150007 secs]
实际上还有total的汇总信息,如下所示:
Heap PSYoungGen total 5496832K, used 5357511K [0x00000006aaa80000, 0x0000000800000000, 0x0000000800000000)
eden space 5402624K, 97% used [0x00000006aaa80000,0x00000007ebe75800,0x00000007f4680000)
from space 94208K, 99% used [0x00000007f4680000,0x00000007fa27c530,0x00000007fa280000) to space 95744K, 0% used [0x00000007fa280000,0x00000007fa280000,0x0000000800000000)
ParOldGen total 11185152K, used 781938K [0x00000003fff80000, 0x00000006aaa80000, 0x00000006aaa80000)
PSPermGen total 1048576K, used 58663K [0x00000003bff80000, 0x00000003fff80000, 0x00000003fff80000)
object space 1048576K, 5% used [0x00000003bff80000,0x00000003c38c9d60,0x00000003fff80000)
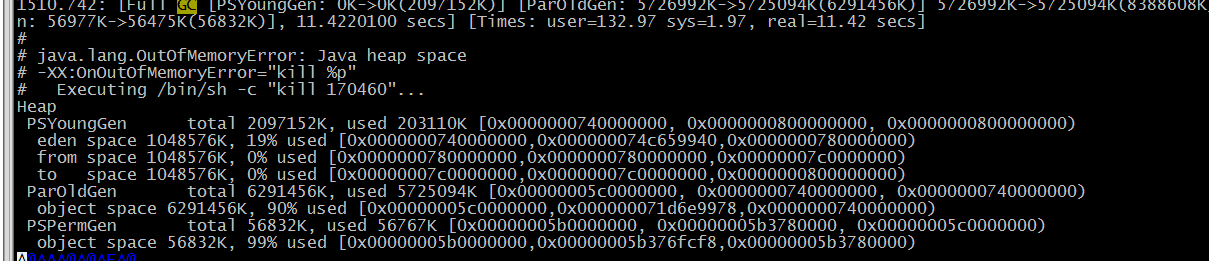
作业卡住的时候,PSPermGen的使用占比一般在99%左右,因此我在Spark程序中增大了堆外内存
conf.set("spark.executor.extraJavaOptions", "-XX:PermSize=1024m -XX:MaxPermSize=2048m -XX:+PrintGCDetails -XX:+PrintGCTimeStamps")
这里GC和Full GC代表gc停顿的类型,Full GC代表stop-the-world。箭头两边是gc前后的区间空间大小,分别是young区、tenured区和perm区,括号里是该区的大小。冒号前面是GC发生的时间,单位是秒,从jvm启动开始计算。DefNew代表Serial收集器,为Default New Generation的缩写,类似的还有PSYoundGen,代表parallel Scavenge收集器。这样可以通过分析日志找到导致GC overhead limit execeeded的原因, 通过调节相应的参数解决问题。
文中涉及到的名词解释:
Eden Space:堆内存池,大多数对象在这里分配内存空间
Survivor Space:堆内存池,存储在Eden Space中存活下来的对象
Tenured Generation:堆内存,存储Survivor Space中存过几次GC的对象
Permanent Generation:非对空间,存储的是class和method对象
Code Cache:非堆空间,JVM用来存储编译和存储native code
Executor & Task Lost
executor lost
WARN TaskSetManager: Lost task 1.0 in stage 0.0 (TID 1, aa.local):ExecutorLostFailure (executor lost)
task lost
WARN TaskSetManager: Lost task 69.2 in stage 7.0 (TID 1145, 192.168.47.217):java.io.IOException: Connection from /192.168.47.217:55483 closed
各种timeout
java.util.concurrent.TimeoutException: Futures timed out after [120 second]ERROR TransportChannelHandler: Connection to /192.168.47.212:35409 has been quiet for 120000 ms while there are outstanding requests.Assuming connection is dead; please adjust spark.network.timeout if this is wrong
解决:由网络或者GC引起,worker或者executor没有接收到executor或task的心跳反馈,提高spark.core.connection.ack.wait.timeout
的值,根据情况改为300s或更高。增大spark.yarn.executor.memoryOverhead
堆外内存的值,根据情况改为4096或更高。
倾斜
数据倾斜

任务倾斜
差距不大的几个task,有的运行速度特别慢
解决:大多数任务都完成了,还有一两个任务怎们都跑不完或者跑的很慢,分数据倾斜和任务倾斜
数据倾斜:
数据倾斜大多数情况是由于大量的无效数据引起,比如null或者“ ”,也有可能是一些异常数据,,比如统计用户登录情况时,出现某用户登录过千万次的情况,无效数据在计算前需要过滤掉。 数据处理有一个原则,多使用filter,这样你真正需要分析的数据量就越少,处理速度就越快。
具体可参见解决spark中遇到的数据倾斜问题
任务倾斜
task倾斜原因比较多,网络io,cpu,mem都有可能造成这个节点上的任务执行缓慢,可以去看该节点的性能监控过来分析原因。以前遇到过同事在spark的一台worker上跑R的任务导致该节点spark task运行缓慢。 或者可以开启spark的推测机制,开启推测机制后如果某一台机器的几个task特别慢,推测机制会将任务分配到其他机器执行,最后Spark会选取最快的作为最终结果。
spark.speculation true
spark.speculation.interval 100 - 检测周期,单位毫秒;
spark.speculation.quantile 0.75 - 完成task的百分比时启动推测
spark.speculation.multiplier 1.5 - 比其他的慢多少倍时启动推测。
OOM解决: 内存不够,数据太多就会抛出OOM的Exception,主要有Driver OOm和Executor OOM两种
Driver OOM
一般是使用了collect操作将所有executor的数据聚合到dirver端导致,尽量不要使用collect操作即可
Executor OOM
可以按下面的内存优化的方法增加code使用内存空间
增加executor内存总量,也就是说增加spark.executor.memory
的值
增加任务并行度(大任务就被分割成小任务了),参考下面优化并行度的方法
一些优化
部分Executor不执行任务
有时候会发现部分executor并没有执行任务,为什么呢?
任务partition数量过少
每个partition只会在一个task执行任务。改变分区数,可以通过repartition方法,即使这样,在repartition前面还是要从数据源读取数据,此时(读入数据)的并发度根据不同的数据源受到不同限制,常用的大概有以下几种:
hdfs - block数就是partition数mysql - 按读入时的分区规则分partitiones - 分区数即为 es 的 分片数(shard)
数据本地行的副作用
taskManager在分发任务之前会优先计算数据本地行,优先等级是:
process(同一个executor) -> node_local(同一个节点) -> rack_local(同一个机架) -> any(任何结点)
Spark会优先执行高优先级的任务, 任务完成的速度很快(小于设置的spark.locality.wait时间),则数据本地性下一级别的任务则一直不会启动,这就是Spark的延时调度机制。
举个极端例子:运行一个count任务,如果数据全都堆积在某一台节点上,那将只会有这台机器在长期计算任务,集群中的其他机器则会处于等待状态(等待本地性降级)而不执行任务,造成了大量的资源浪费。
判断的公式为:curTime – lastLaunchTime >= localityWaits(currentLocalityIndex)
其中 curTime
为系统当前时间,lastLaunchTime
为在某优先级下最后一次启动task的时间
如果满足这个条件则会进入下一个优先级的时间判断,直到 any
,不满足则分配当前优先级的任务。
数据本地性任务分配的源码在 taskSetManager.Scala
。
如果存在大量executor处于等待状态,可以降低以下参数的值(也可以设置为0),默认都是3s。
spark.locality.waitspark.locality.wait.processspark.locality.wait.nodespark.locality.wait.rack
当你数据本地性很差,可适当提高上述值,当然也可以直接在集群中对数据进行balance。
内存
如果你的Shuffle量特别大,同时rdd缓存比较少可以更改下面的参数进一步提高任务运行速度
spark.storage.memoryFraction
- 分配给rdd缓存的比例,默认为0.6(60%),如果缓存的数据比较少可以降低该值
spark.shuffle.memoryFraction - 分配给shuffle数据的比例,默认为0.2(20%),剩下的20%内存空间则是分配给代码生成对象等。
如果运行任务运行缓慢,jvm进行频繁GC或者内存空间不足,或者可以降低上述的两个值。
"spark.rdd.compress","true"
- 默认为false,压缩序列化的RDD分区,消耗一些cpu减少空间的使用
以上这些方法是我在解决Spark作业性能过程中接触的,更加详细的情况以及解决方法可以看这篇文章Spark排错与优化 ,总结的非常详细了。
此外,还是应该多看Spark调度的源码,对写代码已经分析问题都非常有帮助。