Python面试知识点(2020持续更新)
文章目录
-
- 一、Python宏观问题
-
- ——————1.Python自身——————
- 1.1.1. 到底什么是Python(Python语言特性)?
- 1.1.2. Python的优缺点?
- 1.1.3.说说python程序运行过程?
- 1.1.4. .pyc 与 .py文件有什么区别?
- 1.1.5. Python代码执行原理
- ——————2.Python和其他语言——————
- 1.2.1 Python 和 Java 区别是什么?运行效率哪个高,为什么?
- 1.2.2. Python 和 Java/C 的区别
- 1.2.3. python为什么不能像C++一样快? 如果要追求速度该怎么做?
- ——————3.Python2和Python3——————
- 1.3.1. Python3和Python2的区别(print,range,整数相除,map函数,废除旧式类,编码,input()函数)
- 1.3.2. Python2和3中range区别
- ——————4.其他——————
- 1.4.1. 动态语言和静态语言区别
- 二、语言特性
-
- 2.1. 什么是PEP8
- 三、数据类型
-
- ————1.Python的数据类型及互相的区别————
- 3.1.1Python当中有哪些数据类型
- 3.1.2. Python有哪些基本容器(list、tuple、set、dict)
- 3.1.3. Python中的列表,元组,集合,字典的区别
- 3.1.4. tuple(元组)和list(列表)的区别在什么地方
- 3.1.5. 对于Python的可变数据类型和不可变数据类型的了解?(答了深拷贝和浅拷贝那一套)
- ——————2.List列表——————
- 3.2.1. list的方法有哪些
- 3.2.2. list切片越界会报错吗?(不会,直接返回空列表)
- 3.2.3 如何将两个列表转换成字典,如['a', 'b', 'c'], [1, 2, 3] 转换成{'a': 1, 'b' : 2, 'c': 3} (zip函数)
- 3.2.4. 一个list中有重复,去重(set)
- 3.2.5. 如何打乱列表的顺序?(import random)
- 3.2.6.【一行式】 [[1,2],[3,4],[5,6]] 用一行代码展开该列表,得出[1,2,3,4,5,6]
- 3.2.7. 【一行式】列表推导式求列表所有奇数并构造新列表
- 3.2.8. 【一行式】写一个列表生成式,产生一个公差为11的等差数列
- 3.2.9. 请按alist中元素的age由大到小排序
- 3.2.10. 给定两个list A,B ,请用找出A,B中相同与不同的元素(相同&, 不同^)
- ——————3.Dic字典——————
- 3.3.1. Python字典常用方法
- 3.3.2. Python字典能作为key的数据类型有什么
- ???3.3.3. 字典是怎么实现的,插入一个元素
- 3.3.4.常见的哈希碰撞解决方法(没写完)
- 3.3.5. Python实现删除数组中相同的元素,不能改变顺序
- 3.3.6. 怎么样合并两个字典
- 3.3.7. 在字典中操作中pop 和 del 有什么区别
- 3.3.8. 字典根据键从小到大排序
- 3.3.9. Python items 和 iteritems的区别。
- 3.3.10. 将字符串 "k:1 |k1:2|k2:3|k3:4",处理成字典 {k:1,k1:2,...}
- ——————4.tuple 元祖——————
- 3.4.1. 哪些情况需要tuple
- ——————5.str 字符串——————
- 3.5.1. 请反转字符串 "aStr"?
- 3.5.2. s="info:xiaoZhang 33 shandong",用正则切分字符串输出['info', 'xiaoZhang', '33', 'shandong']
- 3.5.3. 如何去除字符串中多个空格并保留一个
- 3.5.4. Python 的 find() 方法
- 四、语法
- 五、深拷贝浅拷贝
-
- 5.1. Python的深拷贝和浅拷贝
- 5.2. 写一个实现深拷贝的方法,能够将多级list,dict嵌套的数据结构深拷贝
- 六、闭包,装饰器,生成器,迭代器
-
- 6.1. 了解闭包吗?他是怎么实现的,有什么用处?
- 6.2. Python里的装饰器是什么?
- 6.3. Python的装饰器?写一个计算函数执行时间的装饰器
- 6.4. 什么是迭代器?
- 6.5. 迭代器和可迭代对象分别是什么,它们之间有什么区别?
- 6.6. 如何创建一个迭代器(迭代器协议)
- 6.7. 如何构造一个生成器
- 4. 迭代器和生成器的区别?生成器是如何实现迭代的?
- 七、文件
- 八、继承
- 九、进程、线程、协程
-
- 9.1. Python多线程,多进程比较
- 9.2. 解释Python的GIL
-
- 问题1: 什么时候会释放Gil锁,
- 问题2: 互斥锁和Gil锁的关系
- 9.3. GIL是单线程的,那么Python中多线程的实现有什么用。
- 9.4. 为什么说GIL对于CPU密集型任务不友好,而对于IO密集型任务比较友好呢?
- 9.5. Python多进程编程
-
- multiprocess模块
- 利用multiprocess模块的Pool类创建多进程
- 9.6.Python 多线程编程
- 9.7.Python多进程和多线程哪个快?
- 9.8. Python线程缺陷,使用场景,替代方案
- 9.9. Python中的进程,线程和协程的区别
- 9.10. Python多线程用了几个CPU
- 9.11. python里面的进程、线程、协程特点(崩溃、卡死区别啥的)
- 9.12.Python协程
-
- 协程的作用
- 协程的优点
- 协程之生产者消费者模型
- 9.13. Python的IO多路复用是怎么实现的
- 9.14. Python多线程中Lock()与RLock()锁
- 十、内存管理
- 十一、底层
一、Python宏观问题
——————1.Python自身——————
1.1.1. 到底什么是Python(Python语言特性)?
- Python是一种解释型语言。Python不像Java,C语言,在运行之前需要编译。
(解释性语言的程序不需要编译,相比编译型语言省了道工序,解释性语言在运行程序的时候才逐行翻译。
优点:有良好的平台兼容性,在任何环境中都可以运行,前提是安装了解释器(虚拟机)。灵活,修改代码的时候直接修改就可以,可以快速部署,不用停机维护。
缺点:每次运行的时候都要解释一遍,性能上不如编译型语言。代表语言:JavaScript、Python、Erlang、PHP、Perl、Ruby) - Python是动态类型语言,在声明变量时,不需要说明变量的类型。(是一类在运行时可以改变其结构的语言:例如新的函数、对象、甚至代码可以被引进,已有的函数可以被删除或是其他结构上的变化。通俗点说就是在运行时代码可以根据某些条件改变自身结构。)
- Python适合面向对象编程,因为它支持通过组合(composition)与继承(inheritance)的方式定义类(class)。
- Python中没有public、protected、privated这些访问修饰符,但是以单下划线+变量名相当于protected,双下划线+变量名相当于privated。
- Python用途非常广泛——网络应用,自动化,科学建模,大数据应用,等等。它也常被用作“胶水语言”,帮助其他语言和组件改善运行状况。Python让困难的事情变得容易,因此程序员可以专注于算法和数据结构的设计,而不用处理底层的细节。
语言特性:python语言特性,比如面向对象?
什么是面向对象编程
面向对象的程序设计的核心是对象(上帝式思维),要理解对象为何物,必须把自己当成上帝,上帝眼里世间存在的万物皆为对象,不存在的也可以创造出来。
面向对象的优缺点
优点:
- 解决了程序的扩展性。对某一个对象单独修改,会立刻反映到整个体系中,如对游戏中一个人物参数的特征和技能修改都很容易。
- 面向对象编程可以使程序的维护和扩展变得更简单,并且可以大大提高程序开发效率
缺点:
- 可控性差,无法向面向过程的程序设计流水线式的可以很精准的预测问题的处理流程与结果,面向对象的程序一旦开始就由对象之间的交互解决问题,即便是上帝也无法预测最终结果。于是我们经常看到一个游戏人某一参数的修改极有可能导致阴霸的技能出现,一刀砍死3个人,这个游戏就失去平衡。
面向对象的三大特性:继承、封装、多态
- 继承
继承的意思就是拥有所有父类的特性。这也是继承的好处,实现了代码复用。
- 封装
- 隐藏对象的属性和实现细节,仅对外提供公共访问方式。
- 好处:
- 将变化隔离;
- 便于使用;
- 提高复用性;
- 提高安全性;
- 在python中用双下划线开头的方式将属性隐藏起来(设置成私有的)
- 多态
多态就是在子类中覆写父类的方法。这样做的好处是同样名称的方法在不同的子类中会有不同的行为。
扩展:鸭子类型
当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子。
在鸭子类型中,关注点在于对象的行为,能作什么;而不是关注对象所属的类型
1.1.2. Python的优缺点?
优点:
- python语法糖比较多。比如python的列表推导,只要熟悉的人都会觉得看的比java的几个for循环清楚很多。
- python是一门动态语言。更加灵活,更好入门,然后不需要了解很多底层细节。
- 方向广,比如可以做web开发、机器学习、人工智能、数据分析、金融量化交易、爬虫开发、自动运维、自动化测试等…
缺点:
-
慢
-
Python2和Python3兼容性问题
-
缺点就是做web大型网站没有java稳定,并发没java强。(但是现在都是通过python + go来解决任何网站的难题,python解决计算密集型的操作,go解决高并发的操作;)
1.1.3.说说python程序运行过程?
当python运行脚本时,在代码开始处理之前,Python先会把.py文件中的每一条语句都编译成字节码。
- 如果Python在当前机器上有写入权限,那么Python会把这一组字节码保存为一个.pyc文件。下一次运行程序时,如果在上一次保存字节码之后没有修改过源代码,Python会跳过编译这个步骤,直接加载.pyc文件。修改过就重新编译。(怎么知道修改过?Python会自动检查源文件和字节码文件的时间戳)
- 如果Python在当前机器上没有写入权限,程序依旧可以工作,只不过字节码会在内存中生成,程序运行完之后字节码就会被丢弃。(这块有更深入的实现,不写了。)
编译完成后,或是字节码从.pyc文件导入后,字节码会被发送到Python虚拟机,就是PVM(Python Virtual Machine),PVM迭代运行字节码指令,一个接一个的完成操作。
- python是以.py结尾的。从技术上讲,这种命名方案在导入时才是必须的,你可以用任何自己喜欢的文本编辑器创建以其它扩展名结尾的文件,但大多数python文件为了统一都是以.py结尾命名的。你在文本文件中输入代码,之后在解释器中运行这些代码。
- 执行程序时,python内部(对大多数用户完全隐藏)会先将源代码编译成字节码。编译是一个简单的翻译步骤,字节码是一个低级的与平台无关的表现形式。这些字节码比文本文件中的源代码语句的运行速度快的多。如果python进程在机器上具有写入权限,那么它会将字节码保存在一个以.pyc为扩展名的文件中。python保存字节码是对启动速度的一个优化。如果下次启动时,源代码没有修改,并且使用的python版本也没有改变,那么python将会直接加载.pyc文件,并跳过编译这个步骤。如果python无法在机器上写入字节码,程序仍然可以工作:字节码会在内存中生成,并在程序结束时被丢弃。
- 一旦程序被编译成字节码,之后的字节码发送到python虚拟机(Python Virtual Machine,PVM)上来执行。PVM就是迭代运行字节码指令的一个大循环,一个接一个地完成操作。PVM是Python运行时的引擎,它时常表现为Python系统的一部分,并且是实际运行脚本的组件。从技术上来说,它只是所谓Python解释器的最后一步。
1.1.4. .pyc 与 .py文件有什么区别?
什么是.pyc文件?
.pyc是一种二进制文件,是由py文件经过编译后,生成的文件,是一种byte code,py文件变成pyc文件后,加载的速度有所提高,而且pyc是一种跨平台的字节码,是由python的虚拟机来执行的,这个是类似于JAVA或者.NET的虚拟机的概念
- 在Python程序中,是把原始程序代码放在.py文件里,而Python会在执行.py文件的时候。将.py形式的程序编译成中间式文件(byte-compiled)的.pyc文件,这么做的目的就是为了加快下次执行文件的速度。
- 所以,在我们运行python文件的时候,就会自动首先查看是否具有.pyc文件,如果有的话,而且.py文件的修改时间和.pyc的修改时间一样,就会读取.pyc文件,否则,Python就会读原来的.py文件。
- 不要答!!!(其实并不是所有的.py文件在与运行的时候都会产生.pyc文件,只有在import相应的.py文件的时候,才会生成相应的.pyc文件)
- 为什么需要pyc文件?
1.提高加载速度
2.商业保密,因为py文件是可以直接看到源码的,如果你是开发商业软件的话,不可能把源码也泄漏出去吧?所以就需要编译为pyc后,再发布出去。 - 如何生成.pyc?
在命令行中输入python
>>> import py_compile
>>> py_compile.compile("E:/setup.py")

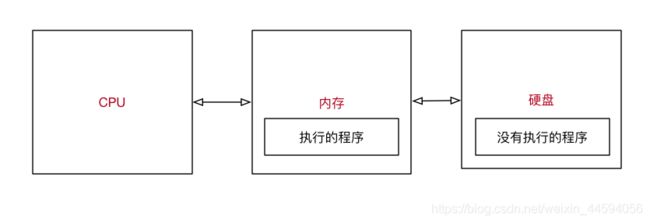
1.1.5. Python代码执行原理
- 操作系统会首先让 CPU 把 Python 解释器 的程序复制到 内存 中
- Python 解释器 根据语法规则,从上向下 让 CPU 翻译 Python 程序中的代码
- CPU 负责执行翻译完成的代码
- 示意图:
——————2.Python和其他语言——————
1.2.1 Python 和 Java 区别是什么?运行效率哪个高,为什么?
- 难易度而言。python远远简单于java。
- 开发速度。Python远优于java
- 运行速度。java远优于标准python,pypy和cython可以追赶java,但是两者都没有成熟到可以做项目的程度。
- 可用资源。java一抓一大把,python很少很少,尤其是中文资源。
- 稳定程度。python3和2不兼容,造成了一定程度上的混乱以及大批类库失效。java由于有企业在背后支持所以稳定的多。(from future import *)(将新版本的特性引进当前版本中,也就是说我们可以在当前版本使用新版本的一些特性。)
(是否开源。python从开始就是完全开源的。Java由sun开发,但现在有GUN的Openjdk可用,所以不用担心。
编译还是解释。两者都是解释型。
我理解,C好比手动挡车(编译型语言),java和python(解释型语言)好比自动档车。跑的最快的车都是手动档,但是对开不好的人来说,开自动档反而更快些。)
1.2.2. Python 和 Java/C 的区别
- Python比Java简单,学习成本低。
- Java是一种静态类型语言,Python是一种动态类型语言。(Java中的所有变量需要先声明(类型)才能使用,Python中的变量不需要声明类型)
- Java编译以后才能运行,Python直接就可以运行,开发效率高。
- 但是Java运行效率高于Python,尤其是纯Python开发的程序,效率极低。
- Java相关资料多,尤其是中文资料。
- Java版本比较稳定,Python2和3不兼容导致大量类库失效。
- JAVA 里的块用大括号对包括,Python 以冒号 + 四个空格缩进表示。
- JAVA 每行语句以分号结束,Python 可以不写分号。
- Java开发偏向于软件工程,团队协同,Python更适合小型开发???
- Java偏向于商业开发,Python适合于数据分析???
1.2.3. python为什么不能像C++一样快? 如果要追求速度该怎么做?
我觉得关键问题是 Python是动态类型、需要解释执行、还有Python的虚拟机、GIL这四个方面的问题:
1、为了支持动态类型,Python对象加入了很多抽象,执行的时候要不断的判断数据类型,带来很大的开销,所以慢
2、Python的解释执行一个是交互模式的时候需要逐行解释,二是,如果Python程序先编译再运行,编译后的文件也不是机器的二进制代码。所以第三点
3、虚拟机带来间接开销,PVM循环仍然需要解释字节码。
4、GIL带来的伪多线程问题,在Python中,如果解释器用的是Cpython,那么这时候没有真正意义上的多线程
追求速度可以使用C与Python混合编程,因为Python可以调用其他的语言,如果是GIL带来的慢的问题,可以用多进程代替多线程,也可用其他的python解释器代替Cpython。
- 与C/C++这类完全编译语言不同的是,python工作中通常没有构建或“make”的步骤: 代码写好后立即运行,另外一个就是 python 字节码不是机器的二进制代码,字节码是特定于 python 的一种表现形式。
- PVM循环仍然需要解释字节码。大多数使用的python都是Cython,是标准的实现,CPython具有调用C函数以及使用变量、参数和类属性的C类型声明的能力。追求速度可以使用C与python混合编程。
(Shed Skin是python 到 C++ 的转换器。尝试将python代码翻译成C++代码,然后使用机器中的C++编译器将得到的C++代码编译为机器代码)
——————3.Python2和Python3——————
1.3.1. Python3和Python2的区别(print,range,整数相除,map函数,废除旧式类,编码,input()函数)
在python3中,print语句没有了,取而代之的是print()函数。必须用括号括起来。不加括号会报SyntaxError(语法错误)
编码
- python2 中使用 ascii 编码,
- python3 中使用utf-8编码
Python 2 有 ASCII str() 类型,unicode() 是单独的,不是 byte 类型。
现在, 在 Python 3,我们最终有了 Unicode (utf-8) 字符串,以及一个字节类:byte 和 bytearrays。
由于 Python3.X 源码文件默认使用utf-8编码,这就使得以下代码是合法的:
>>> 中国 = 'china'
>>>print(中国)
china
Python 2.x
>>> str = "我爱北京天安门"
>>> str
'\xe6\x88\x91\xe7\x88\xb1\xe5\x8c\x97\xe4\xba\xac\xe5\xa4\xa9\xe5\xae\x89\xe9\x97\xa8'
>>> str = u"我爱北京天安门"
>>> str
u'\u6211\u7231\u5317\u4eac\u5929\u5b89\u95e8'
Python 3.x
>>> str = "我爱北京天安门"
>>> str
'我爱北京天安门'
异常
在 Python 3 中处理异常也轻微的改变了,在 Python 3 中我们现在使用 as 作为关键词。
捕获异常的语法由 except exc, var 改为 except exc as var。
(使用语法except (exc1, exc2) as var可以同时捕获多种类别的异常。 Python 2.6已经支持这两种语法。
- 在2.x时代,所有类型的对象都是可以被直接抛出的,在3.x时代,只有继承自BaseException的对象才可以被抛出。
- 2.x raise语句使用逗号将抛出对象类型和参数分开,3.x取消了这种奇葩的写法,直接调用构造函数抛出对象即可。)
range
- Python2中range返回的是列表(在2中有xrange)
- Python3中range返回的是迭代对象(3中xrange() 会抛出命名异常)
整数相除
- 在Python 2中,3/2的结果是整数,
- 在Python 3中,结果则是浮点数
八进制字面量表示
八进制数必须写成0o777,原来的形式0777不能用了;二进制必须写成0b111。
新增了一个bin()函数用于将一个整数转换成二进制字串。 Python 2.6已经支持这两种语法。
在Python 3.x中,表示八进制字面量的方式只有一种,就是0o1000。
python 2.x
>>> 0o1000
512
>>> 01000
512
python 3.x
>>> 01000
File "" , line 1
01000
^
SyntaxError: invalid token
>>> 0o1000
512
不等运算符
Python 2.x中不等于有两种写法 != 和 <>
Python 3.x中去掉了<>, 只有!=一种写法,还好,我从来没有使用<>的习惯
数据类型
1)Py3.X去除了long类型,现在只有一种整型——int,但它的行为就像2.X版本的long
2)新增了bytes类型,对应于2.X版本的八位串,定义一个bytes字面量的方法如下:
>>> b = b'china'
>>> type(b)
str 对象和 bytes 对象可以使用 .encode() (str -> bytes) 或 .decode() (bytes -> str)方法相互转化。
>>> s = b.decode()
>>> s
'china'
>>> b1 = s.encode()
>>> b1
b'china'
3)dict的.keys()、.items 和.values()方法返回迭代器,而之前的iterkeys()等函数都被废弃。同时去掉的还有 dict.has_key(),用 in替代它吧 。
map函数
-
在Python 2中,map函数返回列表list,而在Python 3中,map函数返回迭代器。
Python 2
map(lambda x: x+1, range(5)) # [1, 2, 3, 4, 5]Python 3
map(lambda x: x+1, range(5))
#
list(map(lambda x: x+1, range(5)))
# [1, 2, 3, 4, 5]
废除旧式类
- 在Python3中,没有旧式类,只有新式类,也就是说不用再像这样 class Foobar(object): pass 显式地子类化object
input()函数
- python2中是raw_input()函数,python3中是input()函数
1.3.2. Python2和3中range区别
py2中有range和xrange()
py3中的range是py2中的xrange()。
如果想要得到1~1000000(一百万)这些数,使用range()会得到一个列表,列表中存储了1到一百万的每个值,如果使用的是xrange(),会得到一个迭代器,(迭代器中保存的是生成1到一百万每个数的代码),每次这个迭代器会返回一个值。如果想要得到的值特别多,如果使用列表,会占用较大的空间,而迭代器之后占用较小的代码空间。
- python2中的range返回的是一个列表
- python3中的range返回的是一个迭代器
for i in range(1,10)在python2和python3中都可以使用,但是要生成1-10的列表,就需要用list(range(1,10))
In [14]: l = list(range(5)) + list(range(2))
In [15]: l
Out[15]: [0, 1, 2, 3, 4, 0, 1]
In [5]: s = range(1,10)
In [6]: s
Out[6]: range(1, 10)
In [7]: list(s)
Out[7]: [1, 2, 3, 4, 5, 6, 7, 8, 9]
——————4.其他——————
1.4.1. 动态语言和静态语言区别
编译时就知道变量类型的是静态类型;运行时才知道一个变量类型的叫做动态类型。
- 动态语言:如Python,JavaScript,都是弱类型语言,写代码的时候不用每次都指定其类型。是在程序运行时确定的。优点就是开发快,但是维护难。
- 静态语言:如Java、C语言这种在程序编译时就知道变量的类型的就是静态语言。优点是容易排查错误。
二、语言特性
2.1. 什么是PEP8
PEP8是Python官方推出的编码约定,主要是为了保证Python编码风格的统一。提高代码的可读性 比如:
- 缩进。4个空格的缩进(编辑器都可以完成此功能),不使用Tap,更不能混合使用Tap和空格。
- 每行最大长度79,换行可以使用反斜杠,最好使用圆括号。换行点要在操作符的后边敲回车。
- 类前空两行;类中的方法定义之间空一行;函数内逻辑无关段落之间空一行;其他地方尽量不要再空行。
- 模块导入的顺序:按标准、三方和自己编写顺序依次导入,之间空一行。不要在一句import中多个库,比如import os, sys不推荐。
- 避免不必要的空格
- 注释必须要有
- 函数命名要遵循规范
- 使用基于类的异常,每个模块或包都有自己的异常类,此异常类继承自Exception。??
- 异常中try的代码尽可能少。
- (类的方法第一个参数必须是self,而静态方法第一个参数必须是cls)
三、数据类型
————1.Python的数据类型及互相的区别————
3.1.1Python当中有哪些数据类型
- 数字类型:Python数字类型主要包括int(整型)、long(长整型)和float(浮点型),但是Python3中就不再有long类型了。
- 字符串:在Python中,加了引号的字符都被认为是字符串。
- 布尔型:和其他编程语言一样,Python布尔类型也是用于逻辑运算,有两个值:True(真)和False(假)。
- 列表:列表是Python中使用最频繁的数据类型,集合中可以放任何数据类型,可对集合进行创建、查找、切片、增加、修改、删除、循环和排序操作。
- 字典:字典是一种键值对的集合,是除列表以外Python之中最灵活的内置数据结构类型,列表是有序的对象集合,字典是无序的对象集合。
- 元祖:元组和列表一样,也是一种序列,与列表不同的是,元组是不可修改的,元组用”()”标识,内部元素用逗号隔开。
- 集合:集合是一个无序的、不重复的数据组合,它的主要作用有两个,分别是去重和关系测试。
3.1.2. Python有哪些基本容器(list、tuple、set、dict)
- list(列表): list是一个有序的,可更改的数据集合
- tuple(元祖):元组不能通过下标的方式去做更改。可以获取但是不能赋值
- set(集合): 集合中可以存储任意类型的数据,集合中不会出现重复的数据。集合的方法add(), update(), remove(), pop()
- dict(字典):字典是可变的容器模型,可以存储任意类型的对象。 注意的是不允许一个键出现两次。键必须不可变。所以键值可以用数字,字符串或元祖充当,但是列表和字典不行。
3.1.3. Python中的列表,元组,集合,字典的区别
(1) 列表
特点:
- 可以用list()函数或者方括号[]创建,元素之间用逗号
“,”分隔 - 列表的元素不需要具有相同的类型
- 使用索引来访问元素
- 元素可以切片 list2[1:3]
| 操作 | 解释 | 时间复杂度 |
|---|---|---|
| list.append(): | 追加成员 | O(1) |
| list.count(x): | 计算列表中参数x出现的次数 | O(n) |
| list.extend(L): | 向列表中追加另一个列表L | O(1) |
| list.index(x): | 获得参数x在列表中的位置 | O(n) |
| list.insert(): | 向列表中插入数据 | O(1) |
| list.pop(): | 删除列表中的成员(通过下标删除) | O(1) |
| list.remove(): | 删除列表中的成员(直接删除) | O(n) |
| list.reverse(): | 将列表中成员的顺序颠倒 | O(n) |
| list.sort(): | 将列表中成员排序 | O(nlogn) |
- 列表不太适合做元素的查找、删除、插入等操作,对应的时间复杂度为O(n);
- 访问某个索引的元素、尾部添加元素或删除元素这些操作比较适合做,对应的时间复杂度为O(1)
(2) 元祖
- 元组跟列表很像,只不过元组用小括号来实现(),这里要区分好和生成器的区别,两者都可用小括号来实现的。
- 特点:
- 可以用tuple()函数或者方括号()创建,元素之间用逗号’,‘’分隔。
- 元组的元素不需要具有相同的类型
- 使用索引来访问元素
- 可切片
- 元素的值一旦创建就不可修改!!!(这是区别与列表的一个特征)
- python里,多返回值,就是用tuple来表示
(3) 集合
特点:
- 可以用set()函数或者方括号{}创建,元素之间用逗号”,”分隔。
- 与字典相比少了键
- 不可索引,不可切片
- 不可以有重复元素
(4) 字典
字典是另一种可变容器模型,且可存储任意类型对象。
特点:
- 元素由键(key)和值(value)组成
- 可以用dict()函数或者方括号()创建,元素之间用逗号’,‘’分隔,键与值之间用冒号”:”隔开
- 键必须是唯一的,但值则不必。值可以取任何数据类型,但键必须是不可变的,如字符串,数字或元组
- 使用键(key)来访问元素
| 操作 | 解释 |
|---|---|
| adict.keys() | 返回一个包含字典所有KEY的列表; |
| adict.values() | 返回一个包含字典所有value的列表; |
| adict.items() | 返回一个包含所有(键,值)元祖的列表; |
| adict.clear() | 删除字典中的所有项或元素; |
| adict.copy() | 返回一个字典浅拷贝的副本; |
| adict.fromkeys(seq, val=None) | 创建并返回一个新字典,以seq中的元素做该字典的键,val做该字典中所有键对应的初始值(默认为None); |
| adict.get(key, default = None) | 返回字典中key对应的值,若key不存在字典中,则返回default的值(default默认为None); |
| adict.has_key(key) | 如果key在字典中,返回True,否则返回False。 现在用 in 、 not in; |
| adict.iteritems() adict.iterkeys() adict.itervalues() | 与它们对应的非迭代方法一样,不同的是它们返回一个迭代子,而不是一个列表; |
| adict.pop(key[,default]) | 和get方法相似。如果字典中存在key,删除并返回key对应的vuale;如果key不存在,且没有给出default的值,则引发keyerror异常; |
| adict.setdefault(key, default=None) | 和set()方法相似,但如果字典中不存在Key键,由 adict[key] = default 为它赋值; |
| adict.update(bdict) | 将字典bdict的键值对添加到字典adict中。 |
3.1.4. tuple(元组)和list(列表)的区别在什么地方
- 相同点:
- 都是序列
- 都可以存储任何数据类型
- 可以通过索引访问
- 不同点:
- 使用方括号[]创建列表,而使用括号()创建元组。
- 列表是可变的,而元组是不可变的。可以修改列表的值,但是不可以修改元组的值。
arr = ['a', 'b', 'c']
tuple_arr = ('a', 'b', 'c')
arr[1] = 'z'
print(arr) # ['a', 'z', 'c']
tuple_arr[1] = 'z' # 报错
当执行最后一行时报错,TypeError(类型错误): ‘tuple’ object does not support item assignment
1.列表不能当作字典的key, 而元组可以。
a = (1, 2)
b = [3, 4]
c = {
a: 'start point'} # OK
c = {
b: 'end point'} # Error
???2.元组通常由不同的数据,而列表是相同类型的数据队列。元组表示的是结构,而列表表示的是顺序。举个例子来讲:当你想记录棋盘上一个子的坐标时, 应该使用元组; 当你想记录棋盘上所有的子的坐标(一系列相同的数据)时,应该使用列表。
# 表示一个点
point = (1, 2)
# 表示一系列点
points = [(1, 2), (1, 3), (4, 5)]
3.重用与拷贝元组无法复制。 原因是元组是不可变的。
例如深拷贝和浅拷贝,如果拷贝的是一个不包含可变对象的元组,就不拷贝了。
如果运行tuple(tuple_name)将返回自己。
>>> copy_t = tuple(t)
>>> print t is copy_t
True
>>> copy_l = list(l)
>>> print l is copy_l
False
3.1.5. 对于Python的可变数据类型和不可变数据类型的了解?(答了深拷贝和浅拷贝那一套)
- 将python3的基本数据类型有六种: Number(int, float, bool, complex),String, List, Tuple, Dictionary, Set
- 可变数据类型:list, dic, set。 变量引用的数据类型,在更改数值的时候,存在不开辟新内存 的行为,此数据类型为可变数据类型。
- 不可变数据类型:Number, String,Tuple。 变量引用的数据类型,在更改数值的时候,不存在不开辟新内存 的行为,此数据类型为不可变数据类型。
1.数字
更改值,开辟新内存
代码:
num = 1
print(id(num)) # 140713990975744
num = 2
print(id(num)) # 140713990975776
分析下图中红色框代表里面的内容不可更改 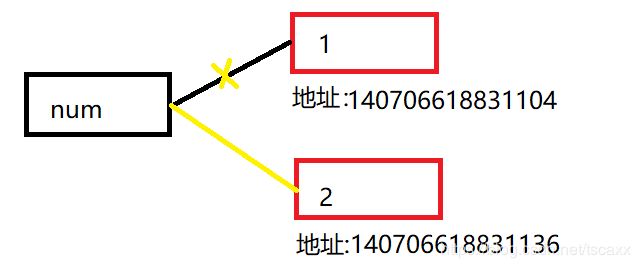
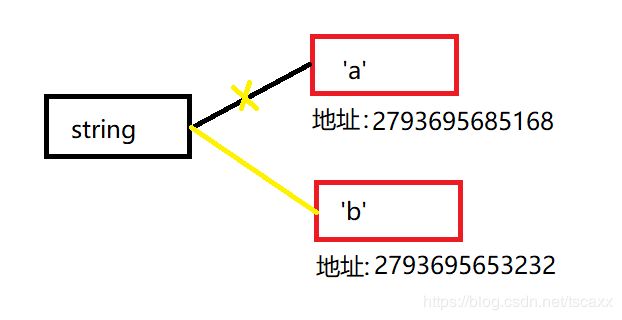
2.字符串
更改值,开辟新内存
代码:
string = 'a'
print(id(string)) # 2215758737008
string = 'b'
print(id(string)) # 2215758721456
分析:
3.列表
更改值,不开辟新内存
代码:
list = ['a','b','c','d','e','f','g']
print(id(list)) # 2049838961224
list[1] = 'w'
print(id(list)) # 2049838961224
print(list) # ['a', 'w', 'c', 'd', 'e', 'f', 'g']
分析:

更改值,开辟新内存
代码:
list = ['a','b','c','d','e','f','g']
print(id(list))
list = (1,2,3,4,5,6)
print(id(list))
分析:
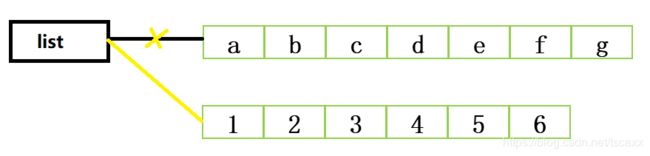
4.元组
更改值,不开辟新内存 ——> 报错,不能修改 ——> 假设不成立
代码:
tup = ('a','b','c','d','e','f','g')
print(id(tup))
tup[1] = 'w'
print(id(tup))
print(tup)
分析:

更改值,开辟新内存
tup = ('a','b','c','d','e','f','g')
print(id(tup))
tup = (1,2,3,4,5,6)
print(id(tup))
结果:
2444846585112
2444846514920
分析:
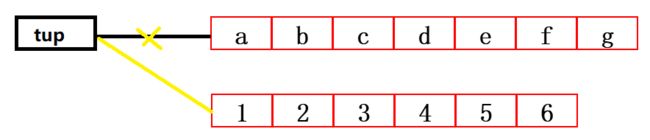
5.字典
同“列表”,略
6.集合
同“列表”,略
——————2.List列表——————
3.2.1. list的方法有哪些
| 方法 | 意义 |
|---|---|
| L.index(v [, begin[, end]]) | 返回对应元素的索引下标, begin为开始索引,end为结束索引,当 value 不存在时触发ValueError错误 |
| L.insert(index, obj) | 将某个元素插放到列表中指定的位置 |
| L.count(x) | 返回列表中元素的个数 |
| L.remove(x) | 从列表中删除第一次出现在列表中的值 |
| L.copy() | 复制此列表(只复制一层,不会复制深层对象) |
| L.append(x) | 向列表中追加单个元素 |
| L.extend(lst) | 向列表追加另一个列表 |
| L.clear() | 清空列表,等同于 L[:] = [] |
| L.sort(reverse=False) | 将列表中的元素进行排序,默认顺序按值的小到大的顺序排列 |
| L.reverse() | 列表的反转,用来改变原列表的先后顺序 |
| L.pop([index]) | 删除索引对应的元素,如果不加索引,默认删除最后元素,同时返回删除元素的引用关系 |
3.2.2. list切片越界会报错吗?(不会,直接返回空列表)
list = ['a','b','c','d','e']
print(list[10:])
- 代码将输出[],不会产生IndexError错误,就像所期望的那样,尝试用超出成员的个数的index来获取某个列表的成员。
- 例如,尝试获取list[10]和之后的成员,会导致IndexError。
- 然而,尝试获取列表的切片,开始的index超过了成员个数不会产生IndexError,而是仅仅返回一个空列表。
- 这成为疑难杂症,因为运行的时候没有错误产生,导致Bug很难被追踪到。
3.2.3 如何将两个列表转换成字典,如[‘a’, ‘b’, ‘c’], [1, 2, 3] 转换成{‘a’: 1, ‘b’ : 2, ‘c’: 3} (zip函数)
- zip()函数在运算时,会以一个或多个序列(可迭代对象)做为参数,返回一个元组的列表。同时将这些序列中并排的元素配对。
- zip()参数可以接受任何类型的序列,同时也可以有两个以上的参数;当传入参数的长度不同时,zip能自动以最短序列长度为准进行截取,获得元组。
>>> a = [1,2]
>>> b = ['a','b']
>>> list(zip(a, b)) # a,b长度相同,构建元素是元组的列表
[(1, 'a'), (2, 'b')]
>>> x = "abcdef"
>>> y = "12345"
>>> dict(zip(x, y)) # x,y长度不同,构建字典,多余的丢掉
{
'd': '4', 'b': '2', 'e': '5', 'c': '3', 'a': '1'}
3.2.4. 一个list中有重复,去重(set)
快速的去重:
set (list-set-list)
In [1]: a = [1, 2, 3, 3, 2, 5, 6, 7, 7]
In [2]: a = list(set(a))
In [3]: a
Out[3]: [1, 2, 3, 5, 6, 7]
其他去重方法:
字典
a = [1, 2, 3, 1, 1, 1, 7, 9, 5]
b = {
}
# fromkeys 创建一个新的字典,已a中的元素作为字典的键
b = b.fromkeys(a)
print b # {1: None, 2: None, 3: None, 7: None, 9: None, 5: None}
c = list(b.keys())
print c # [1, 2, 3, 7, 9, 5]
逻辑判断
a = [1, 2, 3, 1, 1, 1, 7, 9, 5]
b = []
for i in a:
if i not in b:
b.append(i)
print b # [1, 2, 3, 7, 9, 5]
3.2.5. 如何打乱列表的顺序?(import random)
a = ['a', 'b', 'c', 'd', 'e']
import random
# shuffle() 方法将序列的所有元素随机排序
random.shuffle(a)
print(a)
# ['a', 'd', 'e', 'c', 'b']
3.2.6.【一行式】 [[1,2],[3,4],[5,6]] 用一行代码展开该列表,得出[1,2,3,4,5,6]
a = [[1, 2], [3, 4], [5, 6]]
b = [j for i in a for j in i]
print(b)
# [1, 2, 3, 4, 5, 6]
3.2.7. 【一行式】列表推导式求列表所有奇数并构造新列表
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
b = [i for i in a if i % 2 == 1]
print(b)
# [1, 3, 5, 7, 9]
3.2.8. 【一行式】写一个列表生成式,产生一个公差为11的等差数列
>>> [x*11 for x in range(10)]
[0, 11, 22, 33, 44, 55, 66, 77, 88, 99]
3.2.9. 请按alist中元素的age由大到小排序
alist = [{
'name':'a','age':20},{
'name':'b','age':30},{
'name':'c','age':25}]
t = sorted(alist, key=lambda x: x["age"], reverse=True)
print(t)
# [{'name': 'b', 'age': 30}, {'name': 'c', 'age': 25}, {'name': 'a', 'age': 20}]
3.2.10. 给定两个list A,B ,请用找出A,B中相同与不同的元素(相同&, 不同^)
A = [1, 2, 3, 1, 2, 3, 4, 5]
B = [6, 7, 5, 2, 2, 1]
# 找相同的元素
a1 = set(A) & set(B)
print(a1)
# 找不同元素
a2 = set(A) ^ set(B)
print(a2)
——————3.Dic字典——————
3.3.1. Python字典常用方法
| 方法 | 描述 |
|---|---|
| clear() | 删除字典中的所有元素 |
| copy() | 返回字典的副本 |
| fromkeys() | 返回拥有指定键和值的字典 |
| get() | 返回指定键的值 |
| items() | 返回包含每个键值对的元组的列表 |
| keys() | 返回包含字典键的列表 |
| pop() | 删除拥有指定键的元素 |
| popitem() | 删除最后插入的键值对 |
| setdefault() | 返回指定键的值。如果该键不存在,则插入具有指定值的键。 |
| update() | 使用指定的键值对字典进行更新 |
| values() | 返回字典中所有值的列表 |
3.3.2. Python字典能作为key的数据类型有什么
两个角度:
-
一个对象能不能作为字典的key,就取决于其有没有
__hash__方法。查看源代码可以看到object对象是定义了__hash__方法的,而list、set和dict都把__hash__赋值为None了。 -
class object: def __hash__(self, *args, **kwargs): """Return hash(self).""" pass class list(object): __hash__ = None class set(object): __hash__ = None class dict(object): __hash__ = None -
字典中的key只能使用不可变数据类型。例如列表,字典都不能作为key的键值。key 是不能变的,列表和字典的值是可以变化的。一旦变化,就再也找不到value 了
???3.3.3. 字典是怎么实现的,插入一个元素
-
在Python中,字典是通过散列表(哈希表)实现的。字典也叫哈希数组或关联数组,所以其本质是数组。
-
字典是通过哈希表实现的。也就是说,字典也是一个数组,但数组的索引是键经过哈希函数处理后得到的散列值。
-
哈希函数的目的是使键均匀地分布在数组中,并且可以在内存中以O(1)的时间复杂度进行寻址,从而实现快速查找和修改。
-
哈希表中哈希函数的设计困难在于将数据均匀分布在哈希表中,从而尽量减少哈希碰撞和冲突。
-
由于不同的键可能具有相同的哈希值,即可能出现冲突,高级的哈希函数能够使冲突数目最小化。
-
由于字典是通过哈希表实现的。**只有可哈希的对象才能作为字典的键。**字典的三个基本操作(添加元素,获取元素和删除元素)的平均事件复杂度为O(1)。
3.3.4.常见的哈希碰撞解决方法(没写完)
3.3.5. Python实现删除数组中相同的元素,不能改变顺序
a = [1, 2, 3, 1, 6, 5, 5, 1]
In [62]: for i in a:
...: if i in lookup:
...: lookup[i] += 1
...: else:
...: lookup[i] = 1
In [63]: lookup
Out[63]: {
1: 3, 2: 1, 3: 1, 6: 1, 5: 2}
In [65]: res = [k for k, v in lookup.items() if v == 1]
In [66]: res
Out[66]: [2, 3, 6]
3.3.6. 怎么样合并两个字典
dict_1 = {
'a': 1, 'b': 2}
dict_2 = {
'c': 3, 'd': 5}
"""
方式一
"""
print dict(dict_1, **dict_2) # {'a': 1, 'b': 2, 'c': 3, 'd': 5}
"""
方式二
"""
dict_1.update(dict_2)
print dict_1
"""
方式三
"""
for k, v in dict_2.items():
dict_1[k] = v
print dict_1
3.3.7. 在字典中操作中pop 和 del 有什么区别
1.通过pop进行删除
temp = {
'a': 1, 'b': 2, 'c': 3}
# 删除a元素 并将对应的值赋值给v
v = temp.pop('a')
print(v) # 1
print(temp) # {'b': 2, 'c': 3}
# 如果元素不存在,可以设置值返回值。否则会报错
v = temp.pop('d', 'not exist')
print(v) # not exist
v = temp.pop('d') # KeyError: 'd'
print(v)
2.通过del进行删除
del 不像pop那样有返回值。
temp = {
'a': 1, 'b': 2, 'c': 3}
del temp['a']
print(temp) # {'b': 2, 'c': 3}
del temp['d'] # KeyError: 'd'
3.3.8. 字典根据键从小到大排序
d = {
'a': 24, 'g': 52, 'i': 12, 'k': 33}
# reverse=True 表示降序
a = sorted(d.items(),key=lambda x:x[1], reverse=True)
print(a)
# [('g', 52), ('k', 33), ('a', 24), ('i', 12)]
y = {
1:3, 2:2, 3:1}
by_key = sorted(y.items(),key = lambda item:item[0])
by_value = sorted(y.items(),key = lambda item:item[1])
print by_key # 结果为[(1, 3), (2, 2), (3, 1)],即按照键名排列
print by_value # 结果为[(3, 1), (2, 2), (1, 3)],即按照键值排列
3.3.9. Python items 和 iteritems的区别。
-
字典的items方法作用:是可以将字典中的所有项,以列表方式返回。因为字典是无序的,所以用items方法返回字典的所有项,也是没有顺序的。
-
字典的iteritems方法作用:与items方法相比作用大致相同,只是它的返回值不是列表,而是一个迭代器。
-
在Python 3.x 里面,iteritems()方法已经废除了。在3.x里用 items()替换iteritems() ,可以用于 for 来循环遍历。
-
In [8]: x = { 'a':1,'b':2} In [10]: y = x.items() In [11]: y Out[11]: dict_items([('a', 1), ('b', 2)]) In [12]: type(y) Out[12]: dict_items In [14]: list(y) Out[14]: [('a', 1), ('b', 2)]
3.3.10. 将字符串 “k:1 |k1:2|k2:3|k3:4”,处理成字典 {k:1,k1:2,…}
str1 = "k:1 |k1:2|k2:3|k3:4"
dict1 = {
}
for item in str1.split("|"):
k, v = item.split(":")
dict1[k] = v
print(dict1) # {'k': '1 ', 'k1': '2', 'k2': '3', 'k3': '4'}
——————4.tuple 元祖——————
3.4.1. 哪些情况需要tuple
- python里,多返回值,就是用tuple来表示
- 因为tuple不可变,所以代码更安全。如果可能,能用tuple代替list就尽量用tuple。
- Tuple 比 list 操作速度快。如果您定义了一个值的常量集,并且唯一要用它做的是不断地遍历它,请使用 tuple 代替 list。tuple比list快的原因:
- tuple中是不可变的,在CPython中tuple被存储在一块固定连续的内存中,创建tuple的时候只需要一次性分配内存。但是List被的被存储在两块内存中,一块内存固定大小,记录着Python Object(某个list对象)的信息,另一块是不固定大小的内存,用来存储数据。所以,查找时tuple可以快速定位(C中的数组);list必须遍历(C中的链表)。在编译中,由于Tuple是不可变的,python编译器将它存储在它所在的函数或者模块的“常量表”(constants table)中。运行时,只要找到这些预构建的常量元组。但是List是可变的,必须在运行中构建,分配内存。
- 当Tuple的元素是List的时候,它只存储list的引用,(C中定长数组里一个元素是指向某个链表的指针),定位查找时它还是会比List快
- CPython中已经做了相关优化以减少内存分配次数:释放一个List对象的时候,它的内存会被保存在一个自由List中以重复使用。不过非空list的创建时,仍然需要给它分配内存存储数据。
——————5.str 字符串——————
3.5.1. 请反转字符串 “aStr”?
print("aStr"[::-1])
# rtSa
3.5.2. s=“info:xiaoZhang 33 shandong”,用正则切分字符串输出[‘info’, ‘xiaoZhang’, ‘33’, ‘shandong’]
- |表示或,根据冒号或者空格切分
import re
s="info:xiaoZhang 33 shandong"
res = re.split(r':| ', s)
print(res) # ['info', 'xiaoZhang', '33', 'shandong']
3.5.3. 如何去除字符串中多个空格并保留一个
text = 'aaaa cccc'
t1 = text.split()
print(t1) # ['aaaa', 'cccc']
t2 = " ".join(t1)
print(t2) # aaaa cccc
3.5.4. Python 的 find() 方法
Python find() 方法检测字符串中是否包含子字符串 str ,如果指定 beg(开始) 和 end(结束) 范围,则检查是否包含在指定范围内,如果包含子字符串返回开始的索引值,否则返回-1。
语法:
str.find(str, beg=0, end=len(string))
用法:
str1 = "this is a example....wow!!!"
str2 = "exa"
print(str1.find(str2)) # 10
print(str1.find(str2, 9, 20)) # 10
print(str1.find(str2, 11, 20)) # -1
print(str1.find("h")) # 1
四、语法
五、深拷贝浅拷贝
5.1. Python的深拷贝和浅拷贝
浅拷贝:
- 开辟一块新的空间,里面指向原来对象的指向
深拷贝:
- 开辟一块新的空间,递归拷贝所有的子对象。
不管是copy还是deepcopy,都会先创建一份新的空间,而直接赋值b=a则不会。
如果拷贝的是一个元组(第一层是元组),而且元组中都是不可变对象,那么copy模块不管是深拷贝还是浅拷贝都变为了指向(引用)。
如果拷贝的是一个元组(第一层是元组),不管元组中的对象可变还是不可变,浅拷贝都直接指向,而不开辟新的空间了。
如果拷贝的是一个元组(第一层是元组),元组中有可变对象,那么深拷贝还是会开辟新的空间,把每一层的数据都拷贝了。
所以当深拷贝的时候,如果每一层的元素都是不可变对象,那深拷贝也不拷贝了,变为了指向,但是不管哪一层的数据,只要有一个是可变对象,那么深拷贝就会递归的把所有的数据都拷贝一份。
浅拷贝和深拷贝的不同仅仅是对组合对象来说,所谓的组合对象就是包含了其它对象的对象,如列表,类实例。而对于数字、字符串以及其它“原子”类型,没有拷贝一说,产生的都是原对象的引用。
- 浅拷贝:创建一个新的组合对象,这个新对象与原对象共享内存中的子对象。浅拷贝并不会产生一个独立的对象单独存在。浅拷贝只会拷贝第一层数据。
- 深拷贝:创建一个新的组合对象,同时递归地拷贝所有子对象,新的组合对象与原对象没有任何关联。虽然实际上会共享不可变的子对象,但不影响它们的相互独立性。改变原有被复制对象不会对已经复制出来的新对象产生影响。deepcopy的时候会将复杂对象的每一层复制一个单独的个体出来。
https://www.jianshu.com/p/961dda16d738
拷贝就是对变量的复制,
1.1 浅拷贝
拷贝对象并给其分配新的内存。但是只会拷贝父对象
# 定义一个变量a
a = ['a', 1, 'd', ['z', 'x', 'c']]
# b 浅拷贝了a
b = a.copy()
print(a) # ['a', 1, 'd', ['z', 'x', 'c']]
print(b) # ['a', 1, 'd', ['z', 'x', 'c']]
# 打印各自的内存地址,发现各不相同。证明了浅拷贝会分配一个新的内存地址
print(id(a)) # 2767408
print(id(b)) # 121575744
但是如果修改a中的元素,会怎么样呢?
# 修改a中的第一个元素为'A'
a[0] = 'A'
print(a) # ['A', 1, 'd', ['z', 'x', 'c']]
print(b) # ['a', 1, 'd', ['z', 'x', 'c']] 发现b并没有受影响
# 修改第四个元素中的第一个元素,将z 修改成 Q
a[3][1] = 'Q'
print(a) # ['A', 1, 'd', ['z', 'Q', 'c']]
print(b) # ['A', 1, 'd', ['z', 'Q', 'c']] 发现b也被修改了。why?
print(id(a[3])) # 2766208
print(id(b[3])) # 2766208
如上修改a中的第一个元素。b不会被修改。但是修改第四个元素中的第一个元素。b却被影响了。这就是前面说的浅拷贝只会拷贝第一层数据。
第二层[‘z’, ‘Q’, ‘c’]并没有拷贝成功。
这个时候b中的[‘z’, ‘Q’, ‘c’] 的内存地址和a中的[‘z’, ‘Q’, ‘c’]内存地址是一样的。 (浅拷贝只是把这个第二层的引用拷贝过来了。)。所以a中第二层的数据发生变化,b中的数据也会跟着变化。
1.2 深拷贝
对对象的完全拷贝,不管你有多少层,数据都不会共享。 深拷贝需要引入copy模块。import copy
还是拿上面的数据我们进行演示。
import copy
a = ['a', 1, 'd', ['z', 'x', 'c']]
b = copy.deepcopy(a)
print(a) # ['a', 1, 'd', ['z', 'x', 'c']]
print(a) # ['a', 1, 'd', ['z', 'x', 'c']]
# 变量的内存空间地址
print(id(a)) # 120265424
print(id(b)) # 15809072
print(a[-1])
# 最后一个元素(['z', 'x', 'c'])的内存地址
print(id(a[-1])) # 16171936
print(id(b[-1])) # 120265344
# 修改
a[0] = 'A'
a[3][0] ='Q'
print(a) # ['A', 1, 'd', ['Q', 'x', 'c']]
# 深拷贝中第二层数据也是独立的,不会被修改
print(b) # ['a', 1, 'd', ['z', 'x', 'c']]
5.2. 写一个实现深拷贝的方法,能够将多级list,dict嵌套的数据结构深拷贝
In [26]: from copy import deepcopy
In [27]: l = [1, 2, [1, 2, 3]]
In [28]: c1 = deepcopy(l)
In [29]: c1
Out[29]: [1, 2, [1, 2, 3]]
In [30]: l[2][0] = "z"
In [31]: l
Out[31]: [1, 2, ['z', 2, 3]]
In [32]: c1
Out[32]: [1, 2, [1, 2, 3]]
六、闭包,装饰器,生成器,迭代器
6.1. 了解闭包吗?他是怎么实现的,有什么用处?
闭包就是一种函数的嵌套,在一个函数中,有另一个函数的定义,并且这个里面的函数使用到了外部函数的变量,那么这个内部函数以及用到的外部函数的变量就构成了一个特殊的对象,这个特殊的对象就是闭包,或者说把这个特殊的对象当作闭包来对待。
闭包变量 既不属于全局名称空间,也不属于局部名称空间。与对象不同,对象存活在一个对象的名称空间,但是闭包变量存活在一个 函数 的名称空间和作用域。
闭包引用的自由变量将与函数一同存在,即使离开了创作它的环境也不例外,可以用来保护或隐藏一个变量,不会在调用后被垃圾回收机制(garbage collection)回收
闭包避免了使用全局变量,使得局部变量在函数外被访问成为可能,相比较面向对象,不用继承那么多的额外方法,闭包占用了更少的空间。
(闭包可用于间接访问一个变量,但是不能修改外部环境的局部变量
闭包不会造成内存泄露
闭包有利于并行运算)
用处:
闭包可以做装饰器啊。
- 当函数在定义时的词法作用域以外调用时,闭包使得函数可以继续访问其定义时的词法作用域
- 闭包可以阻止内存空间的回收
- 只要使用了回调函数,实际上就在使用闭包
工厂函数(闭包)能够记忆外层作用域里的值,不管那些嵌套作用是否还在内存中存在。
def maker(N):
def action(X):
return X ** N
return action
定义一个外层函数,返回一个嵌套函数,却并不调用内嵌函数。maker创造出action,却只是简单地返回action而不执行它。若调用外部函数,我们得到的只是内嵌函数的一个引用。
f = maker(2)
f(3) # 9
f(4) # 16
内嵌函数记住了 N = 2,即maker内部的变量N。实际上,在外层嵌套局部作用域内的N被作为执行状态信息保留了下来,并附加到生成的 action 函数上。
如果再调用外部函数,可以得到一个新的不同状态信息的嵌套函数。
g = maker(3) # 返回的action函数用来求一个数的立方
g(4) # 64
f(4) # 16
每次对工厂函数的调用,都将得到属于调用自己的状态信息的集合。我们使 g 函数记住了 N = 3,使 f 函数记住了 N = 2。每个函数都有自己的状态值,这个状态信息由 maker 中的变量 N 决定。
6.2. Python里的装饰器是什么?
Python的装饰器就是闭包。
闭包:闭包就是一种函数的嵌套,在一个函数中,有另一个函数的定义,并且这个里面的函数使用到了外部函数的变量,那么这个内部函数以及用到的外部函数的变量就构成了一个特殊的对象,这个特殊的对象就是闭包,或者说把这个特殊的对象当作闭包来对待。
装饰器就是在定义了闭包后,在某个函数或类的上一行,写上@+闭包外部函数的函数名,
(这一行相当于 被定义的函数的名 = 闭包最外层函数名(被定义的函数的名) 然后调用被定义的函数的名())可以不说
def set_func(func):
def call_func():
print("调用闭包")
func()
return call_func
# @set_func
def test():
print("调用函数test")
test = set_func(test)
test()
装饰器的作用是在不修改原来函数或类代码的前提下,为函数和类添加新的功能。
常用于身份认证(权限校验)、日志记录、输入合理性检查(检查参数)等。
有了装饰器,可以抽离出与函数功能本身无关的雷同代码并继续重用。
就是增强函数或类的功能的一个函数。
- 装饰器本质上是一个Python函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外功能,装饰器的返回值也是一个函数对象。
- 它经常用于有切面需求的场景,比如:插入日志、性能测试、事务处理、缓存、权限校验等场景。
- 装饰器是解决这类问题的绝佳设计,有了装饰器,我们就可以抽离出大量与函数功能本身无关的雷同代码并继续重用。
- 概括的讲,装饰器的作用就是为已经存在的对象添加额外的功能。
6.3. Python的装饰器?写一个计算函数执行时间的装饰器
import time
def run_timer(func):
def wrapper(*args, **kwargs):
start = time.time()
res = func(*args, **kwargs) # 函数带返回值
end = time.time()
cost_time = end - start
print("func 的运行时间为:{}".format(cost_time))
return res
return wrapper
@run_timer
def fun_one(num):
count = num
time.sleep(1)
count += 1
return count
count = fun_one(100) # func 的运行时间为:1.0004017353057861
print(count)
# 101
6.4. 什么是迭代器?
迭代器是一个可迭代对象,除此之外这个可迭代对象还实现了next魔法函数,使得遍历这个可迭代对象的适合可以记住遍历位置。
迭代器只能往前继续遍历,不能后退。
- 迭代器是python里面可以记住遍历位置的对象
- 迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。**迭代器只能往前不会后退。**使用iter()创建一个迭代器,使用next()返回一个迭代器里面的元素。
- 迭代器有两个基本的方法:iter() 和 next()。
- 字符串,列表或元组对象都可用于创建迭代器:
import sys
it = iter([1, 32, 43, 2])
while True:
try:
print(next(it))
except StopIteration:
sys.exit()
"""
1
32
43
2
"""
- 迭代器对象可以使用常规for语句进行遍历, 也可以使用 next() 函数:
it = iter("hello world~")
for i in it:
print(i, end="")
"""
hello world~
"""
6.5. 迭代器和可迭代对象分别是什么,它们之间有什么区别?
可迭代对象就是一个实现了__iter__魔法函数的对象。
如果一个对象是迭代器,那么它一定可以迭代。因为它一定包含__iter__和__next__。iter__ 返回的是它自身 self,next 则是返回迭代器中的下一个值。
一个对象可迭代,它不一定是迭代器。也就是说这个对象有__iter__魔法函数,但是没有next魔法函数。
迭代器和可迭代对象都可以被for循环使用。
判断是否是可迭代对象,可以使用isinstance来判断, isinstance(对象名,Iterable)
判断是否是迭代器,可以用isinstance(对象名,Iterator)
使用Iterable和Iterator都要先导入。
from collections.abc import Iterable
from collections.abc import Iterator
- 如果一个对象定义了 iter 和 next 两个方法,它就是一个迭代器。对于迭代器来说,iter 返回的是它自身 self,next 则是返回迭代器中的下一个值,如果没有值了则抛出一个 StopIteration 的异常。(关于这点,你可以想象成一个只进不退的标记位,每次调用 next,就会将标记往后移一个元素并返回,直到结束。)
- 如果一个对象定义了 iter 方法,返回一个迭代器对象,那么它就是一个可迭代的对象。 如果一个对象可迭代,那么就可以被 for 循环使用。比如经常用到的 list、dict、str 等类型。
- 迭代器(Iterator)和可迭代(Iterable)区别:
- 一个迭代器一定是可迭代对象,因为它一定有 iter 方法。反过来则不成立。(事实上,Iterator 就是 Iterable 的子类)
- 迭代器的 iter 方法返回的是自身,并不产生新实例。而可迭代对象的 iter 方法通常会生成一个新的迭代器对象。iter、next 分别对应于 Python 的内置函数 iter() 和 next()。
6.6. 如何创建一个迭代器(迭代器协议)
这个类要实现两个魔法函数是__iter__()与 __next__() 。
__iter__()魔法函数一定要返回一个迭代器对象的引用,这个被返回的对象要实现__iter__()与 __next__() 方法,一般返回自身。
next方法返回迭代器对象的下一个元素,当后续没有元素的时候,要让next抛出一个StopIteration异常,这样for循环在遍历这个类的对象的时候,如果没有后续元素,就会停止遍历,否则会一直遍历,没有元素后每次取到的元素都是None。
import time
from collections.abc import Iterable
from collections.abc import Iterator
class Classmate(object):
"""docstring for Classmate"""
def __init__(self):
self.name = list()
self.cur_index = 0
def add(self, name):
self.name.append(name)
def __iter__(self):
return self
def __next__(self):
if self.cur_index < len(self.name):
res = self.name[self.cur_index]
self.cur_index += 1
return res
else:
raise StopIteration
classmate = Classmate()
classmate.add("同学一")
classmate.add("同学二")
classmate.add("同学三")
for name in classmate:
print(name)
time.sleep(1)
结果:
D:\>python test05.py
同学一
同学二
同学三
-
把一个类作为一个迭代器使用需要在类中实现两个方法
__iter__()与__next__()。 -
__iter__()方法返回一个特殊的迭代器对象, 这个迭代器对象实现了 next() 方法并通过 StopIteration 异常标识迭代的完成。__next__()方法(Python 2 里是 next())会返回下一个迭代器对象。在没有后续元素时,next()会抛出一个 StopIteration 异常。 -
迭代器协议实现斐波那契数列
class Fib():
def __init__(self):
self._a = 1
self._b = 1
def __iter__(self):
return self
def __next__(self):
self._a, self._b = self._b, self._a + self._b
return self._a
f1 = Fib()
print(next(f1))
print(next(f1))
print(next(f1))
print(next(f1))
"""
1
2
3
5
"""
6.7. 如何构造一个生成器
方法1:
可以使用一行式:
In [13]: nums2 = (x*2 for x in range(10))
In [14]: nums2
Out[14]: <generator object <genexpr> at 0x0000015761EE6DC8>
方法2:
把函数变为生成器。
只要函数里有yield,那么这个函数就会变成生成器。调用这个生成器的方式和原来调用函数的方式不同。原来调用函数是函数名+(),而如果当前函数已经是一个生成器了,再这么写,只会创建一个生成器对象,用for遍历这个生成器对象,就可以每次取到一个值。
def worker(tmp):
a, b = 0, 1
cur = 0
while cur < tmp:
# print(a)
yield a
a , b = b, a+b
cur += 1
obj = worker(10)
for i in obj:
print(i)
如果想让生成器停止迭代,或取到生成器的返回值,都可以用抛异常的方式:
def worker(tmp):
a, b = 0, 1
cur = 0
while cur < tmp:
# print(a)
yield a
a , b = b, a+b
cur += 1
return "OK!"
obj = worker(10)
while True:
try:
print(next(obj))
except Exception as res:
print(res.value)
break
运行:
D:\>python test06.py
0
1
1
2
3
5
8
13
21
34
OK!
深入浅出Python多任务(线程,进程,协程)
- 在 Python 中,使用了 yield 的函数被称为生成器(generator)。
- 生成器本质上就是一个函数,它记住了上一次返回时在函数体中的位置。生成器不仅“记住”了它的数据状态,生成器还记住了程序执行的位置。
- 跟普通函数不同的是,生成器是一个返回迭代器的函数,只能用于迭代操作,更简单点理解生成器就是一个迭代器。
- 在调用生成器运行的过程中,每次遇到 yield 时函数会暂停并保存当前所有的运行信息,返回 yield 的值, 并在下一次执行 next() 方法时从当前位置继续运行。
- 使用yield实现斐波那契数列
def Fib(n):
a, b = 1, 1
count = 0
while True:
if count > n:
return
yield a
a, b = b, a + b
count +=1
f = Fib(10)
while True:
try:
print(next(f), end=" ")
# 1 1 2 3 5 8 13 21 34 55 89
except StopIteration:
sys.exit()
4. 迭代器和生成器的区别?生成器是如何实现迭代的?
生成器是一种特殊的迭代器。
共同点:
- 生成器是通过一个或多个
yield表达式构成的函数,每一个生成器都是一个迭代器(但是迭代器不一定是生成器)。
不同点:
- 语法上
- 生成器是通过函数的形式中调用 yield 或()的形式创建的
- 迭代器可以通过 iter()内置函数创建
- 用法上
- 除了next函数,生成器还支持send函数。该函数可以向生成器传递参数。
- 生成器在调用next()函数或for循环中,所有过程被执行,且返回值。
- 迭代器在调用next()函数或for循环中,所有值被返回,没有其他过程或说动作。
七、文件
八、继承
九、进程、线程、协程
9.1. Python多线程,多进程比较
- I/O密集型使用多线程,CPU密集型使用多进程
- Python的多线程是并发(假的“一起执行”)
- 多进程较稳定,一个进程意外结束一般不会影响其他进程,而一个线程死掉了,进程也就死掉了。
- 多线程是在同一份资源的前提下执行代码,而多进程是多份资源,同一份代码或多份代码,各自使用各自的资源去执行。
- 进程之间切换,消耗资源较大,线程之间共享资源,切换消耗资源相对较少。
9.2. 解释Python的GIL
GIL就是保证当程序有多线程的时候,同一时间只有一个线程在执行。
GIL这个问题并不是Python本身的问题,而是Python解释器的问题,而且只有Cpython解释器有这个问题。
GIL效率低下主要体现在计算密集型程序的程序里。因为计算密集型程序没有延时的情况下会一直进行计算,又因为GIL的原因,其他线程也无法执行,所以这时候多线程退化成了单线程。但是如果是IO密集型程序,因为程序IO会产生等待时间,这时候因为程序有耗时,GIL锁就会自动解开,python就会利用这个等待时间让其他的线程去执行。所以一般IO密集型的程序比较推荐使用多线程,而计算密集型的程序比较推荐用多进程。
如果想克服GIL所带来的问题,一个是可以换一个Python解释器,因为GIL是Cpython所带来的问题,而是可用用其他语言来实现功能,因为Python可以调用其他类型的语言。还可以用多进程代替多线程。
python面试不得不知道的点——GIL
- GIL(global interpreter lock) 是python的全局解释器锁,同一进程中假如有多个线程运行,一个线程在运行python程序的时候会霸占python解释器(加了一把锁即GIL),使该进程内的其他线程无法运行,等该线程运行完后其他线程才能运行。
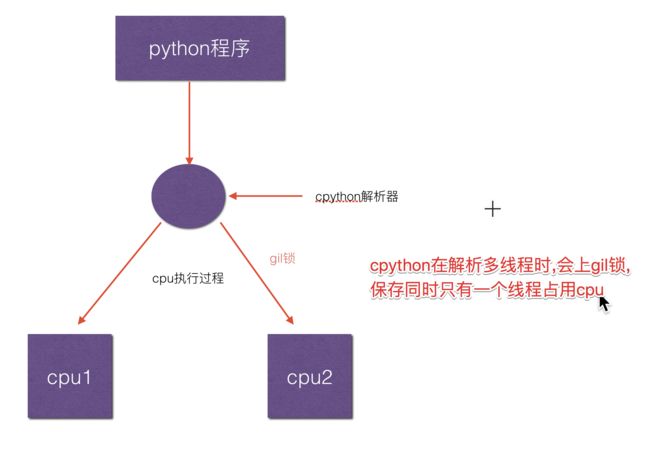
- 如果线程运行过程中遇到耗时操作,则解释器锁解开,使其他线程运行。
- 所以在多线程中,线程的运行仍是有先后顺序的,并不是同时进行。
- 多进程中因为每个进程都能被系统分配资源,相当于每个进程有了一个python解释器,所以多进程可以实现多个进程的同时运行,缺点是进程系统资源开销大
以下是几个面试会遇到的问题,希望对大家有所帮助:
问题1: 什么时候会释放Gil锁,
- 遇到像 i/o操作这种耗时操作,会有时间空闲情况造成cpu闲置的情况会释放Gil
- 会有一个专门ticks进行计数 一旦ticks数值达到100 这个时候释放Gil锁 线程之间开始竞争Gil锁(说明:
ticks这个数值可以进行设置来延长或者缩减获得Gil锁的线程使用cpu的时间)
问题2: 互斥锁和Gil锁的关系
- Gil锁 : 保证同一时刻只有一个线程能使用到cpu
- 互斥锁 : 多线程时,保证修改共享数据时有序的修改,不会产生数据修改混乱
首先假设只有一个进程,这个进程中有两个线程 Thread1,Thread2, 要修改共享的数据date, 并且有互斥锁
执行以下步骤:
- 多线程运行,假设Thread1获得GIL可以使用cpu,这时Thread1获得互斥锁lock,Thread1可以改date数据(但并没有开始修改数据)
- Thread1线程在修改date数据前发生了 i/o操作 或者 ticks计数满100 (注意就是没有运行到修改data数据),这个时候 Thread1 让出了Gil,Gil锁可以被竞争
- Thread1 和 Thread2 开始竞争 Gil (注意:如果Thread1是因为 i/o 阻塞 让出的Gil Thread2必定拿到Gil,如果Thread1是因为ticks计数满100让出 Gil 这个时候 Thread1 和 Thread2 公平竞争)
- 假设 Thread2正好获得了GIL, 运行代码去修改共享数据date,由于Thread1有互斥锁lock,所以Thread2无法更改共享数据date,这时Thread2让出GIL锁 , GIL锁完再次发生竞争
- 假设Thread1又抢到GIL,**由于其有互斥锁Lock所以其可以继续修改共享数据data,当Thread1修改完数据释放互斥锁lock,Thread2在获得GIL与lock后才可对data进行修改。**以上描述了 互斥锁和Gil锁的 一个关系
9.3. GIL是单线程的,那么Python中多线程的实现有什么用。
虽然Cpython有GIL锁,但是它会在适合的时间转换给其他的线程去执行,所以总的来说,多线程还是比单线程要快。而且Python还有其他的解释器,只有Cpython有GIL。
GIL效率低下主要体现在计算密集型程序的程序里。因为计算密集型程序没有延时的情况下会一直进行计算,又因为GIL的原因,其他线程也无法执行,所以这时候多线程退化成了单线程。但是如果是IO密集型程序,因为程序IO会产生等待时间,这时候因为程序有耗时,GIL锁就会自动解开,python就会利用这个等待时间让其他的线程去执行。所以一般IO密集型的程序比较推荐使用多线程,而计算密集型的程序比较推荐用多进程。
- Python中的多线程是假的多线程。
- python中多线程可以实现并发来提升性能
- 正常的多线程程序就像多个人同时干原本一个人干的活,由于多个人同时干,那么自然就会快不少,但是在Python的情况里面,这多个工人都得拿到一张令牌后才能干活,而令牌只有一个,一次只能发给一个工人,其他没拿到令牌的工人就得原地等待,直到拿到令牌为止,这样时时刻刻其实仍然只有最多一个工人在干活。
9.4. 为什么说GIL对于CPU密集型任务不友好,而对于IO密集型任务比较友好呢?
GIL效率低下主要体现在计算密集型程序的程序里。因为计算密集型程序没有延时的情况下会一直进行计算,又因为GIL的原因,其他线程也无法执行,所以这时候多线程退化成了单线程。但是如果是IO密集型程序,因为程序IO会产生等待时间,这时候因为程序有耗时,GIL锁就会自动解开,python就会利用这个等待时间让其他的线程去执行。所以一般IO密集型的程序比较推荐使用多线程,而计算密集型的程序比较推荐用多进程。
-
因为GIL的释放逻辑是当前线程遇见IO操作(文件操作)或者ticks计数达到100(ticks可以看作是python自身的一个计数器,专门做用于GIL,每次释放后归零,这个计数可以通过 sys.setcheckinterval 来调整),进行释放。
-
而每次释放GIL锁,线程进行锁竞争、切换线程,会消耗资源。
-
那CPU密集型任务(各种循环处理、计数等等),在这种情况下,ticks计数很快就会达到阈值,然后触发GIL的释放与再竞争(多个线程来回切换当然是需要消耗资源的),但是对于IO密集型任务,多线程能够有效提升效率(单线程下有IO操作会进行IO等待,造成不必要的时间浪费,
-
而开启多线程能在线程A等待时,自动切换到线程B,可以不浪费CPU的资源,从而能提升程序执行效率)。因此说GIL对于CPU密集型任务不友好,而对于IO密集型任务比较友好。
解决方法:
可以用多进程。multiprocessing库的出现很大程度上是为了弥补thread库因为GIL而低效的缺陷,它完整的复制了一套thread所提供的接口方便迁移。唯一的不同就是它使用了多进程而不是多线程。每个进程有自己的独立的GIL,因此也不会出现进程之间的GIL争抢。当然multiprocessing也不是万能良药。它的引入会增加程序实现时线程间数据通讯和同步的困难。 Python的多线程在多核CPU上,只对于IO密集型计算产生正面效果;而当至少有一个CPU密集型线程存在时,那么多线程效率会由于GIL而大幅下降,这个时候就得使用多进程;
9.5. Python多进程编程
multiprocess模块
python的多进程编程主要依靠multiprocess模块。我们先对比两段代码,看看多进程编程的优势。我们模拟了一个非常耗时的任务,计算8的20次方,为了使这个任务显得更耗时,我们还让它sleep 2秒。第一段代码是单进程计算(代码如下所示),我们按顺序执行代码,重复计算2次,并打印出总共耗时。
import time
import os
def long_time_task():
print('当前进程: {}'.format(os.getpid()))
time.sleep(2)
print("结果: {}".format(8 ** 20))
if __name__ == "__main__":
print('当前母进程: {}'.format(os.getpid()))
start = time.time()
for i in range(2):
long_time_task()
end = time.time()
print("用时{}秒".format((end-start)))
"""
当前母进程: 28864
当前进程: 28864
结果: 1152921504606846976
当前进程: 28864
结果: 1152921504606846976
用时4.00257420539856秒
"""
输出结果如下,总共耗时4秒,至始至终只有一个进程14236。看来电脑计算8的20次方基本不费时。
第2段代码是多进程计算代码。我们利用multiprocess模块的Process方法创建了两个新的进程p1和p2来进行并行计算。Process方法接收两个参数, 第一个是target,一般指向函数名,第二个时args,需要向函数传递的参数。对于创建的新进程,调用start()方法即可让其开始。我们可以使用os.getpid()打印出当前进程的名字。
from multiprocessing import Process
import os
import time
def long_time_task(i):
print('子进程: {} - 任务{}'.format(os.getpid(), i))
time.sleep(2)
print("结果: {}".format(8 ** 20))
if __name__=='__main__':
print('当前母进程: {}'.format(os.getpid()))
start = time.time()
p1 = Process(target=long_time_task, args=(1,))
p2 = Process(target=long_time_task, args=(2,))
print('等待所有子进程完成。')
p1.start()
p2.start()
p1.join()
p2.join()
end = time.time()
print("总共用时{}秒".format((end - start)))
输出结果如下所示,耗时变为2秒,时间减了一半,可见并发执行的时间明显比顺序执行要快很多。你还可以看到尽管我们只创建了两个进程,可实际运行中却包含里1个母进程和2个子进程。之所以我们使用join()方法就是为了让母进程阻塞,等待子进程都完成后才打印出总共耗时,否则输出时间只是母进程执行的时间。
"""
当前母进程: 6920
等待所有子进程完成。
子进程: 17020 - 任务1
子进程: 5904 - 任务2
结果: 1152921504606846976
结果: 1152921504606846976
总共用时2.131091356277466秒
"""
知识点:
- 新创建的进程与进程的切换都是要耗资源的,所以平时工作中进程数不能开太大。
- 同时可以运行的进程数一般受制于CPU的核数。
- 除了使用Process方法,我们还可以使用Pool类创建多进程。
利用multiprocess模块的Pool类创建多进程
很多时候系统都需要创建多个进程以提高CPU的利用率,当数量较少时,可以手动生成一个个Process实例。当进程数量很多时,或许可以利用循环,但是这需要程序员手动管理系统中并发进程的数量,有时会很麻烦。这时进程池Pool就可以发挥其功效了。可以通过传递参数限制并发进程的数量,默认值为CPU的核数。
Pool类可以提供指定数量的进程供用户调用,当有新的请求提交到Pool中时,如果进程池还没有满,就会创建一个新的进程来执行请求。如果池满,请求就会告知先等待,直到池中有进程结束,才会创建新的进程来执行这些请求。
下面介绍一下multiprocessing 模块下的Pool类的几个方法:
- apply_async
函数原型:apply_async(func[, args=()[, kwds={}[, callback=None]]])
其作用是向进程池提交需要执行的函数及参数, 各个进程采用非阻塞(异步)的调用方式,即每个子进程只管运行自己的,不管其它进程是否已经完成。这是默认方式。
- map()
函数原型:map(func, iterable[, chunksize=None])
Pool类中的map方法,与内置的map函数用法行为基本一致,它会使进程阻塞直到结果返回。 注意:虽然第二个参数是一个迭代器,但在实际使用中,必须在整个队列都就绪后,程序才会运行子进程。
- map_async()
函数原型:map_async(func, iterable[, chunksize[, callback]])
与map用法一致,但是它是非阻塞的。其有关事项见apply_async。
- close()
关闭进程池(pool),使其不在接受新的任务。
- terminate()
结束工作进程,不在处理未处理的任务。
- join()
主进程阻塞等待子进程的退出, join方法要在close或terminate之后使用。
下例是一个简单的multiprocessing.Pool类的实例。因为小编我的CPU是4核的,一次最多可以同时运行4个进程,所以我开启了一个容量为4的进程池。4个进程需要计算5次,你可以想象4个进程并行4次计算任务后,还剩一次计算任务(任务4)没有完成,系统会等待4个进程完成后重新安排一个进程来计算。
from multiprocessing import Pool, cpu_count
import os
import time
def long_time_task(i):
print('子进程: {} - 任务{}'.format(os.getpid(), i))
time.sleep(2)
print("结果: {}".format(8 ** 20))
if __name__=='__main__':
print("CPU内核数:{}".format(cpu_count()))
print('当前母进程: {}'.format(os.getpid()))
start = time.time()
p = Pool(4)
for i in range(5):
p.apply_async(long_time_task, args=(i,))
print('等待所有子进程完成。')
p.close()
p.join()
end = time.time()
print("总共用时{}秒".format((end - start)))
知识点:
- 对Pool对象调用join()方法会等待所有子进程执行完毕,调用join()之前必须先调用close()或terminate()方法,让其不再接受新的Process了。
输出结果如下所示,5个任务(每个任务大约耗时2秒)使用多进程并行计算只需4.37秒, 耗时减少了60%,可见并行计算优势还是很明显的。
CPU内核数:4
当前母进程: 2556
等待所有子进程完成。
子进程: 16480 - 任务0
子进程: 15216 - 任务1
子进程: 15764 - 任务2
子进程: 10176 - 任务3
结果: 1152921504606846976
结果: 1152921504606846976
子进程: 15216 - 任务4
结果: 1152921504606846976
结果: 1152921504606846976
结果: 1152921504606846976
总共用时4.377134561538696秒
相信大家都知道python解释器中存在GIL(全局解释器锁), 它的作用就是保证同一时刻只有一个线程可以执行代码。由于GIL的存在,很多人认为python中的多线程其实并不是真正的多线程,如果想要充分地使用多核CPU的资源,在python中大部分情况需要使用多进程。然而这并意味着python多线程编程没有意义哦,请继续阅读下文。
9.6.Python 多线程编程
python 3中的多线程编程主要依靠threading模块。创建新线程与创建新进程的方法非常类似。threading.Thread方法可以接收两个参数, 第一个是target,一般指向函数名,第二个时args,需要向函数传递的参数。对于创建的新线程,调用start()方法即可让其开始。我们还可以使用current_thread().name打印出当前线程的名字。 下例中我们使用多线程技术重构之前的计算代码。
import threading
import time
def long_time_task(i):
print('当前子线程: {} - 任务{}'.format(threading.current_thread().name, i))
time.sleep(2)
print("结果: {}".format(8 ** 20))
if __name__=='__main__':
start = time.time()
print('这是主线程:{}'.format(threading.current_thread().name))
t1 = threading.Thread(target=long_time_task, args=(1,))
t2 = threading.Thread(target=long_time_task, args=(2,))
t1.start()
t2.start()
end = time.time()
print("总共用时{}秒".format((end - start)))
下面是输出结果。为什么总耗时居然是0秒? 我们可以明显看到主线程和子线程其实是独立运行的,主线程根本没有等子线程完成,而是自己结束后就打印了消耗时间。主线程结束后,子线程仍在独立运行,这显然不是我们想要的。
这是主线程:MainThread
当前子线程: Thread-1 - 任务1
当前子线程: Thread-2 - 任务2
总共用时0.0017192363739013672秒
结果: 1152921504606846976
结果: 1152921504606846976
如果要实现主线程和子线程的同步,我们必需使用join方法(代码如下所示)。
import threading
import time
def long_time_task(i):
print('当前子线程: {} 任务{}'.format(threading.current_thread().name, i))
time.sleep(2)
print("结果: {}".format(8 ** 20))
if __name__=='__main__':
start = time.time()
print('这是主线程:{}'.format(threading.current_thread().name))
thread_list = []
for i in range(1, 3):
t = threading.Thread(target=long_time_task, args=(i, ))
thread_list.append(t)
for t in thread_list:
t.start()
for t in thread_list:
t.join()
end = time.time()
print("总共用时{}秒".format((end - start)))
修改代码后的输出如下所示。这时你可以看到主线程在等子线程完成后才答应出总消耗时间(2秒),比正常顺序执行代码(4秒)还是节省了不少时间。
这是主线程:MainThread
当前子线程: Thread - 1 任务1
当前子线程: Thread - 2 任务2
结果: 1152921504606846976
结果: 1152921504606846976
总共用时2.0166890621185303秒
当我们设置多线程时,主线程会创建多个子线程,在python中,默认情况下主线程和子线程独立运行互不干涉。如果希望让主线程等待子线程实现线程的同步,我们需要使用join()方法。如果我们希望一个主线程结束时不再执行子线程,我们应该怎么办呢? 我们可以使用t.setDaemon(True),代码如下所示。
import threading
import time
def long_time_task():
print('当子线程: {}'.format(threading.current_thread().name))
time.sleep(2)
print("结果: {}".format(8 ** 20))
if __name__=='__main__':
start = time.time()
print('这是主线程:{}'.format(threading.current_thread().name))
for i in range(5):
t = threading.Thread(target=long_time_task, args=())
t.setDaemon(True)
t.start()
end = time.time()
print("总共用时{}秒".format((end - start)))
9.7.Python多进程和多线程哪个快?
因为计算密集型程序没有延时的情况下会一直进行计算,又因为GIL的原因,其他线程也无法执行,所以这时候多线程退化成了单线程。但是如果是IO密集型程序,因为程序IO会产生等待时间,这时候因为程序有耗时,GIL锁就会自动解开,python就会利用这个等待时间让其他的线程去执行。所以一般IO密集型的程序比较推荐使用多线程,而计算密集型的程序比较推荐用多进程。
由于GIL的存在,很多人认为Python多进程编程更快,针对多核CPU,理论上来说也是采用多进程更能有效利用资源。网上很多人已做过比较,我直接告诉你结论吧。
- 对CPU密集型代码(比如循环计算) - 多进程效率更高
- 对IO密集型代码(比如文件操作,网络爬虫) - 多线程效率更高。
为什么是这样呢?其实也不难理解。对于IO密集型操作,大部分消耗时间其实是等待时间,在等待时间中CPU是不需要工作的,那你在此期间提供双CPU资源也是利用不上的,相反对于CPU密集型代码,2个CPU干活肯定比一个CPU快很多。那么为什么多线程会对IO密集型代码有用呢?这时因为python碰到等待会释放GIL供新的线程使用,实现了线程间的切换。
9.8. Python线程缺陷,使用场景,替代方案
GIL就是保证当程序有多线程的时候,同一时间只有一个线程在执行。
GIL这个问题并不是Python本身的问题,而是Python解释器的问题,而且只有Cpython解释器有这个问题。
GIL效率低下主要体现在计算密集型程序的程序里。因为计算密集型程序没有延时的情况下会一直进行计算,又因为GIL的原因,其他线程也无法执行,所以这时候多线程退化成了单线程。但是如果是IO密集型程序,因为程序IO会产生等待时间,这时候因为程序有耗时,GIL锁就会自动解开,python就会利用这个等待时间让其他的线程去执行。所以一般IO密集型的程序比较推荐使用多线程,而计算密集型的程序比较推荐用多进程。
如果想克服GIL所带来的问题,一个是可以换一个Python解释器,因为GIL是Cpython所带来的问题,而是可用用其他语言来实现功能,因为Python可以调用其他类型的语言。还可以用多进程代替多线程。
9.9. Python中的进程,线程和协程的区别
进程
- 进程是程序执行时的一个实例,是担当分配系统资源(CPU时间、内存等)的基本单位;
- 进程有独立的地址空间,一个进程崩溃后,在保护模式下不会对其它进程产生影响;
- 进程间可以通过信号、信号量、共享内存、管道、队列等来进行通信;
- 进程创建、销毁、上下文切换带来的开销成本都很大;
线程
- 线程是进程的一个实体,作为独立运行和独立调度的基本单位。
- 线程可与同属一个进程的其他的线程共享进程所拥有的全部资源。
- 线程只是一个进程中的不同执行路径,没有单独的地址空间,一个线程死掉就会导致整个进程死掉。
- 线程创建、销毁、上下文切换带来的开销要比进程小得多;
协程
- 协程的控制有应用程序控制,非抢占式的;
- 切换快,开销相较线程更小,所以可以开更多的协程;
9.10. Python多线程用了几个CPU
在python中使用threading多线程库编程要注意:threading并不会使用计算机的多cpu核,仍然是使用的单核进行计算的,所以并不会加快计算速度。
9.11. python里面的进程、线程、协程特点(崩溃、卡死区别啥的)
说了进程是资源最小单元,线程分配最小单元 线程相互影响,一个死了其他的会卡死然后不会了
9.12.Python协程
- 协程(coroutine),又称为微线程,纤程。
协程的作用
- 在执行A函数的时候,可以随时中断,去执行B函数,然后中断继续执行A函数(可以自动切换),单着一过程并不是函数调用(没有调用语句)
- 过程很像多线程,然而协程只有一个线程在执行
协程的优点
- 协程可以很完美的处理IO密集型的问题,但是处理cpu密集型并不是他的长处。要充分发挥CPU的性能,可以结合多进程+多线程的方式
- 执行效率高,因为子程序切换函数,而不是线程,没有线程切换的开销,由程序自身控制切换。于多线程相比,线程数量越多,切换开销越大,协程的优势越明显
- 不需要锁的机制,只有一个线程,也不存在同时写变量冲突,在控制共享资源时也不需要加锁。
协程之生产者消费者模型
import time
def consumer():
r = ''
while True:
n = yield r
if not n:
return
print('[CONSUMER] Consuming %s...' % n)
time.sleep(1)
r = '200 OK'
def produce(c):
c.next()
n = 0
while n < 5:
n = n + 1
print('[PRODUCER] Producing %s...' % n)
r = c.send(n)
print('[PRODUCER] Consumer return: %s' % r)
c.close()
if __name__=='__main__':
c = consumer()
produce(c)
- Python对协程的支持还非常有限,用在generator中的yield可以一定程度上实现协程。虽然支持不完全,但已经可以发挥相当大的威力了。
9.13. Python的IO多路复用是怎么实现的
9.14. Python多线程中Lock()与RLock()锁
资源总是有限的,程序运行如果对同一个对象进行操作,则有可能造成资源的争用,甚至导致死锁
也可能导致读写混乱
锁提供如下方法:
1.Lock.acquire([blocking])
2.Lock.release()
3.threading.Lock():加载线程的锁对象,是一个基本的锁对象,一次只能一个锁定,其余锁请求,需等待锁释放后才能获取
4.threading.RLock():多重锁,在同一线程中可用被多次acquire。如果使用RLock,那么acquire和release必须成对出现,
调用了n次acquire锁请求,则必须调用n次的release才能在线程中释放锁对象
例如:
无锁:
#coding=utf8
import threading
import time
num = 0
def sum_num(i):
global num
time.sleep(1)
num +=i
print (num)
print ('%s thread start!'%(time.ctime()))
try:
for i in range(6):
t =threading.Thread(target=sum_num,args=(i,))
t.start()
except KeyboardInterrupt:
print ("you stop the threading")
print ('%s thread end!'%(time.ctime()))