Python爬虫实战(二):微博评论文本爬取
追风赶月莫停留,平芜尽处是春山。
文章目录
- 追风赶月莫停留,平芜尽处是春山。
- 一、网页分析
- 二、接口分析
-
- url分析
- 返回数据分析
- 三、编写代码
-
- 获取数据
- 完整代码
一、网页分析
微博共有三种浏览方式,便于评论的抓取我们这次选择的是类似手机网页版的微博

打开某一篇博文的评论,进入开发者模式,刷新网页,就能发现这个东西。

里面包含评论内容、评论时间、评论者昵称、id等信息。

二、接口分析
url分析
第一页:
https://m.weibo.cn/comments/hotflow?id=4635408392523906&mid=4635408392523906&max_id_type=0
继续往下翻:
https://m.weibo.cn/comments/hotflow?id=4635408392523906&mid=4635408392523906&max_id=138164334920019&max_id_type=0
发现多了一个max_id参数
经过我们的分析我们可以知道id和mid是一样的都代表这篇博文的id,

现在,文章的id知道了,只要找到max_id和max_id_type就行了。
还是那个接口,发现他已经给出了max_id和max_id_type,然后看下一页评论,发现url中的max_id和max_id_type就是上一页中给出的。
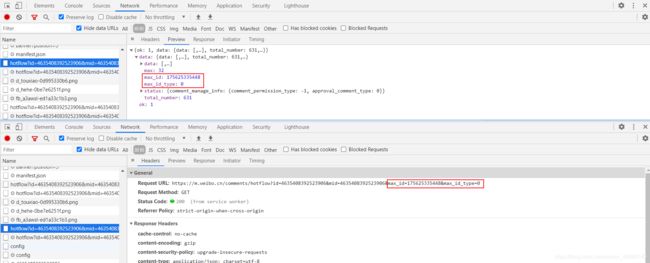
接下来事情就好办了,但是注意一个问题,还有对于评论的评论,我们把它称作二级评论,然后我们看一下二级评论的抓取。

注意:只有当total_number的数量大于0的时候才会有二级评论。
同样是开发者模式刷新页面,发现

这个接口
https://m.weibo.cn/comments/hotFlowChild?cid=4635410275500069&max_id=0&max_id_type=0
其中cid参数是本条评论的mid。

当二级评论多的时候,也会有max_id和max_type参数的存在,这些请读者自行寻找。
返回数据分析

对于这个接口我们可以发现这个是个get请求,并且返回的数据是json格式utf-8的编码。
直接把得到的数据按照json数据格式化就行了。
三、编写代码
知道了url规则,以及返回数据的格式,那现在咱们的任务就是构造url然后请求数据
现在来构造url:
url = 'https://m.weibo.cn/comments/hotflow?id={}&mid={}&max_id={}&max_id_type={}'
url = url.format(mid, mid, max_id, max_id_type)
对于每个url我们都要去用requests库中的get方法去请求数据:
所以我们为了方便就把请求网页的代码写成了函数get_html(url),传入的参数是url返回的是请求到的内容。
def get_html(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36",
"Referer": "https://m.weibo.cn"
}
cookies = {
"cookie": "你的cookie"
}
response = requests.get(url, headers=headers, cookies=cookies)
response.encoding = response.apparent_encoding
time.sleep(3) # 加上3s 的延时防止被反爬
return response.text
其中referer是一个认证读者可以自行百度
cookies是某些网站为了辨别用户身份,进行Session跟踪而储存在用户本地终端上的数据(通常经过加密),由用户客户端计算机暂时或永久保存的信息这个可以在开发者模式里面找到

把自己的cookie里面的信息替换掉代码里的就好了。
获取数据
# 获取二级评论
def get_second_comments(cid):
max_id = 0
max_id_type = 0
url = 'https://m.weibo.cn/comments/hotFlowChild?cid={}&max_id={}&max_id_type={}'
while True:
response = get_html(url.format(cid, max_id, max_id_type))
content = json.loads(response)
comments = content['data']
for i in comments:
text_data = i['text']
save_text_data(text_data)
max_id = content['max_id']
max_id_type = content['max_id_type']
if max_id == 0:
break
# 获取一级评论
def get_first_comments(mid):
max_id = 0
max_id_type = 0
url = 'https://m.weibo.cn/comments/hotflow?id={}&mid={}&max_id={}&max_id_type={}'
while True:
response = get_html(url.format(mid, mid, max_id, max_id_type))
content = json.loads(response)
max_id = content['data']['max_id']
max_id_type = content['data']['max_id_type']
text_list = content['data']['data']
for text in text_list:
text_data = text['text']
total_number = text['total_number']
if int(total_number) != 0: # 如果有二级评论就去获取二级评论。
get_second_comments(text['id'])
save_text_data(text_data)
if int(max_id) == 0: # 如果max_id==0表明评论已经抓取完毕了
break
完整代码
# -*- coding:utf-8 -*-
# @time: 2021/5/11 19:00
# @Author: 韩国麦当劳
# @Environment: Python 3.7
# @file: 微博评论.py
import json
import re
import requests
import time
# 获取网页源码的文本文件
def get_html(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36",
"Referer": "https://m.weibo.cn"
}
cookies = {
"cookie": "你的cookie"
}
response = requests.get(url, headers=headers, cookies=cookies)
response.encoding = response.apparent_encoding
time.sleep(3) # 加上3s 的延时防止被反爬
return response.text
def get_string(text):
t = ''
flag = 1
for i in text:
if i == '<':
flag = 0
elif i == '>':
flag = 1
elif flag == 1:
t += i
return t
# 保存评论
def save_text_data(text_data):
text_data = get_string(text_data)
with open("data.csv", "a", encoding="utf-8", newline="")as fi:
fi = csv.writer(fi)
fi.writerow([text_data])
# 获取二级评论
def get_second_comments(cid):
max_id = 0
max_id_type = 0
url = 'https://m.weibo.cn/comments/hotFlowChild?id={}&max_id={}&max_id_type={}'
while True:
response = get_html(url.format(cid, max_id, max_id_type))
content = json.loads(response)
comments = content['data']
for i in comments:
text_data = i['text']
save_text_data(text_data)
max_id = content['max_id']
max_id_type = content['max_id_type']
if max_id == 0: # 如果max_id==0表明评论已经抓取完毕了
break
# 获取一级评论
def get_first_comments():
max_id = 0
max_id_type = 0
url = 'https://m.weibo.cn/comments/hotflow?id=4615869701554470&mid=4615869701554470&max_id={}&max_id_type={}'
while True:
response = get_html(url.format(max_id, max_id_type))
content = json.loads(response)
max_id = content['data']['max_id']
max_id_type = content['data']['max_id_type']
text_list = content['data']['data']
for text in text_list:
text_data = text['text']
total_number = text['total_number']
if int(total_number) != 0: # 如果有二级评论就去获取二级评论。
get_second_comments(text['id'])
save_text_data(text_data)
if int(max_id) == 0: # 如果max_id==0表明评论已经抓取完毕了
break
if __name__ == '__main__':
mid = ["4635408392523906"]
for id in mid:
get_first_comments(id) # 爬取一级评论
获得的部分数据截图

欢迎一键三连哦!
还想看哪个网站的爬虫?欢迎留言,说不定下次要分析的就是你想要看的!