C语言——数据结构之树与二叉树(下)(线索二叉树、树与二叉树的转换、哈夫曼树)
前言
树的后半部分,将介绍线索二叉树,树和二叉树的转换及哈夫曼树。
树的应用很多,内容主要集中在讲解算法思想,代码量有所减少,另外会附很多图以便讲解。
ps:(一点废话),不咕咕了。这一篇比上篇会短小一点。
一、线索二叉树
1.引入部分
(1)遍历二叉树是按某种规则将非线性结构的二叉树结点线性化
(2)遍历二叉树可得到结点的一个线性序列,在线性序列中,就存在结点的前驱和后继,但是在二叉链表上只能找到结点的左孩子、右孩子
(3)二叉树结点中没有相应前驱和后继的信息。
现在的问题是:能否通过结点的两个链域查找出任一结点的前驱和后继?
结点的前驱和后继只有在每次遍历时动态产生
(4)回顾前面,我们使用了n个节点的二叉链表:
有:2n个指针域
使用:n-1个指针,除根以外,每个结点被一个指针指向
空指针域数:2n-(n-1)=n+1
2.线索二叉树
(1)定义:利用n+1个空链域存放结点的前驱和后继信息
(2)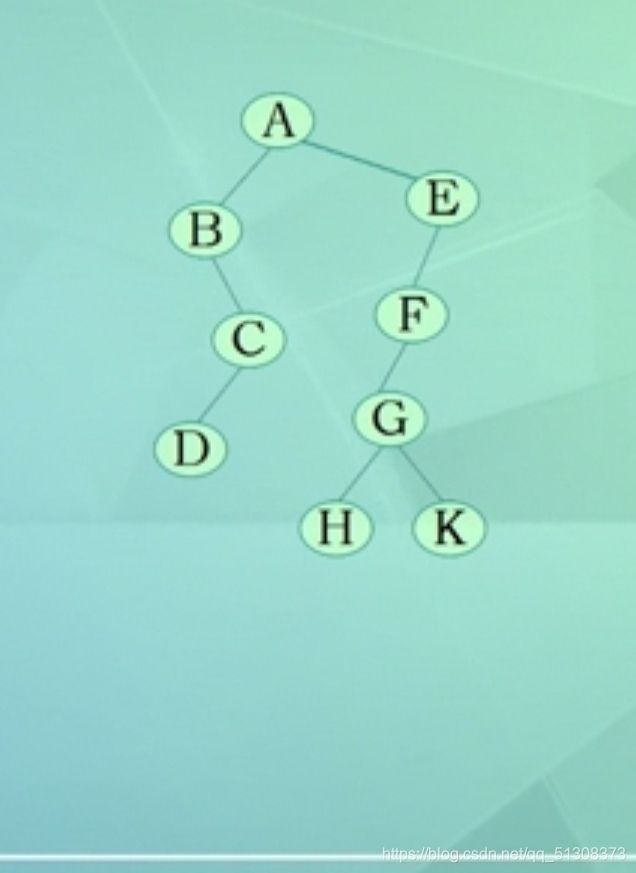
①先序序列:ABCDEFGHK
②线索:指向先序序列中的前驱和后继的指针
则产生一个问题:如何判断一个指针究竟是指向孩子,还是指向前驱或后继
(3)结点结构
为解决以上问题,在二叉链表中增加Ltag和Rtag两个标志域
此时,链表结点包含5个域:lchild,Ltag,data,Rtag,rchild
①考虑结点的左子树:
若有,则左链域lchild指示其左孩子(Ltag=0)
否则,令左链域lchild指示其前驱(Ltag=1)
②考虑结点的右子树:
若有,则右链域rchild指示其右孩子(Rtag=0)
否则,令右链域rchild指示其后继(Rtag=1)
3.整体结构
(1)增设一个头结点,令其lchild指向二叉树的根结点,Ltag=0,Rtag=1
(2)并将该结点作为遍历访问的第一个结点的前驱和最后一个结点的后继
(3)最后用头指针指示该结点
(4)若为空二叉树,只有一个头结点,其Ltag=0、Rtag=1,;lchild与rchild都指向头结点自身
4.线索链表的类型描述
//线索链表的类型描述
//定义1个枚举类型PointerTag,其中Link==0,指针;Thread==1,线索
typedef enum
{
Link,Thread
}PointerTag;
typedef struct BiThrNode
{
TElemType data;
struct BiThrNode *lchild,*rchild;//左右孩子指针
PointerTag LTag,RTag;//左右标志
}BiThrNode,*BiThrTree;//*BiThrTree为指向BiThrNode的指针类型
(1)称以这种BiThrNode结点结构构成的二叉链表为二叉树的线索链表
(2)其中指示前驱和后继的链域称为线索
(3)加上线索的二叉树称为线索二叉树
(4)线索化:对二叉树以某规则遍历使其变为线索二叉树的过程
如:
按中序遍历得到的线索二叉树称为中序线索二叉树
按先序遍历得到的线索二叉树称为先序线索二叉树
按后序遍历得到的线索二叉树称为后序线索二叉树
5.中序线索链表的遍历算法(不需堆栈,非递归处理)
(1)目的:为了能更快的二叉树进行再次遍历,由于在线索链表中添加了以前遍历中得到的前驱和后继的信息,从而可以简化遍历算法
(2)考虑几个问题:
①中序遍历的第一个结点如何找到?(左子树上最左下的结点)
②在中序线索链表中如何找到结点的后继?若无右子树,则为后继线索所指结点,否则为对其右子树进行中序遍历时所访问的第一个结点
(3)步骤:
①设置一个搜索指针p
② 先寻找中序遍历的首结点(即最左下角结点),当LTag=0时(表示有左孩子),p=p->lchild,
直到LTag=1(无左孩子,已到最左下角),首先访问p->data
③接着进入该结点的右子树,检查RTag和p->rchild
1)若该结点的RTag=1(表示有后继线索),则p=p->rchild,访问p->data;并重复1),直到后继结点的RTag=0
2)当RTag=0时(表示有右孩子),则应从该结点的右孩子开始(p=p->rchild)查找左下角的子孙结点,即重复2
主要规则:有后继找后继,无后继找右子树的最左子孙
//中序线索二叉树遍历
void InOrderTraverse_Thr (BiThrTreeT,void(*visit)(TElemType e))
{
p = T->lchild;//p指向根结点
while (p!=T)//空树或遍历结束时,p==T
{
while (p->LTag==Link)//第一个结点
{
p = p->lchild;
}
if (!visit(p->data))//访问其左子树为空的结点
return ERROR;
while (p->RTag==Thread && p->rchild!=T)//访问其后继结点
{
p = p->rchild;
visit(p->data);
}
p = p->rchild;//处理其右子树
}
}
二、树与二叉树的转换
1.树转换成二叉树
根据树的二叉链表特征,可以制定以下转换规则与步骤:
(1)加线:在树兄弟结点之间依次加一连线

(2)抹线:对每个结点,除了其左孩子(第一个孩子)外,去掉其与其余孩子之间的关系
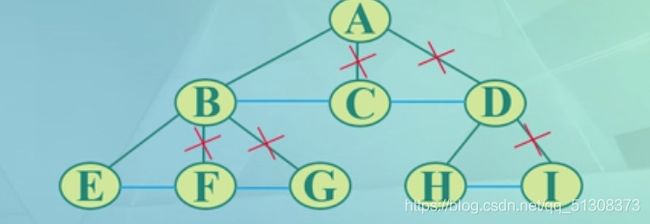
(3)旋转:以树的根结点为轴心,将整树顺时针旋转45°

转换之后的二叉树与其对应的二叉链表一样,根结点右子树一定为空
原来树中兄弟关系转换成了二叉树中双亲与右孩子的关系
2.二叉树转换成树
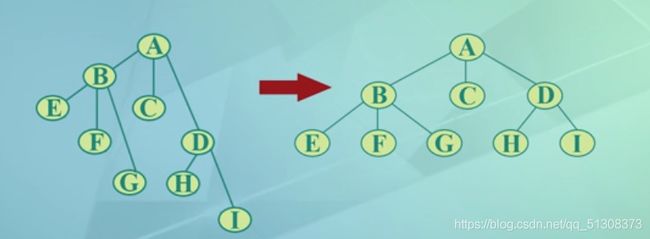
(1)加线(恰好是上述中抹线的逆过程,恢复双亲与孩子的关系):若p结点是双亲结点的左孩子,则将p的右孩子,右孩子的右孩子,
以及沿分支找到的所有右孩子,都与p的双亲用线连起来、

(2)抹线:抹掉原二叉树中双亲与右孩子之间的连线(他们在树中本为兄弟,无需连线)

(3)调整:将结点按层次排列,形成树结构
3.森林转换成二叉树
(1)将各棵树分别转换成二叉树
(2)将每棵二叉树的根结点用线相连
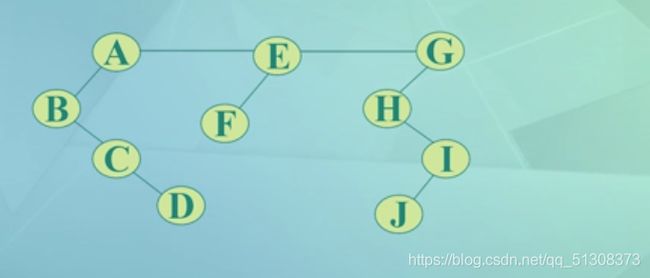
(3)以第一棵树根结点为二叉树的根,再以根结点为轴心,顺时针旋转,构成二叉树型结构
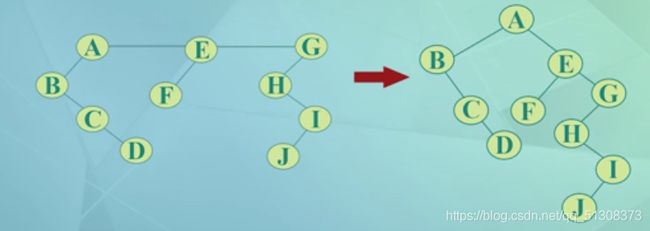
可知,二叉树的根及其左子树来源于第一棵树,根的右孩子及其左子树来源于第二棵树,而根的右孩子的右孩子及其左子树来源于第三课树
4.二叉树转换成森林
(1)抹线:将二叉树中根结点与其右孩子的连线,以及沿右分支
搜索到的所有右孩子间连线全部抹掉,使之变成孤立的二叉树
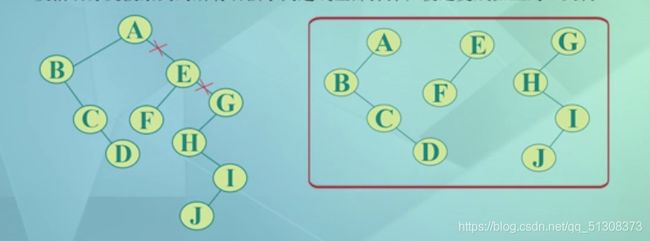
(2) 利用二叉树转换成树的方法分别将孤立的二叉树还原成树,从而形成森林
5.树的遍历
树的遍历要规定根与子树的访问次序,可分成先根遍历与后根遍历
(1)先根遍历:(递归) (与二叉树的先序遍历一致)
若树为空,则空操作
否则,树非空时,按以下两步处理
①访问树的根结点
②依次先根遍历每颗子树

如图,序列为RADEBCFGHK
(2)后根遍历:(递归) (与二叉树的中序遍历一致)
若树为空,则空操作
否则,树非空时,按以下两步处理
①依次后根遍历每颗子树
②访问树的根结点
序列为DEABGHKFCR
6.森林的遍历
(1)先序遍历:(递归)(等价于对其二叉树进行先序遍历)
若森林为空,则空操作
否则,森林非空时,
①访问第一棵树的根结点
②先序遍历第一棵树中根结点的子树森林
③先序遍历余下的树构成的森林
(2)中序遍历 :(递归)(等价于对其二叉树进行中序遍历)
若森林为空,则空操作
否则,森林非空时,
①中序遍历第一棵树中根结点的子树森林
②访问第一棵树的根结点
③中序遍历余下的树构成的森林
7.树的遍历和二叉树遍历的对应关系

三、哈夫曼树(基于二叉树的应用)及其应用
1.最优二叉树 (哈夫曼树)
(1)路径长度:
从树中一个结点到另一个结点之间的分支构成这两个结点之间的路径,路径上的分支数目叫做路径长度
(2)树的路径长度(PL(T)):
从树根到每一结点的路径长度之和
举几个例子

问题:什么时候路径长度最小(大)
分析如下:
(3)PL(T)最小
当n个结点的二叉树为完全二叉树时,结点i的层=[log2 i]+1(向下取整)
树T的根到结点i的路径长度=结点i的层-1=[log2i](向下取整)
故PL(T)=[log2 1]+[log2 2]+…+[log2 n](向下取整)=∑(1<=i<=n)[log2 i] (向下取整)
(4)PL(T)最大
当n个结点的二叉树为单枝树时,PL(T)=0+1+2+…+(n-1)=n(n-1)/2
(5)树或二叉树T的带全路径长度:WPL(T)
每个叶子的权与根到该叶子的路径长度的乘积之和
WPL=∑(1<=k<=n) wk*lk
其中:
n——树T的叶子数目
wk——叶子k的权
lk——树T的根到叶子k的路径长度、
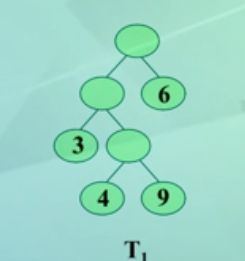
WPL(T1)=32+43+93+61=51
(6)哈夫曼树定义:
在具有n个相同叶子的各二叉树中,WPL最小的树
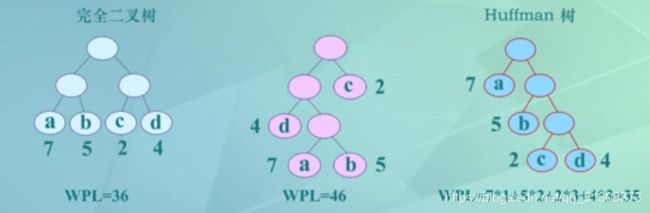
几点特征:
①完全二叉树并不一定是哈夫曼树(如第一棵)
②在哈夫曼树中,权值大的结点离根近
③哈夫曼树不唯一,但带权路径长度WPL一定相等
④不存在度为1 的结点
2.哈夫曼算法
(1)以权值分别为w1,w1,…,wn的n个结点,构成n棵二叉树T1,T2,…,Tn,并组成森林F={T1,T2,…,Tn}
注意:每棵二叉树Ti仅有一个权值为wi的根结点
(2)在F中选取两棵根结点最小的树作为左右子树构造一颗新二叉树,并且置新二叉树根结点权值为左右子树上根结点的权值之和
即:根结点的权值=左右孩子权值之和
叶结点的权值=wi
(3)从F中删除这两棵二叉树,同时将新二叉树加入到F中
(4)重复(2)(3)直到F中只含一棵二叉树为止(这棵树就是哈夫曼树)
3.哈夫曼编码 / 最小冗余码
之前学的ASCII码为定长码
哈夫曼码(不定长)特点:能按字符的使用频率,使文本代码的总长度具有最小值
举例说明哈夫曼编码与译码
eg:给定有18个字符组成的文本:AADATARAEFRTAAFTER,求各字符的哈夫曼码
(1)在文本中统计各字符的出现频率

(2)以上述频度为叶子结点的权值,构造哈夫曼树
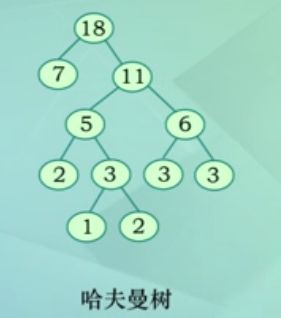
(3)在哈夫曼树基础上,对每个字符进行编码,左分支标0,右分支标1

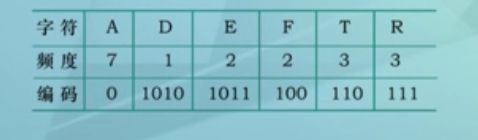
可见,哈夫曼码是不定长的码。实现编码时,顺序:对于给定的字符,从叶子结点找双亲,按逆序记录下01串
另一特点:任一编码不是其他编码的前缀(如A为0,不是其他任意编码的前缀)
这一特性使得对编码后的01串译码时,具有唯一性
(4)译码
顺序:通过输入的01串,从根沿01分支搜索到叶子,得到对应子串的原文字符

4.哈夫曼算法的实现(使用链式和顺序两种存储结构)(建立三叉链表结构)
(1)哈夫曼树不存在度为1的结点,因此若哈夫曼树有n个叶子结点,则其共有2n-1个结点
(2)哈夫曼编码时从叶子走到根,译码时又从根走到叶子,因此每个结点需要增开双亲指针分量
//哈夫曼算法
typedef struct
{
unsigned int weight;//权值分量(可放大取整)
unsigned int parent,lchild,rchild;//双亲和孩子分量,指向双亲与左右孩子结点的位置指示域
}HTNode,*HuffmanTree;//HuffmanTree为动态数组名
typedef char**HuffmanTree;//动态数组存储HuffmanTree编码表(每个符合对应的01编码串)
//先构造哈夫曼树HT(引用型参数),再求出n个字符的编码HC(引用型参数)
void HuffmanCoding(HuffmanTree &HT,HuffmanTree &HT,HuffmanCode &HC,int *w,int n)//*w存放n个字符的权值,叶子个数n
//具体函数未给出
总结
这篇比较短小,附了很多图。
简要介绍线索二叉树,一些操作类似于二叉树。
关于树与二叉树的转换,有很多内容和方法,这里主要贴图,便于大家直观理解。
哈夫曼树,及最优二叉树。这里举了一点例子,附上图片和代码。
ps:代码非原创,如有错误,欢迎指正。
下一篇会讲到图的一些定义和基本算法。