【统计模拟及其R实现】蒙特卡罗 / 精度估计 / 对偶变量法 上机习题答案(超详细)
课本:统计模拟及其R实现 - 肖枝红,朱强 武汉大学出版社
目录
1. 蒙特卡洛模拟法
2. 精度估计:控制置信度和置信区间长度
3. 精度提升:对偶变量法
1. 蒙特卡洛模拟法
题目1:用模拟的方法近似计算下列积分,并和已知的精确答案进行比较
解:
使用蒙特卡洛模拟法进行模拟.
要计算![]()
则先做变换 ![]() ,
,![]()
得到 ![]()
其中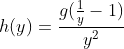
获得较为精确的值:
利用R的内嵌积分函数,如下
integrate(func,lower,upper)代码:
t1 = function(n) {
x = runif(n)
h = function(x) {
y = 1/(x+1)
g = function(x) x*((1+x^3)^(-4))
g(1/y - 1)/y^2
}
normal = sum(h(x))/n
accurate = integrate(h,0,1)
print(normal)
print(accurate)
}
t1(10000) # 模拟10000次题目2:对(0,1) 上的均匀随机变量U1, U2, U3, ... ,定义

即,N等于使其和超过1的随机数的个数,通过产生10000个N的值来估计 E[N],并猜测 E[N] 的理论值为多少?
解:
通过直接模拟的办法来生成10000个N的值,然后求其平均值,平均值即为估计的E[N],猜测理论值也为E[N].
代码:
t2 = function(t) {
x = matrix(0,nrow=t,ncol=t)
N = 0; N[2] = 0
for (i in 1:t) {
n = 1
repeat {
x[i,n] = runif(1)
if ( sum(x[i,]) > 1 ) {
N[i] = n
break
} else {n = n+1}
}
}
print(mean(N))
}
t2(10000)题目3:一个意外伤亡保险公司有1000个客户,每个客户独立地在下个月以概率0.05索赔,假设索赔量是独立的具有均值$800 指数随机变量,用模拟方法估计这些索赔量的和超过$50000的概率?
解:
① 先模拟一位客户单独的赔偿情况 - getCost()
② 将所有客户的情况汇总,形成一次总模拟 - oneSimu()
③ 将②模拟 n 次,计算其中索赔量的和超过$50000的概率 - t3(n)
代码:
# 模拟一位客户的赔偿
getCost = function() {
u = runif(1)
if (u < 0.05) {
cost = rexp(1,rate=1/800)
} else {
cost = 0
}
cost
}
# 模拟一次所有客户的赔偿,若超过50000则返回1,否则返回0
oneSimu = function() {
n = 1000; sum = 0
for (i in 1:n) {
cost = getCost()
if (cost > 0) {
sum = sum + cost
}
}
if (sum > 50000) {
result = 1
} else {
result = 0
}
result
}
# 做n次模拟,返回概率值
t3 = function(n) {
x = 0; x[2] = 0
for (i in 1:n) {
x[i] = oneSimu()
}
sum(x)/n
}
t3(10000)2. 精度估计:控制置信度和置信区间长度
题目1:在用随机投点法估计 pi 时,做多少次模拟才能获得一个长度小于0.1的区间,使之以95%的可能性包含 pi ?
解:
① 写一个随机模拟产生 pi 的程序
② 至少产生1个pi 的模拟数据
③ 连续地产生数据,直到数据的个数 k 满足 ![]() ,其中 l 为置信区间长度
,其中 l 为置信区间长度
④ 置信区间的上限为 ![]() ,下限为
,下限为 
代码:
getPi = function(n) {
k = 0; u1 = runif(n); u2 = runif(n)
x = 2*u1-1; y = 2*u2-1
for (i in 1:n) {
if (x[i]^2+y[i]^2<=1) {
k = k + 1
}
}
4*k/n
}
t4 = function(alpha, len) {
k = 1; n = 10000; x = 0; x[2] = 0
for (i in 1:k) {
x[i] = getPi(n)
}
while (2*qnorm(1-alpha/2)*sd(x)/sqrt(k) >= len) {
k = k + 1
x[k] = getPi(n)
}
totalTimes = k
upper = mean(x) - qnorm(1-alpha/2)*sd(x)/sqrt(k)
lower = mean(x) + qnorm(1-alpha/2)*sd(x)/sqrt(k)
result = mean(x)
print(totalTimes)
print(upper)
print(lower)
print(result)
}
t4(0.05,0.1)
题目2:为了估计theta,产生了20个相互独立的具有均值theta的随机数,其值如下:
102, 112, 131, 107, 114, 95, 133, 145, 139, 117,
93, 111, 124, 122, 136, 141, 119, 122, 151, 143
如果要确定theta的置信系数为0.99长度为1的theta最终估计量,另外还需要产生多少个随机数?
解:
仿照上一题中的步骤,但一开始不用产生新的数据,直接将已有数据输入即可.
代码:
t5 = function(alpha, len) {
k = 20
x = c(102, 112, 131, 107, 114, 95, 133, 145, 139, 117,
93, 111, 124, 122, 136, 141, 119, 122, 151, 143)
meanx = mean(x); sdx = sd(x)
while (2*qnorm(1-alpha/2)*sd(x)/sqrt(k) >= len) {
k = k + 1
x[k] = rnorm(1, mean=meanx, sd=sdx)
}
moreTimes = k - 20
upper = mean(x) - qnorm(1-alpha/2)*sd(x)/sqrt(k)
lower = mean(x) + qnorm(1-alpha/2)*sd(x)/sqrt(k)
result = mean(x)
print(moreTimes)
print(upper)
print(lower)
print(result)
}
t5(0.01,1)3. 精度提升:对偶变量法
题目:如何通过对偶变量法得到 ![]() 的一个模拟估计量?利用对偶变量法是否比独立地产生随机数更有效?并给出估计.
的一个模拟估计量?利用对偶变量法是否比独立地产生随机数更有效?并给出估计.
解:
普通法:直接模拟估计该定积分的值.
对偶变量法:使用均匀随机变量u1 u2估计一次,再使用(1-u1) (1-u2)估计一次,取两次估计结果的平均值.
代码:
f = function(x,y) exp((x+y)^2)
# 普通法估计
normal = function(n) {
u1 = runif(n); u2 = runif(n)
result = mean(f(u1,u2))
v = var(f(u1,u2))
print(result)
print(v)
}
avg = function(n) {
u1 = runif(n); u2 = runif(n)
u11 = 1-u1; u22 = 1-u2 # 构建对偶变量
result = (mean(f(u1,u2))+mean(f(u11,u22)))/2
v = var((f(u1,u2)+f(u11,u22))/2)
print(result)
print(v)
}
normal(10000)
avg(10000)结果:
> normal(10000)
[1] 4.887511 # 值
[1] 35.50393 # 方差
> avg(10000)
[1] 4.893464 # 值
[1] 11.75947 # 方差
后记
本人为零基础小白,努力学习中,发布的文章难免有错误及纰漏之处,欢迎各位看官批评指正!