UPSNet: A Unified Panoptic Segmentation Network 论文阅读
UPSNet: A Unified Panoptic Segmentation Network 论文阅读
- 简介
- 一、 引言
- 二、 相关工作
- 三、UPSNet
-
- 3.1UPSNet结构
- 3.2实施细节
- 四、实验结果
- 五、消融实验
- 五、结论
- 六、参考文献
论文链接:https://arxiv.org/abs/1901.03784?context=cs.CV
简介
文章提出UPSNet,一个统一的全景分割网络。以ResNet做基干,首先设计了一个基于可变形卷积的语义分割头和一个MaskR-CNN风格的实例分割头,同时解决了这两个子任务。文章还提出了parameter-free全景分割头,它应用了来自前两个分支的得分,并将特征扩展从而能够预测一个额外的未知类,这个未知类能更好地解决语义分割和实力分割之间的冲突。除此之外,它还处理了变化的实例数目带来的挑战,并实现了端到端。该网络在Cityscapes和COCO数据集上都进行了评估,达到了当时最优,并且预测速度很快。
一、 引言
语义分割和实力分割有相同之处,因此设计一个统一的表征是有益的,但是由于传统的语义分割和实力分割的实现结构差别很大,前者是基于fcn,后者则是普遍基于区域提议,因此,实现统一很难。
为了利用语义分割和实力分割之间的互补性,并且将分割更多的利用到实际应用中,文章[1]中统一了二者任务并提出了所谓的全景分割。其实在深度学习广泛应用之前,也已经有雷同全景分割的任务被研究,如图像解析[2],场景解析[2],全局场景理解[3]。
与之前使用独立的两个分支来完成全景分割和实例分割的方法[1][4]不同,文章使用了统一的基干网络,并在该基干上搭建两个分支同时完成两个任务。文章语义分支基于可变形卷积[5]搭建,使用了来自FPN[6]的多层多规模特征做输入,实例分支同Mask R-CNN[7]的设计,实验证明使用这两个轻量级头部与使用两个单独的网络达到的效果相当。更重要的是,文章还搭建了全景分割头,通过像素级的分类预测最终的全景分割图,其中的类别数目随着不同的图像有所改变,它利用来自上面两个分支的得分,并加入一个新的通道,该通道对应着一个额外的未知类,这能更好地解决语义分割和实例分割之间的矛盾。文章的parameter-free全景分割头是轻量级的,可以跟各种基干网络搭配使用。实现了端到端。
二、 相关工作
语义分割
由于上下文环境对语义分割的重要性,出现了空洞卷积[8][9],它带来了更大的感受野,且并无参数负担。金字塔场景解析网络(PSPNet)[10]就在其基干中使用了空洞卷积,它的实时应用变体[11]更是被广泛应用到实际应用中。基于FPN和PSPNet,一个多任务的架构在文章[12]中提出,并十分有效。
实例分割
大部分实例分割工作分为两个阶段,因此较慢,文章[13]提出了全卷积实例感知分割方法,除此之外还有Mask R-CNN。
全景分割
全景分割的基线方法[1]使用了两个独立的网络进行语义分割和实例分割,分别为PSPNet和Mask R-CNN,并使用启发式方法进行结果融合。近期,文章[4]提出一个弱半监督的全景分割方法,他们通过使用绑定框来监管事物类,通过使用图像级标记来监管事物类,从而减轻了GT约束。文章[14]提出了JSIS-Net,其使用一个统一的特征提取基干,并使用启发式方法进行结果融合,实现了统一的全景分割结构。文章[15]提出了一个注意力引导的统一网络(AUNet),利用了提议区域和mask级的注意力去更好地分割背景,与文章[1]中相同的预处理启发式方法被用在了生成最终的全景分割结果中。文章[16]提出things and stuff consistency network(TASCNet),该网络建立了一个能在things和stuff之间为每个像素进行二值掩膜预测的结构,还额外增加了一个loss来加强things和stuff预测间的一致性。
与上述大多数方式不同的是,文章使用了单一的基干网络为予以分割和实例分割提供特征,更重要的是,文章提出了一个简单的但是有效的全景分割头,能够准确的预测实例和类别。
三、UPSNet
文章在这部分介绍了文章模型并进而揭示了实施细节。用Nstuff和Nthing来代表stuff和thing类的个数。
3.1UPSNet结构
网络的整体结构如图1所示。

基干使用的是Mask R-CNN的基干,即resnet+fpn,实例分割头使用的也是Mask R-CNN的结构。
语义分割头
语义分割可以帮助提升实例分割的效果,文章使用基于变形卷积的语义分割网络头,以FPN的多层特征(P2-P5)为输入,这些特征首先各自经过相同的变形卷积进而被上采样到原图1/4大小,然后联合各个特征使用11卷积和softmax来预测语义类别,如图2所示。
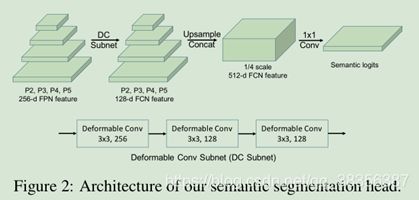
实验证明使用这种方法能达到与使用独立的PSPNet方法效果相当。使用常规的像素级交叉熵损失。为了更多的关注如行人等前景物体,文章还引进了ROI loss。在训练过程中,使用GT box来剪裁各个实例的语义得分图并将其resize到2828,这是根据Mask R-CNN来的。ROI loss即在28*28的批上进行的交叉熵计算,能帮助惩罚实例物体内的像素的错误分类。后续实验也证明了,引入ROI loss 能在不损害语义分割的情况下提升全景分割效果。
全景分割头
来自语义分割头的得分表示为X,它的尺寸为N stuff +N thing , H ,W,X可以从通道维度被分为Xstuff和Xthing,分别代表stuff和thing中各个类别的语义得分。对各个图像,在训练过程中,根据GT的实例个数决定实例个数Ninst,在预测过程中,文章依赖一个掩模修剪过程决定实例个数Ninst,Nstuff是固定的因为stuff类别个数固定。全景分割头旨在首先生成一个得分向量Z,它的尺寸是(N stuff +N inst )×H×W ,进而决定每个像素的类别和实例ID。
文章首先将Xstuff直接给了Z的前Nstuff个通道,来提供stuff得分。而对于任何一个实例i,文章有它的对应类别掩膜得分Yi,这来自于实例分割头,尺寸为2828,同时还有它的box Bi和类别ID Ci,在训练过程中,Bi和Ci来自GT,在预测过程中二者来自Mask R-CNN的预测,因此,文章可以通过在语义分割图中根据Bi的位置和Ci从Xthing对应Ci类的通道中取得对应特征,且只取框Bi中的值,框外的值置零,即从语义分割头获取第i个实例的另一个特征Xmaski,Xmaski的尺寸为HW。进而,将Yi双线性插值成跟Xmaski相同尺寸,对框Bi外的值同样置零,示意为Ymaski,最终的第i个实例的特征表示为Z N stuff +i = X mask i + Y mask i 。当对每个实例完成以上工作并得到ZNstuff+Nthing后,对其通道维度进行softmax操作,以预测像素级的类别。如果某像素处的各个通道中最大值处于前Nstuff层,则该像素为对应的stuff类,否则,则最大值对应的通道指示实例ID。全景分割头结构如图3所示。
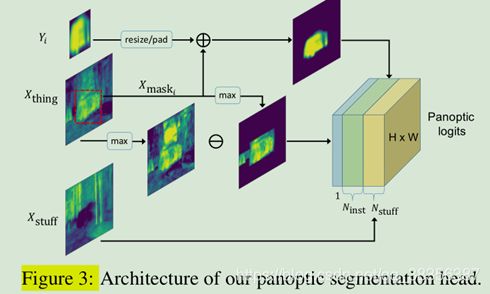
在训练过程中,文章根据用于建立全景得分的GT boxes来生成GT实例ID,全景分割头进而与标准像素级交叉熵损连接。
在预测过程中,文章根据上述方法预测好实例id后,仍需要确定每个实例的类别ID。这时,可以选择使用Mask R-CNN中预测的类别ID Cinst或者语义分割头预测的类别ID Csem,对于该处选择,文章利用了一个更好的启发式规则。具体地,对任何实例,文章可以知道哪些像素属于它,即在Z中,那些通道维度上的最大值对应的通道与该实例ID相对应的像素,都是属于该实例的。对这些像素,文章首先检查它们的Cinst和Csem是否都相同,如果是,文章按照Cinst的判断对该实例指派类别ID,否则,文章将计算这些像素的Csem的众数,表示为Csem。如果该众数所指类别在这些像素类别中所占的比例大于0.5,并且Csem属于stuff类,则将这些像素预测为C^sem类别,即不再是实例,否则,将这些像素分配类别为Cinst类别ID,即仍为实例。简而言之,当遇到语义分割和实例分割预测的不一致时,只有在语义分割头更多地指示该实例其实为stuff类时才相信语义分割头的最大决断。选择以这样的启发式方法解决该矛盾,是因为语义分割头往往在stuff类别上能够实现很好的分割结果。
未知预测
文章介绍了一个崭新的方法,该方法能够允许UPSNet将一个像素分类为未知类。而不是做一个错误的预测。即如果一个行人被预测为自行车,因为该预测错过了正确的行人类别,则行人的FN值会增加1,另一方面,自行车的FP会增加1。考虑到PQ的定义为:

可以看到FP和FN增大都会导致PQ下降,因此如果错误的预测是难免的,则将该像素预测为未知类别,则只会增加原本该类的FN,而不会升高其他某一类的FP。
为减轻这个问题,文章用Z unknown = max(X thing ) − max(X mask )来计算额外的未知类的得分,其中Xmask是对Xmaski的联合,在通道维度上,Xmask的尺寸为N inst ×H ×W,最大值从通道维度获取。这样做的背后原理是,对于任何像素,如果Xthing的最大值大于Xmask的最大值,则很大可能上是忽略了一些实例,造成了(FN),图3示意了得分的组成。为了给未知类生成GT,在训练过程中,文章随机采样了30%的GT掩膜并设置他们为未知。在评估这个机制时,任何属于未知累的像素被忽略,例如,设置它为无用,这不会对结果产生影响。
3.2实施细节
继承自Mask R-CNN的部分大多沿袭它的设置和超参数,只介绍不同的部分。
训练
Pytorch,16Gpus,分布式训练框架Horovod[17],图像预处理与Mask R-CNN相同,batchsize=1,前面提到,训练阶段文章使用GT box,mask和类别标签来建立全景分割头的得分,文章的区域提案网络(RPN)是端到端的连同基干训练,而它是在Mask R-CNN的实施中是单独训练的。由于Cityscapes的分辨率太高,语义分割头和全景分割头的得分被下采样到1/4大小,虽然没有对基干的BN进行微调,但仍然达到了与目前最优的语义分割网络如PSPNet相当的性能,根据经验,文章提出如果能对BN进行微调,性能还能上升。
文章的UPSNet网络包含8个loss:语义分割头(全图和ROI 像素级分类loss)、全景分割头(全图像素级分类loss)、RPN(框分类、框回归loss)和实例分割头(框分类、框回归、掩膜分割loss),对这些多任务loss的不同加权机制可能导致很不相同的训练结果。后续的实验找到了loss平衡策略,比如,确保所有loss的规模都大致相同。
预测
预测阶段,当从实例分割头得到boxes、masks和预测的类别标签之后,就可以进行掩膜修剪,以此来决定哪个掩膜将被用于构建全景得分(在预测过程中,文章依赖一个掩模修剪过程决定实例个数Ninst,)。特别的,首先执行类不可知的非极大值抑制,box的IoU阈值为0.5,以此过滤掉部分重叠box,接下来,将剩余的box的类别概率进行排序,并保留概率大于0.6的。对每一个类别,对于每个类,创建一个与图像大小相同的画布。然后,将该类别的masks进行插值到原本图像规模对应的box尺寸大小,进而,按照概率从大到小的顺序一个个地将mask贴到画布上。每复制一次mask,如果当前mask和已经存在于当前mask位置上的其他掩码之间的交集大于阈值,则丢弃它,否则,复制非交叉部分到画布上。文章将该阈值设置为0.3。在预测阶段,来自语义分割和全景分割头的得分与原图尺寸相同。
四、实验结果
由于RQ很敏感,文章将所有stuff类的分割中面积小于阈值的分类为未知类。在Cityscapes中为2048,在COCO中为4096。实验结果如下。
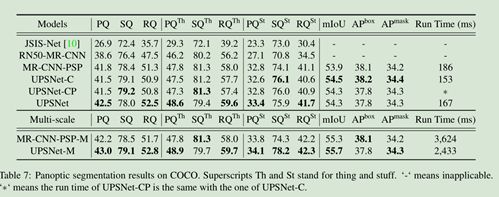


关于运行时间,对比如下。
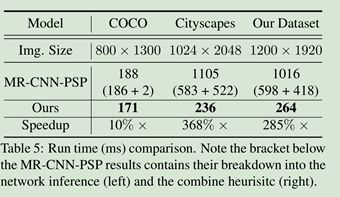
使用一个NVIDIA GeForce GTX 1080 Ti GPU 和一个 Intel Xeon E5-2687W CPU(3.00GHz)。结果是平均化后的,随着图片尺寸增大,文章模型在运行时间上更具优势。
五、消融实验
全景分割头
由于全景分割头是无参数的,可以当成一个简单的后处理,只对语义分割和实例分割进行训练后,在使用全景分割头进行预测,也可以对三个网络头同时训练,即也考虑全景分割的loss,从下表可见,对全景分割头的训练可以提高PQ
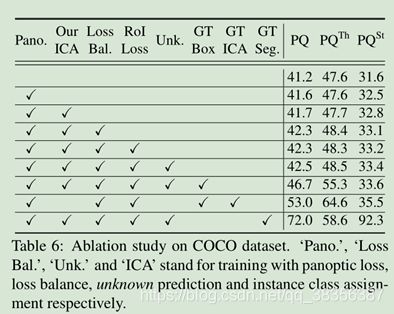
实例类别分配
还验证了不同的实例类别分配方法,对比了之前文中提到的启发式方法和直接以实例预测为准的方法,从上表中也可以看到启发式方法的有效性。
损失平衡
使用损失平衡可以提升效果
ROI损失和未知类预测
也能提升效果
除此之外,可以看到增加GTseg到预测中,也可以将PQth的值提升约10%。这是因为文章利用了语义分割辅助实例分割。
五、结论
文章提出了用于全景分割的统一的网络UPSNet,使用了统一的基干和轻量级的头部设计,更重要的是,文章的无参数全景分割网络头使用了上述两个网络头的得分并且预测了未知类。它解决了每个图片中变化的类别数量,并且实现了端到端的训练。在各个数据集上的实验结果表明文章模型实现了最佳效果并且与其他模型相比预测速度很快,未来,文章作者将探索更有力量的基干网络和更精明的全景分割头参数化。
六、参考文献
[1] A. Kirillov, K. He, R. Girshick, C. Rother, and P. Dollár.Panoptic segmentation. arXiv preprint arXiv:1801.00868,2018. 1, 2, 3, 4, 5, 6, 7, 8, 10, 11, 12, 13, 14, 15
[2] Z. Tu, X. Chen, A. L. Yuille, and S.-C. Zhu. Image parsing:Unifying segmentation, detection, and recognition. IJCV,63(2):113–140, 2005. 1
[3] J. Yao, S. Fidler, and R. Urtasun. Describing the scene asa whole: Joint object detection, scene classification and se-mantic segmentation. In CVPR, pages 702–709. IEEE, 2012.1
[4] Q. Li, A. Arnab, and P. H. Torr. Weakly-and semi-supervised panoptic segmentation. In ECCV, pages 102–118, 2018. 1,2, 6, 7, 12
[5] J. Dai, H. Qi, Y. Xiong, Y. Li, G. Zhang, H. Hu, and Y. Wei.Deformable convolutional networks. In ICCV, pages 764–773, 2017. 1, 3
[6] T.-Y. Lin, P. Dollár, R. B. Girshick, K. He, B. Hariharan, and S. J. Belongie. Feature pyramid networks for object detec-tion. In CVPR, volume 1, page 4, 2017. 1, 3
[7] K. He, G. Gkioxari, P. Dollár, and R. Girshick. Mask r-cnn. In ICCV, 2017. 1, 2, 3, 5
[8] F. Yu and V. Koltun. Multi-scale context aggregation by dilated convolutions. In ICLR, 2016. 2
[9] F. Yu, V. Koltun, and T. A. Funkhouser. Dilated residual networks. In CVPR, 2017. 2
[10] H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia. Pyramid scene parsing network. In CVPR, 2017. 1, 2, 5
[11] H. Zhao, J. Shi, X. Qi, X. Wang, and J. Jia. Pyramid scene parsing network. In CVPR, 2017. 1, 2, 5
[12] T. Xiao, Y. Liu, B. Zhou, Y. Jiang, and J. Sun. Unified perceptual parsing for scene understanding. In ECCV, 2018. 2
[13] Y. Li, H. Qi, J. Dai, X. Ji, and Y. Wei. Fully convolutional instance-aware semantic segmentation. In CVPR, 2017. 2
[14] D. de Geus, P. Meletis, and G. Dubbelman. Panoptic segmentation with a joint semantic and instance segmentation network. arXiv preprint arXiv:1809.02110, 2018. 2, 5, 6, 12
[15] Y. Li, X. Chen, Z. Zhu, L. Xie, G. Huang, D. Du, and X. Wang. Attention-guided unified network for panoptic segmentation. arXiv preprint arXiv:1812.03904, 2018. 2, 6
[16] J. Li, A. Raventos, A. Bhargava, T. Tagawa, and A. Gaidon. Learning to fuse things and stuff. arXiv preprint arXiv:1812.01192, 2018. 2, 6, 7
[17] A. Sergeev and M. D. Balso. Horovod: fast and easy distributed deep learning in TensorFlow. arXiv preprint arXiv:1802.05799, 2018. 5