机器学习——逃逸攻击
QQ 1274510382
Wechat JNZ_aming
商业联盟 QQ群538250800
技术搞事 QQ群599020441
解决方案 QQ群152889761
加入我们 QQ群649347320
共享学习 QQ群674240731
纪年科技aming
网络安全 ,深度学习,嵌入式,机器强化,生物智能,生命科学。
叮叮叮:产品已上线 —>关注 官方-微信公众号——济南纪年信息科技有限公司
民生项目:商城加盟/娱乐交友/创业商圈/外包兼职开发-项目发布/
安全项目:态势感知防御系统/内网巡查系统
云服项目:动态扩容云主机/域名/弹性存储-数据库-云盘/API-AIeverthing
产品咨询/服务售后(同)
纸上得来终觉浅,绝知此事要躬行 !!!
寻找志同道合伙伴创业中。。。抱团滴滴aming联系方式!!
机器自身的安全性问题
在模型预测过程中的逃逸攻击。
相关攻击技术、思想并通过代码实现,
然后会给出针对性的防御措施。
机器学习与网络安全 本科/专科信息安全专业
计算机网络、操作系统

1.逃逸攻击
逃逸攻击是指攻击者在不改变目标机器学习系统的情况下,
通过构造特定输入样本以完成欺骗目标系统的攻击。
例如,
攻击者可以修改一个恶意软件样本的非关键特征,
使得它被一个反病毒系统判定为良性样本,从而绕过检测。
攻击者为实施逃逸攻击而特意构造的样本通常被称为“对抗样本”。
只要一个机器学习模型没有完美地学到判别规则,
攻击者就有可能构造对抗样本用以欺骗机器学习系统。
如何将AI应用于网络安全领域,
那么AI自身是否会受到安全威胁呢?答案是肯定的。
AI模型的完整性
主要体现在模型的学习和预测过程完整不受干扰,输出结果符合模型的正常表现上。
这是研究人员能相信AI模型的输出结果的根本,也是AI模型最容易受到攻击的地方。
针对AI模型完整性发起的攻击通常称为“对抗攻击”。
对抗攻击通常分为两类,
一类是从模型入手的逃逸攻击,
一类是从数据入手的数据中毒攻击。
我们来学习逃逸攻击。
例如,
研究者一直试图在计算机上模仿人类视觉功能,
但由于人类视觉机理过于复杂,两个系统在判别物体时依赖的规则存在一定差异。
对抗图片恰好利用这些差异使得机器学习模型得出和人类视觉截然不同的结果,
如下所示,攻击者生成对抗样本使系统与人类有不同的判断

一个著名的逃逸样本是IanGoodfellow在2015年ICLR会议上用过的熊猫与长臂猿分类的例子。
被攻击目标是一个来自谷歌的深度学习研究系统。
该系统利用卷积神经元网络能够精确区分熊猫与长臂猿等图片。
但是攻击者可以对熊猫图片增加少量干扰,生成的图片对人来讲仍然可以清晰地判断为熊猫,但深度学习系统会误认为长臂猿。
下图显示了熊猫原图以及经过扰动生成后的图片

这其中的根本原因,在于模型没有学到完美的判别规则。
虽然图片识别系统一直试图在计算机上模仿人类视觉功能,
但由于人类视觉机理过于复杂,两个系统在判别物体时依赖的规则存在一定差异。
比如说我们可能是通过熊猫的黑眼圈,黑耳朵,黑手臂还有熊脸判断出它是一个熊猫
但图片识别系统可能只是根据它躺在树枝上的这个动作,就将其判断为了长臂猿。
因此完美的判别规则和模型实际学到的判别规则之间的差距,
就给了攻击者逃脱模型检测的可趁之机。
逃逸攻击目前已经受到了广泛的关注,
并被应用到了大量场景上,
如攻击自动驾驶汽车、物联网设备、语音识别系统等,可以说“哪里有AI,
哪里就有逃逸攻击”。
比如下面的例子

让自动驾驶汽车错误识别路边的标识。
在原停止标志图像(左边)中,停止标志可以被成功地检测到。
在中间图像,在整个图像中添加了小的干扰,停止标志不能被检测到。
在最后一个图像中,在停止标志的符号区域添加小的干扰,而不是在整个图像,
停止标志被检测成了一个花瓶。
再比如可以攻击语音识别系统
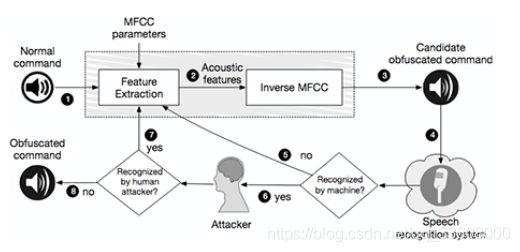
从正常命令倒推产生混淆的音频命令(如一段人类无法辨认的噪音),
从而在三星Galaxy S4以及iPhone 6上面被正确识别为相对应的语音命令,
变为让手机切换飞行模式、拨打911等。


我们不会做工作量这么大的工作,
我们将会以一个训练好的用于检测xss的waf模型为目标,
尝试构造对抗样本,逃过该模型的检测。

首先我们给出一个样本,使用模型检测并生成预测概率
之后我们将对模型进行分析,找到在我们希望发生错误分类的方向上权重最大的特征。
换句话说,我们找到某个特征,该特征可以导致模型对原始预测的confidence下降。
比如最开始模型判别为了1,为了实现逃逸攻击,我们希望能够让模型将样本判别为0,所以我们会迭代增加特征的大小,知道预测概率超过置信度阈值。
这里我们作为攻击者,
已经拿到了用于检测的模型waf/trained_waf_model,
并且可以访问序列化的scikit-learn的pipeline对象,
并可以检查模型pipeline中的每一阶段。
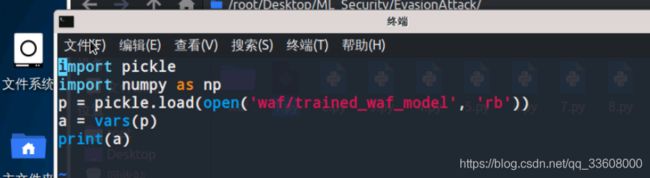
首先我们加载训练好的模型,
然后使用python内置的vars()查看pipeline包含的步骤:
通过python3 1.py测试
结果如下
可以看到pipeline对象有两个步骤,
一个是TfidfVectorizer,
一个是LogisticRegression分类器。
我们指定一个典型的xss的payload来测试一下模型是否起作用。
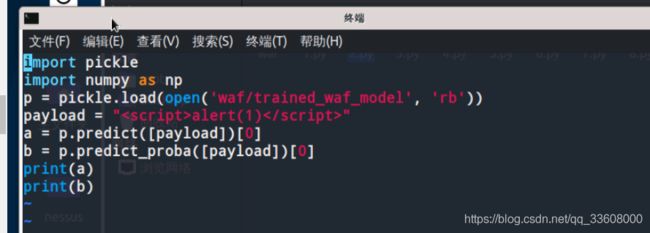
python3 2.py测试如下
从结果看出,模型成功将其预测为1,
也就是认为这个payload是属于xss攻击,
并且在第二行可以看到模型有0.99999998的置信度认为这个预测是对的。
确认模型是可以工作的,那么接下来就进入攻击阶段。
我们首先需要找到可以帮助最大化程度影响分类器的特定字符串token。
我们通过观察词汇表属性来检查的vectorizer的token词汇表
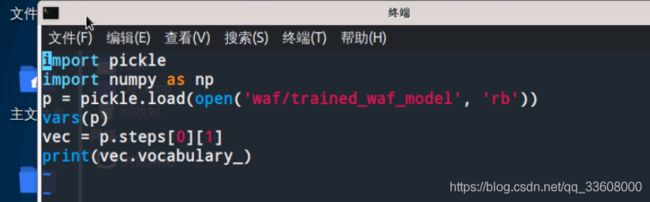
测试如下
从打印的结果中可以看到,
每个token都与一个特定的权重相关联,
这些权重会被作为单个文档的特征被喂给分类器。
经过训练的LogisticRegression分类器的系数可以通过coef_属性来访问。我们将这两个数组打印出来并尝试理解其意义。
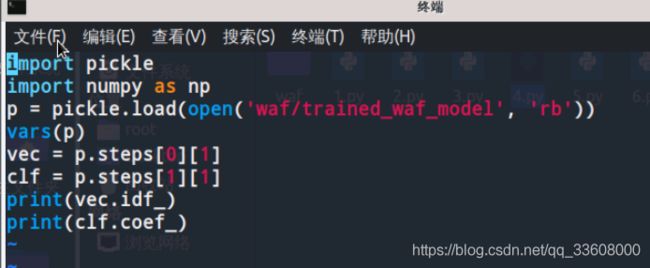
测试如下
TF-IDF(term frequency–inverse document frequency)
是一种用于信息检索与数据挖掘的常用加权技术。
TF是词频(Term Frequency),
IDF是逆文本频率指数(Inverse Document Frequency)。
结果分别打印了IDF每项的权重与LogisticRegression系数,
他们的乘积可以确定每个项对整体预测概率的影响程度。
我们在下面的代码中将其相乘并打印

测试如下
置信度 知乎

接下来我们根据置信度对每一项进行排序,
这里使用numpy.argpartition()进行排序并将值转为vec.idf_的索引,
这样我们就可以从vectorizer的token字典
(就是前面打印出的vec.vocabulary_)
中找到相应的token字符串了。然后将排序后的结果打印出来

结果如下
可以看到索引为81937处的token对预测的置信度有最大的正向影响
(positive influence,也就是是说出现这个字符串越多的话,
那么越有可能将对应的payload判定为0,即非xss攻击的payload),
那么我们从token字典中将对应这个索引的token提取出来
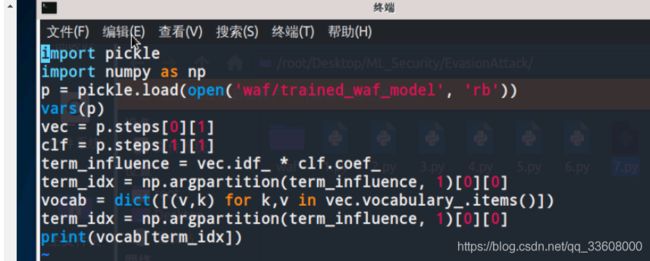
import pickle
import numpy as np
p = pickle.load(open('waf/trained_waf_model', 'rb'))
vars(p)
vec = p.steps[0][1]
clf = p.steps[1][1]
term_influence = vec.idf_ * clf.coef_
term_idx = np.argpartition(term_influence, 1)[0][0]
vocab = dict([(v,k) for k,v in vec.vocabulary_.items()])
term_idx = np.argpartition(term_influence, 1)[0][0]
print(vocab[term_idx])
测试如下

那么我们来看看是不是在前面测试过的payload中加上这个token会使得判别器将判为0
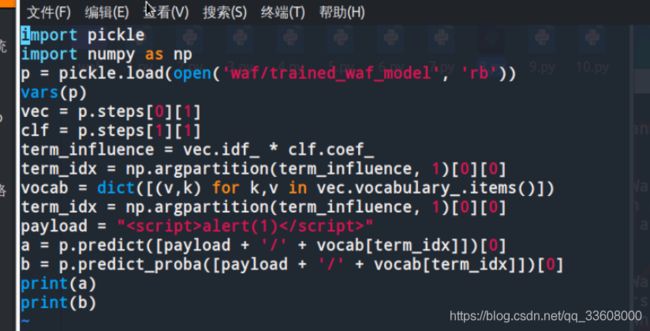
import pickle
import numpy as np
p = pickle.load(open('waf/trained_waf_model', 'rb'))
vars(p)
vec = p.steps[0][1]
clf = p.steps[1][1]
term_influence = vec.idf_ * clf.coef_
term_idx = np.argpartition(term_influence, 1)[0][0]
vocab = dict([(v,k) for k,v in vec.vocabulary_.items()])
term_idx = np.argpartition(term_influence, 1)[0][0]
payload = ""
a = p.predict([payload + '/' + vocab[term_idx]])[0]
b = p.predict_proba([payload + '/' + vocab[term_idx]])[0]
print(a)
print(b)
测试如下

从结果中我们可以看到,
模型还是将加上了“t/s”后的payload认为是xss攻击,
不过在第二行可以看到此时的判为xss的置信度为0.99999816,比之前的要低。
说明其实加上”t/s”后还是有效的,我们继续往payload里增加”t/s”
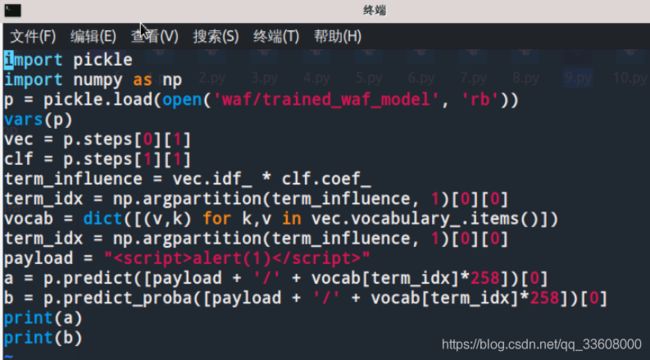
结果如下

可以看到此时将我们的payload加上了258次”t/s”后,
终于使得模型将其判别为0,即非xss攻击,从置信度也可以看到,
判为xss的置信度低于了0.5
我们可以进一步打印出此时的字符串
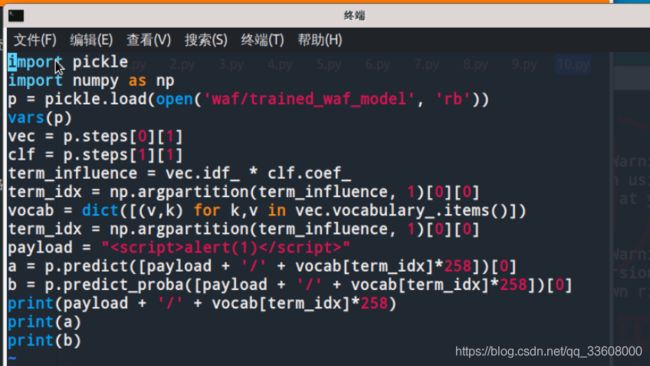
测试如下

此时的payload虽然有t/s,
但是我们人工去判断的话仍会认为这是一个有效的xss攻击,
换句话说,
这个payload确实有效,
但是逃逸了模型的检测,
这个payload就是我们前面提到的对抗样本。
防御措施
针对逃逸攻击的防御。
研究发现,对抗样本的对策有
两种主要类型的防御策略:
1)被动型,
即在构建完机器学习系统之后
检查对抗样本;
许多研究项目正在尝试在测试阶段检测对抗样本。
Metzen等人为对抗样本创建了一个检测器作为原始神经网络的辅助网络。
这个检测器是一个简单的小型神经网络,
用于对二元分类做预测,也即预测输入样本是对抗样本的概率。
SafetyNet提取每一个ReLU层的输出的二元阈值作为对抗检测器的特征,
并且使用RBF-SVM来检测对抗图像。

作者声称即便对手了解这个检测器,对手也很难击败此方法,
因为对攻击者来说,
为对抗样本和SafetyNet检测器的新特征找到一个最优值是困难的。
2)主动型,
在对手产生对抗样本之前使机器学习系统更加健壮。
Papernot等人使用网络净化来防御深度神经网络抵御对抗样本,
其背后的机理是作者发现攻击主要以网络的敏感度为目标,
使用高温度的softmax可以降低模型对小的扰动的敏感度,
进而达到对对抗样本的防御能力。
同时,作者还指出,网络净化可以增强神经网络的泛化能力。
Goodfellow等人和Huang等人在训练阶段引入了对抗样本,
即使用对抗样本来训练神经网络,
并证明了这种对抗训练可以增强深度神经网络的健壮性。
应用对抗样本的可转移特性,文献还提出了集成式的对抗训练方法,
使用来自不同源产生的对抗样本来训练模型,
这个源可以是正在训练的模型,也可以是先前训练过的外部模型。
AI与安全「2」
对深度学习的逃逸攻击
传送
《机器学习系统面临的安全攻击及其防御技术研究》