ROS学习——Ubuntu16.04 + ROS Kinetic下语音识别PocketSphinx功能包的安装和使用
1、前言
由于pocketsphinx只支持到Ubuntu14.04,ROS Kinetic不支持 sudo apt-get install ros-kinetic-pocketsphinx,所以在kinetic安装时比较麻烦一点。
2、安装依赖 ros-kinetic-audio-common
sudo apt-get install ros-kinetic-audio-common
3、安装依赖 libasound2
sudo apt-get install libasound2
4、安装依赖 libgstreamer0.10
sudo apt-get install gstreamer0.10-*
5、安装依赖 python-gst0.10
sudo apt-get install python-gst0.10
6、安装功能包 libsphinxbase1_0.8-6
下载链接:https://packages.debian.org/jessie/libsphinxbase1
sudo dpkg -i libsphinxbase1_0.8-6_amd64.deb
7、安装功能包 libpocketsphinx1_0.8-5
下载链接:https://packages.debian.org/jessie/libpocketsphinx1
sudo dpkg -i libpocketsphinx1_0.8-5_amd64.deb
8、安装功能包 gstreamer0.10-pocketsphinx
下载链接:https://packages.debian.org/jessie/gstreamer0.10-pocketsphinx
sudo dpkg -i gstreamer0.10-pocketsphinx_0.8-5_amd64.deb
9、进入工作空间目录,下载 pocketsphinx 功能包的源码并编译
cd ~/catkin_ws/src
git clone https://github.com/mikeferguson/pocketsphinx
cd ~/catkin_ws/
catkin_make
source devel/setup.bash
10、下载并安装英文语音包pocketsphinx-hmm-en-tidigits_0.8-5
下载链接:https://packages.debian.org/jessie/pocketsphinx-hmm-en-tidigits
sudo dpkg -i pocketsphinx-hmm-en-tidigits_0.8-5_all.deb
11、在 pocketsphinx 包里创建一个 model 目录,存放解压的语音模型文件
cd ~/catkin_ws/src/pocketsphinx
mkdir model
sudo cp /usr/share/pocketsphinx/model/* ~/catkin_ws/src/pocketsphinx/model -r
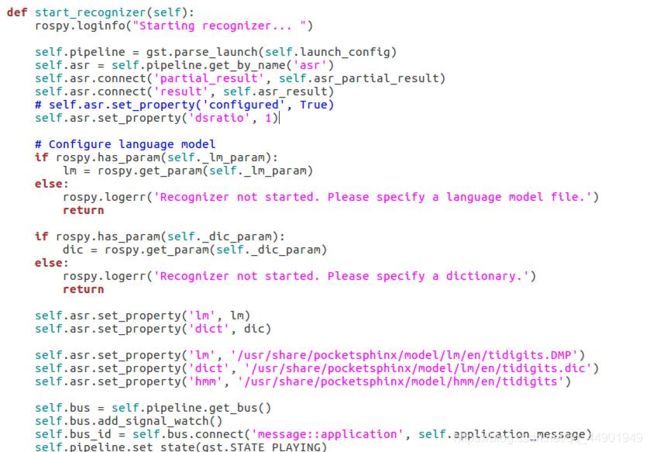
12、修改 recognizer.py 文件 cd ~/catkin_ws/src/pocketsphinx/nodes
(1)注释掉 self.asr.set_property(‘configured’, True)
(2)添加lm,dict,hmm支持英语识别(如果是其他语言可以改为别的路径)
self.asr.set_property('lm', '/usr/share/pocketsphinx/model/lm/en/tidigits.DMP')
self.asr.set_property('dict', '/usr/share/pocketsphinx/model/lm/en/tidigits.dic')
self.asr.set_property('hmm', '/usr/share/pocketsphinx/model/hmm/en/tidigits')
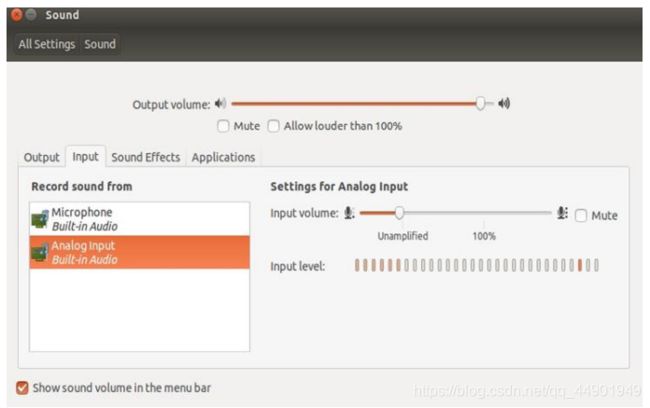
13、检查麦克风是否接入,并在系统设置里进行测试,确保麦克风里有语音输入
14、测试 pocketsphinx 的语音识别功能
(1)在终端启动 launch 文件
roslaunch pocketsphinx robocup.launch
(2)说一些简单的语句(如果使用英文库,说一些数字;如果使用普通话库,说一些中文)
(3)通过 rostopic echo 查看识别的结果,即ros发布的结果消息
rostopic echo /recognizer/output
15 、下载中文普通话包进行测试
pocketsphinx-hmm-zh-tdt
pocketsphinx-lm-zh-hans-gigatdt