Oracle总结一
表结构
表命名
表的命名应该遵循公司相关的规范,如无特别要求也应该做到以下:
- 必须以字母开头 ,命名尽可能简洁。
- 长度不能超过30个字符
- 只能包含26个字母( A–Z, a–z 0–9, _, $, and #
- 不能与数据库中的已有对象重名
- 不能使用Oracle 数据库的保留字
- 表名应该做到见名知意,例如汉得员工表可以命名为 TB_HAND_EMPLOYEES
- 可使用大写命名方式如 TB_HAND_EMPLOYEES
常用字段类型
| VARCHAR2(size) | 可变长字符串 |
|---|---|
| CHAR(size) | 定长字符串 |
| NUMBER(p,s) | 可变长数值 |
| DATE | 日期时间 |
| LONG | (可变长)大字符串,最大可到2G |
| CLOB | (可变长)大字符串数据,最大可到4G |
| RAW and LONG RAW | 二进制数据 |
| BLOB | 大二进制数据,最大可到4G |
| BFILE | 存储于外部文件的二进制数据,最大可到4G |
| ROWID | 64进制18位长度的数据,用以标识行的地址 |
| TIMESTAMP | 精确到分秒级的日期类型(9i以后提供的增强数据类型) |
| INTERVAL YEAR TO MONTH | 表示几年几个月的间隔(9i以后提供的增强数据类型-极其少见) |
| INTERVAL DAY TO SECOND | 表示几天几小时几分几秒的间隔(9i以后提供的增强数据类型-极其 少见) |
创建表(脚本方式)
例:
CREATE TABLE TB_TWG_INFO(
id varchar2(10 char) NOT NULL,
join_date TIMESTAMP WITH LOCAL TIME ZONE,
name varchar2(12 char) NOT NULL,
status number(11) DEFAULT 13458897988 NOT NULL);
语法:([]为可选参数)
CREATE TABLE 表名(
字段名1 类型(类型限定) [条件指定]
字段名2 类型(类型限定) [条件指定]
字段名2 类型(类型限定) [条件指定],
字段名2 类型(类型限定) [条件指定],
添加注释:([]为可选参数)
comment on column is '主键';
comment on column table_name.text is '说明';
comment on column table_name.status is '状态';
添加字段
例:ALTER TABLE TB_TWG_INFO ADD inint_date DATE;
ALTER TABLE 待添加表名 ADD 待添加字段 类型(类型限定)[条件指定];
修改字段类型限定
例:ALTER TABLE TB_TWG_INFO modify(NAME varchar2(16));
ALTER TABLE 表名 modify(待修改字段名 类型(类型限定));
删除字段
例:ALTER TABLE TB_TWG_INFO DROP COLUMN ININT_DATE;
ALTER TABLE 表名 DROP COLUMN 对应表中待删除的字段;
修改字段名
例:ALTER TABLE TB_TWG_INFO RENAME COLUMN NAME to MYNAME;
ALTER TABLE 表名 RENAME COLUMN 老字段 to 新字段;
修改表名
例:RENAME TB_TWG_INFO TO TB_INFO_TWG;
RENAME 旧表名 TO 新表名;
删除表
-- 没有事务回滚TRUNCATE TABLE 表名;-- 有事务回滚DELETE FROM 表名;
约束
查看指定表约束
SELECT constraint_name, constraint_type FROM SYS.USER_CONSTRAINTS WHERE TABLE_NAME = '指定查询的表名'
给指定表添加约束
CHECK自定义约束
例:ALTER TABLE TB_TEST ADD CONSTRAINT TB_TEST_SELFDEFINE_PK CHECK('NAME' IS NOT NULL) --语法 ALTER TABLE 需要添加约束的表名 ADD CONSTRAINT 约束名 CHECK('字段' 条件)
主键约束
例:ALTER TABLE TB_JOB ADD CONSTRAINT TB_JOB_JOBID_PK PRIMARY KEY(JOB_ID);--语法 ALTER TABLE 表名 ADD CONSTRAINT 约束名 PRIMARY KEY(待添加字段名);
唯一约束
例:ALTER TABLE TB_JOB ADD CONSTRAINT UNIQUE_PK_JOBTITLE UNIQUE(JOB_TITLE); --语法 ALTER TABLE 表名 ADD CONSTRAINT 约束名 UNIQUE(待约束字段);
非空约束
例:ALTER TABLE TB_EMPLOYEES MODIFY PHONE_NUMBER CONSTRAINT NOT_NULL_PK_PN NOT NULL; --语法 ALTER TABLE 待修改表名 MODIFY 待修改字段 CONSTRAINT 约束名 NOT NULL;
外键约束
例:ALTER TABLE TB_EMPLOYEES ADD CONSTRAINT TBJ_TBE_FK FOREIGN KEY(JOB_ID) REFERENCES TB_JOB(JOB_ID); --语法 ALTER TABLE 表名 ADD CONSTRAINT 外键约束名 FOREIGN KEY(外键约束字段) REFERENCES 待关联表名(外键待约束关联字段);
注意:这里添加外键约束时可能报错,解决的办法就是给一张表此字段为主键的设置一个主键约束即可
删除约束
例:ALTER TABLE TB_TEST DROP CONSTRAINT TB_TEST_SELFDEFINE_PK; --语法 ALTER TABLE 表名 DROP CONSTRAINT 约束名;
禁用启用约束
例:ALTER TABLE TB_JOB disable constraint SYS_C0011476; --语法 ALTER TABLE 待禁用约束的表名 disable constraint 约束名;
DML(CUD)
INSERT
1.字段值对应
(可添加指定字段值且顺序可以任意调换)
例:INSERT INTO TB_INFO_TWG (ID,STATUS,JOIN_DATE,MYNAME)VALUES('TWG_CAPSA',15870345879,TO_DATE('2021-07-31 10:04:34','yyyy-mm-dd HH24:MI:SS'),'OldBaby+')--语法INSERT INTO 待插入的表 ([字段1],[字段2],....,[字段n])VALUES('[值1]',[值2],.....[值n])
2. 没有对应字段指定
(系统默认全部添加,且顺序不能改变应该和对应字段顺序相同)
例:INSERT INTO TB_INFO_TWG VALUES('TWG_CAPSA',TO_DATE('2021-07-31 10:04:34','yyyy-mm-dd HH24:MI:SS'),'OldBaby+',15870345879,TO_DATE('1997-04-30','yyyy-mm-dd'))--语法INSERT INTO 待插入的表VALUES('[值1]',[值2],.....[值n])
3.复制插入
(将一个表的数据复制到当前,要求字段类型相同)
--语法INSERT INTO 表名(字段1,字段2,....) SELECT 值1,值2 FROM 表名 WHERE 条件
**注意:**在Oracle里面日期格式需要使用特定的函数进行转化例如TO_DATE(‘2021-07-31 10:04:34’,‘yyyy-mm-dd HH24:MI:SS’)
DELETE
例:DELETE FROM TB_INFO_TWG WHERE ININT_DATE IS NULL --语法DELETE FROM 表名称 WHERE 条件
**注意:**如果删除不带有where条件那么默认就会删除整张表的数据
UPDATE
例:UPDATE TB_INFO_TWG SET MYNAME='What your name?', STATUS=18234023456 WHERE ID = 'TWG_CAPSA' --语法 UPDATE 待更新表名 SET 待更新字段1=值1, 待更新字段2=值2.... WHERE 条件
**注意:**如果更新不带有where条件那么默认就会更新整张表的数据
视图
理解
视图(View)实际上是一张或者多张表上的预定义查询,这些表称为基表,而查询出来的视图又称之为虚表,不会占用内存空间。(简单来说就是不占空间的临时表)从视图中查询信息与从表中查询信息的方法完全相同。当要想创建视图的时候必须得有权限,没有权限无法创建视图。
注意
更改视图的数据也会同时更改表的数据,同理更改了表的数据,视图也会同步修改,所以一般不直接对视图数据进行更改,只有视图为单张表的时候才进行修改。可以把视图简单的理解为查询了多张表的数据,然后进行临时数据处理。
语法
([ ]是可选参数)
CREATE [OR REPLACE] [FORCE/NOFORCE] VIEW 视图名 [(视图名1,视图名2......)] ASSELECT查询语句[WITH READ ONLY]--参数说明--1. OR REPLACE:如果视图已经存在,则更新原有视图。--2. FORCE:预定义视图,如果基表不存也可创建视图,但是无法使用视图,只有创建了基表后该视图才可以继续使用--3. NOFORCE:如果基表不存在,无法创建视图--4. WITH READ ONLY: 只能对视图进行查询无法CUD
创建视图
– 简单视图
不含有复杂的函数等,就一张表的操作
– 复杂视图
含有函数、多张表等的复杂查询视图(如下就是一个复杂视图)
例:CREATE OR REPLACE VIEW VIEW_TWGUNION (name,minsal,maxsal,avgsal) ASSELECT d.department_name, MIN(e.salary), MAX(e.salary), AVG(e.salary)FROM employees e,departments dWHERE e.department_id = d.department_idGROUP BY d.department_name;
删除视图
CASCADE CONSTRAINT :如果视图有任何约束,则必须指定CASCADE CONSTRAINT子句以删除引用视图中的主键和唯一键的所有参照完整性约束。如果不这样做,存在这样的约束时,DROP VIEW语句将会失败。
DROP VIEW 视图名[CASCADE CONSTRAINT];
查询所有视图
可以在查询出的所有视图中找到列名为OWNER的查看视图所属的数据库
例:select * from all_views t WHERE VIEW_NAME LIKE '%VIEW_A%'--语法select * from all_views t WHERE 条件
索引
理解
专业术语来讲是一种加快查询效率的存储结构。简单来讲就是类似于目录,能快速查询数据的一类文件。
什么样的数据字段建立能够加快查询的效率。
- 查询的这个字段数据量超过了整表数据量的4%;
- 表的主键、外键必须有索引;
- 数据量超过300的表应该有索引;
- 经常与其他表进行连接的表,在连接字段上应该建立索引;
- 经常出现在Where子句中的字段,特别是大表的字段,应该建立索引;
- 索引应该建在选择性高的字段上;
索引的类型
索引的CRUD
索引的类型及创建方式
--b-tree b树索引(默认索引)CREATE INDEX 索引名 ON 表名(列名1,列名2......)--bitmap 位图索引CREATE bitmap INDEX 索引名 ON 表名(列名1,列名2......)--reverse 反转索引CREATE bitmap INDEX 索引名 ON 表名(列名1,列名2......) reverse--基于函数的索引CREATE INDEX 索引名 ON 表名(函数名(列名1) ,函数名(列名2).....)
添加索引
-- 指定索引类型CREATE 索引类型 INDEX 索引名 ON 表名(列名1,列名2,......);-- 这种是默认B-TREE索引CREATE INDEX 索引名 ON 表名(列名1,列名2,......);
查询索引
--查询表中所有的索引SELECT * FROM ALL_INDEXES WHERE TABLE_NAME = '表名'--查询表中建立索引的列SELECT * FROM SYS.ALL_IND_COLUMNS WHERE TABLE_NAME ='表名'
删除索引
DROP INDEX 索引名;
事务
理解
专业术语:
事务是数据库管理系统执行过程中的一个逻辑单位,由一个有限的数据库操作序列构成。事物的操作要么完全地执行,要么完全地不执行
简单的说
就是为了保证数据一致性的控制单位。
转账举例
kevin 要给 willian 进行银行转账100元。在这个过程中发生了四件事
1、》kevin 账户要减少100
2、》willian的账户增加100
3、》转账的数据要保存并且进行记录
由以上可以看出任何一个环节出现了问题都会导致数据不正确,所以三条语句要么都执行要么都不执行才能保证正确性,理论上kevin的账户需要减少100执行后就应该减少100,所以要保证一致性,当前转账业务不会影响viena和jone的转账所以具有隔离性,转账完成后两个的账户都要实际发生改变满足持久性。
四大特性
ACID
-
原子性(Atomicity):
所有包含在事务控制之内的语句不可分割出来,要么都执行,要么都不执行
-
一致性(Consistency):
事务执行前后的数据要和理论上保持一致
-
隔离性(isolation):
各个事务之间互相隔离,独立执行,互不影响
-
持久性(durability):
事务执行后需要持久化到数据文件或磁盘,保证数据持久
三读的理解
脏读
当一个事务读取到另一个事务还没commit的数据时就会发生脏读例如A修改了一行数据,然后 B在 A还未提交事务操作之前读取了被修改的那行数据。如果A进行了回滚(也就是没提交事务),那么B读取的数据就是根本不存在的数据。
虚读(幻读)
举例来说就是A进行数据读取,当前行的数据是123,A本来该读取到123。现在B对这样数据进行了更改为456,结果A重新执行查询时发现数据是456,然后B又撤销操作结果A本该两次读到123却出现了一条为456的虚数据
不可重复读
在一个事务内,多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改,那么第一个事务两次读到的的数据可能是不一样的。这样在一个事务内两次读到的数据是不一样的,因此称为是不可重复读。
事务的隔离级别
-
Read Uncommitted(读未提交)
一个事务修改数据后即使未提交,其他事务也可以读取到该事务修改后未被提交的数据,所以这个级别的隔离机制无法解决脏读、不可重复读、幻读中的任何一种
-
Read Committed (读已提交)(ORACLE中提供)
一个事务能够读取到那些其他事务已经提交的数据,能够防止脏读,但是无法解决不可重复读和幻读的问题
-
Repeatable Read(重复读)
事务在数据读取出来后就对该数据加锁,防止别人修改他,即读取了一条数据,当前加锁的这个事务不结束,别的事务也不能修改这条记录,能够解决脏读、不可重复读的问题,但是幻读依旧解决不了
-
Serializable(串行化)(ORACLE中提供)
最高级别的事务隔离级别,不管拥有多少事务,只有执行完一个完整的事务后才能执行下一个事务,这样能够避免脏读、不可重复读、幻读的问题
-
Read-Only(只读)(ORACLE中提供)
遵从事务级的读一致性,仅仅能看见在本事务开始前由其它事务提交的更改。
不允许在本事务中进行DML操作
事务的操作(Oracle)
设置事务隔离级别
--设置读已提交SET TRANSACTION ISOLATION LEVEL READ COMMITTED;--设置串行化读SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;--设置只读SET TRANSACTION READ ONLY;
锁
以下部分来自于:https://blog.csdn.net/czh500/article/details/89077168
理解
锁的作用就是为了防止并发事务对相同的资源进行更改造成数据前后不一致。
Oracle中的锁分类
- DML lock(data locks,****数据锁****):用于保护数据的完整性。
- DDL lock(dictionary locks,****字典锁****):用于保护数据库对象的结构(例如表、视图、索引的结构定义)。
- Internal locks 和latches(****内部锁与闩****):保护内部数据库结构。
- Distributed locks(****分布式锁****):用于OPS(并行服务器)中。
- PCM locks(****并行高速缓存管理锁****):用于OPS(并行服务器)中。
Oracle中的主要锁
Oracle中最主要的锁是DML锁,DML锁的目的在于保证并发情况下的数据完整性。在Oracle数据库中,DML锁主要包括TM锁和TX锁,其中TM锁称为表级锁,TX锁称为事务锁或行级锁
共享锁(S锁)
可通过lock table in share mode命令添加该S锁。在该锁定模式下,不允许任何用户更新表。但是允许其他用户发出select …from for update命令对表添加RS锁。
排他锁(X锁)
可通过lock table in exclusive mode命令添加X锁。在该锁定模式下,其他用户不能对表进行任何的DML和DDL操作,该表上只能进行DQL。
行级共享锁(RS锁)
通常是通过select … from for update语句添加的,同时该方法也是我们用来手工锁定某些记录的主要方法。比如,当我们在查询某些记录的过程中,不希望其他用户对查询的记录进行更新操作,则可以发出这样的语句。当数据使用完毕以后,直接发出rollback命令将锁定解除。当表上添加了RS锁定以后,不允许其他事务对相同的表添加排他锁,但是允许其他的事务通过DML语句或lock命令锁定相同表里的其他数据行。
行级排他锁(RX锁)
当进行DML操作时会自动在被更新的表上添加RX锁,或者也可以通过执行lock命令显式的在表上添加RX锁。在该锁定模式下,允许其他的事务通过DML语句修改相同表里的其他数据行,或通过lock命令对相同表添加RX锁定,但是不允许其他事务对相同的表添加排他锁(X锁)。
共享行级排他锁(SRX锁)
通过lock table in share row exclusive mode命令添加SRX锁。该锁定模式比行级排他锁和共享锁的级别都要高,这时不能对相同的表进行DML操作,也不能添加共享锁。
锁管理
基本上所有的锁都可以由Oracle内部自动创建和释放,但是其中的DDL和DML锁是可以通过命令进行管理的
语法如下:
LOCK table_name IN [row share][row exclusive][share][share row exclusive][exclusive] MODE [NOWAIT];
锁定模式下的SQL
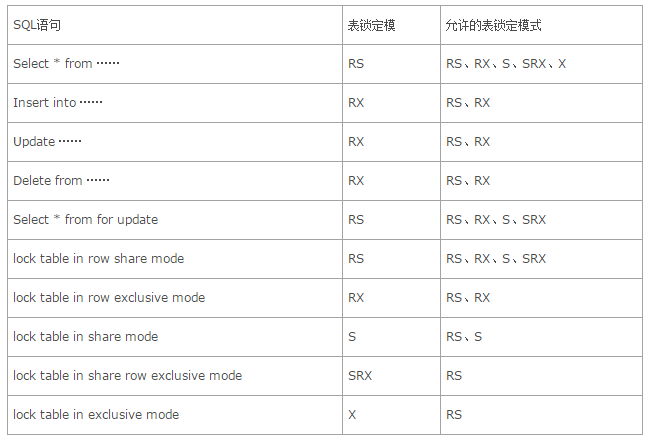
解锁
当程序对所做的修改进行提交(Commit)或回滚(Rollback)后,锁住的资源便会得到释放,从而允许其他用户进行操作。如果两个事务,分别锁定一部分数据,而都在等待对方释放锁才能完成事务操作,这种情况下就会发生死锁。