LinkedList源码笔记 --- 普通增删查改
LinkedList源码笔记 — 普通增删查改
这次先看一下类关系图:
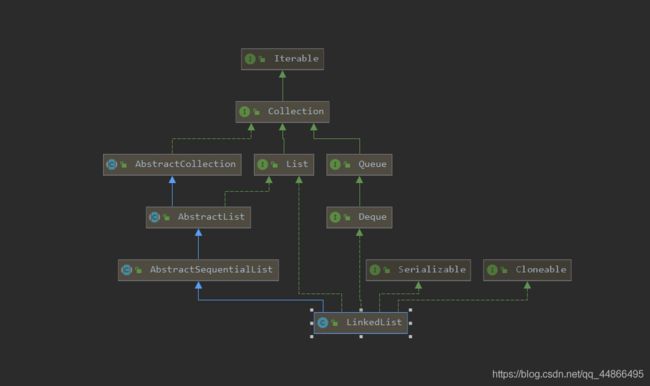
嗯就是这样,这货不止是List的实现类,而且也是Queue的实现类。
特此说明下:Queue: 基本上,一个队列就是一个先入先出(FIFO)的数据结构
再看看类介绍(这里偷懒了一下看看JDK1.8帮助文档):
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, Serializable双链表实现了List和Deque接口。 实现所有可选列表操作,并允许所有元素(包括null )。
所有的操作都能像双向列表一样预期。 索引到列表中的操作将从开始或结束遍历列表,以更接近指定的索引为准。
请注意,此实现不同步。 如果多个线程同时访问链接列表,并且至少有一个线程在结构上修改列表,则必须在外部进行同步。 (结构修改是添加或删除一个或多个元素的任何操作;仅设置元素的值不是结构修改。)这通常通过在自然封装列表的对象上进行同步来实现。 如果没有这样的对象存在,列表应该使用Collections.synchronizedList方法“包装”。 这最好在创建时完成,以防止意外的不同步访问列表:
List list = Collections.synchronizedList(new LinkedList(...)); 这个类的iterator和listIterator方法返回的迭代器是故障快速的 :如果列表在迭代器创建之后的任何时间被结构化地修改,除了通过迭代器自己的remove或add方法之外,迭代器将会抛出一个ConcurrentModificationException 。 因此,面对并发修改,迭代器将快速而干净地失败,而不是在未来未确定的时间冒着任意的非确定性行为。
请注意,迭代器的故障快速行为无法保证,因为一般来说,在不同步并发修改的情况下,无法做出任何硬性保证。 失败快速迭代器尽力投入ConcurrentModificationException 。 因此,编写依赖于此异常的程序的正确性将是错误的:迭代器的故障快速行为应仅用于检测错误。
这个班是Java Collections Framework的会员 。
从这里了解到这玩意是一个双向列表结构,
这篇双向列表的博客挺不错的,可以看看这一篇:https://blog.csdn.net/qq_41028985/article/details/84495300
需要java数据结构预算法的PDF的加我V:17704065506 (记得备注:java数据结构预算法,不然我会把你当顾客处理的)
构造
别的不多说直接干代码:
List list = new LinkedList<>();
先上一个空参构造方法,看看玩意有啥妖魔鬼怪,
/**
* Constructs an empty list. 构造一个空列表。
*/
public LinkedList() {
}
好家伙啥都没干:
增
接着添加一个元素:
List list = new LinkedList<>();
list.add(1);
添加永远是重头戏:
/**
* Appends the specified element to the end of this list.
将指定的元素追加到此列表的末尾。
*
* This method is equivalent to {@link #addLast}.
*
* @param e element to be appended to this list
* @return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
//看看这个方法先 [linkLast]
linkLast(e);
return true;
}
/**
* Links e as last element. 链接e作为最后一个元素。
*/
void linkLast(E e) {
//获取最后一个元素 先去看看 [Node 这个内部类]
final Node<E> l = last;
//创建一个新的Node (每一个添加的元素都是一个一个的Node)
final Node<E> newNode = new Node<>(l, e, null);
//将新添加的NODE记录为最后一个NODE
last = newNode;
//如果是第一个添加的元素则
if (l == null)
//把它记录为第一个元素 [first]
first = newNode;
else //不是则
//添加在链表的末尾
l.next = newNode;
//这两个是啥看成员变量
//集合元素个数+1
size++;
// 此列表已被结构修改的次数 加1
modCount++;
}
改
接着在来看看修改,废话不多少直接干代码:
List list = new LinkedList<>();
list.add(1);
list.set(0,2);
看看set方法
/**
* Replaces the element at the specified position in this list with the
* specified element.
用指定的元素替换此列表中指定位置的元素。
*
* @param index index of the element to replace
* @param element element to be stored at the specified position
* @return the element previously at the specified position
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E set(int index, E element) {
//检测这个集合是否拥有该索引
checkElementIndex(index);
//找到索引对应的节点
Node<E> x = node(index);
//获取当前节点存的值
E oldVal = x.item;
//赋值新值
x.item = element;
//返回旧值
return oldVal;
}
/**
*这个方法主要是检测这个集合是否拥有该索引
*/
private void checkElementIndex(int index) {
if (!isElementIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
/**
* Tells if the argument is the index of an existing element.
指示参数是否是现有元素的索引。
*/
private boolean isElementIndex(int index) {
return index >= 0 && index < size;
}
/**
* Returns the (non-null) Node at the specified element index.
返回指定元素索引处的(非空)节点。
*/
Node<E> node(int index) {
// assert isElementIndex(index);
//这里妙呀
//如果当前需要检索的索引小于集合长度的一半 则从第一个节点开始检索,如果不是则从最后一个索引开始检索
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
查
在来看看查找:
List list = new LinkedList<>();
list.add(1);
list.set(0,2);
System.out.println(list.get(0));
进源码:
/**
* Returns the element at the specified position in this list.返回此列表中指定位置的元素。
*
* @param index index of the element to return
* @return the element at the specified position in this list
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E get(int index) {
//是不是很熟悉 就是修改检索的两个方法 这里去看一下修改那一块就知道了
checkElementIndex(index);
return node(index).item;
}
删
最后在来看看删除操作:
List list = new LinkedList<>();
list.add(1);
list.add(2);
list.set(0,2);
System.out.println(list.get(0));
list.remove(0);
list.stream().forEach(System.out::println);
接着上代码:
/**
* Removes the element at the specified position in this list. Shifts any
* subsequent elements to the left (subtracts one from their indices).
* Returns the element that was removed from the list.
删除该列表中指定位置的元素。
*
* @param index the index of the element to be removed
* @return the element previously at the specified position
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E remove(int index) {
//这里就不说了 修改那里说了 检索索引是否存在
checkElementIndex(index);
//node(index)这里上面也说了,检索并且拿到当前索引值
//unlink这个方法就是移除当前索引,并且返回移除的值
return unlink(node(index));
}
/**
* Unlinks non-null node x. 移除当前索引,并且返回移除的值
*/
E unlink(Node<E> x) {
// assert x != null;
//拿到当前节点值 上一个节点 还有下一个节点
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
//如果是第一个节点
if (prev == null) {
first = next;
} else {
//如果不是第一节点则,将下一个节点赋值给前一个节点的下一个节点,并清除此节点的上一个节点
prev.next = next;
x.prev = null;
}
//判断当前节点是否是最后一个节点,如果是将它的上一个节点最为最后一个节点
if (next == null) {
last = prev;
} else {
//如果不是则把当前节点的前一个节点赋值给下一个节点的前一个节点并把下一个
next.prev = prev;
x.next = null;
}
//把当前节点的值设为空
x.item = null;
//集合元素数量 -1
size--;
//操作次数 +1
modCount++;
//返回旧的值
return element;
}
成员变量:
/**
* Pointer to last node. 指向最后一个节点的指针。 这里是做最后一个指针的记录
* Invariant: (first == null && last == null) ||
* (last.next == null && last.item != null)
*/
transient Node<E> last;
/**
* Pointer to first node. 指向第一个节点的指针。
* Invariant: (first == null && last == null) ||
* (first.prev == null && first.item != null)
*/
transient Node<E> first;
/**
* 这个没有注释,据猜测应该是集合元素数量
*/
transient int size = 0;
/**
此列表已被结构修改的次数。 结构修改是改变列表大小的那些修改,或以其他方式扰乱它,使得正在进行的迭代可能产生不正确的结果。
该字段由迭代器和列表迭代器实现使用,由iterator和listIterator方法返回。 如果该字段的值意外更改,迭代器(或列表迭代器)将抛出一个ConcurrentModificationException响应next , remove , previous , set或add操作。 这提供了故障快速行为,而不是面对在迭代期间的并发修改的非确定性行为。
子类使用此字段是可选的。 如果一个子类希望提供故障快速迭代器(和列表迭代器),那么它只需要在其add(int, E)和remove(int)方法(以及它覆盖的任何其他方法导致对列表的结构修改)中增加该字段。 对add(int, E)或remove(int)单一调用必须向该字段添加不超过一个,否则迭代器(和列表迭代器)将抛出伪造的ConcurrentModificationExceptions 。 如果实现不希望提供故障快速迭代器,则该字段可能会被忽略。
* The number of times this list has been structurally modified.
* Structural modifications are those that change the size of the
* list, or otherwise perturb it in such a fashion that iterations in
* progress may yield incorrect results.
*
* This field is used by the iterator and list iterator implementation
* returned by the {@code iterator} and {@code listIterator} methods.
* If the value of this field changes unexpectedly, the iterator (or list
* iterator) will throw a {@code ConcurrentModificationException} in
* response to the {@code next}, {@code remove}, {@code previous},
* {@code set} or {@code add} operations. This provides
* fail-fast behavior, rather than non-deterministic behavior in
* the face of concurrent modification during iteration.
*
*
Use of this field by subclasses is optional. If a subclass
* wishes to provide fail-fast iterators (and list iterators), then it
* merely has to increment this field in its {@code add(int, E)} and
* {@code remove(int)} methods (and any other methods that it overrides
* that result in structural modifications to the list). A single call to
* {@code add(int, E)} or {@code remove(int)} must add no more than
* one to this field, or the iterators (and list iterators) will throw
* bogus {@code ConcurrentModificationExceptions}. If an implementation
* does not wish to provide fail-fast iterators, this field may be
* ignored.
*/
protected transient int modCount = 0;
内部类[Node]: 有点寒碜就三个参数一个构造方法
private static class Node<E> {
/**
* 记录值
*/
E item;
/**
* 指向下一个节点
*/
Node<E> next;
/**
* 指向上一个节点
*/
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
//记录下一个节点
this.prev = prev;
}
}