基于pytorch语音识别_说话人分割聚类错误率从15.8%到2.2%的蜕变:基于序列传导的语音识别和说话人分割聚类模型联合...
在interspeech2019会议上,一篇名为《Joint Speech Recognition and Speaker Diarization via Sequence Transduction》的谷歌论文,又把说话人分割聚类技术提升到了一个新的阶段,成功的将语音识别技术和说话人分割聚类任务融合在一起,联合训练,不仅可以知道“什么时候说了什么”,最重要的是可以知道“谁在什么时候说了什么”。论文使用了大量的医患之间的对话语料进行实验,相比于传统的基线系统,该论文提出的方法将词级别的说话人分割聚类错误率从15.8%降到了2.2%,性能提升了7倍多。该论文的主要贡献是将联合语音识别和说话人分割聚类方法定义为序列传导问题,并且使用了循环神经网络变体进行了模型实现。
1.“谁在什么时候说了什么话”传统的系统方案
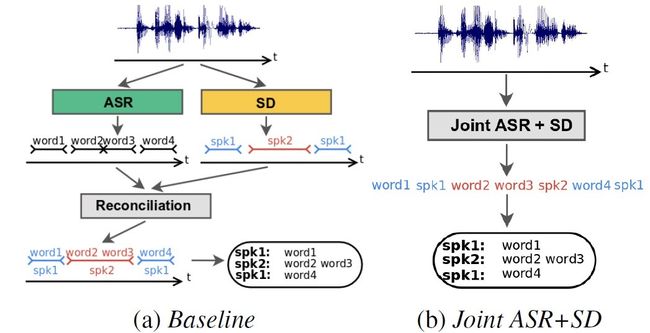
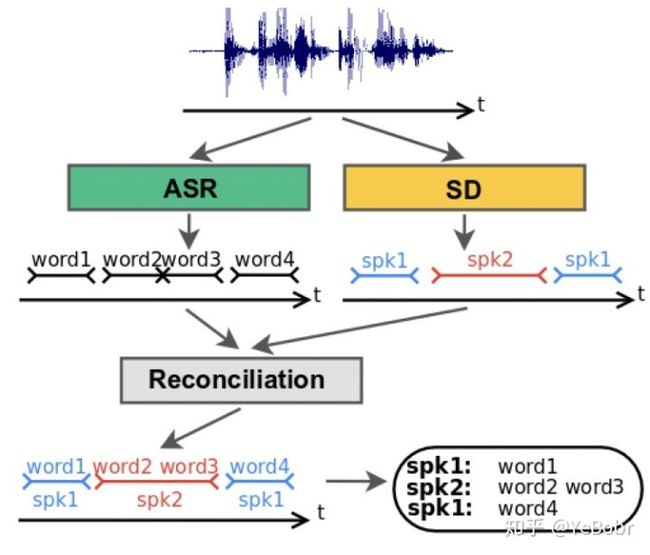
目前的语音应用在处理对话场景时,不仅仅需要识别“什么时候说了什么话”,而且需要确定“谁在什么时候说了什么话”。为了解决这个问题,很多传统的实现方案都是meger语音识别系统和说话人分割聚类系统的结果。这两个系统根据不同目标函数进行分别训练,毫无关联。传统的区分”谁在什么时候说了什么话”的方法,一般分为以下三个步。框架图如图1所示。
(1)使用语音识别系统将语音数据识别为文本;
(2)使用说话人分割聚类系统完成“谁在什么时候说了话”;
(3)最后将(1)和(2)得到的识别文本和说话人标签进行结合,确定”谁在什么时候说了什么话”。
目前工业界最常用的说话人分割聚类方法就是首先将语音流切分成固定时间段,然后再对每一个分割段进行说话人标注。虽然在过去的很多年提取了很多不同的说话人分割聚类模型,但是大都是同一个模式:
(1)使用语音活动检测技术对语音进行静音和噪音去除;
(2)对语音通过固定的长度分割成段,然后提取声学特征,例如MFCC;
(3)利用提取的特征提取feature embedding,例如 i-vectors, x-vectors;
(4)根据提取到了ferature embedding,通过聚类技术将同一说话人聚合,目前采用的比较多的聚类技术主要是一种有监督的聚类技术,详解论文《Fully supervised speaker diarization》。
传统的说话人分割聚类技术都有一个共性,大多数模型所采用的特征只用声学特征信息,而没有包含其他特征信息,例如,语言学信息,说话人性别信息等等,将这些信息利用上的话,或许可以将分割聚类效果再次提升一个层次。
2. “谁在什么时候说了什么话”语音识别和说话人分割聚类联合方案
在许多语音对话场景中,对话主角们往往都扮演者不同固定的角色。例如,在一次医患交流中,医生主要是询问一些病人经历过的一些病情症状,而病人主要是询问治疗方案,因此我们很容易就能跟两个人所说的话,确定哪一个是病人,哪一个是医生。目前也出现了根据和说话人密切相关的语言学信息进行语音分割的方法,详见论文《Speaker diarization from speech transcripts》。
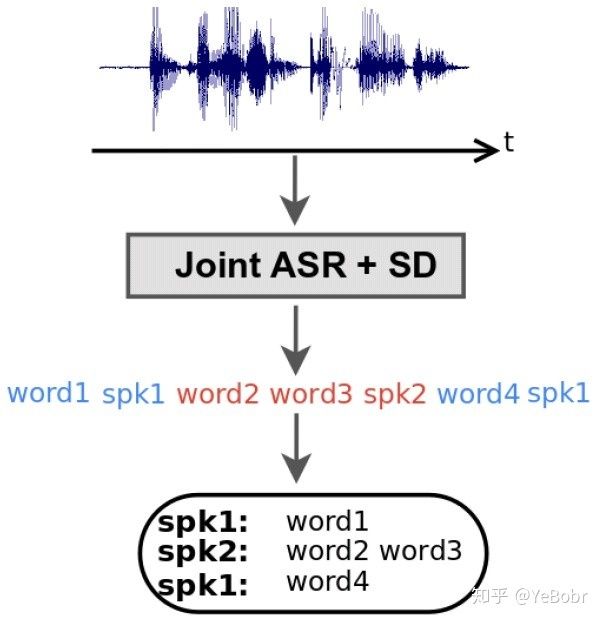
谷歌这篇论文中,就同时采用声学特征和语言学特征,提出了一种语音识别和说话人分割聚类联合训练的方法来确定“谁在什么时候说了什么话”。该方法在说话人说各有侧重点的话的场景中效果非常好。系统实现流程图如图2所示。
3. 语音识别和说话人分割聚类联合模型
为了实现语音识别和说话人分割聚类联合训练,论文中采用了语音识别中常用到的端到端识别模型RNN-T(RNN transducer, RNN-T)。RNN-T模型被使用到本论文中主要有两点原因:(1)RNN-T可以输出更加丰富的目标集合,例如说活人角色和发音,(2)RNN-T可以更好的融合声学特征和语言学特征。RNN-T的模型架构如图3所示。

其中,
3.1 Transcription Network
Transcription Network 通常被称为序列到序列的编码器,其作用是将声学特征映射到更高层次的特征表示。之前的论文中使用的序列到序列的识别模型通常是把词素作为单元,论文中作者认为更长的单元可能更加适合于语音识别,因此在论文中作者使用了语素作为单元,其可以更好地降低输出序列的时间分辨率,使得在训练和推断阶段更加有效。为了将时间分辨率从10ms降低到80ms,作者使用了一个层次时延DNN(time delay DNN, TDNN),如图4所示。这个架构和CTC词建模非常相似,只不过CTC把时间分辨率降低到120ms,这个操作既提高了推理速度又降低了字错率,详见论文《Reducing the computational complexity for whole word models》。该编码器包含了三个相同的网络块组成,每一个网络块都由一层时域卷积网络(512个滤波器,核尺寸为5,最大池化层为尺寸为2)和三层双向LSTM(512个units)构成。

3.2 Prediction Network
Prediction Network的作用是基于之前非空符号序列进行预测,得到更高层次的特征表示。其包含一个词嵌入层(word embedding layer),把一个包含大约4k个单元的语素词表向量映射到512维的空间向量,然后紧接着跟着一层1024个单元的单向LSTM和一个512个单元的全连接层。
3.3 Joint Network
Joint Network:将(1)和(2)两个网络输出的高层次的逻辑值结合得到逻辑输出值送到softmax层来得到一个概率分布
为了训练考虑,论文中将很长的对话分割为最大15s的语音段,其中可能包含多个说话人。对应的输出目标是包含说话人标签的字符序列。如图5所示。

4. 实验结果
4.1 实验数据及处理
论文中采用的数据是100k条的手动标注的医生和患者之间临床对话数据,平均每条语音大约10分钟,大约15k小时。在说话人转换的地方,会标注上说话人角色,医生
4.2 评估指标
通常使用的说话人聚类评估指标是说话人聚类错误率(diarizaition error rate, DER),它将参考说话人标签段和系统预测的标签段进行比较,得到DER。然而,语音识别(ASR)和说话人分割聚类(SD)融合系统由于是直接对识别的词进行说话人标注,所以不需要依靠时间界限来进行词和说话人进行对齐。受到NIST RT-03F评估计划中提出的speaker attributed task的启发,作者使用了一种适用于评估端到端ASR和SD模型融合系统的评估指标,即通过计算识别文本中正确说话人标签的词的比例得到指标值。作者将Word Diarization Error Rate(WDER)定义为:
其中,
注意WDER必须结合WER使用,以考虑词删除和词插入错误,因为词删除和词插入对应的说话人标签在参考标签中是没有与之对应的标签的。因此词级别的评估指标在实际的应用中是优于时间级别的评估指标的。
4.3 基线系统模型
为了与论文提出的模型进行对比,基线系统使用的网络和ASR和SD融合模型完全一致,只不过其只用于语音识别。训练文本将全部的说话人标签删除。说话人分割聚类使用传统的系统。作者构建了一个强健的基线系统,主要包含五部分:语音检测和分割、Speaker embedding、说话人改变检测、说话人聚类、语音识别和说话人识别结合模块。每个模块具体的介绍见论文。 评估方法为为没一个识别词分配角色,当说话人转换边界落在了词中间的时候,我们就把和词重叠帧最多的说话人分配给这个词。
4.4实验结果及分析
图6是WDER在每一条对话中的分布,其中红色是基线系统,蓝色是ASR和SD联合系统。联合系统的WDER大部分都低于4%,而传统的方法大部分分布在11%左右。
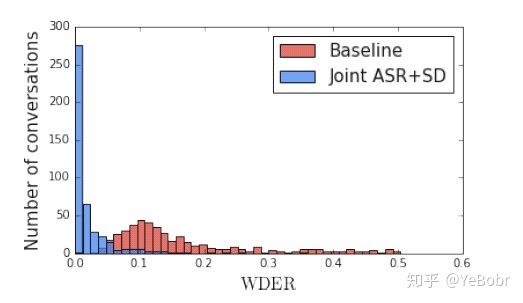
图7是语音识别错误率WER和说话人分割聚类错误率WDER随着训练集语音时长变化曲线。更多的训练数据对于降低WER比降低WDER更有帮助。
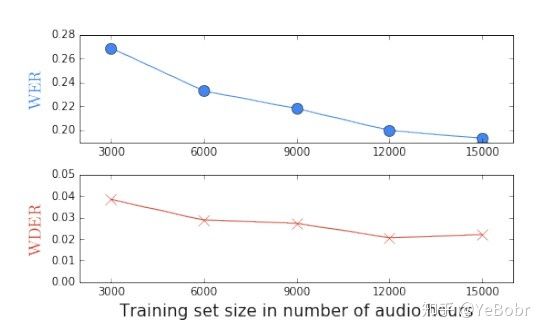
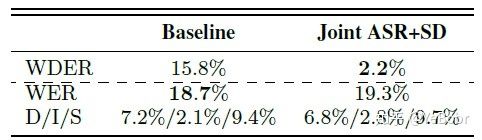
图8是基线系统和ASR与SD联合系统WDER和WER的指标值。可以看到联合系统的WDER相对提升了86%,但是语音识别率降低了0.6%。作者分析了传统方法的WDER较低的一些原因,例如语音识别得到的词边界错误、说话人分割聚类得到的说话人转变边界错误已经在两个系统进行结合时候出现的错误等等,但是对于联合系统来讲,就不存在这些中间步骤,从而极大的降低了WDER。