pytorch实现LSTM学习总结
pytorch实现LSTM学习总结
第一次写csdn,可以通过这样的方式记录一下自己学习过程中遇到的问题。
学习目标:
- 学习语言模型,以及如何训练一个语言模型
- 学习torchtext的基本使用方法
构建 vocabulary
word to inde 和 index to word - 学习torch.nn的一些基本模型
Linear
RNN
LSTM
GRU(因为我觉得LSTM和GRU在代码方面如出一辙,所以只用了LSTM) - RNN的训练技巧
Gradient Clipping
5.如何保存和读取模型
代码如下:
导入库:
torchtext提供了LanguageModelingDataset这个class来帮助我们处理语言模型数据集
BPTTIterator可以连续地得到连贯的句子
import torchtext
from torchtext.vocab import Vectors
import torch
import numpy as np
import random
USE_CUDA = torch.cuda.is_available()
# 为了保证实验结果可以复现,把各种random seed固定在某一个值
random.seed(53113)
np.random.seed(53113)
torch.manual_seed(53113)
if USE_CUDA:
torch.cuda.manual_seed(53113)
BATCH_SIZE = 32#每个batch的包含的句子数
EMBEDDING_SIZE = 1000#嵌入层大小
HIDDEN_SIZE = 500#隐藏层数量,区别于EMBEDDING_SIZE
MAX_VOCAB_SIZE = 50000# 单词总数
使用 torchtext 来创建vocabulary, 然后把数据读成batch的格式:
#参考:https://pytorch.org/text/0.8.1/data.html?highlight=field#torchtext.data.Field
#Filed还有很多参数,具体看官方文档,这里参数lower是所有单词都是小写
TEXT = torchtext.data.Field(lower=True)
train, val, test = torchtext.datasets.LanguageModelingDataset.splits(path=".",
train="text8.train.txt",
validation="text8.dev.txt",
test="text8.test.txt", text_field=TEXT)
#构造train的vocab的对象
TEXT.build_vocab(train, max_size=MAX_VOCAB_SIZE)
VOCAB_SIZE = len(TEXT.vocab)
#迭代器返回模型所需要的处理后的数据。迭代器主要分为Iterator,BucketIterator,BPTTIterator三种。
#Iterator:标准迭代器
#BucketIterator:相比于标准迭代器,会将类似长度的样本当做一批来处理,
#因为在文本处理中经常会需要将每一批样本长度补齐为当前批中最长序列的长度,
#因此当样本长度差别较大时,使用BucketIerator可以带来填充效率的提高。
#除此之外,我们还可以在Field中通过fix_length参数来对样本进行截断补齐操作。
#BPTTIterator:基于BPTT(基于时间的反向传播算法)的迭代器,一般用于语言模型中。
#参考:https://blog.csdn.net/leo_95/article/details/87708267
#bptt_len: 反向传播往回传的长度,这里我暂时理解为一个样本有多少个单词传入模型
#repeat: 多个epoch是否重复迭代器
#shuffle:epoch之间是否打乱数据
#device:CPU/GPU
train_iter, val_iter, test_iter = torchtext.data.BPTTIterator.splits(
(train, val, test), batch_size=BATCH_SIZE, device=-1, bptt_len=50, repeat=False, shuffle=True)
print(VOCAB_SIZE)
out:50002
可以通过vocab.stoi和vocab.itos映射乘数字或者对应的字符
#stoi:把字符映射成数字
TEXT.vocab.stoi["apple"]
out:1259
#itos:把数字映射成字符
TEXT.vocab.itos[5]
out:‘one’
- 模型的输入是一串文字,模型的输出也是一串文字,他们之间相差一个位置,因为语言模型的目标是根据之前的单词预测下一个单词
#iter(obj) 从可迭代对象创建一个迭代器 .简单地说,迭代器是包含方法__next__的对象,可用于迭代一组值。
it = iter(train_iter)
batch = next(it)
# string.join(sequence) 将string与sequence中的所有字符串元素合并,并返回结果
print(" ".join([TEXT.vocab.itos[i] for i in batch.text[:,1].data]))
print(" ".join([TEXT.vocab.itos[i] for i in batch.target[:,1].data]))
out:had dropped to just three zero zero zero k it was then cool enough to allow the nuclei to capture electrons this process is called recombination during which the first neutral atoms
dropped to just three zero zero zero k it was then cool enough to allow the nuclei to capture electrons this process is called recombination during which the first neutral atoms took
- 相差一个位置
for i in range(5):
batch = next(it)
print(" ".join([TEXT.vocab.itos[i] for i in batch.text[:,2].data]))
print(" ".join([TEXT.vocab.itos[i] for i in batch.target[:,2].data]))
太多了省略…
定义模型:
- 继承nn.Module
- 初始化函数
- forward函数
import torch
import torch.nn as nn
class LSTMModel(nn.Module):
def __init__(self, ntoken, ninp, nhid, nlayer , dropout = 0.5 ):
#notoken=VOCAB_SIZE=50002
#ninp=EMBEDDING_SIZE=1000
# nhid:HIDDEN_SIZE = 500,隐藏层维度。
# nlayers:神经网络的层数,这里为1
super(LSTMModel, self).__init__()
self.drop = nn.Dropout(dropout)
self.encoder = nn.Embedding(ntoken,ninp)
self.rnn = nn.LSTM(ninp, nhid)
self.decoder = nn.Linear(nhid, ntoken)
self.init_weights()
self.nlayer = nlayer
self.nhid = nhid
def init_weights(self):
initrange = 0.1
self.encoder.weight.data.uniform_(-initrange, initrange)
self.decoder.bias.data.zero_()
self.decoder.weight.data.uniform_(-initrange, initrange)
#input.size() = data = batch.text 维度:(50,32)
#正常看input的维度,应该是(32,50),如果觉得(50,32)看着别扭,可以在LSTM中设置batch_first = True, 输入和输出的tensors就会变成(batch, seq, feature)
#hidden是一个元祖,(h_0, c_0)
#h_0.size() = (num_layers * num_directions, batch, hidden_size) = (1*1,32,1000)
#h_0.size() = (num_layers * num_directions, batch, hidden_size) = (1*1,32,1000)
#num_layers为LSTM层数,这里只用了一层。
#num_directions:如果是双向LSTM的话,将该参数设置为2,否则就设置为1。
def forward(self, input, hidden):
#Embedding(50002,1000)后得到的emb的维度:(50,32,1000)
emb = self.drop(self.encoder(input))
#第一次执行时,hidden是从init_hidden()中返回的,维度为(1,32,500),全为0,第二次之后,就是用前一次的hidden值
output, hidden = self.rnn(emb, hidden)
#output.size() = (seq_len, batch, num_directions * hidden_size) = (50,32,1*500)
#LSTM的参数是(1000,500),输入的emb最后一维是1000,输出的output最后一维是500
output = self.drop(output)
#前面定义了线性层为(500,50002),由于高于二维的tensor相乘必须将高维tensor转换为2维,得到结果之后再转换为高维
#output是一个三维tensor,不能直接通过线性层运算,必须将维度转换为2维计算。
#通过view函数将output第一维和第二维拼接在一起,就变成了(50*32,500)*(500,50002)--(50*32,50002)
decoded = self.decoder(output.view(output.size(0)*output.size(1), output.size(2)))
#最后分别返回每个维度的tensor和hidden
#output.size(0)=50, output.size(1)=32, decoded.size(1)=50002,hidden的维度就是前面的维度
return decoded.view(output.size(0), output.size(1), decoded.size(1)), hidden
#初始化隐藏层参数
def init_hidden(self, bsz, requires_grad=True):
weight = next(self.parameters())
# weight = torch.Size([50002, 650])是所有参数的第一个参数
#我的理解是,以weight的数据格式为标准。
#通过new,构造一个数据格式和weight相同,但是维度是我们自己指定的新的张量。将新张量当做hidden的第一个参数
return (weight.new_zeros(self.nlayer,bsz,self.nhid),
weight.new_zeros(self.nlayer,bsz,self.nhid))
初始化模型:
VOCAB_SIZE = 50002
EMBEDDING_SIZE = 1000
HIDDEN_SIZE = 500
只有一层LSTM(为了节省训练时间)
model = RNNModel(VOCAB_SIZE, EMBEDDING_SIZE, HIDDEN_SIZE, 1, dropout=0.5)
if USE_CUDA:
model = model.cuda()
查看model:
model
out:
LSTMModel(
(drop): Dropout(p=0.5, inplace=False)
(encoder): Embedding(50002, 1000)
(rnn): LSTM(1000, 500)
(decoder): Linear(in_features=500, out_features=50002, bias=True)
)
如果有GPU,将模型转换到GPU
if USE_CUDA:
model = model.cuda()
定义评估模型
模型的评估和模型的训练逻辑基本相同,唯一的区别是只需要forward pass,不需要backward pass
def evaluate(model, data):
#在测试时写上model.eval()
model.eval()
total_count=0.
total_loss=0.
it = iter(data)
#执行测试的计算,使该计算不会在反向传播中被记录。
with torch.no_grad():
#这里的hidden是重新初始化的hidden的参数
#要注意hidden不是hidden是指LSTM中内部保存的历史状态,不是可训练参数,为了保持train/eval阶段的一致性,需要对hidden进行相同的初始化操作
hidden = model.init_hidden(BATCH_SIZE)
for i,batch in enumerate(it):
data, target = batch.text, batch.target
if USE_CUDA:
data, target = data.cuda(), target.cuda()
hidden = repackage_hidden(hidden)
#这里的model是每一轮已经训练好的model
output,hidden = model(data,hidden)
# output.view(-1, VOCAB_SIZE) = (1600,50002)
# target.view(-1) =(1600)
loss = loss_fn(output.view(-1, VOCAB_SIZE), target.view(-1))
#data.size() = (50,32)
#*data.size()是进行解包操作 print(*data.size()) = 50 32
#注意这里print只能用于*解包操作,不能用于**解包操作,但是可以用format函数来实现
#具体参考*和**的作用参考https://www.cnblogs.com/mo-nian/p/11842422.html
#total_count计算测试集样本中单词的总数
total_count +=np.multiply(*data.size())
#用每次batch的损失值乘以每次batch的单词数得到了每次batch的损失总数,在求和得到总的损失。
total_loss += loss.item() * np.multiply(*data.size())
#总的损失/总单次数=平均损失
loss = total_loss/total_count
model.train()
return loss
定义function,使hidden state和计算图之前的历史分离
def repackage_hidden(h):
if isinstance(h, torch.Tensor):
#isinstance() 函数来判断一个对象是否是一个已知的类型
return h.detach()
# 这个是GRU的截断,因为只有一个隐藏层,判断h是不是torch.Tensor,我没有用GRU,只用了LSTM
else:
return tuple(repackage_hidden(v) for v in h)
# 这个是LSTM的截断,有两个隐藏层,格式是元组,
定义loss function和optimizer
loss_fn = nn.CrossEntropyLoss()
learning_rate = 0.01
optimizer = torch.optim.Adam(model.parameters(),lr = learning_rate)
# 每调用一次这个函数,lenrning_rate就降一半
#具体理解:https://blog.csdn.net/qyhaill/article/details/103043637
scheduler = torch.optim.lr_scheduler.ExponentialLR(optimizer, 0.5)
训练模型:
- 模型一般需要训练若干个epoch
- 每个epoch我们都把所有的数据分成若干个batch
- 把每个batch的输入和输出都包装成cuda tensor
- forward pass,通过输入的句子预测每个单词的下一个单词
- 用模型的预测和正确的下一个单词计算cross entropy loss
- 清空模型当前gradient
- backward pass
- gradient clipping,防止梯度爆炸
- 更新模型参数
- 每隔一定的iteration输出模型在当前iteration的loss,以及在验证集上做模型的评估
NUM_EPOCHS = 2
GRAD_CLIP = 1.
val_losses = []
for epoch in range(NUM_EPOCHS):
#训练开始之前写上model.trian()
#如果模型中有BN层(Batch Normalization)和Dropout,需要在训练时添加model.train(),在测试时添加model.eval()。
#其中model.train()是保证BN层用每一批数据的均值和方差,而model.eval()是保证BN用全部训练数据的均值和方差;
#而对于Dropout,model.train()是随机取一部分网络连接来训练更新参数,而model.eval()是利用到了所有网络连接。
#具体原理参考https://www.cnblogs.com/luckyplj/p/13424561.html
model.train()
# iter,生成迭代器,这里train_iter也是迭代器,不用iter也可以
it = iter(train_iter)
#初始化hidden
#初始化hidden为什么用的是BATCH_SIZE而不是HIDDEN_SIZE,官方文档给出的hidden的 (num_layers * num_directions, batch, hidden_size)
hidden = model.init_hidden(BATCH_SIZE)
for i,batch in enumerate(it):
#取训练集中的数据和标签
data, target = batch.text, batch.target
if USE_CUDA:
data, target = data.cuda(), target.cuda()
# 语言模型每个batch的隐藏层的输出值是要继续作为下一个batch的隐藏层的输入的
# 因为batch数量很多,如果一直往后传,会造成整个计算图很庞大,反向传播会内存崩溃。
# 所有每次一个batch的计算图迭代完成后,需要把计算图截断,只保留隐藏层的输出值。
# 不过只有语言模型才这么干,其他比如翻译模型不需要这么做。
# repackage_hidden自定义函数用来截断计算图的。
hidden = repackage_hidden(hidden)
#前向传播求出预测的值
output,hidden = model(data,hidden)
#梯度初始化为零
#当optimizer=optim.Optimizer(model.parameters())时,和model.zero_grad()等效
optimizer.zero_grad()
#计算loss
#output.size() = (50,32,50002) output.view(-1,50002) = (1600,50002)
#target.size() = (50,32) target.view(-1) = (1600)
loss = loss_fn(output.view(-1, VOCAB_SIZE), target.view(-1))
#反向传播求梯度
loss.backward()
#防止梯度爆炸或者梯度小时,设定阈值,当梯度小于/大于阈值时,更新的梯度为阈值
#nn.utils.clip_grad_norm(parameters, max_norm, norm_type=2)
#max_norm:梯度的最大范数(原文:max norm of the gradients) 这里为1
torch.nn.utils.clip_grad_norm_(model.parameters(),GRAD_CLIP)
#更新所有参数
optimizer.step()
if i %100 == 0:
print("epoch",epoch,"iter",i,"loss",loss.item())
if i % 10000 == 0:
val_loss = evaluate(model, val_iter)
if len(val_losses) == 0 or val_loss < min(val_losses):
# 如果比之前的loss要小,就保存模型
print("best model, val loss: ", val_loss)
torch.save(model.state_dict(), "lm-best.th")
else: # 否则loss没有降下来,需要优化
scheduler.step() # 自动调整学习率
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 学习率调整后需要更新optimizer,下次训练就用更新后的
val_losses.append(val_loss) # 保存每10000次迭代后的验证集损失损失
加载保存好的模型:
# 加载保存好的模型参数
best_model = LSTMModel(VOCAB_SIZE, EMBEDDING_SIZE, HIDDEN_SIZE, 1, dropout=0.5)
if USE_CUDA:
best_model = best_model.cuda()
best_model.load_state_dict(torch.load("lm-best.th"))
计算困惑度
困惑度(Perplexity)是信息论中的一个概念,可以用来衡量一个分布的不 确定性.对于离散随机变量 ∈ ,其概率分布为(),困惑度为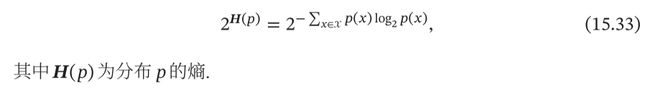
但是实验常用的困惑度定义一般为:
PPL = ecross_entropy
使用最好的模型在valid数据上计算perplexity
val_loss = evaluate(best_model, val_iter)
print("perplexity: ", np.exp(val_loss))
使用最好的模型在test数据上计算perplexity
test_loss = evaluate(best_model, test_iter)
print("perplexity: ", np.exp(test_loss))
参考:
https://blog.csdn.net/Chowzheng/article/details/107721941
https://discuss.pytorch.org/t/what-does-next-self-parameters-data-mean/1458
https://www.bilibili.com/video/BV12741177Cu?t=6368&p=3
其余参考列在了代码里。