中间件之XXL-JOB的介绍及源码分析
XXL-JOB的使用及原理
- 一、基本介绍
-
- 1.Quartz的不足
- 2.xxl-job特性
- 二、简单使用
-
- 1.快速启动
- 2.路由策略
- 3.运行模式
- 4.阻塞处理策略
- 5.子任务
- 6.分片任务
- 三、架构设计
-
- 1.系统组成
-
- (1)调度模块(调度中心)
- (2)执行模块(执行器)
- 2.设计思想
-
- (1)调度与任务解耦
- (2)全异步化、轻量级
- 四、源码分析
-
- 1.执行器启动与注册
-
- (1)XxlJobSpringExecutor
- (2)initJobHandlerMethodRepository(applicationContext);
- (3)start
- (4)小结
- 2.调度器的启动与任务执行
-
- (1)JobRegistryMonitorHelper.getInstance().start();
- (2)JobScheduleHelper.getInstance().start();
-
- ① scheduleThread
- ② 任务触发
- ③ XXL-JOB中的时间轮
- ④ ringThread
- (3)小结
- 3.执行器执行任务
-
- (1)EmbedHttpServerHandler
- (2)ExecutorBizImpl
- (3)JobThread
- (4)TriggerCallbackThread
-
- ①triggerCallbackThread
- ②triggerRetryCallbackThread
- 4.总结
一、基本介绍
XXL-JOB是一个分布式任务调度平台,其核心设计目标是开发迅速、学习简单、轻量级、易扩展。现已开放源代码并接入多家公司线上产品线,开箱即用。
XXL-JOB原理是开启线程while循环调度,包括时间轮算法,快线程慢线程等等
1.Quartz的不足
Quartz差不多有20年的历史,调度模型已经非常成熟,而且很容易集成到Spring中去,用来执行业务任务是一个很好的选择。
但是还是会有一些问题,比如:
- 调度逻辑(Scheduler)和任务耦合在同一个项目中,随着调度任务数量逐渐增多,同时任务逻辑逐渐加重,调度系统的整体性能会受到很大的影响
- Quartz集群的节点之间负载结果是随机的,谁抢到了数据库锁就由谁去执行任务,这就有可能出现某台机器负载过重,发挥不了集群机器的性能。
- Quartz本身没有提供动态任务调度和管理界面的功能,需要自己根据API进行开发。
- Quartz的日志记录,数据统计,监控不是特别完善
2.xxl-job特性
调度采用线程池方式实现,避免单线程因阻塞而引起任务调度延迟。
跟老牌Quartz相比,xxl-job拥有更加丰富的功能。
总体上可以分成三大类:
- 性能的提升:可以调度更多的任务。
- 可靠性的提升:任务超时、失败、故障转移的处理。
- 运维更加便捷:提供操作界面,有用户权限,详细的日志,提供通知配置,自动生成报表等等。
并行调度
XXL-JOB调度模块默认采用并行机制,在多线程调度的情况下,调度模块被阻塞的几率很低,大大提高了调度系统的承载量。
XXL-JOB的不同任务之间并行调度、并行执行。
XXL-JOB的单个任务,针对多个执行器是并行运行的,针对单个执行器是串行执行的。同时支持任务终止。
全异步化 & 轻量级
- 全异步化设计:XXL-JOB系统中业务逻辑在远程执行器执行,触发流程全异步化设计。相比直接在调度中心内部执行业务逻辑,极大的降低了调度线程占用时间;
- 异步调度:调度中心每次任务触发时仅发送一次调度请求,该调度请求首先推送“异步调度队列”,然后异步推送给远程执行器
- 异步执行:执行器会将请求存入“异步执行队列”并且立即响应调度中心,异步运行。
- 轻量级设计:XXL-JOB调度中心中每个JOB逻辑非常 “轻”,在全异步化的基础上,单个JOB一次运行平均耗时基本在 “10ms” 之内(基本为一次请求的网络开销);因此,可以保证使用有限的线程支撑大量的JOB并发运行;
得益于上述两点优化,理论上默认配置下的调度中心,单机能够支撑 5000 任务并发运行稳定运行;
实际场景中,由于调度中心与执行器网络ping延迟不同、DB读写耗时不同、任务调度密集程度不同,会导致任务量上限会上下波动。
如若需要支撑更多的任务量,可以通过 “调大调度线程数” 、”降低调度中心与执行器ping延迟” 和 “提升机器配置” 几种方式优化。
二、简单使用
1.快速启动
v2.2.0版本源码地址:https://github.com/xuxueli/xxl-job/releases/tag/v2.2.0
下载完毕导入idea下载依赖,并本地执行数据库脚本。
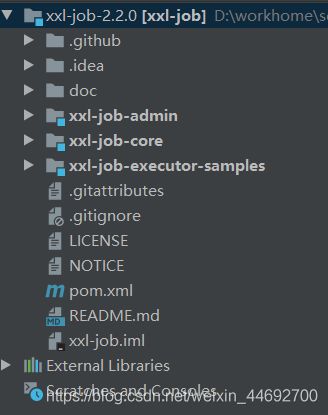
- /doc:文档资料,包括数据库脚本
- /xxl-job-core:公共jar依赖
- /xxl-job-admin:调度中心,项目源码,SpringBoot项目可以直接启动
- /xxl-job-executor-samples:执行器,Sample实例项目,其中SpringBoot工程可以直接启动。可以在该项目上进行开发,也可以将现有项目改造成执行器项目。

| 表名 | 作用 |
|---|---|
| xxl_job_group | 执行器信息表,维护任务执行器信息 |
| xxl_job_info | 调度扩展信息表:用域保存XXL-JOB调度任务的扩展信息,比如任务分组、任务名、机器地址、执行器、执行入参报警邮件等等。 |
| xxl_job_lock | 任务调度锁表 |
| xxl_job_log | 日志表:用于保存xxl-job任务调度的历史信息,如调度结果、执行结果、调度入参、调度机器和执行器等 |
| xxl_job_log_report | 日志报表:用于存储job任务调度日志的报表,调度中心报表功能页面会用到 |
| xxl_job_logglue | 任务GLUE日志,用于保存GLUE更新历史,用域支持GLUE的版本回溯功能 |
| xxl_job_registry | 执行器注册表,维护在线的执行器和调度中心机器地址信息 |
| xxl_job_user | 系统用户表 |
依赖下载完成数据库导入完成后,可以进行启动,首先修改application.properties配置文件中的数据库地址,然后直接启动。
访问:http://127.0.0.1:8080/xxl-job-admin
默认账号密码admin/123456。
为了保证可用性,调度中心可以做集群部署,需要满足以下几个条件:
- 连接到同一个数据库
- 集群机器时钟保持一致
- 建议:通过域名/VIP进行访问,使用Nginx做负载均衡。访问管理界面,执行器注册等都用域名/VIP。
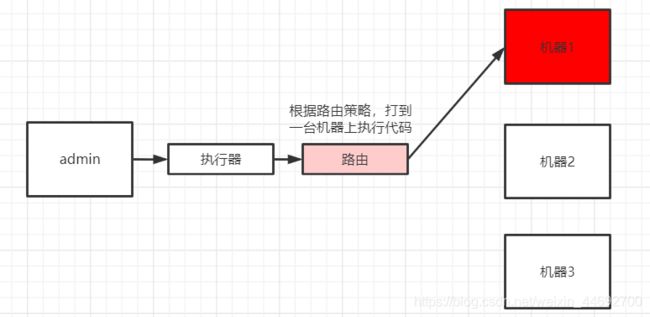
2.路由策略

路由策略是指一个任务选择哪个执行器去执行,Quartz只能随机负载,xxljob提供了丰富的路由策略,包括:
| 策略 | 参数值 | 详细含义 |
|---|---|---|
| 第一个 | FIRST | 固定选择第一个机器(先注册) |
| 最后一个 | LAST | 固定选择最后一个机器 |
| 轮询 | ROUND | 依次选择执行 |
| 随机 | RANDOM | 随机选择在线的机器 |
| 一致性HASH | CONSISTENT_HASH | 每个任务按照Hash算法固定选择某台机器执行,且所有任务均匀散列在不同机器上 |
| 最不经常使用 | LEAST_FREQUENTLY_USED | 使用频率最低的机器优先被选举 |
| 最近最久未使用 | LEAST_RECENTLY_USED | 醉酒未使用的机器优先被选举 |
| 故障转移 | FAILOVER | 按照顺序依次进行心跳检测,第一个心跳检测成功的机器选定为目标执行机器 |
| 忙碌转移 | BUSYOVER | 按照顺序依次进行空闲检测,第一个空闲检测成功的机器选定为目标机器并发起调度 |
| 分片广播 | SHARDING_BROADCAST | 广播触发对应集群中所有机器执行依次任务,同时系统自动传递分片参数(index,total),可根据分片参数开发分片任务。 |
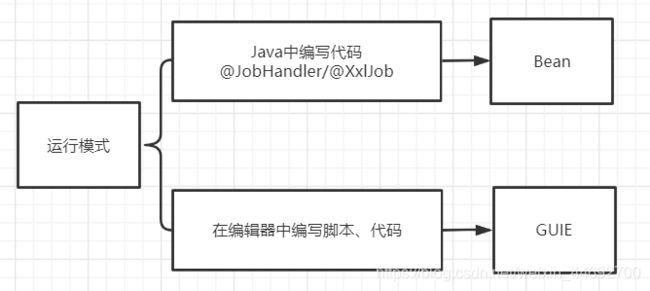
3.运行模式
在xxl-job中,不仅支持运行预先编写好的任务类,还可以直接输入代码或者脚本运行。
运行任务类,这种方式就叫做BEAN模式,需要指定任务类,这个任务就叫做JobHandler,需要在执行器端编写业务代码。
运行代码或者脚本,叫做GLUE模式,支持java、shell、puthon、php、nodejs、powerShell,这个时候代码是直接维护在调度器这边的。
注意:GUIE模式必须在执行器和调度中心中配置相同的TOKEN,否则会有远程执行漏洞。
xxl.job.accessToken=xxx
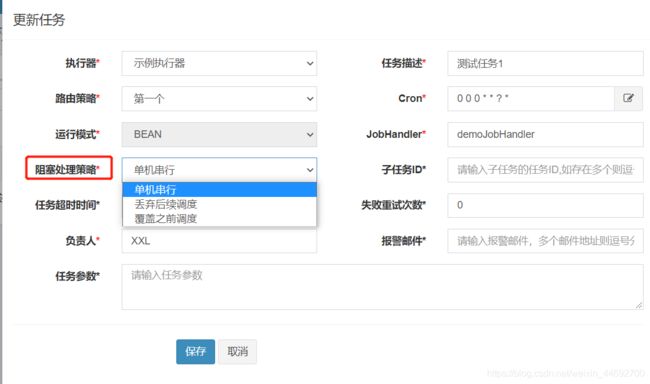
4.阻塞处理策略
阻塞处理策略,指任务的一次运行还没有结束的时候,下一次调度的时间又到了,这时候怎么处理。
| 策略 | 参数值 | 详细含义 |
|---|---|---|
| 单机串行(默认) | SERIAL_EXECUTION | 调度请求进入单机执行器后,调度请求进入FIFO队列并以串行方式运行 |
| 丢弃后续调度 | DISCARD_LATER | 调度请求进入单机执行器后,发现执行器存在运行的调度任务,本次请求将会被丢弃并标记为失败 |
| 覆盖之前调度 | COVER_EARLY | 调度请求进入单机执行器后,发现执行器存在运行的调度任务,将会终止运行中的调度任务并清空队列,然后运行本地调度任务。 |
- SERIAL_EXECUTION(单机串行,默认):对当前线程不做任何处理,并在当前线程的队列里增加一个执行任务(一次只执行一个任务)。
举例:有个任务是增加访问计数。虽然上次任务还没执行完毕,但是计数还是要增加,所以先放到队列中。 - DISCARD_LATER(丢弃后续调度):如果当前线程阻塞,后续任务不再执行,直接返回失败(阻塞不再执行)
举例:有个任务是清理日志,上次的还没有执行完毕,但是不需要重复清理,忽略。 - COVER_EARLY(覆盖之前调度):创建一个移除原因,新建一个线程去执行后续任务(杀掉当前线程)
举例:有个任务是下载文件,如果上次还没跑完,可能是出现问题了,直接停掉重新下载。
5.子任务
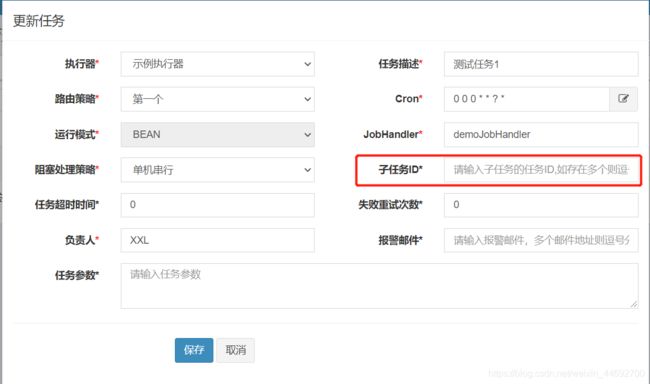
在【子任务】栏填写相关子任务的id(任务ID可以从任务列表获取)。在执行完本任务后,会自动调用子任务,进行串行执行。(在一个任务的尾端触发另一个任务)。
注意:子任务不需要启动,上一个任务执行完毕后会自动调用执行。
6.分片任务
其他路由策略比较简单读者可自行测试。这里强调下分片任务。
首先看其他路由策略:
分片任务路由策略:

分片广播任务是在执行器的所有机器上面都执行一次任务。
如果运行的是相同的任务,执行同一段代码,不会有冲突吗?
注意:分片广播任务在执行时,调度器会给每个执行器发送一个不同的分片序号和总机器数量。比如我们有三台机器,那么总数total=3,三台机器的index分别为0、1、2。可以由代码控制任务不会重复执行。
看代码:
/**
* 分片广播任务
*/
@XxlJob("shardingJobHandler")
public ReturnT<String> shardingJobHandler(String param) throws Exception {
// 分片参数
ShardingUtil.ShardingVO shardingVO = ShardingUtil.getShardingVo();
XxlJobLogger.log("分片参数:当前分片序号 = {}, 总分片数 = {}", shardingVO.getIndex(), shardingVO.getTotal());
// 业务逻辑
for (int i = 0; i < shardingVO.getTotal(); i++) {
if (i == shardingVO.getIndex()) {
XxlJobLogger.log("第 {} 片, 命中分片开始处理", i);
} else {
XxlJobLogger.log("第 {} 片, 忽略", i);
}
}
return ReturnT.SUCCESS;
}
ShardingUtil.ShardingVO shardingVO = ShardingUtil.getShardingVo();可以获得分片参数
shardingVO.getTotal()可以获得总机器数total。
shardingVO.getIndex()可以获得当前命中分片index。
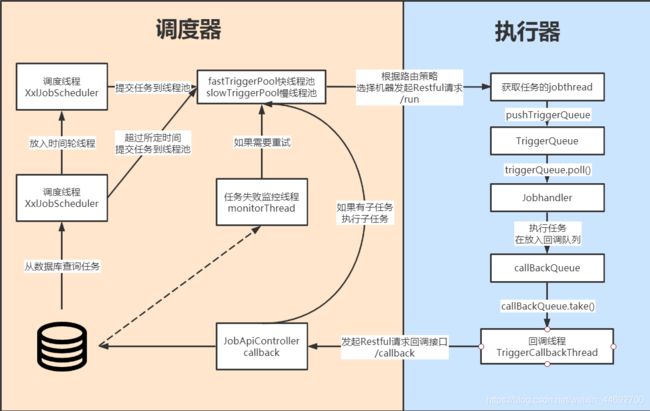
三、架构设计

将调度行为抽象形成“调度中心”公共平台,而平台自身并不承担业务逻辑,“调度中心”负责发起调度请求。
将任务抽象成分散的JobHandler,交由“执行器”统一管理,“执行器”负责接收调度请求并执行对应的JobHandler中业务逻辑。
因此,“调度”和“任务”两部分可以相互解耦,提高系统整体稳定性和扩展性;
1.系统组成
(1)调度模块(调度中心)
负责管理调度信息,按照调度配置发出调度请求,自身不承担业务代码。调度系统与任务解耦,提高了系统可用性和稳定性,同时调度系统性能不再受限于任务模块;
支持可视化、简单且动态的管理调度信息,包括任务新建,更新,删除,GLUE开发和任务报警等,所有上述操作都会实时生效,同时支持监控调度结果以及执行日志,支持执行器Failover。
(2)执行模块(执行器)
负责接收调度请求并执行任务逻辑。任务模块专注于任务的执行等操作,开发和维护更加简单和高效;
接收“调度中心”的执行请求、终止请求和日志请求等。
从整体上来看,XXL-JOB架构依赖较少,功能强大,简约而不简单,方便部署,易于使用。
2.设计思想
(1)调度与任务解耦
在Quartz中,调度逻辑和任务代码是耦合在一个项目中的。(项目经理和小组组长、打工人是挤在同一间办公室)
而XXL-JOB把调度的动作抽象和独立出来,形成调度中心公共平台。调度中心只负责发起调度请求,平台自身并不承担业务逻辑。(项目经理有了独立办公室,通过电话远程安排任务)
将任务抽象成分散的JobHandler,交给执行器统一管理,执行器负责接受调度请求并执行对应的JobHandler中业务逻辑。(几个小组组长,每个小组组长管理各自的打工人,小组组长会找打工人执行任务)
“调度”和“任务”两部分相互解耦,可以提高系统整体稳定性和扩展性
(2)全异步化、轻量级
Quartz原来的设计是:在一个while循环里面,不断地获取下一个即将触发的任务,包装成一个线程执行它。任务的执行是不会占用调度线程的时间的,但是任务的触发会占用调度线程的时间,也就是获取任务创建线程的时间。
xxl-job把调度器和任务执行解耦后,把触发的过程改成了异步的触发,它会先把调度请求放进一个异步调度队列中。任务的执行不消耗调度中心的资源,它的结果也是异步返回的。
根据官方的描述,单个任务的一次运行平均耗时在10ms之内(基本为一次请求的网络开销),所以即使线程数量优先,也不会影响任务的执行。
理论上默认配置下的调度中心,单机能够支撑5000任务并发稳定运行。
实际场景中,由于调度中心与执行器网络延迟不同,DB读写耗时不同,任务调度密集程度不同,会导致任务量上限会上下波动。
如果需要支撑更多的任务量,可以通过调大调度线程数,降低调度中心与执行器ping延迟和提升机器配置等几种优化方式。
四、源码分析
因为调度的流程涉及到执行器,所以我们先分析执行器
执行器启动主要做的事情:把自己注册到调度中心,保存在数据库。
1.执行器启动与注册

注册器的注册与发现有两种方式:
- 一种是执行器启动时,主动到注册中心注册,并定时发送心跳,保持续约。执行器正常关闭时,也主动告知调度中心注销。这种方式叫做
主动注册。 - 如果执行器宕机或者网络出现问题,调度中心本身也需要不断的对执行器进行
探活(类似于RocketMQ中的NameServer和Broker)。调度中心会启动一个专门探活的后台线程,定时调用执行器接口,如果发现异常就将执行器下线,避免路由到一个不可用的执行器导致任务失败。
(1)XxlJobSpringExecutor
在执行器端我们从XXL-JOB的配置类XxlJobConfig触发,这里用到了我们配置在application.properties的参数。
配置类中定义了一个XxlJobSpringExecutor,会在启动扫描配置类的时候创建Bean。
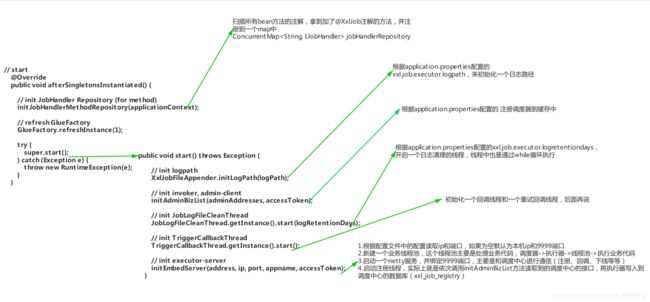
点进此类发现集成了XxlJobExecutor,又实现了Spring中的SmartInitializingSingleton接口,此接口在对象初始化的时候会调用afterSingletonInstantiated()方法对执行器进行初始化。
public class XxlJobSpringExecutor extends XxlJobExecutor implements ApplicationContextAware, SmartInitializingSingleton, DisposableBean {
private static final Logger logger = LoggerFactory.getLogger(XxlJobSpringExecutor.class);
// start
@Override
public void afterSingletonsInstantiated() {
// init JobHandler Repository (for method)
initJobHandlerMethodRepository(applicationContext);
// refresh GlueFactory
GlueFactory.refreshInstance(1);
// super start
try {
super.start();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
(2)initJobHandlerMethodRepository(applicationContext);
此方法中拿到所有IOC容器中的bean,并扫描看其中的方法是否有带@XxlJob注解的得到一个Map
private void initJobHandlerMethodRepository(ApplicationContext applicationContext) {
if (applicationContext == null) {
return;
}
// 拿到所有的bean
String[] beanDefinitionNames = applicationContext.getBeanNamesForType(Object.class, false, true);
//循环遍历
for (String beanDefinitionName : beanDefinitionNames) {
Object bean = applicationContext.getBean(beanDefinitionName);
Map<Method, XxlJob> annotatedMethods = null;
try {
//获取到加了@XxlJob注解的方法
annotatedMethods = MethodIntrospector.selectMethods(bean.getClass(),
new MethodIntrospector.MetadataLookup<XxlJob>() {
@Override
public XxlJob inspect(Method method) {
return AnnotatedElementUtils.findMergedAnnotation(method, XxlJob.class);
}
});
} catch (Throwable ex) {
logger.error("xxl-job method-jobhandler resolve error for bean[" + beanDefinitionName + "].", ex);
}
//没有加注解的方法,则跳过,继续下一个bean
if (annotatedMethods==null || annotatedMethods.isEmpty()) {
continue;
}
for (Map.Entry<Method, XxlJob> methodXxlJobEntry : annotatedMethods.entrySet()) {
Method method = methodXxlJobEntry.getKey();
XxlJob xxlJob = methodXxlJobEntry.getValue();
if (xxlJob == null) {
continue;
}
String name = xxlJob.value();
//任务名不能为空
if (name.trim().length() == 0) {
throw new RuntimeException("xxl-job method-jobhandler name invalid, for[" + bean.getClass() + "#" + method.getName() + "] .");
}
//任务名不能重复
if (loadJobHandler(name) != null) {
throw new RuntimeException("xxl-job jobhandler[" + name + "] naming conflicts.");
}
//方法格式校验public ReturnT execute(String param){}
if (!(method.getParameterTypes().length == 1 && method.getParameterTypes()[0].isAssignableFrom(String.class))) {
throw new RuntimeException("xxl-job method-jobhandler param-classtype invalid, for[" + bean.getClass() + "#" + method.getName() + "] , " +
"The correct method format like \" public ReturnT execute(String param) \" ." );
}
if (!method.getReturnType().isAssignableFrom(ReturnT.class)) {
throw new RuntimeException("xxl-job method-jobhandler return-classtype invalid, for[" + bean.getClass() + "#" + method.getName() + "] , " +
"The correct method format like \" public ReturnT execute(String param) \" ." );
}
method.setAccessible(true);
// init and destory
Method initMethod = null;
Method destroyMethod = null;
//@XxlJob注解中的init方法
if (xxlJob.init().trim().length() > 0) {
try {
initMethod = bean.getClass().getDeclaredMethod(xxlJob.init());
initMethod.setAccessible(true);
} catch (NoSuchMethodException e) {
throw new RuntimeException("xxl-job method-jobhandler initMethod invalid, for[" + bean.getClass() + "#" + method.getName() + "] .");
}
}
//@XxlJob注解中的destory方法
if (xxlJob.destroy().trim().length() > 0) {
try {
destroyMethod = bean.getClass().getDeclaredMethod(xxlJob.destroy());
destroyMethod.setAccessible(true);
} catch (NoSuchMethodException e) {
throw new RuntimeException("xxl-job method-jobhandler destroyMethod invalid, for[" + bean.getClass() + "#" + method.getName() + "] .");
}
}
//注册到jobHandlerRepository中
registJobHandler(name, new MethodJobHandler(bean, method, initMethod, destroyMethod));
}
}
}
注册比较简单,其实就是将JobHandler放到一个map中,map的key就是jobHandler的名字,value就是jobhandler。
// ---------------------- job handler repository ----------------------
private static ConcurrentMap<String, IJobHandler> jobHandlerRepository = new ConcurrentHashMap<String, IJobHandler>();
public static IJobHandler registJobHandler(String name, IJobHandler jobHandler){
logger.info(">>>>>>>>>>> xxl-job register jobhandler success, name:{}, jobHandler:{}", name, jobHandler);
return jobHandlerRepository.put(name, jobHandler);
}
(3)start
注册扫描完所有的jobhandler之后,就运行到XxlJobSpringExecutor的父类XxlJobExecutor的start()方法中。
public void start() throws Exception {
// init logpath 初始化日志路径
XxlJobFileAppender.initLogPath(logPath);
// init invoker, admin-client 创建调度器客户端
initAdminBizList(adminAddresses, accessToken);
// init JobLogFileCleanThread 初始化日志清理线程
JobLogFileCleanThread.getInstance().start(logRetentionDays);
// init TriggerCallbackThread 初始化回调线程
TriggerCallbackThread.getInstance().start();
// init executor-server 初始化执行器服务
initEmbedServer(address, ip, port, appname, accessToken);
}
- initAdminBizList创建调度器客户端,是执行器用来连接调度器的,可以获得所有的调度器地址并封装到一个list中。
private static List adminBizList;
- Trigger回调线程使用来处理任务执行完毕后的回调,这个后面再说。
- 从initEmbedServer方法进入执行器的创建,到embedServer.start()方法。
// start
embedServer = new EmbedServer();
embedServer.start(address, port, appname, accessToken);
thread = new Thread(new Runnable() {
@Override
public void run(){
...}
});
在这个方法中,new了一个线程来异步的执行,那么我们直接看线程的run()方法中的代码。
public void run() {
// param
EventLoopGroup bossGroup = new NioEventLoopGroup();
EventLoopGroup workerGroup = new NioEventLoopGroup();
//创建一个线程池,由名字可以看出是业务线程池
ThreadPoolExecutor bizThreadPool = new ThreadPoolExecutor(
0,
200,
60L,
TimeUnit.SECONDS,
new LinkedBlockingQueue<Runnable>(2000),
new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "xxl-rpc, EmbedServer bizThreadPool-" + r.hashCode());
}
},
new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
throw new RuntimeException("xxl-job, EmbedServer bizThreadPool is EXHAUSTED!");
}
});
try {
// start server 创建一个Netty的包,bootstrap
ServerBootstrap bootstrap = new ServerBootstrap();
bootstrap.group(bossGroup, workerGroup)
.channel(NioServerSocketChannel.class)
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel channel) throws Exception {
channel.pipeline()
.addLast(new IdleStateHandler(0, 0, 30 * 3, TimeUnit.SECONDS)) // beat 3N, close if idle
.addLast(new HttpServerCodec())
.addLast(new HttpObjectAggregator(5 * 1024 * 1024)) // merge request & reponse to FULL
.addLast(new EmbedHttpServerHandler(executorBiz, accessToken, bizThreadPool));
}
})
.childOption(ChannelOption.SO_KEEPALIVE, true);
// bind 绑定端口启动
ChannelFuture future = bootstrap.bind(port).sync();
logger.info(">>>>>>>>>>> xxl-job remoting server start success, nettype = {}, port = {}", EmbedServer.class, port);
// start registry 将执行器注册到注册中心中(传入执行器的名字和admin注册地址)
startRegistry(appname, address);
// wait util stop
future.channel().closeFuture().sync();
} catch (InterruptedException e) {
if (e instanceof InterruptedException) {
logger.info(">>>>>>>>>>> xxl-job remoting server stop.");
} else {
logger.error(">>>>>>>>>>> xxl-job remoting server error.", e);
}
} finally {
// stop
try {
workerGroup.shutdownGracefully();
bossGroup.shutdownGracefully();
} catch (Exception e) {
logger.error(e.getMessage(), e);
}
}
}
});
在startRegistry(appname, address);方法中启动了这个线程:
ExecutorRegistryThread.getInstance().start(appname, address);
在这个start(appname,address);方法中也是新建了一个线程来执行,那么就看这个线程的run()方法。
首先拿到调度器列表,XxlJobExecutor.getAdminBizList()其实就是前面的initAdminBizList()方法中写入到的一个ist。
for (AdminBiz adminBiz: XxlJobExecutor.getAdminBizList()) {
ReturnT<String> registryResult = adminBiz.registry(registryParam);
}
然后挨个注册上去,调用的是AdminBizClient的registry方法。实际上就是调用admin的一个注册接口进行注册(core包中)。
调用接口地址:http://127.0.0.1:8080/xxl-job-admin/api/registry
@Override
public ReturnT<String> registry(RegistryParam registryParam) {
return XxlJobRemotingUtil.postBody(addressUrl + "api/registry", accessToken, timeout, registryParam, String.class);
}
请求的是admin客户端的com.xxl.job.admin.controller.JobApiController中的api,admin会将调用此接口的执行器存入到数据库表xxl_job_registry中。
到此为止,执行器的注册就完成了。
(4)小结
2.调度器的启动与任务执行
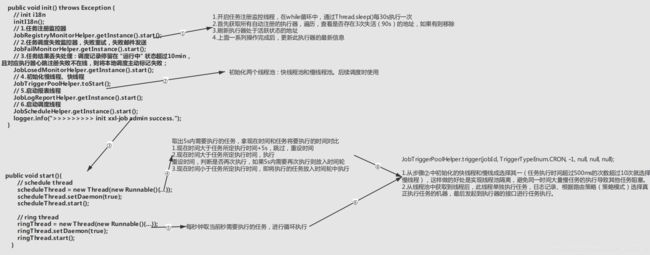
调度中心也从config配置类XxlJobAdminConfig开始,实现了InitializingBean接口,会在初始化的时候调用afterPropertiesSet()方法。
@Override
public void afterPropertiesSet() throws Exception {
adminConfig = this;
xxlJobScheduler = new XxlJobScheduler();
xxlJobScheduler.init();
}
在init()方法中初始化了调度中心。
public void init() throws Exception {
// init i18n
initI18n();
// 1.任务注册监控器
JobRegistryMonitorHelper.getInstance().start();
// 2.任务调度失败监控器,失败重试,失败邮件发送
JobFailMonitorHelper.getInstance().start();
// 3.任务结果丢失处理
JobLosedMonitorHelper.getInstance().start();
// 4.trigger pool 启动 创建了两个调度线程池,一个快线程池,一个慢线程池
JobTriggerPoolHelper.toStart();
// 5.log report启动 报表线程
JobLogReportHelper.getInstance().start();
// 6.start-schedule 创建了两个线程,一个调度线程,一个时间论线程
JobScheduleHelper.getInstance().start();
logger.info(">>>>>>>>> init xxl-job admin success.");
}
挑选其中几个比较重要的方法分析。
(1)JobRegistryMonitorHelper.getInstance().start();
启动任务注册监控器线程,方法内单独启动了一个线程做while循环,30秒执行一次,那么我们直接看run()方法内的代码。
- 首先从表
xxl_job_group中拿到所有自动注册的执行器(之所以不拿非自动注册的,是因为写死的执行器地址在执行器端配置文件中配置,不归调度中心管理) - 不为空,则拿表
xxl_job_registry中更新时间超过3次循环(90s)的地址,如果执行器处于活跃状态,每次while循环都会刷新更新时间,超过3次调度中心则认为它已经失活,从表xxl_job_registry中移除。 - 找到库中执行器处于活跃状态的执行器,因为调度中心支持多执行器多集群的形式注册,所以将执行器封装为一个Map<执行器名称,List<执行器地址>>
- 循环遍历每一个执行器,对表
xxl_job_group中执行器进行更新(执行器id,执行器名称,执行器类型【自动注册,手动注册】,执行器地址列表(’,'分割)) - 该循环每30s执行一次。
TimeUnit.SECONDS.sleep(RegistryConfig.BEAT_TIMEOUT);
@Override
public void run() {
while (!toStop) {
try {
// auto registry group 自动注册的执行器
List<XxlJobGroup> groupList = XxlJobAdminConfig.getAdminConfig().getXxlJobGroupDao().findByAddressType(0);
if (groupList!=null && !groupList.isEmpty()) {
// 查询更新时间超过90s的执行器
List<Integer> ids = XxlJobAdminConfig.getAdminConfig().getXxlJobRegistryDao().findDead(RegistryConfig.DEAD_TIMEOUT, new Date());
if (ids!=null && ids.size()>0) {
//移除
XxlJobAdminConfig.getAdminConfig().getXxlJobRegistryDao().removeDead(ids);
}
// 将执行器封装为一个HashMap<执行器名,该执行器IPs>
HashMap<String, List<String>> appAddressMap = new HashMap<String, List<String>>();
List<XxlJobRegistry> list = XxlJobAdminConfig.getAdminConfig().getXxlJobRegistryDao().findAll(RegistryConfig.DEAD_TIMEOUT, new Date());
if (list != null) {
for (XxlJobRegistry item: list) {
if (RegistryConfig.RegistType.EXECUTOR.name().equals(item.getRegistryGroup())) {
String appname = item.getRegistryKey();
List<String> registryList = appAddressMap.get(appname);
if (registryList == null) {
registryList = new ArrayList<String>();
}
if (!registryList.contains(item.getRegistryValue())) {
registryList.add(item.getRegistryValue());
}
appAddressMap.put(appname, registryList);
}
}
}
// 循环遍历每一个执行器,更新app_name,title,address_type,address_list
for (XxlJobGroup group: groupList) {
List<String> registryList = appAddressMap.get(group.getAppname());
String addressListStr = null;
if (registryList!=null && !registryList.isEmpty()) {
Collections.sort(registryList);
addressListStr = "";
for (String item:registryList) {
addressListStr += item + ",";
}
addressListStr = addressListStr.substring(0, addressListStr.length()-1);
}
group.setAddressList(addressListStr);
XxlJobAdminConfig.getAdminConfig().getXxlJobGroupDao().update(group);
}
}
} catch (Exception e) {
if (!toStop) {
logger.error(">>>>>>>>>>> xxl-job, job registry monitor thread error:{}", e);
}
}
try {
//每隔30秒循环一次
TimeUnit.SECONDS.sleep(RegistryConfig.BEAT_TIMEOUT);
} catch (InterruptedException e) {
if (!toStop) {
logger.error(">>>>>>>>>>> xxl-job, job registry monitor thread error:{}", e);
}
}
}
logger.info(">>>>>>>>>>> xxl-job, job registry monitor thread stop");
}
(2)JobScheduleHelper.getInstance().start();
此方法中创建了两个线程:scheduleThread、ringThread,我们分别看其run()方法。
① scheduleThread
TimeUnit.MILLISECONDS.sleep(5000 - System.currentTimeMillis()%1000 );先随机睡眠了4~5s,为了防止执行器集中启动过多而导致的资源竞争。preReadCount计算预读取的任务书,这里默认为6000。- 获取数据库的排他锁,因为调度中心集群的所有节点连接的是同一个数据库,同一时间只允许有一台调度中心获取任务信息。(如果没有获取到锁,说明集群中有其他调度中心在加载任务,只能等其他节点提交事务或者回滚事务后才能获取到锁)
- 查找运行状态(status=1)且下次触发时间小于[现在时间+5s]的任务。也就是说查询5s内需要执行的启动中的任务。
- 接下来遍历所有任务,分了
三种情况处理
nowTime > jobInfo.getTriggerNextTime() + PRE_READ_MS[现在时间]大于[任务所定时间+5s],那么调度中心是不执行的,直接刷新该任务的下次执行时间(根据cron表达式计算)。
nowTime > jobInfo.getTriggerNextTime()[现在时间]大于[任务所定时间],说明已经超过了任务规定的执行时间,应该立即触发调度,此时是正常触发。
直接通过JobTriggerPoolHelper.trigger(jobInfo.getId(), TriggerTypeEnum.CRON, -1, null, null, null);方法执行任务(内也是另起一个线程执行),然后刷新下次触发时间(根据cron表达式计算)。
更新完成后,再次判断此任务的执行时间与此时相比是否还在5s内,如果还在5s内,则放入时间轮内。
完成后再次刷新下次执行时间。nowTime <= jobInfo.getTriggerNextTime()[任务触发时间]大于[现在时间],且小于[现在时间+5s](最前面sql限制),也就是说5s内会到达此任务的下次执行时间。
此时直接放入时间轮中。再刷新下次任务执行时间(实际上此时任务在时间轮中还没有执行,但是提前刷新了任务的下次执行时间,意思就是放入时间轮交给时间轮线程执行,那么我就认为此任务本次已经执行完毕了)
- 处理完毕后,根据刷新的任务执行时间持久化到数据库
xxl_job_info中。 - 等到本轮所有任务处理完毕,计算处理时间,如果本轮处理时间小于大于1s,直接开始下轮处理。如果本轮处理时间小于1s,则睡眠到下一个整秒后开始下轮处理。
scheduleThread = new Thread(new Runnable() {
@Override
public void run() {
try {
TimeUnit.MILLISECONDS.sleep(5000 - System.currentTimeMillis()%1000 );
} catch (InterruptedException e) {
if (!scheduleThreadToStop) {
logger.error(e.getMessage(), e);
}
}
logger.info(">>>>>>>>> init xxl-job admin scheduler success.");
// pre-read count: treadpool-size * trigger-qps (each trigger cost 50ms, qps = 1000/50 = 20)
int preReadCount = (XxlJobAdminConfig.getAdminConfig().getTriggerPoolFastMax() + XxlJobAdminConfig.getAdminConfig().getTriggerPoolSlowMax()) * 20;
while (!scheduleThreadToStop) {
// Scan Job
long start = System.currentTimeMillis();
Connection conn = null;
Boolean connAutoCommit = null;
PreparedStatement preparedStatement = null;
boolean preReadSuc = true;
try {
conn = XxlJobAdminConfig.getAdminConfig().getDataSource().getConnection();
connAutoCommit = conn.getAutoCommit();
conn.setAutoCommit(false);
preparedStatement = conn.prepareStatement( "select * from xxl_job_lock where lock_name = 'schedule_lock' for update" );
preparedStatement.execute();
// 1、pre read
long nowTime = System.currentTimeMillis();
List<XxlJobInfo> scheduleList = XxlJobAdminConfig.getAdminConfig().getXxlJobInfoDao().scheduleJobQuery(nowTime + PRE_READ_MS, preReadCount);
if (scheduleList!=null && scheduleList.size()>0) {
// 2、push time-ring
for (XxlJobInfo jobInfo: scheduleList) {
// time-ring jump
if (nowTime > jobInfo.getTriggerNextTime() + PRE_READ_MS) {
// 2.1、trigger-expire > 5s:pass && make next-trigger-time
//如果现在的时间超过 取出任务时间+5,则丢弃,并根据cron表达式刷新任务下次执行时间
logger.warn(">>>>>>>>>>> xxl-job, schedule misfire, jobId = " + jobInfo.getId());
// fresh next
refreshNextValidTime(jobInfo, new Date());
} else if (nowTime > jobInfo.getTriggerNextTime()) {
// 1、trigger
JobTriggerPoolHelper.trigger(jobInfo.getId(), TriggerTypeEnum.CRON, -1, null, null, null);
logger.debug(">>>>>>>>>>> xxl-job, schedule push trigger : jobId = " + jobInfo.getId() );
// 2、fresh next
refreshNextValidTime(jobInfo, new Date());
// next-trigger-time in 5s, pre-read again
if (jobInfo.getTriggerStatus()==1 && nowTime + PRE_READ_MS > jobInfo.getTriggerNextTime()) {
// 1、make ring second
int ringSecond = (int)((jobInfo.getTriggerNextTime()/1000)%60);
// 2、push time ring
pushTimeRing(ringSecond, jobInfo.getId());
// 3、fresh next
refreshNextValidTime(jobInfo, new Date(jobInfo.getTriggerNextTime()));
}
} else {
// 2.3、trigger-pre-read:time-ring trigger && make next-trigger-time
// 如果其他情况(现在时间 小于任务所定时间),则放入时间轮中。
// 因为取的是[任务所定时间]<=[现在时间+5s]的任务,所以有可能出现现在时间小于任务所定时间的任务。
// 比如 执行时间:12:00:00,现在时间:11:59:59。还没有到达任务执行时间此时直接放入时间轮中执行
// 1、make ring second
int ringSecond = (int)((jobInfo.getTriggerNextTime()/1000)%60);
// 2、push time ring
pushTimeRing(ringSecond, jobInfo.getId());
// 3、fresh next
refreshNextValidTime(jobInfo, new Date(jobInfo.getTriggerNextTime()));
}
}
// 3、update trigger info
for (XxlJobInfo jobInfo: scheduleList) {
XxlJobAdminConfig.getAdminConfig().getXxlJobInfoDao().scheduleUpdate(jobInfo);
}
} else {
preReadSuc = false;
}
} catch (Exception e) {
...} finally {
...}
long cost = System.currentTimeMillis()-start;
// 本轮任务是否小于1s
if (cost < 1000) {
// scan-overtime, not wait
try {
//如果本轮没有获取到5s内需要处理的任务,直接等待5s
//否则等待到下一个整秒再开始下轮处理。
TimeUnit.MILLISECONDS.sleep((preReadSuc?1000:PRE_READ_MS) - System.currentTimeMillis()%1000);
} catch (InterruptedException e) {
if (!scheduleThreadToStop) {
logger.error(e.getMessage(), e);
}
}
}
}
logger.info(">>>>>>>>>>> xxl-job, JobScheduleHelper#scheduleThread stop");
}
});
② 任务触发
在①中的第二种情况,会直接触发任务,调用代码:
JobTriggerPoolHelper.trigger(jobInfo.getId(),TriggerTypeEnum.CRON, -1, null, null, null);
接着进入addTrigger()方法
helper.addTrigger(jobId,triggerType,failRetryCount,executorShardingParam, executorParam, addressList);
在addTriger()方法中,使用了我们上面JobTriggerPoolHelper.toStart();创建的两个线程池[快线程池]和慢线程池。默认使用的是快线程池,如果任务执行时间超过500毫秒的次数超过了10次,则转为慢线程池,在方法的finally里面计算了任务执行时间和执行时间超过500毫秒的次数。
这么做的好处是,快任务和慢任务做线程池隔离,避免慢任务数量过多影响其他任务调度的正常使用(任务执行时间超过500毫秒10次则用慢线程池中的线程执行)
// 选择线程池。快线程池、慢线程池
ThreadPoolExecutor triggerPool_ = fastTriggerPool;
AtomicInteger jobTimeoutCount = jobTimeoutCountMap.get(jobId);
if (jobTimeoutCount!=null && jobTimeoutCount.get() > 10) {
// job-timeout 10 times in 1 min
triggerPool_ = slowTriggerPool;
}
接下来看真正执行任务的方法:
XxlJobTrigger.trigger(jobId, triggerType, failRetryCount, executorShardingParam, executorParam, addressList);
- 根据任务id加载任务数据封装为XxlJobInfo
- 获取到任务执行时输入的参数param
- 获取到任务的失败重试次数,如果前面带过来的是小于0的,则用最新查出来的重试次数
- 通过XxlJobInfo中携带的group即执行器id查询出执行器的信息XxlJobGroup。包括执行器的地址、执行器的名称等等
- 先跳过分片广播任务直接来到
processTrigger(group, jobInfo, finalFailRetryCount, triggerType, shardingParam[0], shardingParam[1]);
public static void trigger(int jobId,
TriggerTypeEnum triggerType,
int failRetryCount,
String executorShardingParam,
String executorParam,
String addressList) {
// 加载任务数据
XxlJobInfo jobInfo = XxlJobAdminConfig.getAdminConfig().getXxlJobInfoDao().loadById(jobId);
if (jobInfo == null) {
logger.warn(">>>>>>>>>>>> trigger fail, jobId invalid,jobId={}", jobId);
return;
}
if (executorParam != null) {
//获取到任务执行输入的参数
jobInfo.setExecutorParam(executorParam);
}
//获取到任务的失败重试次数,如果前面带过来的是小于0的,则用最新查出来的重试次数
int finalFailRetryCount = failRetryCount>=0?failRetryCount:jobInfo.getExecutorFailRetryCount();
//从数据库中查询到该任务的[执行器]信息XxlJobGroup,包括执行器的地址、执行器的名称等等
XxlJobGroup group = XxlJobAdminConfig.getAdminConfig().getXxlJobGroupDao().load(jobInfo.getJobGroup());
// cover addressList
if (addressList!=null && addressList.trim().length()>0) {
group.setAddressType(1);
group.setAddressList(addressList.trim());
}
int[] shardingParam = null;
//如果是分片广播任务则走这个
if (executorShardingParam!=null){
String[] shardingArr = executorShardingParam.split("/");
if (shardingArr.length==2 && isNumeric(shardingArr[0]) && isNumeric(shardingArr[1])) {
shardingParam = new int[2];
shardingParam[0] = Integer.valueOf(shardingArr[0]);
shardingParam[1] = Integer.valueOf(shardingArr[1]);
}
}
if (ExecutorRouteStrategyEnum.SHARDING_BROADCAST==ExecutorRouteStrategyEnum.match(jobInfo.getExecutorRouteStrategy(), null)
&& group.getRegistryList()!=null && !group.getRegistryList().isEmpty()
&& shardingParam==null) {
for (int i = 0; i < group.getRegistryList().size(); i++) {
//执行任务调度
processTrigger(group, jobInfo, finalFailRetryCount, triggerType, i, group.getRegistryList().size());
}
} else {
//如果不是分片任务,则传入0,1
if (shardingParam == null) {
shardingParam = new int[]{
0, 1};
}
//执行任务调度
processTrigger(group, jobInfo, finalFailRetryCount, triggerType, shardingParam[0], shardingParam[1]);
}
}
processTrigger
-
此方法中前面是获取到一些参数,然后记录日志,初始化调度Trigger参数等操作
-
然后根据路由策略选择执行方式。如果是分片广播,则所有节点都需要参与负载都需要执行(通过外层方法的for循环,传入total和index这里计算出本次实际需要执行的address)
-
否则根据配置的策略获取执行器地址并封装到
routAddressResult中,并判断机器是否正常可用,可用则放入address中。
这里路由策略的选择使用的是策略模式。
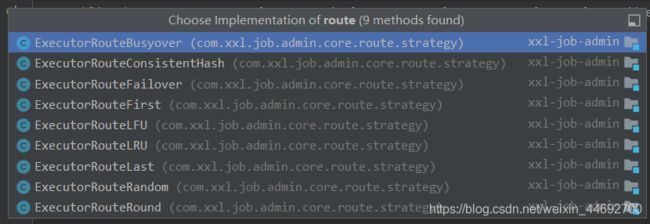
-
triggerResult = runExecutor(triggerParam, address);方法触发远程的执行器。return XxlJobRemotingUtil.postBody(addressUrl +"run",accessToken, timeout, triggerParam, String.class);这里就调用了所选定的执行器地址的远程接口
http://127.0.0.1:9999/run,执行器收到调用请求后会执行业务代码。
后续再更新执行器接收到请求后的代码逻辑。 -
更新本次调度的日志记录等信息。
private static void processTrigger(XxlJobGroup group, XxlJobInfo jobInfo, int finalFailRetryCount, TriggerTypeEnum triggerType, int index, int total){
// param
...
// 1、save log-id
...
// 2、init trigger-param
...
// 3、init address
String address = null;
ReturnT<String> routeAddressResult = null;
if (group.getRegistryList()!=null && !group.getRegistryList().isEmpty()) {
if (ExecutorRouteStrategyEnum.SHARDING_BROADCAST == executorRouteStrategyEnum) {
if (index < group.getRegistryList().size()) {
address = group.getRegistryList().get(index);
} else {
address = group.getRegistryList().get(0);
}
} else {
routeAddressResult = executorRouteStrategyEnum.getRouter().route(triggerParam, group.getRegistryList());
if (routeAddressResult.getCode() == ReturnT.SUCCESS_CODE) {
address = routeAddressResult.getContent();
}
}
} else {
routeAddressResult = new ReturnT<String>(ReturnT.FAIL_CODE, I18nUtil.getString("jobconf_trigger_address_empty"));
}
// 4、trigger remote executor
ReturnT<String> triggerResult = null;
if (address != null) {
triggerResult = runExecutor(triggerParam, address);
} else {
triggerResult = new ReturnT<String>(ReturnT.FAIL_CODE, null);
}
// 5、collection trigger info
...
// 6、save log trigger-info
...
logger.debug(">>>>>>>>>>> xxl-job trigger end, jobId:{}", jobLog.getId());
}
到这里任务调度线程,和任务执行线程代码已经走完了,前面讲到还没到任务触发时间的任务将会被会被扔到时间轮中执行。
1.任务执行后,更新后的下次执行时间还小于[现在时间+5s]。
2.任务的[执行时间]大于[现在时间]且小于[现在时间+5s])。
所以说XXL-JOB的时间轮只会存储将来5s内需要执行的任务,这也是XXL-JOB只有一个时间轮的原因。
什么是时间轮呢?
③ XXL-JOB中的时间轮
因为XXL-JOB中的时间轮只存储将来5s内需要执行的任务,只有一个秒轮,并不涉及到分层时间轮。所以我们这里就简单介绍下时间轮,不深入讲解。

如上图所示,假设现在有12段分别为0~11,且此时钟每次走一个小时,每走一圈需要重新开始。
可以很容易看出在00:00的时候有4个任务将要执行,在3:00的时候有两个任务将要执行。这就可以看作一个时轮,以小时为单位,每小时做一些任务操作。
如果用数据结构来表示这样一个抽象结构的话,要怎么表示呢?
可以用Map这样的结构来表示此时轮,map的key就是0~11分别对应0点到11点,而0点的四个任务则可以表示为一个List,当时间来到零点时就取出这四个任务执行。
上面我们举例为一个以时为单位的时间轮,实际上XXL-JOB中是以秒为单位的秒轮
private volatile static Map<Integer, List<Integer>> ringData = new ConcurrentHashMap<>();
key为0~59的数字,value为一个list,list中存储的是JOB的id。可以做出猜想,每秒钟,从map中拿到list,然后一个个执行。
了解了XXL-JOB中的时间轮结构,下面看时间轮线程做了哪些操作。
④ ringThread
- 时间轮线程刚开始执行,先对齐秒数,休眠当前秒数模以1000的余数,相当于下一个整秒。
- 然后进入一个while循环。获取当前秒数。
- 根据当前秒数和上一秒数获取到需要调度的任务,并从时间轮中移除掉取出的任务。
(nowSecond+60-i)%60也能算出一个0~59的数值,比如现在26秒,获取的是26、25的任务数据。for (int i = 0; i < 2; i++) { List<Integer> tmpData = ringData.remove( (nowSecond+60-i)%60 ); if (tmpData != null) { ringItemData.addAll(tmpData); } } - 获取到需要执行的任务后,循环逐个执行。
JobTriggerPoolHelper.trigger(jobId, TriggerTypeEnum.CRON, -1, null, null, null); - 和上面一样实际上就是向执行器发送调度请求。
ringThread = new Thread(new Runnable() {
@Override
public void run() {
// 对齐秒数
try {
TimeUnit.MILLISECONDS.sleep(1000 - System.currentTimeMillis()%1000 );
} catch (InterruptedException e) {
if (!ringThreadToStop) {
logger.error(e.getMessage(), e);
}
}
while (!ringThreadToStop) {
try {
// 初始化调度数据
List<Integer> ringItemData = new ArrayList<>();
//获取当前秒数
int nowSecond = Calendar.getInstance().get(Calendar.SECOND);
//这里取的是当前秒数和上一秒数,避免执行时间过长导致漏秒
for (int i = 0; i < 2; i++) {
List<Integer> tmpData = ringData.remove( (nowSecond+60-i)%60 );
if (tmpData != null) {
ringItemData.addAll(tmpData);
}
}
// ring trigger
logger.debug(">>>>>>>>>>> xxl-job, time-ring beat : " + nowSecond + " = " + Arrays.asList(ringItemData) );
if (ringItemData.size() > 0) {
// do trigger
for (int jobId: ringItemData) {
// do trigger
JobTriggerPoolHelper.trigger(jobId, TriggerTypeEnum.CRON, -1, null, null, null);
}
// clear
ringItemData.clear();
}
} catch (Exception e) {
if (!ringThreadToStop) {
logger.error(">>>>>>>>>>> xxl-job, JobScheduleHelper#ringThread error:{}", e);
}
}
// 睡眠到下一个整秒
try {
TimeUnit.MILLISECONDS.sleep(1000 - System.currentTimeMillis()%1000);
} catch (InterruptedException e) {
if (!ringThreadToStop) {
logger.error(e.getMessage(), e);
}
}
}
logger.info(">>>>>>>>>>> xxl-job, JobScheduleHelper#ringThread stop");
}
});
(3)小结
3.执行器执行任务
还记得执行器端在启动的时候初始化了一个bizThreadPool业务线程池。并且启动了一个9999(默认)端口的Netty服务。
(1)EmbedHttpServerHandler
当调度器端打请求到执行器端时,会走到EmbedServer的内部类EmbedHttpServerHandler的channelRead0()方法中。在此方法,使用了bizThreadPool线程池中的线程来执行任务。
可以取出此次请求所携带的一些参数,比如uri。

在process方法中,首先对必须条件的一些校验,然后根据传入的uri来执行对应的方法

我们这里直接看/run所对应的方法,因为现在是在执行器端,所以要走ExecutorBizImpl类中的run方法。
(2)ExecutorBizImpl
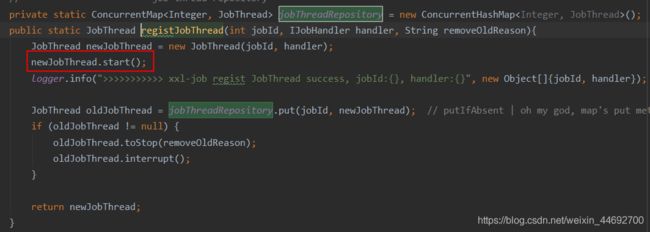
- 第一步先从容器中根据任务id拿到任务的jobThread,再从jobThread中获取到jobhandler。(实际上每一个任务的第一次执行这里拿到的都是null,在执行完毕后再放入内存中存储为一个map:
jobThreadRepository,再次调度的时候直接从内存中获取这个jobhandler)ConcurrentMap<Integer, JobThread> jobThreadRepository; - 然后根据参数传入的运行模式来选择执行哪段逻辑,这里是BEAN模式。
- 再根据任务ID获取到内存中的JobHandler(在执行器端启动的时候放入内存的一个map
jobHandlerRepository中,可以看上面执行器启动注册的时候做的动作)//key是任务id,value是id对应的jobhandler ConcurrentMap<String, IJobHandler> jobHandlerRepository - 判断如果由job线程中获取的handler为空的话,就将其赋值为最新的handler。
- (非第一次执行)需要根据配置的策略采取不同的措施,比如:
- DISCARD_LATER(丢弃后续调度):如果当前线程阻塞,后续任务不再执行,直接
返回失败 - COVER_EARLY(覆盖之前调度):创建一个移除原因,新建一个线程去执行后续任务(杀掉当前线程)
- SERIAL_EXECUTION(单机穿行,默认):对当前线程不做任何处理,并在当前线程的队列里增加一个执行任务(一次只执行一个任务)
- DISCARD_LATER(丢弃后续调度):如果当前线程阻塞,后续任务不再执行,直接
- 重置jobThread(为空则新建),之后启动此job线程,再放入内存中存储
- 最后调用jobThread的
pushTriggerQueue方法把Trigger放入队列中。LinkedBlockingQueue<TriggerParam> triggerQueue;
@Override
public ReturnT<String> run(TriggerParam triggerParam) {
// load old:jobHandler + jobThread
JobThread jobThread = XxlJobExecutor.loadJobThread(triggerParam.getJobId());
IJobHandler jobHandler = jobThread!=null?jobThread.getHandler():null;
String removeOldReason = null;
// valid:jobHandler + jobThread
GlueTypeEnum glueTypeEnum = GlueTypeEnum.match(triggerParam.getGlueType());
if (GlueTypeEnum.BEAN == glueTypeEnum) {
// new jobhandler
IJobHandler newJobHandler = XxlJobExecutor.loadJobHandler(triggerParam.getExecutorHandler());
// valid old jobThread
if (jobThread!=null && jobHandler != newJobHandler) {
// change handler, need kill old thread
removeOldReason = "change jobhandler or glue type, and terminate the old job thread.";
jobThread = null;
jobHandler = null;
}
// valid handler
if (jobHandler == null) {
jobHandler = newJobHandler;
if (jobHandler == null) {
return new ReturnT<String>(ReturnT.FAIL_CODE, "job handler [" + triggerParam.getExecutorHandler() + "] not found.");
}
}
//这里是bean模式先忽略GLUE
} else if (GlueTypeEnum.GLUE_GROOVY == glueTypeEnum) {
...
} else if (glueTypeEnum!=null && glueTypeEnum.isScript()) {
...
} else {
return new ReturnT<String>(ReturnT.FAIL_CODE, "glueType[" + triggerParam.getGlueType() + "] is not valid.");
}
// executor block strategy
if (jobThread != null) {
ExecutorBlockStrategyEnum blockStrategy = ExecutorBlockStrategyEnum.match(triggerParam.getExecutorBlockStrategy(), null);
if (ExecutorBlockStrategyEnum.DISCARD_LATER == blockStrategy) {
// discard when running
if (jobThread.isRunningOrHasQueue()) {
return new ReturnT<String>(ReturnT.FAIL_CODE, "block strategy effect:"+ExecutorBlockStrategyEnum.DISCARD_LATER.getTitle());
}
} else if (ExecutorBlockStrategyEnum.COVER_EARLY == blockStrategy) {
// kill running jobThread
if (jobThread.isRunningOrHasQueue()) {
removeOldReason = "block strategy effect:" + ExecutorBlockStrategyEnum.COVER_EARLY.getTitle();
jobThread = null;
}
} else {
// just queue trigger
}
}
// replace thread (new or exists invalid)
if (jobThread == null) {
jobThread = XxlJobExecutor.registJobThread(triggerParam.getJobId(), jobHandler, removeOldReason);
}
// push data to queue
ReturnT<String> pushResult = jobThread.pushTriggerQueue(triggerParam);
return pushResult;
}
(3)JobThread
在(2)中我们知道,每个任务都会启动一个jobThread。
- 实际上JobThread继承了Thread,在start的时候会进入run方法的死循环,不断的从队列里面拿它的任务
triggerParam = triggerQueue.poll(3L, TimeUnit.SECONDS); - 如果任务设置了超时时间则用Feature来执行任务,超时就将
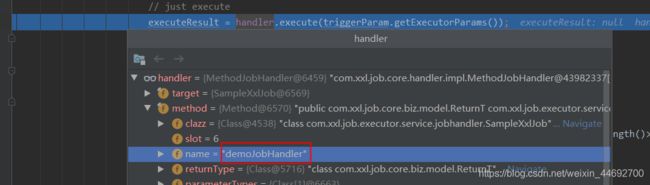
executeResult设置为失败。 - 如果任务没有设置超时时间,则直接执行此任务。最终调用到Handler(任务类)的execute方法,这不就是我们自己的方法么?
- 然后根据自己业务代码的执行逻辑,返回执行结果
executeResult。 - 最后在finally中,将执行结果
executeResult放入到类TriggerCallbackThread的一个回调队列callBackQueue中private LinkedBlockingQueue<HandleCallbackParam> callBackQueue = new LinkedBlockingQueue<HandleCallbackParam>(); public static void pushCallBack(HandleCallbackParam callback){ getInstance().callBackQueue.add(callback); logger.debug(">>>>>>>>>>> xxl-job, push callback request, logId:{}", callback.getLogId()); }
while(!toStop){
running = false;
idleTimes++;
TriggerParam triggerParam = null;
ReturnT<String> executeResult = null;
try {
// to check toStop signal, we need cycle, so wo cannot use queue.take(), instand of poll(timeout)
triggerParam = triggerQueue.poll(3L, TimeUnit.SECONDS);
if (triggerParam!=null) {
running = true;
idleTimes = 0;
triggerLogIdSet.remove(triggerParam.getLogId());
// log filename, like "logPath/yyyy-MM-dd/9999.log"
String logFileName = XxlJobFileAppender.makeLogFileName(new Date(triggerParam.getLogDateTime()), triggerParam.getLogId());
XxlJobFileAppender.contextHolder.set(logFileName);
ShardingUtil.setShardingVo(new ShardingUtil.ShardingVO(triggerParam.getBroadcastIndex(), triggerParam.getBroadcastTotal()));
// execute
XxlJobLogger.log("
----------- xxl-job job execute start -----------
----------- Param:" + triggerParam.getExecutorParams());
if (triggerParam.getExecutorTimeout() > 0) {
// limit timeout
Thread futureThread = null;
try {
final TriggerParam triggerParamTmp = triggerParam;
FutureTask<ReturnT<String>> futureTask = new FutureTask<ReturnT<String>>(new Callable<ReturnT<String>>() {
@Override
public ReturnT<String> call() throws Exception {
return handler.execute(triggerParamTmp.getExecutorParams());
}
});
futureThread = new Thread(futureTask);
futureThread.start();
executeResult = futureTask.get(triggerParam.getExecutorTimeout(), TimeUnit.SECONDS);
} catch (TimeoutException e) {
XxlJobLogger.log("
----------- xxl-job job execute timeout");
XxlJobLogger.log(e);
executeResult = new ReturnT<String>(IJobHandler.FAIL_TIMEOUT.getCode(), "job execute timeout ");
} finally {
futureThread.interrupt();
}
} else {
// just execute
executeResult = handler.execute(triggerParam.getExecutorParams());
}
if (executeResult == null) {
executeResult = IJobHandler.FAIL;
} else {
executeResult.setMsg(
(executeResult!=null&&executeResult.getMsg()!=null&&executeResult.getMsg().length()>50000)
?executeResult.getMsg().substring(0, 50000).concat("...")
:executeResult.getMsg());
executeResult.setContent(null); // limit obj size
}
XxlJobLogger.log("
----------- xxl-job job execute end(finish) -----------
----------- ReturnT:" + executeResult);
} else {
if (idleTimes > 30) {
if(triggerQueue.size() == 0) {
// avoid concurrent trigger causes jobId-lost
XxlJobExecutor.removeJobThread(jobId, "excutor idel times over limit.");
}
}
}
} catch (Throwable e) {
if (toStop) {
XxlJobLogger.log("
----------- JobThread toStop, stopReason:" + stopReason);
}
StringWriter stringWriter = new StringWriter();
e.printStackTrace(new PrintWriter(stringWriter));
String errorMsg = stringWriter.toString();
executeResult = new ReturnT<String>(ReturnT.FAIL_CODE, errorMsg);
XxlJobLogger.log("
----------- JobThread Exception:" + errorMsg + "
----------- xxl-job job execute end(error) -----------");
} finally {
if(triggerParam != null) {
// callback handler info
if (!toStop) {
// commonm
TriggerCallbackThread.pushCallBack(new HandleCallbackParam(triggerParam.getLogId(), triggerParam.getLogDateTime(), executeResult));
} else {
// is killed
ReturnT<String> stopResult = new ReturnT<String>(ReturnT.FAIL_CODE, stopReason + " [job running, killed]");
TriggerCallbackThread.pushCallBack(new HandleCallbackParam(triggerParam.getLogId(), triggerParam.getLogDateTime(), stopResult));
}
}
}
}
(4)TriggerCallbackThread
还记得在执行器启动的时候初始化了一个TriggerCallbackThread,并调用其start()方法(可以看上面执行器的启动与注册),这时候就派上用处了。在start()方法中初始化了两个线程,一个是回调线程,一个是重试线程。
public void start() {
// valid
if (XxlJobExecutor.getAdminBizList() == null) {
logger.warn(">>>>>>>>>>> xxl-job, executor callback config fail, adminAddresses is null.");
return;
}
// callback
triggerCallbackThread = new Thread(()->{
...});
triggerCallbackThread.setDaemon(true);
triggerCallbackThread.setName("xxl-job, executor TriggerCallbackThread");
triggerCallbackThread.start();
// retry
triggerRetryCallbackThread = new Thread(()->{
...});
triggerRetryCallbackThread.setDaemon(true);
triggerRetryCallbackThread.start();
}
①triggerCallbackThread
- callback线程中一个while循环不断的消费回调队列中的内容
- 在doCallback()方法里面请求了调度器的回调接口,写入回调结果。
这里请求的是调度器接口http://127.0.0.1:8080/xxl-job-admin/api/callback - 走到AdminBizImpl的callback方法中,如果由子任务就回去调度子任务(还是以同样的方式调用),否则就在表
xxl_job_log中更新调度信息。

triggerCallbackThread = new Thread(() -> {
// normal callback
while(!toStop){
try {
HandleCallbackParam callback = getInstance().callBackQueue.take();
if (callback != null) {
// callback list param
List<HandleCallbackParam> callbackParamList = new ArrayList<HandleCallbackParam>();
int drainToNum = getInstance().callBackQueue.drainTo(callbackParamList);
callbackParamList.add(callback);
// callback, will retry if error
if (callbackParamList!=null && callbackParamList.size()>0) {
doCallback(callbackParamList);
}
}
} catch (Exception e) {
if (!toStop) {
logger.error(e.getMessage(), e);
}
}
}
// last callback
try {
List<HandleCallbackParam> callbackParamList = new ArrayList<HandleCallbackParam>();
int drainToNum = getInstance().callBackQueue.drainTo(callbackParamList);
if (callbackParamList!=null && callbackParamList.size()>0) {
doCallback(callbackParamList);
}
} catch (Exception e) {
if (!toStop) {
logger.error(e.getMessage(), e);
}
}
logger.info(">>>>>>>>>>> xxl-job, executor callback thread destory.");
});
②triggerRetryCallbackThread
此线程主要监控回调失败的日志,如果有此类日志,则会发起重试,重新回调。
4.总结