Unity性能优化系列—渲染模块
我们曾在四年前对于Unity的主流模块的性能优化知识点逐一做过讲解,俗称“小白版”。随着这几年引擎本身、硬件设备、制作标准等等的升级,UWA也不断更新优化规则和方法并持续输出给广大开发者。作为"升级版"的性能优化手册,【Unity性能优化系列】将力图以浅显易懂的表达,让更多开发者可以受用。本期就将分享渲染模块相关的知识点。
移动端的优化,渲染是一个逃不掉的话题。作为性能开销的大头,几乎所有的游戏都离不开场景、物体和特效的渲染。如何在优秀的场景视觉效果和流畅的运行中达到最佳的平衡,一直是策划、美术与程序大佬们都头疼的问题。

一、影响渲染效率的两个最基本的参数:DrawCall和Triangle
1、DrawCall
在GOT Online的Overview模式中,我们可以在渲染模块中看到DrawCall曲线,在这个曲线中可以看到具体的的DrawCall数量以及Batch数量。如下图所示:

目前,我们建议在中低端机型上Batch的主体范围(5%~95%)控制在[0,250]以内。
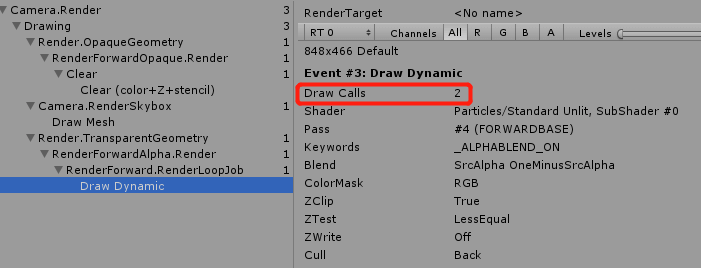
在Unity中,我们需要区分DrawCall和Batch。在一个Batch中会存在有多个DrawCall,如下图中FrameDebugger中可以看到两个默认的ParticleSystem合批成了一个Batch,这样的一个Dynamic Batch中就有2个DrawCall。
降低Batch的方式通常有动态合批、静态合批、GPU Instancing和SRP Batcher这四种,在UWA Day 2020中我们分享了DrawCall与Batch的关系以及这4种Batching的使用详解,供大家参考:《Unity移动游戏项目优化案例分析(上)》。
2、Triangle
通常情况下,Triangle面片数越高会导致渲染的耗时越高,因此在我们的报告中提供了Triangle的使用情况,并有半透明和不透明的区分。一般建议通过LOD工具减少场景中的面片数,进而降低渲染的开销。

需要说明的是,此处的面片数量并不是当前帧场景模型的面片数,而是当前帧所渲染的面片数,其数值不仅与模型面片数有关,也和渲染次数相关。例如:场景中的网格模型面片数为1万,而其使用的Shader拥有2个渲染Pass,或者有2个相机对其同时渲染,那么此处所显示的Triangle数值将为2万。
二、Camera.Render 函数堆栈分析
在渲染模块优化中,很有效的方法是通过Camera.Render函数的具体堆栈来定位具体的性能瓶颈。这些函数可以在无论是真人真机还是GOT Online报告,都可以在【代码效率】中查看。下面是我们优化时常见的几个函数:
1、RenderForward.RenderLoopJob
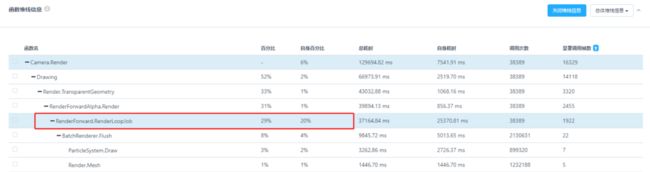
在Camera.Render展开堆栈中,可以看到RenderForward.RenderLoopJob的自身消耗是比较高的,通常是由于Batch数量较高导致的。
2、Culling耗时较高
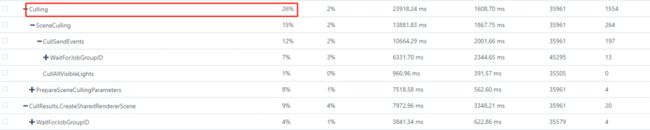
一般来说,Culling的耗时在10%~20%的范围是比较合理的。一般Culling耗时较高的话,可以通过以下几个方面排查:
1)Culling耗时与场景中的GameObject小物件数量的相关性比较大。这种情况建议研发团队优化场景制作方式 ,关注场景中是否存在过多小物件,导致Culling耗时增高。可以考虑采用动态加载、分块显示,或者Culling Group、Culling Distance等方法优化Culling的耗时。
2)如果项目使用了多线程渲染且开启了Occlusion Culling,通常会导致子线程的压力过大导致整体Culling过高。
由于Occlusion Culling需要根据场景中的物体计算遮挡关系,因此开启Occlusion Culling虽然降低了渲染消耗,其本身的性能开销却也是值得注意的,并不一定适用于所有场景。这种情况建议研发团队选择性地关闭一部分Occlusion Culling去测试一下渲染数据的整体消耗进行对比,再决定是否需要开启这个功能。
3、Render.Mesh
Render.Mesh对应的是无法合批的渲染耗时,它的调用次数对应的是相应的Batch数量。下图中,我们可以看到Render.Mesh的调用次数为269,说明场景中有269个不透明对象没有进行合批,数量较高。
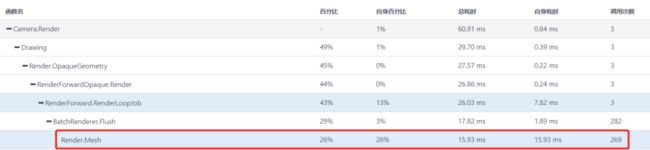
Render.Mesh开销过高,通常是由于不能合批的对象较多导致的,可以从如下几点进行优化:
1)对于不透明的渲染队列,建议对Material的冗余进行排查,如原本一样的材质球因为实例不同而导致不能合批,可以通过UWA的在线AssetBundle检测,对AssetBundle中的Material冗余进行排查。
2)对于半透明的渲染队列,需要区分非NGUI与NGUI的情况,对于使用NGUI的情况,Render.Mesh的调用有很大概率是由UI的DrawCall导致的,Render.Mesh调用次数高说明UI的DrawCall很可能是偏高的,需要排查是否是图集没有合理的打包导致的。
对于非NGUI的情况,那需要考虑半透明的对象是否存在穿插的现象,可以通过调整RenderQueue来增大相同Material的对象进行合批。
4、ParticleSystem.ScheduleGeometryJobs与ParticleSystem.Draw
1)ParticleSystem.ScheduleGeometryJobs,是指在Culling之前主线程要等待子线程计算Particle的位置,然后才能Culling。往往在战斗界面开销较高。
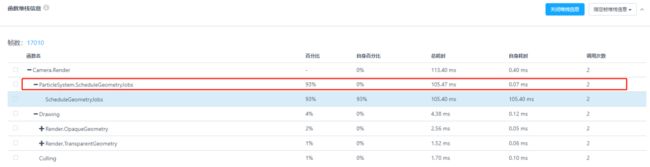
对于该函数的优化,建议研发团队考虑在中低端设备上尽可能降低粒子系统的复杂程度,同时尝试通过视域体对其进行预先裁剪,将视域体外部的粒子系统进行Deactive,从而降低不必要的粒子系统Schedule开销。
2)ParticleSystem.Draw的调用次数对应的是粒子系统的DrawCall数量。
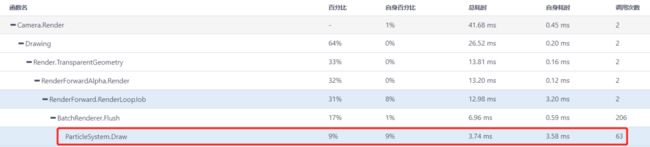
如果该函数调用次数过高,建议研发团队考虑减少粒子系统的数量,可参考UWA真人真机测试报告【内存管理-具体资源信息-粒子系统】中的列表进一步分析和优化。
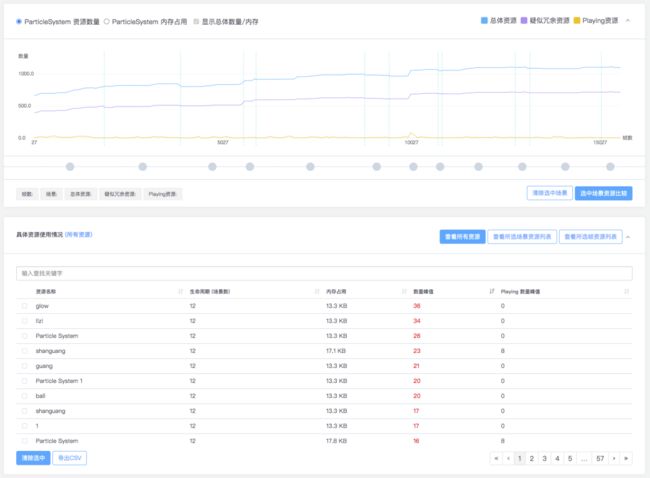
另外,可以通过使用TextureSheetAnimation的方式,或者通过修改Order in Layer减少粒子渲染的穿插从而增大合批的概率,以此来降低DrawCall。
5、Shader.CreateGPUProgram
该API的CPU占用是Shader第一次渲染时产生的耗时,其耗时与渲染Shader的复杂程度相关。
从下图中我们可以看到,在某一帧中Shader.CreateGPUProgram的耗时达到了203.87ms,这个耗时导致游戏的卡顿。
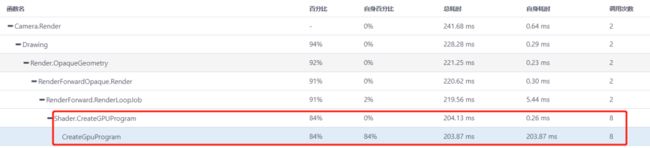
对此,我们可以将Shader通过ShaderVariantCollection进行预加载,在加载后通过ShaderVariantCollection.WarmUp来触发Shader.CreateGPUProgram,并将此SVC进行缓存,从而避免在游戏运行时触发此API的调用,从而避免局部的CPU高耗时。
以下资料可供参考:
《一种Shader变体收集和打包编译优化的思路》
https://answer.uwa4d.com/question/5da86670e84db43d6efbda72
三、开启多线程渲染
开启多线程渲染后,主线程的渲染耗时就会有很明显下降,建议研发团队开启。
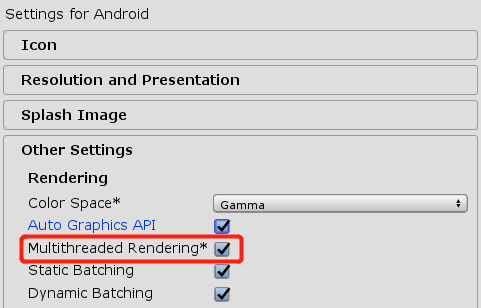
但需要注意的是,由于我们的线上报告的CPU时间占用只统计了主线程的耗时,如果版本开启了多线程渲染,在报告中只能看到主线程的耗时,不利于分析渲染瓶颈。因此我们平时建议大家内部测试的时候,提交两个版本,一个开启多线程渲染,作为Release版本的渲染耗时参考,一个关闭多线程渲染,用于详细分析渲染瓶颈。
四、GPU Instancing
使用GPU Instancing可以一次渲染相同网格的多个副本,但是每个实例可以有不同的参数(例如:Color或Scale),以增加变化。在渲染诸如建筑、树木、草等在场景中重复出现的事物时,GPU Instancing可以有效减少每个场景DrawCall数量,显著提升渲染性能。
但是使用GPU Instancing有如下注意点:
- 兼容的平台及API
- 渲染实例的网格与材质相同
- Shader支持GPU Instancing
- 不支持SkinnedMeshRenderer
在一些特殊情况下,大量半透明物体的GPU Instancing渲染耗时可能会带来很高的耗时,这点我们在UWA DAY 2019的课程《Unity引擎渲染、UI、逻辑代码模块的量化分析和优化方法》中做了详细解释。
五、SRP Batcher
越来越多的团队开始使用URP作为渲染管线,从而通过SRP Batcher大幅提升Batch的合批范围,提升渲染效率。使用URP时,渲染函数堆栈会变为:
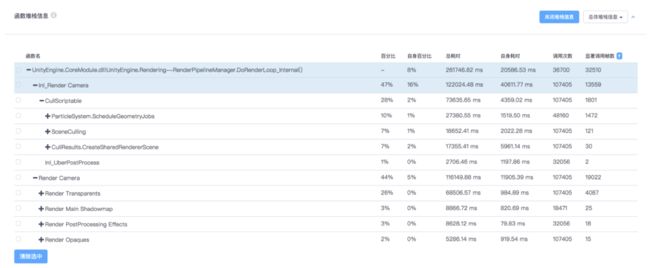
而在使用SRP Batcher时,仍需要注意:
- Shader需要兼容SRP
- SRP Batcher暂时不支持粒子系统
- Shader变体会打断DrawCall的合批
以上就是渲染模块在优化时需要关注的一些问题,如何操作还需要大家结合项目实际情况,同时结合UWA服务可以快速地帮助大家定位到性能瓶颈。