大三Java后端暑期实习面经总结——Java基础篇
博主现在大三在读,从三月开始找暑期实习,总结下了很多面试真题,希望能帮助正在找工作的大家!相关参考都会标注原文链接,尊重原创!
目录
-
- 1. JDK、JRE、JVM的区别和联系
- 2. 采用字节码的好处
- 3. 接口和抽象类的区别
- 4. 面向对象的四大特性
- 5. 面向对象和面向过程
- 6. 静态绑定&动态绑定
- 7. 重载和重写
- 8. Java异常体系
- 9. final关键字
- 10. String、StringBuilder、StringBuffer
- 11. 单例模式
- 12. 工厂模式和建造者模式的区别
- 13. 深拷贝和浅拷贝
- 14. 泛型知识
- 15. Java泛型的原理?什么是泛型擦除机制?
- 16. Java编译器具体是如何擦除泛型的
- 17. Array数组中可以用泛型吗?
- 18. PESC原则&限定通配符和非限定通配符
- 19. Java中List和List\的区别
- 20. for循环和forEach效率问题
- 16. NIO、BIO、AIO
- 17. 什么是反射
- 18. 序列化&反序列化
- 19. 动态代理是什么?有哪些应用?
- 20. 怎么实现动态代理
- 21. 如何实现对象克隆?
参考:
- https://zhuanlan.zhihu.com/p/64147696
- https://www.bilibili.com/video/BV1Eb4y1R7zd?p=2&t=4948
1. JDK、JRE、JVM的区别和联系
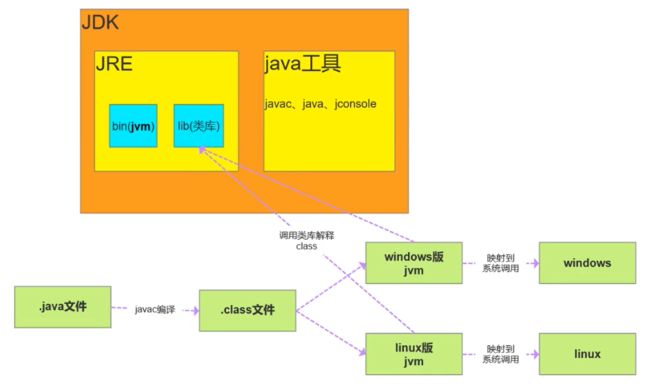
JDK(java程序开发包)=JRE +Tools
JRE=JVM(虚拟机)+API
2. 采用字节码的好处
Java中引入了jvm,即在机器和编译程序之间加了一层抽象的虚拟机器,这台机器在任何平台上都提供给编译程序一个共同的接口。
- 编译程序只需要面向虚拟机,生成虚拟机能够理解的代码,然后由解释器来将虚拟机代码转换为特定系统的机器码来执行。在Java中,这种供虚拟机理解的代码叫做
字节码(.class),它不面向任何特定的处理器,只面向虚拟机 - 每一种平台的解释器是不同的,但是实现的虚拟机是相同的。Java源程序通过编译器进行编译后转换为字节码,字节码在虚拟机上执行,虚拟机将每一条要执行的字节码送给解释器,解释器将其翻译成特定机器上的机器码,然后在特定的机器上运行。这也解释了Java的编译与解释共存的特点。
Java源代码-->编译器-->jvm可执行的java字节码-->jvm中解释器-->机器可执行的二进制机器码-->程序运行
Java语言采用字节码的方式,一定程度上解决了传统解释型语言执行效率低(运行需要解释环境,速度比编译的要慢,占用资源也要多一些)的问题,同时又保留了解释型语言可移植的特点,所以Java程序运行时很高效,此外,由于字节码不针对一种特定的机器,因此Java源程序无需重新编译即可在不同的计算机上运行,实现一次编译,多次运行
3. 接口和抽象类的区别
1️⃣ 从语法上来说
- 抽象类可以存在普通成员函数,而接口中只能存在public abstract方法。
- 抽象类中的成员变量可以是各种类型的,而接口中的成员变量只能是public static final类型的。
- 抽象类只能继承一个,接口可以实现多个
2️⃣ 从设计目的来说
- 接口是用来对类的形为进行约束。也就是提供了一种机制,可以强制要求所有的类具有相同的形为,只约束了行为的有无,不限制形为的具体实现
- 抽象类是为了代码复用。当不同的类具有相同的行为A,且其中一部分形为B的实现方式一致时,可以让这些类都派生于一个抽象类,这个抽象类中实现了B,避免让所有的子类来实现B,以此来达到代码复用的目的。而A-B的部分,交给各个子类自己实现,正是由于这里A-B的行为没有实现,所以抽象类不允许实例化
3️⃣ 从本质上来说
- 接口是对行为的抽象,表达的是
like a的关系,比如 Bird like a Aircraft(鸟像飞行器一样可以飞);接口的核心是定义行为,即接口的实现类可以做什么,至于实现类如何实现,主体是谁,接口并不关心 - 抽象类是 对类本质的抽象,表达的是
is a的关系,比如 BaoMa is a Car(宝马是一辆车);抽象类包含并实现子类的通用特性,将子类存在差异化的特性进行抽象,交给子类去实现
总结:
- 当你关注一个事物的本质的时候,用抽象类;当你关注一个操作的时候,用接口。
- 抽象类的功能要远超过接口,但是,定义抽象类的代价高。因为高级语言来说(从实际设计上来说也是)每个类只能继承一个类。在这个类中,你必须继承或编写出其所有子类的所有共性。虽然接口在功能上会弱化许多,但是它只是针对一个动作的描述。而且你可以在一个类中同时实现多个接口。在设计阶段会降低难度
4. 面向对象的四大特性
1️⃣ 抽象
将一类对象的共同特征总结出来构造类的过程
2️⃣ 封装
将过程和数据包围起来,对数据的访问只能通过特定的接口(例如私有变量的get/set方法)
3️⃣ 继承
从现有类派生出新类的过程
4️⃣ 多态
- 编译时多态:同一方法可根据对象的不同产生不同的效果,也就是
方法的重载 - 运行时多态:父类的引用指向子类对象,一个对象的实际类型确定,但是指向其的引用类型可以有很多
5. 面向对象和面向过程
面向过程(Procedure Oriented)和面向对象(Object Oriented,OO)都是对软件分析、设计和开发的一种思想,它指导着人们以不同的方式去分析、设计和开发软件。早期先有面向过程思想,随着软件规模的扩大,问题复杂性的提高,面向过程的弊端越来越明显的显示出来,出现了面向对象思想并成为目前主流的方式。两者都贯穿于软件分析、设计和开发各个阶段,对应面向对象就分别称为面向对象分析(OOA)、面向对象设计(OOD)和面向对象编程(OOP)。C语言是一种典型的面向过程语言,Java是一种典型的面向对象语言。
面向对象和面向过程是两种不同的处理问题角度
- 面向过程注重事情的每一步以及顺序
- 面向过程诸众事情有哪些参与者(对象),以及各自需要做什么
比如:洗衣机洗衣服
-
面向过程会将任务拆解成一系列的步骤(函数):
1、打开洗衣机–>2、放衣服–>3、放洗衣粉–>4、清洗–>5、烘干
-
面向对象会拆出人和洗衣机两个对象:
人:打开洗衣机放衣服放洗衣粉
洗衣机:清洗烘干
由此可见,面向过程比较直接高效,而面向对象更易于复用、扩展和维护
面向对象和面向过程的总结
- 都是解决问题的思维方式,都是代码组织的方式。
- 解决简单问题可以使用面向过程
- 解决复杂问题:宏观上使用面向对象把握,微观处理上仍然是面向过程。
- 面向对象具有三大特征:封装性、继承性和多态性,而面向过程没有继承性和多态性,并且面向过程的封装只是封装功能,而面向对象可以封装数据和功能。所以面向对象优势更明显
6. 静态绑定&动态绑定
在Java方法调用的过程中,JVM是如何知道调用的是哪个类的方法源代码呢?这就涉及到程序绑定,程序绑定指的是一个方法的调用与方法所在的类(方法主体)关联起来。
对Java来说,绑定分为静态绑定和动态绑定,或者叫做前期绑定和后期绑定。
1️⃣ 静态绑定
针对Java,可以简单地理解为程序编译期的绑定。
这里特别说明一点,Java当中的方法只有final,static,private和构造方法是静态绑定。
# 关于final,static,private和构造方法是前期绑定的理解:
对于private的方法,首先一点它不能被继承,既然不能被继承那么就没办法通过它子类的对象来调用,而只能通过这个类自身的对象来调用。因此就可以说private方法和定义这个方法的类绑定在了一起。
final方法虽然可以被继承,但不能被重写(覆盖),虽然子类对象可以调用,但是调用的都是父类中所定义的那个final方法,(由此我们可以知道将方法声明为final类型,一是为了防止方法被覆盖,二是为了有效地关闭java中的动态绑定)。
构造方法也是不能被继承的(网上也有说子类无条件地继承父类的无参数构造函数作为自己的构造函数,不过个人认为这个说法不太恰当,因为我们知道子类是通过super()来调用父类的无参构造方法,来完成对父类的初始化, 而我们使用从父类继承过来的方法是不用这样做的,因此不应该说子类继承了父类的构造方法),因此编译时也可以知道这个构造方法到底是属于哪个类。
对于static方法,具体的原理我也说不太清。不过根据网上的资料和我自己做的实验可以得出结论:static方法可以被子类继承,但是不能被子类重写(覆盖),但是可以被子类隐藏。(这里意思是说如果父类里有一个static方法,它的子类里如果没有对应的方法,那么当子类对象调用这个方法时就会使用父类中的方法。而如果子类中定义了相同的方法,则会调用子类的中定义的方法。唯一的不同就是,当子类对象上转型为父类对象时,不论子类中有没有定义这个静态方法,该对象都会使用父类中的静态方法。因此这里说静态方法可以被隐藏而不能被覆盖。这与子类隐藏父类中的成员变量是一样的。隐藏和覆盖的区别在于,子类对象转换成父类对象后,能够访问父类被隐藏的变量和方法,而不能访问父类被覆盖的方法)
由上面我们可以得出结论,如果一个方法不可被继承或者继承后不可被覆盖,那么这个方法就采用的静态绑定。
2️⃣ 动态绑定
在运行时根据具体对象的类型进行绑定。也就是说,编译器此时依然不知道对象的类型,但方法调用机制能自己去调查,找到正确的方法主体
动态绑定的过程:
- 虚拟机提取对象的实际类型的方法表;
- 虚拟机搜索方法签名
- 调用方法
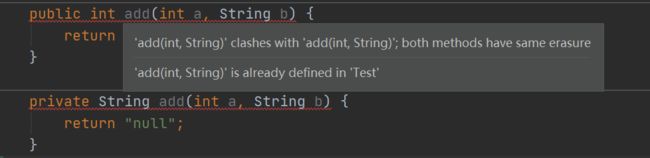
7. 重载和重写
重写:发生在父子类中,方法名、参数列表必须相同;子类的返回值范围小于等于父类,抛出异常范围小于等于父类,访问修饰符范围大于等于父类;如果父类方法访问修饰符为private则子类不能重写该方法。
重载:发生在同一个类中,参数类型不同、个数不同、顺序不同都可以构成重载;
- 重载方法的返回值可以不同,但是不能仅仅返回值不同,否则编译时报错

- 重载方法的访问控制符也可以不同,但是不能仅仅访问控制符不同,否则编译时报错
8. Java异常体系
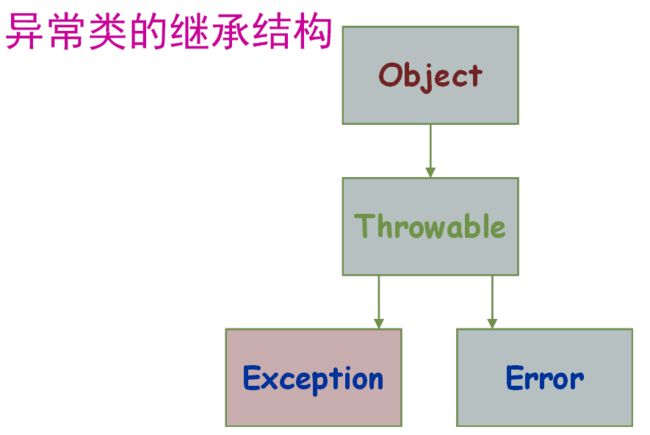
Java中的所有异常都来自顶级父类Throwable,Throwable有两个子类Exception和Error
-
Error是程序无法处理的错误,一旦出现错误,则程序将被迫停止运行
-
Exception不会导致程序停止,又分为
RunTimeException和CheckedException-
RunTimeException常常发生在程序运行过程中,会导致程序当前线程执行失败
//除0错误:ArithmeticException //错误的强制类型转换错误:ClassCastException //数组索引越界:ArrayIndexOutOfBoundsException //使用了空对象:NullPointerException -
CheckedException常常发生在程序编译过程中,会导致程序编译不通过
例如:打开不存在的文件
-
9. final关键字
1.作用
- 修饰类:表示类不可被继承
- 修饰方法:表示方法不可被子类覆盖,但是可以重载
- 修饰变量:表示变量一旦被赋值就不可以更改它的值
2.修饰不同变量的区别
1️⃣ 修饰成员变量
- 如果final修饰的是类变量,只能在静态初始化块中指定初始值或者声明该类变量时指定初始值。
- 如果final修饰的是成员变量,可以在非静态初始化块、声明该变量或者构造器中执行初始值。
2️⃣ 修饰局部变量
系统不会为局部变量进行初始化,局部变量必须由程序员显示初始化。因此使用final修饰局部变量时,即可以在定义时指定默认值(后面的代码不能对变量再赋值),也可以不指定默认值,而在后面的代码中对final变量赋初值(仅一次)

3️⃣ 修饰基本数据类型和引用类型数据
- 如果是基本数据类型的变量,则其数值一旦在初始化之后便不能更改
- 如果是引用类型的变量,则在对其初始化之后便不能再让其指向另一个对象。但是引用的值可变。

2.为什么局部内部类和匿名内部类只能访问局部final变量
局部内部类或匿名内部类编译之后会产生两个class文件:Test.class、Test$1.class,一个是类class,一个是内部类class
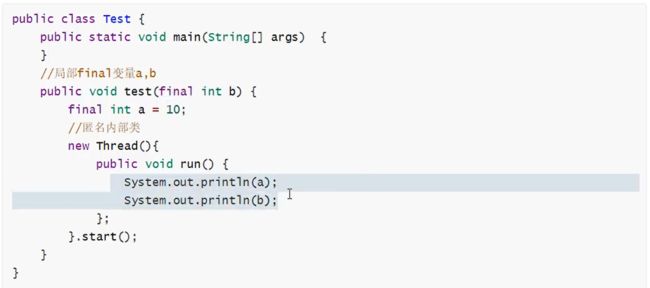
局部内部类:

首先需要知道的一点是:内部类和外部类是处于同一个级别的,内部类不会因为定义在方法中就会随着方法的执行完毕就被销毁。
这里就会产生问题:当外部类的方法结束时,局部变量就会被销毁了,但是内部类对象可能还存在(只有没有人再引用它时,才会死亡),这里就出现了一个矛盾:内部类对象访问了一个不存在的变量。为了解决这个问题,就将局部变量复制了一份作为內部类的成员变量,这样当局部变量死亡后,内部类仍可以访问它,实际访问的是局部变量的"copy".这样就好像延长了局部变量的生命周期
将局部变量复制为内部类的成员变量时,必须保证这两个变量是一样的,也就是如果我们在内部类中修改了成员变量,方法中的局部变量也得跟着改变,怎么解决问题呢?
就将局部变量设置为final,对它初始化后,我就不让你再去修改这个变量,就保证了内部类的成员变量和方法的局部变量的一致性。这实际上也是一种妥协。使得局部变量与内部类內建立的拷贝保持一致。
10. String、StringBuilder、StringBuffer
- String底层是final修饰的char[]数组,不可变,每次操作都会产生新的String对象
- StringBuffer和StringBuilder都是在原对象上操作
- StringBuffer线程安全(所有方法都用synchronized修饰),StringBuilder线程不安全
性能:StringBuilder>StringBuffer>String
使用场景:经常需要改变字符串内容时使用后面两个,优先使用 StringBuilder,多线程使用共享变量时使用 StringBuffer
11. 单例模式
彻底玩转单例模式
12. 工厂模式和建造者模式的区别
- 工厂模式一般都是创建一个产品,注重的是把这个产品创建出来,而不关心这个产品的组成部分。从代码上看,工厂模式就是一个方法,用这个方法来生产出产品
- 建造者模式也是创建一个产品,但是不仅要把这个产品创建出来,还要关心这个产品的组成细节,组成过程。从代码上看,建造者模式在创建产品的时候,这个产品有很多方法,建造者模式会根据这些相同的方法按不同的执行顺序建造出不同组成细节的产品
13. 深拷贝和浅拷贝
-
浅拷贝:复制对象时只复制对象本身,包括基本数据类型的属性,但是不会复制引用数据类型属性指向的对象,即拷贝对象的与原对象的引用数据类型的属性指向同一个对象
浅拷贝没有达到完全复制,即原对象与克隆对象之间有关系,会相互影响
-
深拷贝:复制一个新的对象,引用数据类型指向对象会拷贝新的一份,不再指向原有引用对象的地址
深拷贝达到了完全复制的目的,即原对象与克隆对象之间不会相互影响
14. 泛型知识
Java泛型深度解析以及面试题_周将的博客-CSDN博客
Java泛型是在JDK5引入的新特性,它提供了编译时类型安全检测机制。该机制允许程序员在编译时检测到非法的类型,泛型的本质是参数类型。
1️⃣ 使用泛型的好处
- 泛型可以增强编译时错误检测,减少因类型问题引发的运行时异常。
- 泛型可以避免类型转换。
- 泛型可以泛型算法,增加代码复用性。
2️⃣ Java中泛型的分类
-
泛型类:它的定义格式是
class name,如下, 返回一个对象中包含了code和一个data, data是一个对象,我们不能固定它是什么类型,这时候就用T泛型来代替,大大增加了代码的复用性。public class Result<T> { private T data; private int code; public T getData() { return data; } public void setData(T data) { this.data = data; } } -
泛型接口:和泛型类使用相似
-
泛型方法:它的定义是
[public] [static],只有在前面加返回值类型 方法名(T 参数列表)
3️⃣ 常见的泛型参数
- K 键
- V 值
- N 数字
- T 类型
- E 元素
- S, U, V 等,泛型声明的多个类型
4️⃣ 钻石运算符Diamond
钻石操作符是在 java 7 中引入的,可以让代码更易读,但它不能用于匿名的内部类。在 java 9 中, 它可以与匿名的内部类一起使用,从而提高代码的可读性。
- JDK7以下版本需要
Boxbox = new Box (); - JDK7及以上版本
BoxintegerBox1 = new Box<>();
5️⃣ 受限类型参数
-
它的作用是对泛型变量的范围作出限制,格式:
单一限制:
多种限制:
-
多种限制的时候,类必须写在第一个
6️⃣ 通配符
通配符用?标识,分为受限制的通配符和不受限制的通配符,它使代码更加灵活,广泛运用于框架中。
比如List和List是没有任何关系的。如果我们将print方法中参数列表部分的List声明为List, 那么编译是不会通过的,但是如果我们将List定义为List list或者List list,那么在编译的时候就不会报错了
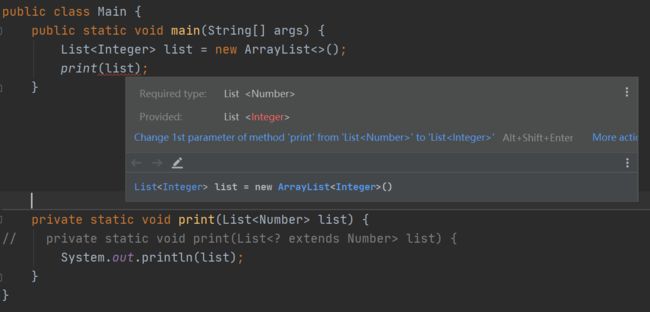
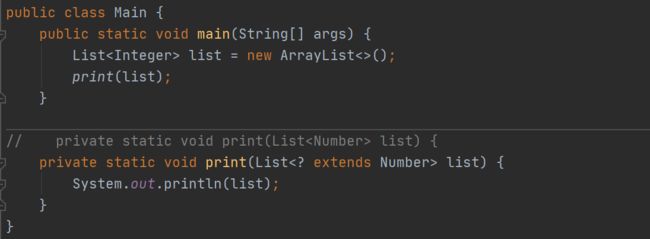
-
受限制的通配符:语法为
,它可以扩大兼容的范围(XXX以及它的子类)比如上面例子中print中如果改为List
,虽然它能存储Integer和Double等类型的元素,但是作为参数传递的时候,它只能接受List 这一种类型。如果声明为List list就不一样了,相当于扩大了类型的范围,使得代码更加的灵活,代码复用性更高。 和extends一样,只不过extends是限定了上限,而super是限定了下限 -
非受限制的通配符:不适用关键字extends或者super。比如上面print参数列表声明为List list也可以解决问题。
?代表了未知类型。所以所有的类型都可以理解为List的子类。它的使用场景一般是泛型类中的方法不依赖于类型参数的时候,比如list.size(), 遍历集合等,这样的话并不关心List中元素的具体类型。
7️⃣ 泛型中的PECS原则
PECS原则的全拼是"Producer Extends Consumer Super"。
- 当需要频繁取值,而不需要写值则使用上界通配符
? extends T作为数据结构泛型。=- 相反,当需要频繁写值,而不需要取值则使用下届通配符
? super T作为数据结构泛型。
案例分析:创建Apple,Fruit两个类,其中Apple是Fruit的子类
public class PECS {
ArrayList exdentFurit;
ArrayList superFurit;
Apple apple = new Apple();
private void test() {
Fruit a1 = exdentFurit.get(0);
Fruit a2 = superFurit.get(0); //Err1
exdentFurit.add(apple); //Err2
superFurit.add(apple);
}
}
其中Err1和Err2行处报错,因为这些操作并不符合PECS原则,逐一分析:
-
Err1
使用? super T规定泛型的数据结构,其存储的值是T的父类,而这里superFruit.get()的对象为Fruit的父类对象,而指向该对象的引用类型为Fruit,父类缺少子类中的一些信息,这显然是不对的,因此编译器直接禁止在使用? super T泛型的数据结构中进行取值,只能进行写值,正是开头所说的CS原则。 -
Err2
使用? extends T规定泛型的数据结构,其存储的值是T的子类,这里exdentFruit.add()也就是向其中添加Fruit的子类对象,而Fruit可以有多种子类对象,因此当我们进行写值时,我们并不知道其中存储的到底是哪个子类,因此写值操作必然会出现问题,所以编译器接禁止在使用? extends T泛型的数据结构中进行写,只能进行取值,正是开头所说的PE原则。
8️⃣ 类型擦除
-
类型擦除作用:因为Java中的泛型实在JDK1.5之后新加的特性,为了兼容性,在虚拟机中运行时是不存在泛型的,所以Java泛型是一种伪泛型,类型擦除就保证了泛型不在运行时候出现。
-
场景:编译器会把泛型类型中所有的类型参数替换为它们的上(下)限,如果没有对类型参数做出限制,那么就替换为Object类型。因此,编译出的字节码仅仅包含了常规类,接口和方法。
- 在必要时插入类型转换以保持类型安全。
- 生成桥方法以在扩展泛型时保持多态性
-
Bridge Methods 桥方法
当编译一个扩展参数化类的类,或一个实现了参数化接口的接口时,编译器有可能因此要创建一个合成方法,名为桥方法。它是类型擦除过程中的一部分。下面对桥方法代码验证一下:public class Node<T> { T t; public Node(T t) { this.t = t; } public void set(T t) { this.t = t; } } class MyNode extends Node<String> { public MyNode(String s) { super(s); } @Override public void set(String s) { super.set(s); }上面
Node是一个泛型类型,没有声明上下限,所以在类型擦除后会变为Object类型。而MyNode类已经声明了实际类型参数为String类型,这样在调用父类set方法的时候就会出现不匹配的情况,所以虚拟机在编译的时候为我们生成了一个桥方法,我们通过javap -c MyNode.class查看字节码文件,看到确实为我们生成了一个桥方法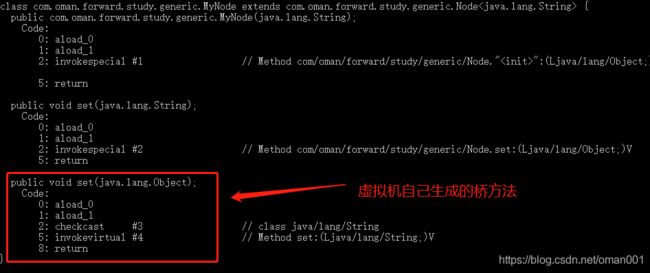
15. Java泛型的原理?什么是泛型擦除机制?
- Java的泛型是JDK5新引入的特性,为了向下兼容,虚拟机其实是不支持泛型,所以Java实现的是一种伪泛型机制,也就是说Java在编译期擦除了所有的泛型信息,这样Java就不需要产生新的类型到字节码,所有的泛型类型最终都是一种原始类型,在Java运行时根本就不存在泛型信息。
- 类型擦除其实在类常量池中保存了泛型信息,运行时还能拿到信息,比如Gson的TypeToken的使用。
- 泛型算法实现的关键:利用受限类型参数。
16. Java编译器具体是如何擦除泛型的
- 检查泛型类型,获取目标类型
- 擦除类型变量,并替换为限定类型
- 如果泛型类型的类型变量没有限定,则用Object作为原始类型
- 如果有限定,则用限定的类型作为原始类型
- 如果有多个限定(T extends Class1&Class2),则使用第一个边界Class1作为原始类
- 在必要时插入类型转换以保持类型安全
- 生成桥方法以在扩展时保持多态性
17. Array数组中可以用泛型吗?
不能,简单的来讲是因为如果可以创建泛型数组,泛型擦除会导致编译能通过,但是运行时会出现异常。所以如果禁止创建泛型数组,就可以避免此类问题。
18. PESC原则&限定通配符和非限定通配符
- 如果你只需要从集合中获得类型T , 使用通配符
- 如果你只需要将类型T放到集合中, 使用通配符
- 如果你既要获取又要放置元素,则不使用任何通配符。例如
List 非限定通配符既不能存也不能取, 一般使用非限定通配符只有一个目的,就是为了灵活的转型。其实List 等于 List。
19. Java中List和List
虽然他们都会进行类型检查,实质上却完全不同。List 是一个未知类型的List,而List
20. for循环和forEach效率问题
== 遍历ArrayList测试==
这里向ArrayList中插入10000000条数据,分别用for循环和for each循环进行遍历测试
package for循环效率问题;
import java.util.ArrayList;
public class Test {
public static void main(String[] args) {
ArrayList<Integer> arrayList = new ArrayList<>();
for (int i = 0; i < 10000000; i++) {
arrayList.add(i);
}
int x = 0;
//for循环遍历
long forStart = System.currentTimeMillis();
for (int i = 0; i < arrayList.size(); i++) {
x = arrayList.get(i);
}
long forEnd = System.currentTimeMillis();
System.out.println("for循环耗时" + (forEnd - forStart) + "ms");
//for-each遍历
long forEachStart = System.currentTimeMillis();
for (int i : arrayList) {
x = i;
}
long forEachEnd = System.currentTimeMillis();
System.out.println("foreach耗时" + (forEachEnd - forEachStart) + "ms");
}
}
根据执行结果,可以看到for循环速度更快一点,但是差别不太大

我们反编译class文件看看
package for循环效率问题;
import java.util.ArrayList;
import java.util.Iterator;
public class Test {
public Test() {
}
public static void main(String[] args) {
ArrayList<Integer> arrayList = new ArrayList();
int x;
for(x = 0; x < 10000000; ++x) {
arrayList.add(x);
}
int x = false;
long forStart = System.currentTimeMillis();
for(int i = 0; i < arrayList.size(); ++i) {
x = (Integer)arrayList.get(i);
}
long forEnd = System.currentTimeMillis();
System.out.println("for循环耗时" + (forEnd - forStart) + "ms");
long forEachStart = System.currentTimeMillis();
int i;
for(Iterator var9 = arrayList.iterator();
var9.hasNext();
i = (Integer)var9.next()) {
}
long forEachEnd = System.currentTimeMillis();
System.out.println("foreach耗时" + (forEachEnd - forEachStart) + "ms");
}
}
可以看到增强for循环本质上就是使用iterator迭代器进行遍历
== 遍历LinkedList测试==
这里向LinkedList中插入测试10000条数据进行遍历测试,实验中发现如果循环次数太大,for循环直接卡死;
package for循环效率问题;
import java.util.LinkedList;
public class Test2 {
public static void main(String[] args) {
LinkedList<Integer> linkedList = new LinkedList<>();
for (int i = 0; i < 10000; i++) {
linkedList.add(i);
}
int x = 0;
//for循环遍历
long forStart = System.currentTimeMillis();
for (int i = 0; i < linkedList.size(); i++) {
x = linkedList.get(i);
}
long forEnd = System.currentTimeMillis();
System.out.println("for循环耗时" + (forEnd - forStart) + "ms");
//for-each遍历
long forEachStart = System.currentTimeMillis();
for (int i : linkedList) {
x = i;
}
long forEachEnd = System.currentTimeMillis();
System.out.println("foreach耗时" + (forEachEnd - forEachStart) + "ms");
}
}
根据结果可以看到,遍历LinkedList时for each速度远远大于for循环速度

反编译class文件的源码
Source code recreated from a .class file by IntelliJ IDEA// (powered by Fernflower decompiler)//
package for循环效率问题;
import java.util.Iterator;
import java.util.LinkedList;
public class Test2 {
public Test2() {
}
public static void main(String[] args) {
LinkedList<Integer> linkedList = new LinkedList();
int x;
for (x = 0; x < 10000; ++x) {
linkedList.add(x);
}
int x = false;
long forStart = System.currentTimeMillis();
for (int i = 0; i < linkedList.size(); ++i) {
x = (Integer) linkedList.get(i);
}
long forEnd = System.currentTimeMillis();
System.out.println("for循环耗时" + (forEnd - forStart) + "ms");
long forEachStart = System.currentTimeMillis();
int i;
for (Iterator var9 = linkedList.iterator(); var9.hasNext(); i = (Integer) var9.next()) {
}
long forEachEnd = System.currentTimeMillis();
System.out.println("foreach耗时" + (forEachEnd - forEachStart) + "ms");
}
}
== 总结 ==
1️⃣ 区别:
- for 循环就是按顺序遍历,随机访问元素
- for each循环本质上是使用iterator迭代器遍历,顺序链表访问元素;
2️⃣ 性能比对:
- 对于arraylist底层为数组类型的结构,使用for循环遍历比使用foreach循环遍历稍快一些,但相差不大
- 对于linkedlist底层为单链表类型的结构,使用for循环每次都要从第一个元素开始遍历,速度非常慢;使用foreach可以直接读取当前结点,速度比for快很多
3️⃣ 原理接释:
-
ArrayList数组类型结构对随机访问比较快,而for循环中的get()方法,采用的即是随机访问的方法,因此在ArrayList里,for循环较快
# 顺序表a[3] - 用for循环,从a[0]开始直接读到元素,接着直接读a[1](顺序表的优点,随机访问) - 用foreach,得到a[0]-a[2]的全部地址放入队列,按顺序取出队里里的地址来访问元素 -
LinkedList链表形结构对顺序访问比较快,iterator中的next()方法,采用的即是顺序访问的方法,因此在LinkedList里,使用iterator较快
# 单链表b[3] - 用for循环,从a[0]开始读元素、然后通过a[0]的next读到a[1]元素、通过a[0]的next的next读到a[2]元素,以此类推,性能影响较大,慎用! - 用foreach,得到a[0]-a[2]的全部地址放入队列,按顺序取出队里里的地址来访问元素;
16. NIO、BIO、AIO
(1条消息) Netty_youthlql的博客-CSDN博客
尚硅谷Netty教程(B站最火,人气最高,好评如潮)_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
阻塞IO 和 非阻塞IO
IO操作分为两个部分,即发起IO请求和实际IO操作,阻塞IO和非阻塞IO的区别就在于第二个步骤是否阻塞
- 若发起IO请求后请求线程一直等待实际IO操作完成,则为阻塞IO
- 若发起IO请求后请求线程返回而不会一直等待,则为非阻塞IO
同步IO 和 异步IO
IO操作分为两个部分,即发起IO请求和实际IO操作,同步IO和异步IO的区别就在于第一个步骤是否阻塞
- 若实际IO操作阻塞请求进程,即请求进程需要等待或轮询查看IO操作是否就绪,则为同步IO
- 若实际IO操作不阻塞请求进程,而是由操作系统来进行实际IO操作并将结果返回,则为异步IO
NIO、BIO、AIO
BIO表示同步阻塞式IO,服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善。
NIO表示同步非阻塞IO,服务器实现模式为一个请求一个线程,即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。
AIO表示异步非阻塞IO,服务器实现模式为一个有效请求一个线程,客户端的I/O请求都是由操作系统先完成IO操作后再通知服务器应用来启动线程进行处理。
17. 什么是反射
反射是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为 Java 语言的反射机制。
反射实现了把java类中的各种结构法、属性、构造器、类名)映射成一个个的Java对象
优点:可以实现动态创建对象和编译,体现了很大的灵活性
缺点:对性能有影响,使用反射本质上是一种接释操作,慢于直接执行java代码
应用场景:
- JDBC中,利用反射动态加载了数据库驱动程序。
- Web服务器中利用反射调用了Sevlet的服务方法。
- Eclispe等开发工具利用反射动态刨析对象的类型与结构,动态提示对象的属性和方法。
- 很多框架都用到反射机制,注入属性,调用方法,如Spring。
18. 序列化&反序列化
Java基础学习总结——Java对象的序列化和反序列化 - 孤傲苍狼 - 博客园 (cnblogs.com)
1️⃣ 什么是序列化?
序列化是指将Java对象转化为字节序列的过程,而反序列化则是将字节序列转化为Java对象的过程
2️⃣ 为什么需要序列化?
我们知道不同线程/进程进行远程通信时可以相互发送各种数据,包括文本图片音视频等,Java对象不能直接传输,所以需要转化为二进制序列传输,所以需要序列化
3️⃣ 序列化的用途?
-
把对象的字节序列永久地保存到硬盘上,通常存放在一个文件中
在很多应用中,需要对某些对象进行序列化,让它们离开内存空间,入住物理硬盘,以便长期保存。比如最常见的是Web服务器中的Session对象,当有10万用户并发访问,就有可能出现10万个Session对象,内存可能吃不消,于是Web容器就会把一些seesion先序列化到硬盘中,等要用了,再把保存在硬盘中的对象还原到内存中
-
在网络上传送对象的字节序列
当两个进程在进行远程通信时,彼此可以发送各种类型的数据。无论是何种类型的数据,都会以二进制序列的形式在网络上传送。发送方需要把这个Java对象转换为字节序列,才能在网络上传送;接收方则需要把字节序列再恢复为Java对象
4️⃣ JDK类库中的序列化API
java.io.ObjectOutputStream代表对象输出流,它的writeObject(Object obj)方法可对参数指定的obj对象进行序列化,把得到的字节序列写到一个目标输出流中java.io.ObjectInputStream代表对象输入流,它的readObject()方法从一个源输入流中读取字节序列,再把它们反序列化为一个对象,并将其返回
只有实现了Serializable和Externalizable接口的类的对象才能被序列化。Externalizable接口继承自Serializable接口,实现Externalizable接口的类完全由自身来控制序列化的行为,而仅实现Serializable接口的类可以 采用默认的序列化方式
对象序列化包括如下步骤:
- 创建一个对象输出流,它可以包装一个其他类型的目标输出流,如文件输出流
- 通过对象输出流的writeObject()方法写对象
对象反序列化的步骤如下:
- 创建一个对象输入流,它可以包装一个其他类型的源输入流,如文件输入流
- 通过对象输入流的readObject()方法读取对象
5️⃣ serialVersionUID的作用
serialVersionUID: 字面意思上是序列化的版本号,凡是实现Serializable接口的类都有一个表示序列化版本标识符的静态变量
如果实现Serializable接口的类如果类中没有添加serialVersionUID,那么就会出现警告提示
serialVersionUID有两种生成方式:
-
采用Add default serial version ID方式生成的serialVersionUID是1L,例如:
private static final long serialVersionUID = 1L; -
采用Add generated serial version ID这种方式生成的serialVersionUID是根据类名,接口名,方法和属性等来生成的,例如:
private static final long serialVersionUID = 4603642343377807741L;
19. 动态代理是什么?有哪些应用?
当想要给实现了某个接口的类中的方法,加一些额外的处理。比如说加日志,加事务等。可以给这个类创建一个代理,故名思议就是创建一个新的类,这个类不仅包含原来类方法的功能,而且还在原来的基础上添加了额外处理的新类。这个代理类并不是定义好的,是动态生成的。具有解耦意义,灵活,扩展性强。
应用:
- Spring的AOP
- 加事务
- 加权限
- 加日志
20. 怎么实现动态代理
在java的java.lang.reflect包下提供了一个Proxy类和一个InvocationHandler接口,通过这个类和这个接口可以生成JDK动态代理类和动态代理对象
- java.lang.reflect.Proxy是所有动态代理的父类。它通过静态方法newProxyInstance()来创建动态代理的class对象和实例。
- 每一个动态代理实例都有一个关联的InvocationHandler。通过代理实例调用方法,方法调用请求会被转发给InvocationHandler的invoke方法。
- 首先定义一个
IncocationHandler处理器接口实现类,实现其invoke()方法 - 通过
Proxy.newProxyInstance生成代理类对象
package demo3;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
public class ProxyInvocationHandler implements InvocationHandler {
//定义真实角色
private Rent host;
//真实角色set方法
public void setHost(Rent host) {
this.host = host;
}
/**
生成代理类方法
1. 类加载器,为当前类即可
2. 代理类实现的接口
3. 处理器接口对象
**/
public Object getProxy() {
return Proxy.newProxyInstance(this.getClass().getClassLoader(),
host.getClass().getInterfaces(), this);
}
//处理代理实例,并返回结果
//方法在此调用
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
//调用真实角色方法,相当于调用rent()方法
Object result = method.invoke(host, args);
//附加方法
seeHouse();
contract();
fare();
return result;
}
//看房
public void seeHouse() {
System.out.println("中介带你看房");
}
//签合同
public void contract() {
System.out.println("租赁合同");
}
//收中介费
public void fare() {
System.out.println("收中介费");
}
}
package demo3;
public class Client {
public static void main(String[] args) {
//真实角色:房东
Host host = new Host();
//处理器接口对象
ProxyInvocationHandler handler = new ProxyInvocationHandler();
//设置要代理的真实角色
handler.setHost(host);
//动态生成代理类
Rent proxy = (Rent) handler.getProxy();
//调用方法
proxy.rent();
}
}
21. 如何实现对象克隆?
有两种方式:
-
实现Cloneable接口并重写Object类中的clone()方法;
protected Object clone() throws CloneNotSupportedException { test_paper paper = (test_paper) super.clone(); paper.date = (Date) date.clone(); return paper; } -
实现Serializable接口,通过对象的序列化和反序列化实现克隆,可以实现真正的深度克隆
import java.io.ByteArrayInputStream; import java.io.ByteArrayOutputStream; import java.io.ObjectInputStream; import java.io.ObjectOutputStream; import java.util.Date; @SuppressWarnings("all") public class Client { public static void main(String[] args) throws Exception { Date date = new Date(); String name = "zsr"; test_paper paper1 = new test_paper(name, date); //通过序列化和反序列化来实现深克隆 ByteArrayOutputStream bos = new ByteArrayOutputStream(); ObjectOutputStream obs = new ObjectOutputStream(bos); obs.writeObject(paper1); byte a[] = bos.toByteArray(); ObjectInputStream ois = new ObjectInputStream(new ByteArrayInputStream(a)); test_paper paper3 = (test_paper) ois.readObject();//获取到新对象 paper3.getDate().setDate(1000);//改变非基本类型属性 System.out.println(paper1); System.out.println(paper3); } }