Alibaba Sentinel超详细整理
Alibaba Sentinel 是面向云原生微服务的流量控制,熔断降级组件,监控保护你的微服务
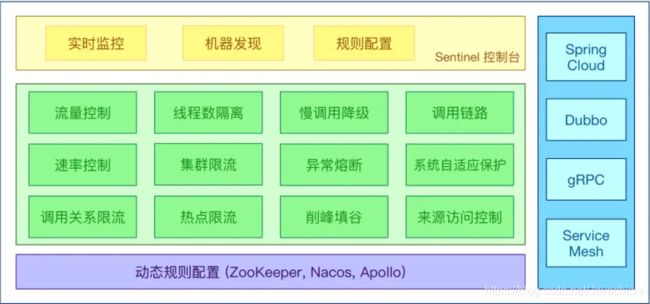
为什么要学Alibaba Sentinel?
先来看看Sentinel的前身 Hystrix,总结下来有几点:
- 需要我们程序员手工搭建监控平台
- 没有一套web界面可以给我们进行更加细粒度配置流控,速率控制,服务熔断,服务降级…
而Sentinel的优势
- 单独一个组件,可以独立出来
- 直接界面化的细粒度统一配置
有没有发现跟Nacos很像,我们不需要在手动建立一个部署模块,直接入驻就可以了,开发简便很多
Sentinel是什么
分布式系统的流量防卫兵
- 丰富的应用场景: Sentinel承接了阿里巴巴近十年的双十一大促流量的核心场景,例如秒杀(即突发流量控制在系统容量可以承受的范围),消息削峰填谷,集群流量控制,实时熔断下游不可用应用等
- 完美的实时监控:
Sentinel同事提供实时的监控功能,您可以在控制台看到接入应用的单台机器秒级数据,甚至500台一下规模的集群的汇总运行情况 - 广泛的开源生态:
Sentinel提供开箱即用的与其他框架/库的整合模块,例如与SpringCloud,Dubbo,gRPC的整合,您只需要引入响应的依赖并进行简单的配置即可快速接入Sentinel. - 完美的SPI扩展点:
Sentinel提供简单易用的,完美的SPI扩展接口,可以通过实现扩展接口来快速定制逻辑,例如定制规则管理,适配动态数据源等.
Sentinel 分为两个部分
- 核心库(java客户端) 不依赖于任何框架/库,能够运行所有java运行时环境,同时对Dubbo/Spring Cloud 等框架也有较好的支持
- 控制台(Dashboard)基于Srping Boot开发,打包后可以直接运行,不需要额外的Tomcat等容器
服务限流配置
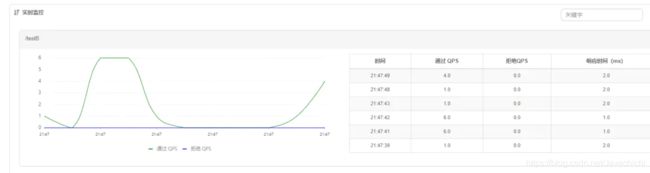
实时查看QPS

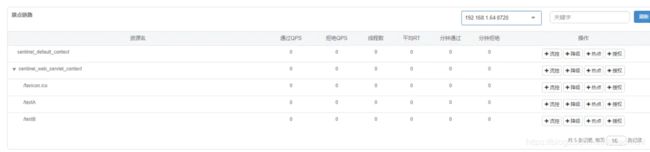
簇点链路:查看Http请求
流控规则 :控制qps,线程等等
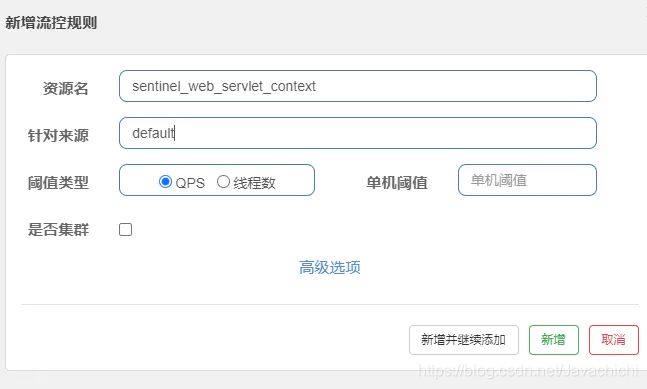
查过峰值,会抛出异常(可自行配置服务降级回调方法)
阈值关联 : 当关联资源/testB的qps阈值超过1时,就限流/testA的Rest访问地址

使用postman并发请求接口 testB
发现A接口被限流关闭了 配置生效
预热 :
每个系统平时处于低水位的情况下,突然来高并发的流量,肯定是承受不住的,要经过预热后才会使系统达到稳定可以接受的状态.如不懂得可以看下我的高并发文章详解JVM调优
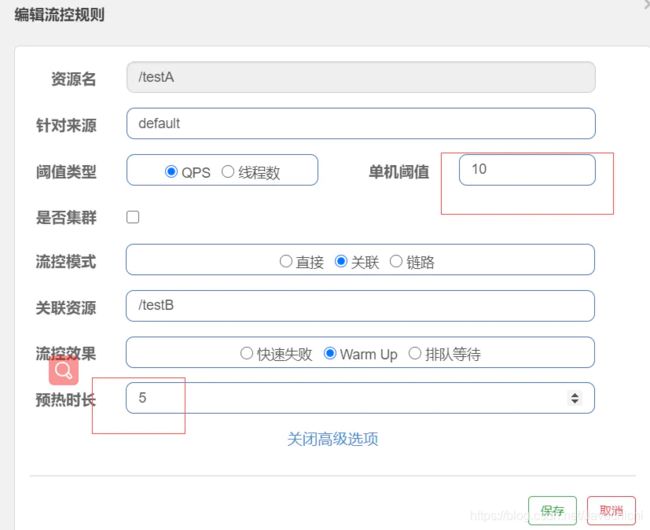
如图所示,阈值是10 但希望五秒内慢慢启动起来,也就是根据源码里的公示,即请求QPS从(threashold/3)开始,经多少预热时长才逐渐升至设定的QPS阈值

来自于:com.alibaba.csp.sentinel.slots.block.flow.controller.WarmUpController,冷加载因子默认是3
他的作用体现在,如果一个秒杀系统在开启的瞬间,会有很多流量上来,很有可能把系统打死,预热方式就是为了保护系统,可慢慢的把流量放进来,慢慢的把阈值增长到设置的阈值
队列等待(常用)
匀速排队,让请求以均匀的速度通过,阈值类型必须需设成QPS,否则无效
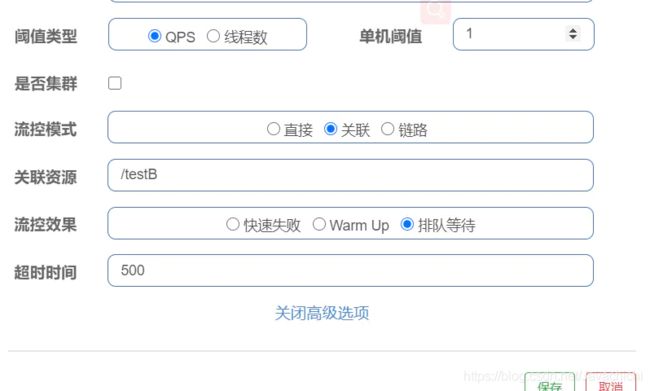
如图所示,每秒请求1次,超过的话就排队等待,等待时间0.5秒
这种方式主要用于处理间隔性突发流量,例如消息队列,在某一秒有大量的请求道来,而接下来的几秒则处于空闲状态,我们希望系统能够在接下来的空闲期间逐渐处理这些请求,而不是一秒直接拒绝多余的请求
服务降级配置
Sentinel 熔断降级会在调用链路中某个资源出现不稳定状态时,例如调用超时或异常比例升高,对这个资源的调用进行限制,让请求快速失败,避免影响到其他的资源而导致级联错误
当资源被降级后,在接下来的降级时间窗口之内,对该资源的调用都自动熔断(默认抛出DegradeException)

-
RT
每秒平均响应时间,超过阈值,且时间窗口内通过的请求>=5,两个条件同时满足触发降级,RT最大4900 -
异常比例(/s)
QPS>=5 且异常比例超过与知识,触发降级,时间窗口结束后,关闭降级 -
异常数(/m)
异常数超过阈值是,触发降级,时间窗口结束后,关闭降级
热点配置
热点即经常访问的数据,很多时候我们希望统计某个热点数据中访问频次最高的Top K数据,并对其访问进行限制,热点参数限流可以看做是一种特殊的流量控制,仅对包含热点参数的资源调用生效.
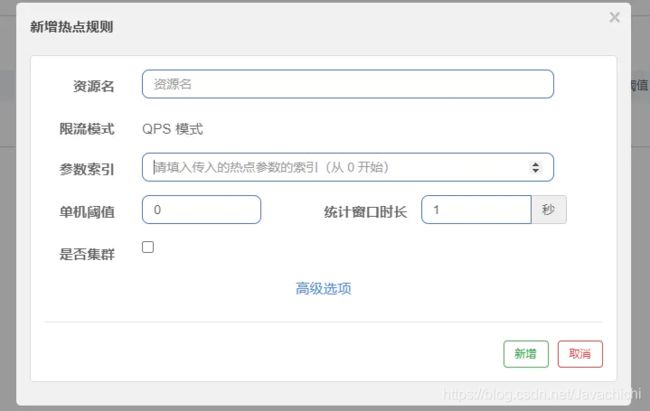
- 资源名即对应@sentenelResource对应的value
- 参数索引对应方法参数位置,从第几个参数开始检查
- 阈值,窗口就不用解释了
@sentenelResource (前身HystrixCommond )

每个SentenelResource都应该有个对应的兜底方法,来处理出错后的返回,不配blockhandler的话会报page Error
高级玩法
普通我们配置热点参数时候,匹配规则就会返回block,但我们想有特定的参数后,例行放开阈值
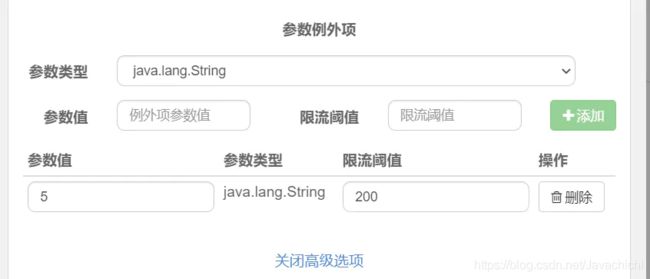
当参数等于5时,可以单独配置阈值(必须是基本类型)
注意
@sentinelResource处理的是控制台配置的违规情况,有blockHandler方法进行兜底,但java运行时异常不归他管,这是两个东西(下面有fallback方法处理)
系统规则
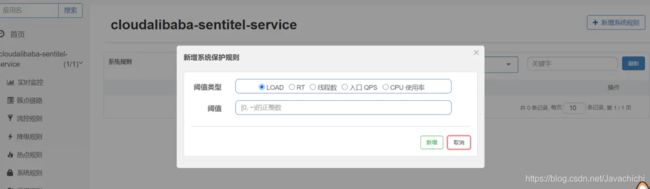
系统规则自然对应所有入口的rest请求做处理,整体管控,设置有风险,需谨慎
全局自定义限流处理逻辑
在我们上面配置SentinelResource后,有没有发现每个类里面每个方法都要配置一个blockhandle,又麻烦又代码膨胀,那我们有没有一个自定义的全局处理方案呢?
1.创建CustomerBlockHandler类用于自定义限流处理逻辑
2.定义公共返回值
3.创建一个或多个对应blockhandler方法
/**
* @program: 杭州品茗信息技术有限公司
* @description
* @author: 徐子木
* @create: 2020-12-03 20:18
**/
@Slf4j
public class CustomerBlockHandler {
public static CommonResult<String> BlocHandler1(BlockException blockException) {
return new CommonResult(500,"自定义block1");
}
public static CommonResult<String> BlocHandler2(BlockException blockException) {
return new CommonResult(500,"自定义block2");
}
}
配置在我们需要保障的方法内
@GetMapping("/testB")
@SentinelResource(value = "testB",blockHandlerClass = CustomerBlockHandler.class,blockHandler = "BlocHandler1")
public CommonResult<String> testB() {
return new CommonResult(200,"testB");
}
其实还有一种保障方法,可以用代码级别来控制,类似try catch,但我不推荐,写起来又长又麻烦,感兴趣的可以去官网查找写法
服务熔断Fallback
前面说的SentinelResouce,只会管理我们的服务限流级别的规则采取措施,若java代码级别的RuntimeException是不归他管的,该怎么报错还怎么报错,这里就要提一个fallback参数
新建全局异常处理类
/**
* @program: 杭州品茗信息技术有限公司
* @description
* @author: 徐子木
* @create: 2020-12-03 20:48
**/
@Slf4j
public class CustomerFallBackHandler {
public static CommonResult resultException(Throwable throwable) {
return new CommonResult(500,"运行异常回调处理");
}
}
配置要保障的方法
@GetMapping("/testA")
@SentinelResource(value = "testA", fallbackClass = {
CustomerFallBackHandler.class}, fallback = "resultException")
public CommonResult testA() {
int a = 1 / 0;
return new CommonResult(200, "testA");
}
可以看到,原理其实跟block差不多,但细节是如果两个都配置的话,并且两种异常都触发的情况下,谁先触发就返回谁的回调,正常情况下限流会大于运行异常的
Sentinel与openFeign整合
这里整合就不过多的叙述了,详细可查官网文档
大致就是在我们feign的@FeignClient注解里也有fallback的参数,然后配置我们与业务类一直的异常返回类即可,如果调用服务关闭或者异常,会自动触发我们的服务熔断降级处理
注意yml 要开启sentinel对Feign的支持
规则持久化
问题: 在我们配置好规则后,每次重启微服务,我们先配置好的规则就都消失了
方案: 将限流配置规则持久化进Nacos保存,只要刷新某个rest地址,sentinel控制台的流控规则就能看到,只要Nacos里面的配置不删除,针对于微服务的流控规则持续有效
解决
1.添加maven坐标,将规则持久化进nacos
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>
2.修改yml,将nacos配置文件对应
sentinel:
transport:
dashboard: 127.0.0.1:8080
port: 8719 #默认就是8719 如果被占用默认+1
datasource:
ds1:
nacos:
server-addr: 192.168.10.37:18848
dataId: ${spring.application.name}
groupId: DEV
namespace: 8622d428-0496-4a09-b178-da3cfc736055
data-type: json
rule-type: flow
3.配置nacos文件
[
{
"resource":"testB",
"limitAPP":"default",
"grade":1,
"count":1,
"strategy":0,
"controlBehavior":0,
"clusterMode":false
}
]
- resource: 资源名称
- limitApp: 来源应用
- grade: 阈值类型, 0表示线程数,1表示QPS
- count: 单机阈值
- strategy: 流控模式,0表示直接,1表示关联,2表示链路
- controlBehavior: 流控效果,0表示快速失败,1表示WarmUp,2表示排队等待
- clusterMode: 是否集群
依次对应后重启我们的微服务,就会看到我们的持久化配置,只要Nacos存在,就会一直生效
学习方向
如今出来的技术越来越多,我们的方向要从剖析源码逐渐演变成 约定>配置>编码 ,所以阿里遵循这个理论给我们带来了很多好的产品
拓展干货阅读:一线大厂面试题、高并发等主流技术资料
码字不易,如果觉得本篇文章对你有用的话,请给我一键三连!关注作者,后续会有更多的干货分享,请持续关注!