C++,软开测开,CV岗面试常考知识点
准备尝试的公司:
华为,VIVO,CVTE,科大讯飞,图普科技,Bigo(百果园),网易,YY,虹软,浦发银行,新华三,多益,大话,海康
1.lambda
第六章 lambda表达式
Lambda表达式详细总结
关于Python中的lambda,这篇阅读量10万+的文章可能是你见过的最完整的讲解
C++11 lambda表达式精讲
2.动态指针,share_ptr之类的
牛客网
weak_ptr的存在原因
C++11学习之share_ptr和weak_ptr
3.inline
C++ 中的 inline 用法
与宏的区别
本质不同:宏不是函数,inline是函数。
处理时机不同:内联函数在编译时展开,宏在预编译展开。
功能不同:内联函数可以进行诸如安全检查、语句是否正确等编译功能,宏只是一个简单的文本替换。
二义性问题:内联函数不会出现二义性;宏处理时要小心,一般要用括号括起来。
4.hash map,hash_table
什么是HashMap
C++中使用STL的hashmap
HashTable详解
HashMap和Hashtable的详细区别
5.B树,B+树
B树、B-树、B+树、B*树之间的关系
6.剪枝压缩
YOLOv3模型剪枝,瘦身80%,提速100%,精度基本不变
7.SVM
支持向量机(SVM)从入门到放弃再到掌握
支持向量机通俗导论(理解SVM的三层境界)
8.KMP算法
从头到尾彻底理解KMP
KMP算法
9.malloc,new
动态内存分配、malloc与new的区别
10.K-means
从零开始实现Kmeans聚类算法
Kmeans聚类算法详解


11.霍夫曼编码
哈夫曼编码的理解(Huffman Coding)
12.交叉熵
经典损失函数:交叉熵(附tensorflow)
13.提高泛化能力的方法:dropout,BN(归一化),正则,提前终止
基础 | batchnorm原理及代码详解
14.正则区别
【通俗易懂】机器学习中 L1 和 L2 正则化的直观解释
15.dropout具体实现
深度学习中Dropout原理解析
理解dropout
16.大数相乘
算法:C++实现大数相乘
C++ 大数相乘算法
17.1 * 1卷积的作用
如何理解卷积神经网络中的1*1卷积
(1)降维( dimension reductionality )。比如,一张500 * 500且厚度depth为100 的图片在20个filter上做1*1的卷积,那么结果的大小为500 * 500 * 20。
(2)加入非线性。卷积层之后经过激励层,1*1的卷积在前一层的学习表示上添加了非线性激励( non-linear activation ),提升网络的表达能力;
(3)跨通道信息交互(channal 的变换)
如:使用1 * 1卷积核,实现降维和升维的操作其实就是channel间信息的线性组合变化,3 * 3,64channels的卷积核前面添加一个1 * 1,28channels的卷积核,就变成了3 * 3,28channels的卷积核,原来的64个channels就可以理解为跨通道线性组合变成了28channels,这就是通道间的信息交互。
18.梯度消失、梯度爆炸原因以及解决
详解机器学习中的梯度消失、爆炸原因及其解决方法
19.sigmod函数有什么问题
函数公式和图表如下图
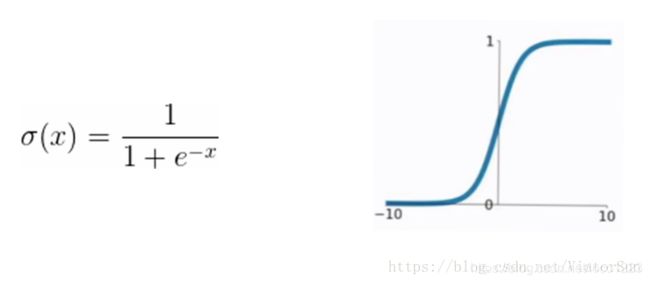
在sigmod函数中我们可以看到,其输出是在(0,1)这个开区间内,这点很有意思,可以联想到概率,但是严格意义上讲,不要当成概率。sigmod函数曾经是比较流行的,它可以想象成一个神经元的放电率,在中间斜率比较大的地方是神经元的敏感区,在两边斜率很平缓的地方是神经元的抑制区。
当然,流行也是曾经流行,这说明函数本身是有一定的缺陷的。
-
当输入稍微远离了坐标原点,函数的梯度就变得很小了,几乎为零。在神经网络反向传播的过程中,我们都是通过微分的链式法则来计算各个权重w的微分的。当反向传播经过了sigmod函数,这个链条上的微分就很小很小了,况且还可能经过很多个sigmod函数,最后会导致权重w对损失函数几乎没影响,这样不利于权重的优化,这个问题叫做梯度饱和,也可以叫梯度弥散。
-
函数输出不是以0为中心的,这样会使权重更新效率降低。对于这个缺陷,在斯坦福的课程里面有详细的解释。
-
sigmod函数要进行指数运算,这个对于计算机来说是比较慢的。
20.判断一棵树是不是BST
判断一棵二叉树是否为二叉搜索树(BST)
21.深度学习基础知识
机器学习之线性代数基础一 矩阵乘法、秩、特征值、特征向量的几何意义
深度学习/机器学习入门基础数学知识整理(一):线性代数基础,矩阵,范数等
深度学习/机器学习入门基础数学知识整理(二):梯度与导数,矩阵求导,泰勒展开等
深度学习/机器学习入门基础数学知识整理(三):凸优化,Hessian,牛顿法
22.SVM手推(免了不学,想学参考7)
如何解决线性不可分问题?间隔最大化,通过引入软间隔、核函数解决线性不可分问题
23.二叉树深度,递归,非递归
求二叉树深度 – 递归和非递归实现
int TreeDepth(TreeNode* pRoot)
{
if (pRoot == NULL)
return 0;
if (pRoot->left == NULL && pRoot->right == NULL)
return 1;
return max(TreeDepth(pRoot->left), TreeDepth(pRoot->right)) + 1;
}
24.NMS(代码)
NMS算法(NonMaximumSuppression)
NMS算法的理解
25.深度学习中的attention机制
深度学习笔记——Attention Model(注意力模型)学习总结
26.vector.erase()函数
【C++】STL常用容器总结之三:向量vector
C++里的sort()函数的强大功能
1 使用方法
vector.erase()的功能从指定容器中删除指定位置的元素或某段范围内的元素,有以下两种重载方式:
iterator erase( iterator _Where);//删除指定位置的元素,返回值是一个迭代器,指向删除元素的下一个元素;
iterator erase( iterator _First, iterator _Last);//删除从_First开始到_Last位置(不包括_Last位置)的元素,返回值也是一个迭代器,指向最后一个删除元素的下一个位置。
2 注意事项
调用erase()方法后,vector后面的元素会向前移位,一般在调用该方法后将迭代器自减一。
v1.erase( v1.begin( ) + 1, v1.begin( ) + 3 );
27.resnet的优点
浅析深度ResNet有效的原理
28.堆和栈在内存分配上的区别
栈区是存储函数内部变量的内存区,堆区是存动态申请的内存,当无法事先确定对象需要使用多少内存(这些对象所需的内存大小只有在程序运行的时候才能确定)时就要申请动态内存,比如维护一个动态增长的链表或树)
堆栈(英语:stack)又称为栈或堆叠,是计算机科学中一种特殊的串列形式的抽象数据类型,其特殊之处在于只能允许在链表或数组的一端(称为堆栈顶端指针,英语:top)进行加入数据(英语:push)和输出数据(英语:pop)的运算。另外堆栈也可以用一维数组或链表的形式来完成。堆栈的另外一个相对的操作方式称为队列。
堆栈数据结构使用两种基本操作:推入(压栈,push)和弹出(弹栈,pop):
推入:将数据放入堆栈的顶端(数组形式或串列形式),堆栈顶端top指针加一。
弹出:将顶端数据数据输出(回传),堆栈顶端数据减一。
堆的概念:
堆(英语:Heap)是计算机科学中的一种特别的树状数据结构。若是满足以下特性,即可称为堆:“给定堆中任意节点 P 和 C,若 P 是 C 的父节点,那么 P 的值会小于等于(或大于等于) C 的值”。若父节点的值恒小于等于子节点的值,此堆称为最小堆(英语:min heap);反之,若父节点的值恒大于等于子节点的值,此堆称为最大堆(英语:max heap)。在堆中最顶端的那一个节点,称作根节点(英语:root node),根节点本身没有父节点(英语:parent node)。
栈是作为执行线程的临时空间留出的内存。调用函数时,在栈顶部保留一个块,用于本地变量和一些临时数据。当该函数返回时,该块将变为未使用状态,并可在下次调用函数时使用。堆栈始终以 LIFO (后进先出)顺序保留;最近保留的块始终是要释放的下一个块。这使得跟踪栈非常简单;从栈中释放块只不过是调整一个指针。
堆是为动态分配留出的内存。与栈不同,堆中的块的分配和释放没有强制模式;您可以随时分配一个块并随时释放它。这使得在任何给定时间跟踪堆的哪些部分被分配或释放变得更加复杂;有许多自定义堆分配器可用于调整不同使用模式的堆性能。
每个线程都有一个栈,而应用程序通常只有一个堆(尽管为不同类型的分配设置多个堆并不罕见)。
它们在多大程度上受操作系统或语言运行时控制?
操作系统在创建线程时为每个系统级线程分配堆栈。 通常,语言运行库调用OS来为应用程序分配堆。
它们的范围是什么?
堆栈附加到一个线程,因此当线程退出堆栈时将被回收。 堆通常在应用程序启动时由运行时分配,并在应用程序(技术过程)退出时回收。
是什么决定了它们的大小?
创建线程时设置堆栈的大小。 堆的大小在应用程序启动时设置,但可以在需要空间时增长(分配器从操作系统请求更多内存)。
哪一个更快?
栈更快,因为访问模式使得从中分配和释放内存变得微不足道(指针/整数简单地递增或递减),而堆在分配或释放中涉及更复杂的临时数据保存。 此外,栈中的每个字节都经常被频繁地重用,这意味着它往往被映射到处理器的缓存,使其非常快。 堆的另一个性能损失是堆(主要是全局资源)通常必须是多线程安全的,即每个分配和释放都需要需要与程序中的“所有”其他堆访问代表性地同步。
29.智能指针
请你来说一下C++中的智能指针
30.class和struct区别
C++中class和struct的区别
31.非极大值抑制(即NMS)
NMS算法(NonMaximumSuppression)
32.a+b,位运算
位运算
33.smooth L1和L1,L1正则化的表达式
L1, L2以及smooth L1 loss
34.batch size
Batch size对模型训练有什么影响?其大小是怎么选取的?(会影响训练的稳定性,Batch size过小会使Loss曲线振荡的比较大,大小一般按照2的次幂规律选择,至于为什么?没有答出来,面试官后面解释是为了硬件计算效率考虑的,海哥后来也说GPU训练的时候开的线程是2的次幂个
35.Batch Normalization的原理?可学习的参数有哪些?
Batch Normalization
36.传统图像算法(HOG,SIFT)
HOG原理与OpenCV实现
Sift算子特征点提取、描述及匹配全流程解析
37.EM算法
EM算法全称为Expectation Maximization,即期望极大算法,是一种用于处理含有隐变量(hidden variable)的概率模型参数的极大似然估计,或极大后验概率估计。EM算法是一种迭代算法,每一次迭代可分为两步:E步,求期望(Expectation);M步,求极大(Maximization)。
最大熵原则:
对于一个随机事件的概率分布进行预测时,预测应当满足全部已知的约束,而对未知的情况下不做任何主观的假设,在这种情况下,概率分布是最均匀的,预测的风险性最小,因此得到的概率分布的熵最大。

这里EM算法的流程借用他人的流程图,这样看来并不好理解,所以我们以kmean算法的实现为例,在实现kmean聚类前,我们首先要假设出k个聚类中心,这就是上图中的隐变量Z,再结合Z就可以给当前样本的类别theta赋初值,然后通过计算类别平均中心来更新Z,theta,当Z不再有变化也就是theta不再有变化时,聚类就完成了。
相似的使用EM算法来完成的还有GMM聚类,不同于Kmean的是,GMM是使用k个c维高斯分布分别去包围k个类别的样本,而Kmean应该是用k个圆来包围。
38.LR和线性回归
一、线性回归和逻辑回归
对线性回归、逻辑回归、各种回归的概念学习
39.最大堆最小堆
算法之堆排序(最大堆c++实现)
深入理解堆(最大堆,最小堆及堆排序)
40.什么是导数、偏导数、方向导数和梯度?
导数、微分、偏导数、全微分、方向导数、梯度的定义与关系
全导数、偏导数、方向导数
导数:函数在某点的导数是函数在该点的瞬时变化率,几何上即该点切线的斜率
偏导数:函数在某点沿坐标轴方向的导数
方向导数:函数在某点沿某一方向的导数(偏导数是方向导数沿坐标轴方向的特例)
梯度:梯度是一个由函数对各坐标轴的偏导数组成的向量,方向导数可以写成梯度grad和单位方向向量l的内积,故当grad与l同方向时,方向导数取得最大值,故梯度的方向时方向导数取最大值时的方向,梯度的幅值是方向导数的最大值
41.分类和回归的区别,各举例3个模型
机器学习 — 1. 线性回归与分类, 解决与区别
分类预测离散值输出,常见分类模型有感知机、朴素贝叶斯、逻辑回归(LR)、支持向量机(SVM)等;
回归预测连续值输出,常见回归模型有线性回归、多项式回归、岭回归(L2正则化)、Lasso回归(L1正则化)等
42.卷积层和全连接层的区别
CNN笔记:通俗理解卷积神经网络
深入理解卷积层,全连接层的作用意义
43.分类中为什么交叉熵损失函数比均方误差损失函数更常用?
交叉熵损失函数关于输入权重的梯度表达式与预测值与真实值的误差成正比且不含激活函数的梯度,而均方误差损失函数关于输入权重的梯度表达式中则含有,由于常用的sigmoid/tanh等激活函数存在梯度饱和区,使得MSE对权重的梯度会很小,参数w调整的慢,训练也慢,而交叉熵损失函数则不会出现此问题,其参数w会根据误差调整,训练更快,效果更好
神经网络:损失函数详解
常用损失函数小结
44.make、cmake、g++这几者之间的关系
Cmake学习笔记(一):认识gcc、make、cmake
gcc、g++、make、cmake区别
1.GCC
GCC全称是GNU Compiler Collection,是一个编译套件。我们可以通过gcc/g++来编译目标项目。
但是当项目结构复杂时,通过gcc/g++命令直接编译会出现非常多不便之处,于是出现了Makefile。
2.Makefile
简单地说Makefile就是一个包含一堆有条理的gcc/g++编译命令的文件,便于提高开发者的工作效率。
Makefile是需要开发者自己手写的。
那之前可以通过在终端输入gcc/g++命令来编译项目,现在有了Makefile,又要怎么用呢?
这就讲到Make工具了。
3.Make
(还是简单地说吧,)Make工具就是“读取”并执行Makefile文件中的编译指令,从而进行项目编译。
4.CMakelists
当项目非常庞大,目录结构非常复杂时,手写Makefile就是一件非常恐怖的事情了,你需要在不同的目录底下写不同的Makefile,这可能有非常多个。
这时候就有CMakelists来拯救开发者了。CMakelists可以通过更简单的写法来生成对应的Makefile文件。
怎么生成呢?就是写好CMakelists.txt之后,通过CMake工具生成。
5.CMake
类似Make工具的功能,CMake工具就是“读取”并执行CMakelists.txt文件中的语句,来生成对应的Makefile。然后开发者就可以通过Make工具来“执行”Makefile了。
45.深度学习中网络训练时loss不降的解决方法
[深度学习] loss不下降的解决方法
46.常用的一阶、二阶优化算法有哪些?区别是什么?
一阶的有:梯度下降法GD、SGD、ASGD、指数加权平均AdaDelta、RMSProp、Adam
二阶的有:牛顿法、拟牛顿法(二阶收敛更快)
牛顿法好材料
基础概念:
梯度(一阶导数)考虑一座在 (x1, x2) 点高度是 f(x1, x2) 的山。那么,某一点的梯度方向是在该点坡度最陡的方向,而梯度的大小告诉我们坡度到底有多陡。
Hesse 矩阵(二阶导数,二阶梯度)
牛顿法是一种在实数域和复数域上近似求解方程的方法。方法使用函数f (x)的泰勒级数的前面几项来寻找方程f (x) = 0的根。牛顿法最大的特点就在于它的收敛速度很快。主要有两个缺陷,一个是需要计算Hessian矩阵,需要O(np^2) 的复杂度,另外一个便是计算Hessian的逆矩阵需要O(p^3 )的复杂度。
47.cv岗位 - 深度学习面试知识总结
48.类继承,多态
理解C++三大特性
C++四大特性——多态 的总结
class Shape {
public:
virtual void draw() const;
virtual void error (const std::string& msg) {std::cout << msg << std::endl;};
int objectID() const { return 1;};
};
class Rectangle: public Shape {
public:
void draw() const {std::cout << "Rect Draw!" << std::endl;};
};
class Ellipse: public Shape {
public:
void draw() const {std::cout << "Elli Draw!" << std::endl;};
};
49.二叉树前、中、后序遍历(递归、非递归形式(较难))
二叉树前序、中序、后序遍历非递归写法的透彻解析
二叉树前中后序遍历——迭代和栈方式实现
非递归实现二叉树先序、中序、后序遍历
50.快速排序、基数排序、插入排序、归并排序
这或许是东半球讲十大排序算法最好的一篇文章
51.动态规划相关
最长上升子序列LIS(重要)
编辑距离
平面最近点对距离
最大子串和
最长公共子序列
区间DP、数位DP、树形DP。(较难DP(面试只需了解): 插头DP、状态压缩DP、斜率优化DP、概率DP)
题目:HDU5489(LIS)、HDU4323(编辑距离)、HDU1561(树形DP),HDU3001(状压DP)、HDU3664(排列DP)、HDU4507(数位DP)、HDU3480(斜率优化DP)、HDU2993(斜率优化DP)、HDU4003(树形DP)、HDU4028(离散化DP)、HDU4842(简单DP)、HDU4734(数位DP)、HDU3652(简单数位DP)、HDU4389(数位DP)、HDU3709(数位DP)、51nod1006(最长公共子序列)、HDU5045(压缩DP)、HDU5115(简单区间DP)、HDU4607(树形DP)、HDU5155(简单DP计数)、HDU4512(LIS)、HDU4532(排列DP)、HDU1007(平面最近点对距离)
动态规划
52.字典树
第K大数
B+ B树
红黑树
KD树(面试可能会问理论)
伸展树(不做要求)
线段树
树状数组(与线段树功能类似,实现方式不同)
并查集
字典树
字典树(Trie树)模板以及简单的入门题总结
53.机器学习和深度学习中值得弄清楚的一些问题
54.机器学习常用算法总结
55.机器学习连载系列
56.各种机器学习算法的应用场景分别是什么(比如朴素贝叶斯、决策树、K 近邻、SVM、逻辑回归最大熵模型)?
57.cv岗位 - 机器学习面试知识总结
58.机器学习里面的聚类和分类模型有哪些?
分类:LR、SVM、KNN、决策树、RandomForest、GBDT
回归:non-Linear regression、SVR(支持向量回归–>可用线性或高斯核(RBF))、随机森林
聚类:Kmeans、层次聚类、GMM(高斯混合模型)、谱聚类
58.虚函数和纯虚函数的区别?
C++:虚函数、虚表和纯虚函数
纯虚函数:要求继承类必须含有某个接口,并对接口函数实现。
虚函数:继承类必须含有某个接口,可以自己实现,也可以不实现,而采用基类定义的缺省实现。
非虚函数:继承类必须含有某个接口,必须使用基类的实现。
59.重载、覆盖、重写的区别
override->重写(=覆盖)、overload->重载、polymorphism -> 多态
override是重写(覆盖)了一个方法,以实现不同的功能。一般是用于子类在继承父类时,重写(重新实现)父类中的方法。
重写(覆盖)的规则:
1、重写方法的参数列表必须完全与被重写的方法的相同,否则不能称其为重写而是重载.
2、重写方法的访问修饰符一定要大于被重写方法的访问修饰符(public>protected>default>private)。
3、重写的方法的返回值必须和被重写的方法的返回一致;
4、重写的方法所抛出的异常必须和被重写方法的所抛出的异常一致,或者是其子类;
5、被重写的方法不能为private,否则在其子类中只是新定义了一个方法,并没有对其进行重写。
6、静态方法不能被重写为非静态的方法(会编译出错)。
overload是重载,一般是用于在一个类内实现若干重载的方法,这些方法的名称相同而参数形式不同。
重载的规则:
1、在使用重载时只能通过相同的方法名、不同的参数形式实现。不同的参数类型可以是不同的参数类型,不同的参数个数,不同的参数顺序(参数类型必须不一样);
2、不能通过访问权限、返回类型、抛出的异常进行重载;
3、方法的异常类型和数目不会对重载造成影响;
多态的概念比较复杂,有多种意义的多态,一个有趣但不严谨的说法是:继承是子类使用父类的方法,而多态则是父类使用子类的方法。
一般,我们使用多态是为了避免在父类里大量重载引起代码臃肿且难于维护。
C++中重载、重写(覆盖)和隐藏的区别
60.C++学习记录
61.c++中的STL
C++中STL用法总结
STL笔试面试题总结(干货)
C++中STL用法超详细总结
专栏
C++中的STL中map用法详解
62.处理高并发
高并发详解(一)
用一个示例讲解我是如何处理高并发的
一、将数据存到redis缓存
二、使用高性能的服务器、高性能的数据库、高效率的编程语言、还有高性能的Web容器.
三、使用Ngnix负载均衡
63.浅拷贝,深拷贝
C++细节 深拷贝和浅拷贝(位拷贝)详解
C++浅拷贝(值拷贝)和深拷贝(位拷贝)
64.线性回归和逻辑回归
线性回归和逻辑回归
65.损失函数的优化算法
最全的机器学习中的优化算法介绍
66.部分总结(c/c++)
C/C++
66.深度学习相关数学推导
刘建平
67.某某博客
68.c++经典面试题(最全,面中率最高)
69.Relu
ReLU激活函数:简单之美
ReLU为什么比Sigmoid效果好
70.AP与mAP
AP与mAP的详解
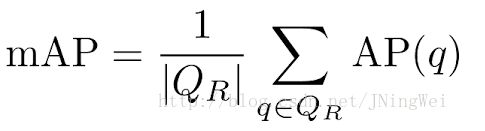
71.傅里叶级数
傅里叶级数推导过程–通俗易懂,强烈推荐!!!
72.函数模板和类模板
模板——函数模板与类模板
73.C++面试题
74.C++设计模式
C++设计模式
75.TCP/IP协议,UDP
TCP/IP五层(四层)模型——传输层(UDP协议、TCP协议)
76.常见应用层协议
应用层常见协议——知识点
77.软件开发测试流程
软件测试流程及规范
78.常用测试用例设计方法总结
常用测试用例设计方法总结
79.自动化测试脚本编写
基于selenium的自动化测试脚本编写-python
自动化脚本编写规范
80.树的前中后序遍历(递归非递归)
树的前中后序遍历
HR面
(1) 期望薪资
(2) 你理想的工作是什么样的?
(3) 关于你以后的工作打算,你有什么想法?
(4) 职业规划
(5) 做项目时遇到的困难及解决方法?
(6)做科研辛苦吗?
(6) 对公司的看法?为什么应聘我们公司?
(7) 你在同龄人中处于什么档次 和大牛的差距在哪?
(8) 你跟同龄人相比有什么优势?
(9) 你除了我们公司,还投了哪些公司?
说几个
(10) BAT之外,你最最想去的是哪家公司,为什么?
(11) 如果我们给你发offer,你还会继续秋招么?
(12) 【跨专业】本科+研究生在本专业学了多年,为什么没在本行业求职?
(13) 【家离企业所在地较远】为什么想来xx地方工作,父母支持么?
(14) 【对象】如果对象和你在意向工作地发生分歧,你怎么处理?
(15) 优缺点?
(16) 介绍你一次最失败的一次经历?
(17) 介绍你一次最成功的一次经历?
(18) 这份工作你有想过会面对哪些困难吗?
(19) 如果你发现上司做错了,你将怎么办?
(20)你觉得大学生活使你收获了什么?
(21)你对加班的看法?
(22)当公司给出的待遇偏低不足以吸引到优秀人才的时候,你该怎么去招聘?