梯度下降算法总结(Gradient Descent Algorithms)
0 摘要
机器学习与深度学习中常用到梯度下降(Vanilla Gradient Descent)优化方法及其改进的变种(Improved Variants),不同专业书与教程中均有所涉及,但缺乏系统性与完整性.本文在参阅相关论文与教程的基础上,通过对比总结,系统性归纳并说明其各自特点,同时结合个人理解与实际使用情况,给出一定的补充,以便交流学习.
1 梯度下降理论基础
对于机器学习与深度学习问题,虽然求解对象多样,但本质上都是优化目标函数(Objective Function)或效用函数(Utility Function)的控制参量 (一维标量、二维或高维向量),实现目标函数值的最小化(极小化)或效用函数的最大化(极大化),求解最大化(极大化)的问题需采用梯度上升方法(Gradient Ascent),对效用函数取负,可等效为目标函数优化问题,本文仅以最小化目标函数为例:
(一维标量、二维或高维向量),实现目标函数值的最小化(极小化)或效用函数的最大化(极大化),求解最大化(极大化)的问题需采用梯度上升方法(Gradient Ascent),对效用函数取负,可等效为目标函数优化问题,本文仅以最小化目标函数为例:

为了求解目标函数![]() ,可从单变量函数
,可从单变量函数 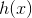 的Taylor展开式入手,即:
的Taylor展开式入手,即:

当 足够接近
足够接近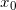 时,若仅考虑一阶导数,二阶以上导数项作为高阶无穷小予以忽略,则:
时,若仅考虑一阶导数,二阶以上导数项作为高阶无穷小予以忽略,则:

考虑多变量函数 的展开形式,当 ![]() 足够接近
足够接近![]() 时,同理得到:
时,同理得到:

再回到(1)式对应的优化问题,以二维为例(高维同理),此时 有两个变量,即 ![\theta=[\theta_1,\theta_2]^T](http://img.e-com-net.com/image/info8/3c1a492b81a34c30a0c8c98eb89f546d.gif) ,
,

其中 ![]() 为常数项,对应变化前的位置目标函数值,
为常数项,对应变化前的位置目标函数值, 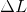 符合下式:
符合下式:

其中,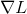 就是通常所说的梯度,实质上是一个方向导数,即:
就是通常所说的梯度,实质上是一个方向导数,即:


其中![]() , 则式(5)变为:
, 则式(5)变为:

为了使得目标函数![]() 随迭代过程逐渐减小, 需为负值.进一步从式(8)可知
随迭代过程逐渐减小, 需为负值.进一步从式(8)可知 ![]() 是两个向量 与
是两个向量 与 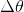 的內积,通常为了保证迭代过程的平稳性,可限定步长大小满足
的內积,通常为了保证迭代过程的平稳性,可限定步长大小满足![]() ,此时当且仅当两向量的夹角为180°(向量反向)时满足目标函数下降速度最快(图示法见下图所示):
,此时当且仅当两向量的夹角为180°(向量反向)时满足目标函数下降速度最快(图示法见下图所示):

此时选取:

其中![]() , 且满足
, 且满足 ![]() ,从而:
,从而:

由此可知,梯度下降的过程, 本质上是采用小步长条件下,选取能够使得目标函数最速下降方向的一种逐步迭代方法,见下图所示(类似于人站在山顶,寻最优径最快到达谷底).

2. 梯度下降迭代方法
2.1 批量梯度下降法(BGD)
批量梯度下降法(Batch Gradient Descent,简称BGD)是梯度下降法最原始的形式,它的具体思路是在更新每一参数时都使用所有的样本来进行更新,其数学形式如下:
(1)对下述目标函数(Mean Square loss)


(2) 由于是最小化风险函数,所以按照每个参数的梯度负方向来更新每个变量:

从上式可知,它得到的是一个全局最优解,但是每迭代一步,都要用到训练集所有的数据,如果样本数目很大,那么其迭代速度很慢.
优点:全局最优解;易于并行实现.
缺点:当样本数目很多时,训练过程会很慢.
从迭代次数看,BGD迭代次数相对较少.其迭代的收敛曲线示意图可表示如下图所示.

2.2 随机梯度下降法(SGD)
由于BGD在更新每一个参数时,都需要所有的训练样本,因此训练过程会随着样本数量的加大而变得异常缓慢.随机梯度下降法(Stochastic Gradient Descent,简称SGD)正是为了解决批量梯度下降法这一弊端而提出.
将上述目标函数式(11)改写为如下:

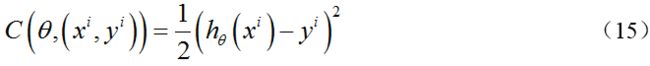

采用SGD迭代时,通常首先随机打乱原始样本数据顺序,然后每次随机选取一个样本迭代指定的步数,再逐步扩展至所有样本.随机梯度下降是通过每个样本来迭代更新一次,如果样本量很大的情况(例如几十万),那么可能只用其中几万条或者几千条的样本,就已经将θ 迭代到最优解了,对比上面的批量梯度下降,迭代一次需要用到十几万训练样本,一次迭代不可能最优,如果迭代10次的话就需要遍历训练样本10次.但是,SGD伴随的一个问题是噪音较BGD要多,使得SGD并不是每次迭代都向着整体最优化方向,出现局部反复抖动但最终趋于收敛.
优点:训练速度快.
缺点:准确度下降,并不是全局最优;不易于并行实现.
从迭代的次数上来看,SGD迭代的次数较多,在解空间的搜索过程看起来很盲目.其迭代的收敛曲线示意图可以表示如下图.
2.3 小批量梯度下降法(MBGD)
由上述两种梯度下降法可以看出,其各自均有优缺点,为了在两种方法的性能之间取得一个折衷,即算法的训练过程比较快,而且也要保证最终参数训练的准确率,而这正是小批量梯度下降法(Mini-batch Gradient Descent,简称MBGD)的初衷.
MBGD在每次更新参数时使用 b 个样本(b 一般为10),其迭代形式为:

即每次选取10个样本迭代指定的步数,再使用后面顺延的10个样本迭代指定步数,依次迭代直至使用完全部样本.
3 普通梯度下降(VGD)方法的变种
上述不同的梯度下降迭代方法本质上都是普通梯度下降(Vanilla Gradient Descent)方法,只是迭代过程对数据样本的使用有所差异,但VGD迭代存在以下问题:
- 选择合适的learning rate比较困难,需在保证快速迭代与稳定收敛(避免发散或反复震荡)之间取得平衡.
- 事先指定的学习率变化函数(如指数衰减函数)难以适应大样本数据的特性.
- 对于稀疏数据,对不同维度的特征难以适应以不同幅度大小进行迭代更新.
- 对于神经网络等高维非凸目标函数,容易卡在鞍点(saddle point)难以继续学习.
针对上述挑战,不同时期相关研究人员提出了多种不同的改进版本.
3.1 Momentum
动量优化方法(Momentum Optimization)由Boris Polyak 在 1964 年首次提出.想象一个保龄球在一个光滑的斜坡表面上平缓的滚动:它会缓慢地开始,但是它会很快地达到最终的速度(如果有一些摩擦或空气阻力的话). 这是提出动量优化背后的一个非常简单的想法.相比之下,普通的梯度下降只需要沿着斜坡进行小的有规律的下降步骤,所以需更多的时间才能到达底部. 这样一步一步下去,带着初速度的小球就会极速的奔向谷底.动量优化方法的迭代形式如下:

![]()
其中超参数μ 为动量因子(取值在0-1之间),通常取0.9或相近值,用于模拟摩擦的影响作用,对于高摩擦μ=0 ,对于无摩擦μ=1 .即VGD实际上就是高摩擦的特例,无法实现“速度”项的累积.
为了直观理解引入动量项对速度提升的影响作用,可对式(18)、(19)作如下推导:
简单的假定梯度项 ![]() 保持为常量C ,则式(18)变换为:
保持为常量C ,则式(18)变换为:

如果取μ=0.9 ,由上式(20)可知最终速度等于10倍的学习率与梯度值的乘积,也就是说优化速度将相当于普通梯度下降(VGD)方法的10倍,如果取μ=0.99,优化速度将达到100倍之巨!然而实际迭代过程中因梯度量 ![]() 并非常量,梯度值随迭代的进行总体上呈减小趋势,因此实际采用Momentum优化的提升效果将达不到10倍或100倍,但仍有几倍或几十倍的提升,实际使用效果也确实如此.
并非常量,梯度值随迭代的进行总体上呈减小趋势,因此实际采用Momentum优化的提升效果将达不到10倍或100倍,但仍有几倍或几十倍的提升,实际使用效果也确实如此.
采用动量优化方法后,迭代过程会以更快的速度趋于收敛,同时因自带momentum项,能够以更快速度越过局部最小值(local minima).
优点:
1)下降初期,使用上一次参数更新,下降方向一致,乘上较大的能够进行很好的加速.
2)下降中后期时,在局部最小值来回震荡时,使得更新幅度增大,越过梯度为0的平稳点(plateaus).
3)在梯度改变方向的时候, 能够减少更新.
缺点:需调整超参数μ (多数情况下无需调整,直接选取0.9)
注意:由于累积了momentum项,选取μ=0.9 ,沿用VGD迭代时调整好的学习率会有发散的风险,此时需重新调整学习率,或适当降低超参数μ ,使其小于0.9.
总而言之,momentum项能够在相关方向加速GD迭代,抑制振荡,从而加快收敛.
3.2 NAG
NAG (Nesterov accelerated gradient)优化方法由Yurii Nesterov于1983年首次提出, 改进自Momentum Optimization算法,让每一次的参数更新方向不仅取决于当前位置的梯度,还受到上一次参数更新方向的影响,具体迭代形式如下:


令![]() ,可得二者对比见下图所示:
,可得二者对比见下图所示:

与Momentum公式的唯一区别在于,NAG不是根据当前参数位置,而是根据先走了本来计划要走的一步后,达到的参数位置计算出来的.
对于这个改动,很多文章给出的解释是,能够让算法提前看到前方的地形梯度,如果前面的梯度比当前位置的梯度大,那么就可以把步子迈得比原来大一些,如果前面的梯度比现在的梯度小,那我就可以把步子迈得小一些.这个大一些、小一些,都是相对于原来不看前方梯度、只看当前位置梯度的情况来说的.
为了从另一个角度更深入地理解这个算法,可以对NAG原来的更新公式进行如下变换:
基于原迭代式(21)、(22)可得:

令:
![]()


则原迭代式(22)等效变换为:

进一步对上式右侧最后一项 展开可得:



最终我们就得到了NAG的等效形式如下:


![]() 中右边多出的一项就是在近似目标函数的二阶导.所以NAG本质上是多考虑了目标函数的二阶导信息,从而实现加速收敛.其实所谓“往前看”的说法,在牛顿法这样的二阶方法中也是经常提到,比喻起来是说“往前看”,数学本质上则是利用了目标函数的二阶导信息.
中右边多出的一项就是在近似目标函数的二阶导.所以NAG本质上是多考虑了目标函数的二阶导信息,从而实现加速收敛.其实所谓“往前看”的说法,在牛顿法这样的二阶方法中也是经常提到,比喻起来是说“往前看”,数学本质上则是利用了目标函数的二阶导信息.
小结:相对于普通Momentum,NAG算法的改进在于,以“向前看”看到的梯度而不是当前位置梯度去更新.经过变换之后的等效形式中,NAG算法相对于普通Momentum多了一个本次梯度相对上次梯度的变化量,这个变化量本质上是对目标函数二阶导的近似.由于利用了二阶导的信息,NAG算法才会比普通Momentum以更快的速度收敛.
特点:
- 相比普通Momentum,NAG算法自带“二阶导”信息,迭代收敛更快.
- 当动量推动参数θ 横跨最优解θ* 左右两侧时,普通Momentum继续推进越过最优解θ* ,而NAG推回θ* 对应的谷底附近,这有助于减少振荡,从而更快地收敛.
3.3 AdaGrad
如果我们希望根据每个参数去调节学习率,那么AdaGrad恰好解决了这个问题.AdaGrad算法根据每个参数过去的更新历史来决定现在的更新学习率.AdaGrad会记录之前每一步更新值的平方,通过将这些累加起来调节每一步学习率的大小.这样一来,对于那些频繁更新的参数,学习率会比较小;而对于那些不频繁更新的参数,学习率会比较大.从这个角度看,AdaGrad很适合比较稀疏的数据.其迭代公式如下:
![]()


根据上式(33)、(34)可知,迭代过程每个 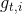 累积了目标函数对参数
累积了目标函数对参数 ![]() 的偏导数即梯度值的平方.随迭代进行, 将变得越来越大,这样梯度矢量将按比例
的偏导数即梯度值的平方.随迭代进行, 将变得越来越大,这样梯度矢量将按比例 ![]() 缩小,由于实际乘以梯度量不变,这等价于对学习率
缩小,由于实际乘以梯度量不变,这等价于对学习率  进行了缩放,起到自适应调整学习率的效果.
进行了缩放,起到自适应调整学习率的效果.
将上述式(35)以向量化的形式进行简化,得到如下迭代式:

其中 ![]() 表示矩阵对应位置乘积即Hadamard积.
表示矩阵对应位置乘积即Hadamard积.
上述 是一个极小值,为了数值稳定(避免除0,通常取1e-8).AdaGrad的一个优点是它可以避免手动去调节学习率,多数时候只要初始化学习率为0.01即可,然后可以放任不管.但是,一个明显的缺点是随着更新步骤的增多,学习率将会一直减小直至接近于0,这样就会导致迭代更新提前停滞.
是一个极小值,为了数值稳定(避免除0,通常取1e-8).AdaGrad的一个优点是它可以避免手动去调节学习率,多数时候只要初始化学习率为0.01即可,然后可以放任不管.但是,一个明显的缺点是随着更新步骤的增多,学习率将会一直减小直至接近于0,这样就会导致迭代更新提前停滞.
优点:
- 迭代前期gt 较小的时候, regularizer较大,能够放大梯度.
- 迭代后期gt 较大的时候,regularizer较小,能够约束梯度.
- 适合处理稀疏梯度.
缺点:
- 依赖于人工设置一个全局学习率η .
- 学习率η 设置过大的话,会使regularizer过于敏感,对梯度的调节太大.
- 迭代中后期,分母上梯度平方的累加将会越来越大,使得训练提前结束.
3.4 AdaDelta
AdaDelta也是为了解决Datagram的学习率消失问题,与AdaGrad累积历次更新所不同的是,AdaDelta将过去的更新限制在固定的长度w 里面.并且,由于存储过去w 个更新在计算上效率很低,取而代之的是通过采取指数衰减的形式来保留最近的更新项(梯度平方).即t 时刻的滑动平均值 取决于历史梯度平方的平均值与当前梯度平方,具体如下:

其中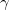 为指数衰减率,取值0~1,常取0.9,于是将AdaGrad方法迭代式(36)中 使用式(37)进行替换,则得到:
为指数衰减率,取值0~1,常取0.9,于是将AdaGrad方法迭代式(36)中 使用式(37)进行替换,则得到:

定义![]() ,则:
,则:

与此同时,再定义一个指数衰减滑动平均量(基于参数更新量![]() 的平方而不是梯度平方):
的平方而不是梯度平方):


由于 ![]() 未知,此时采用历史平均值
未知,此时采用历史平均值 ![]() 近似之,同时将学习率η 以
近似之,同时将学习率η 以![]() 进行替换,于是得到最终迭代表达式:
进行替换,于是得到最终迭代表达式:


结合上述迭代式可知,此时学习率已在迭代式中消除,迭代时无需再设置学习率,相比于AdaGrad方法,AdaDelta方法并不累积历次梯度平方,因此可以有效缓解随迭代进行而出现的学习率逐渐减小导致的提前停滞问题.
3.5 RMSProp
RMSProp与AdaDelta算法几乎是同时提出,由Geoff Hinton(“深度学习之父”)于2012年在Coursera 课程中提出,未在公开论文中发表,是为了解决算法AdaGrad的学习率消失问题,通过在历史更新与梯度平方之间设置一定的比例.其迭代公式如下:


由迭代式(44)、(45)可知 RMSProp其实是AdaDelta方法 取0.9时的一个特例,因此其效果介于AdaGrad方法与AdaDelta方法之间.
3.6 Adam
Adam算法于最近几年被提出来,该算法非常有效,只需要一阶梯度,并且对内存要求也很低.Adam同时考虑了梯度以及梯度的平方,因此,Adam同时具有AdaGrad和AdaDelta的优点,能够很好地适应于稀疏数据或不当的初始化网络.其迭代公式如下:





上述式子中,![]() 、
、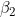 均为常数(文献推荐取值
均为常数(文献推荐取值![]() ),无穷小 取1e-8,
),无穷小 取1e-8, ![]() 和
和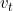 分别是梯度的一阶矩估计和二阶矩估计,初始化时均设置为0,可以看作是对期望
分别是梯度的一阶矩估计和二阶矩估计,初始化时均设置为0,可以看作是对期望![]() 、
、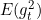 的估计;
的估计;![]() 、
、![]() 分别是对
分别是对 ![]() 、 的校正,这样可以近似为对期望的无偏估计。可以看出,直接对梯度的矩估计对内存没有额外的要求,而且可以根据梯度进行动态调整,从而对学习率
、 的校正,这样可以近似为对期望的无偏估计。可以看出,直接对梯度的矩估计对内存没有额外的要求,而且可以根据梯度进行动态调整,从而对学习率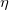 形成一个动态约束
形成一个动态约束 ![]() ,而且有明确的范围.
,而且有明确的范围.
Adam(Adaptive Moment Estimation)本质上是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率,同时对学习率的范围进行了约束,使得迭代过程比较平稳.
特点:
- 结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点.
- 对内存需求较小.
- 为不同的参数计算不同的自适应学习率.
- 也适用于大多数非凸优化问题.
- 适用于大数据集和高维空间.
3.7 其它方法(AdaMax 与Nadam等)
VGD方法的其它变化形式有AdaMax、Nadam等,其中AdaMax基于Adam方法将式 对应的2范数推广至无穷范数,而Nadam(Nesterov-accelerated Adaptive Moment Estimation)方法则结合了Adam与NAG方法的各自特点,将Adam中vanilla gradient考虑成accelerated gradient形式,这两种方法都是对Adam方法的扩展,本质上没有显著差异.
上述两种方法目前在文献中使用较少,且未有明确结论称其较Adam方法在迭代收敛速度和节省储存空间方面有明显提升,同时目前主流学习框架TensorFlow等均未列入,因此目前暂不推荐使用.
4 方法对比与总结
4.1 不同方法的比较
通过前文对梯度下降方法及其变种进行的阐述可知,不同方法有其各自特点,但如果把上述方法按照含有梯度![]() 和梯度的平方
和梯度的平方![]() 项来分类,则可明显的分成两类:
项来分类,则可明显的分成两类:
- 仅含有梯度
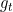 的方法是 VGD、Momentum、NAG等固定学习率的方法.
的方法是 VGD、Momentum、NAG等固定学习率的方法. - 同时含有梯度 和梯度平方
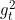 的方法AdaGrad、AdaDelta、RMSProp、Adam、AdaMax,Nadam等偏向自适应学习率调整的方法.
的方法AdaGrad、AdaDelta、RMSProp、Adam、AdaMax,Nadam等偏向自适应学习率调整的方法.
这两类方法一种偏向于传统做法,主要基于梯度的物理意义,一种偏向于数学改良,但实际上,对于一般的机器学习问题,如基于物理模型构建的优化问题:矩阵分解、分类、回归等非神经网络一类的学习问题,由于目标函数中含有多项组成部分(除regularizer项以外),每一部分代表了不同的含义,且不同部分的权重不一,采用类似Adam等方法由于引入了梯度的平方项部分以及梯度平方的累积,客观上改变了原loss函数中不同部分的权重分量,使得参数更新时不同部分迭代快慢的顺序发生了变化,此时需要对原VGD等方法迭代时的权重系数进行调整,否则易出现迭代求解结果背离物理量的真实含义.
事实上,上述第二大类方法也正是由于深度学习兴起后出现的梯度下降改良方法,结合不同方法的特点,可以得出如下结论:
- 基于传统机器学习优化学习问题(特别是耦合参数本身有一定的物理意义)时,可优先采用Momentum Optimization 和NSG方法,如果调整后的超参数适当,再采用Adam方法;
- 对于深度学习问题,尤其是网络层数较多,求解的未知变量数量巨大,达到百万、千万甚至数亿的量级,且对存储空间要求较高时优先选用Adam方法;
- Adam方法综合了自适应学习率调整方法的主要优点,目前属于主流自适应学习率优化方法,其它相近方法如AdaGrad、AdaDelta、RMSProp、AdaMax、Nadam在有必要进行效果对比时可以逐一比较,一般情况下可以不予考虑.
4.2 梯度导数项阶次扩展
上述所讨论的梯度下降方法(仅NAG方法含有简单的二阶导信息)都只依赖于一阶偏导数(Jacobian Matrix),而涉及优化方法的文献中常包含基于二阶偏导数(Hessian Matrix)的算法,为了具体讨论这个问题,假设最小化目标函数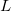 ,其中 是含有多个参数的函数,
,其中 是含有多个参数的函数,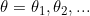 ,所以
,所以![]() ,再次借助于Taylor展开式,目标函数在
,再次借助于Taylor展开式,目标函数在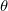 处被近似展开为:
处被近似展开为:

将上式压缩为矩阵表示形式:

其中 就是通常的梯度向量,H 就是矩阵形式的Hessian矩阵,其中第jk 项就是 ,对H 矩阵化表示形式如下:

对式(52)舍弃三阶及以上高阶导数项,则得到:

使用微积分将上式右边进行最小化,然后选择:
![]()
根据式(54)是目标函数的比较好的近似表达式,使得点θ 移动到 可降低目标函数值,则可得到Hessian优化的迭代步骤:
- 初始化选择开始点
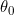 ;
; - 更新到新点
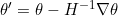 ,其中
,其中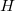 和
和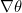 在 处计算求得;
在 处计算求得; - 更新
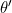 到新点
到新点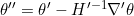 ,其中
,其中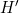 和
和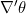 在 处计算求得.
在 处计算求得.
然而上述算法很难应用于大规模机器学习或深度神经网络,因为若每个输出有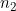 个Hessian元素值(其中n 是参数的数量),而不是每个输出只有n 个Jacobian元素值,那么当参数以万计,二阶优化算法将导致占用内存空间巨大,同时,对大维度矩阵H 求逆也很慢,因此该方法难以实用化,最终使得目前梯度下降等优化方法仍以一阶导为主流.
个Hessian元素值(其中n 是参数的数量),而不是每个输出只有n 个Jacobian元素值,那么当参数以万计,二阶优化算法将导致占用内存空间巨大,同时,对大维度矩阵H 求逆也很慢,因此该方法难以实用化,最终使得目前梯度下降等优化方法仍以一阶导为主流.
4.3 梯度下降方法的局限性
梯度下降方法有其自身局限性,即在目标函数平缓区段梯度值近似为0,迭代更新慢,同时易卡在鞍点和局部最优解附近(见下图),因此对于深度学习等优化问题,通常除了采用Adam等优化方法外,还需要借助于批归一化(Batch Normalization)、弃权(Droupout)、梯度裁剪(Gradient Clipping)等方法改善优化的最终解.
对于一般性非神经网络类机器学习问题,由于高维非凸函数的全局最优解很难求取,
因此通常的做法是采用局部最优解近似全局最优解作为求解问题的近似.
除梯度下降方法以外,其它常用的优化方法还有拟牛顿法、共轭梯度法、弹性梯度法、坐标下降法等,考虑易实现性、计算效率、占用存储空间大小,目前选用梯度下降方法及上述几种变化形式仍是机器学习及深度学习优化问题的主流.

最近Adam作者再出大作Lookahead,未完待续。。。

5 参考文献
- An Introduction to Optimization, Fourth Edition.
- Deep Learning,Goodfellow et al.
- Neural Networks and Deep Learning
- On the importance of initialization and momentum in deep learning.
- Neural Networks for Machine Learning Lecture 6d by Geoffrey Hinton et al.
- Adam: A Method for Stochastic Optimization.
- An overview of gradient descent optimization algorithms.
- Incorporating Nesterov Momentum into Adam.
- ADADELTA: An Adaptive Learning Rate Method.
- Hands-On Machine Learning with Scikit-Learn
- Andrew Ng 's machine learning lecture note
- http://speech.ee.ntu.edu.tw/~tlkagk/courses.html