Python 协程asyncio+aiohttp“百万并发”高速爬取英雄联盟皮肤(1385次get请求和图片下载,用时45s)
博客跟新说明:爬取时间已缩短至29.4s----<<<<传送门
一、前言
英雄联盟是一款很火的游戏,像我这种没玩过的都知道疾风剑豪-亚索,我便以此展示结果:

之前写过一篇多线程爬取王者荣耀1080P壁纸的博客----<<<<文章链接
大家都说Python的多线程是鸡肋,因为有了GIL(全局解释锁),导致Python不能正真意义上实现多线程。只有在IO密集型操作里可以使用多线程,比如网络请求,读写文件会产生一些时间空隙,python在这段时间里不工作,多线程就可以利用这个空隙去做其他工作,从而使python一直保持工作。
但是,多线程每个线程都会有自己的缓存数据,每次切换线程的时候非常耗能。
协程不一样,协程的切换只是单纯的操作CPU的上下文,所以每一秒钟切换100万次都不成问题!而且协程还可以主动终断程序去做其它的事情,然后找个时间再反过来继续执行,这样程序员就可以主动控制程序的中断与否。
光说不行,既然协程这么牛,于是我打算实际写一个程序测试一下。有请“受害者”英雄联盟。
二、分析
python版本3.6+
安装异步请求库:pip install aiohttp
(1)相关依赖
from time import perf_counter
from loguru import logger
import requests
import asyncio
import aiohttp
import os
(2)全局变量
# global variable
ROOT_DIR = os.path.dirname(__file__)
os.mkdir(f'{ROOT_DIR}/image')
IMG_DIR = f'{ROOT_DIR}/image'
RIGHT = 0 # counts of right image
ERROR = 0 # counts of error image
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'
}
# target url
hero_url = 'http://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js'
# skin's url, will completed with hero's id.
base_url = 'http://game.gtimg.cn/images/lol/act/img/js/hero/'
(3)获取英雄编号
规律还是要找一段时间的,我是直接看了别人博客的分析,其实都是老套路,这里简单说一下。


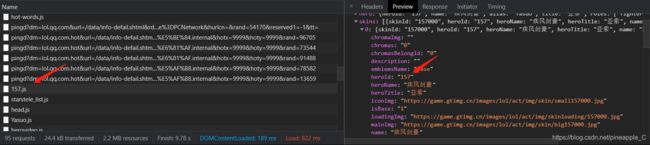
多看几个就能找到规律,第一张图目标url(target_url)是个json格式的数据,里面的heroId是英雄的编号,而很据这个编号正好能拼接
出皮肤url(skin_url),其中的mainImg就是要下载的皮肤的url了。
def get_hero_id(url):
"""
get hero's id, to complete base_url.
:param url: target url
:return: hero's id
"""
response = requests.get(url=url, headers=headers)
info = response.json()
items = info.get('hero')
for item in items:
yield item.get('heroId')
这是一个生成器,获取英雄的编号,然后后面好调用
(4)爬取每个英雄的皮肤信息
async def fetch_hero_url(url):
"""
fetch hero url, to get skin's info
:param url: hero url
:return: None
"""
async with aiohttp.ClientSession() as session:
async with session.get(url=url, headers=headers) as response:
if response.status == 200:
response = await response.json(content_type='application/x-javascript')
# skin's list
skins = response.get('skins')
for skin in skins:
info = {
}
info['hero_name'] = skin.get('heroName') + '_' + skin.get('heroTitle')
info['skin_name'] = skin.get('name')
info['skin_url'] = skin.get('mainImg')
await fetch_skin_url(info)
筛选信息还是老套路。筛选好一个图片的信息后,即刻进入fetch_skin_url()函数,根据此信息对图片进行命名、下载和保存。
(5)下载图片
async def fetch_skin_url(info):
"""
fetch image, save it to jpg.
:param info: skin's info
:return: None
"""
global RIGHT, ERROR
path = f'{IMG_DIR}/{info["hero_name"]}'
make_dir(path)
name = info['skin_name']
url = info['skin_url']
if name.count('/'):
name.replace('/', '//')
elif url == '':
ERROR += 1
logger.error(f'{name} url error {ERROR}')
else:
RIGHT += 1
async with aiohttp.ClientSession() as session:
async with session.get(url=url, headers=headers) as response:
if response.status == 200:
with open(f'{path}/{name}.jpg', 'wb') as file:
chunk = await response.content.read()
logger.success(f'download {name} right {RIGHT}...')
file.write(chunk)
else:
ERROR += 1
logger.error(f'{name},{url} status!=200')
上来的第一件事就是创建目录,因为要进行分类。当然hero_name会有重复的情况,所以在后面的make_dir()里先要检测是否存在此目录
创建好目录后,还要检测这个url是否正确,因为在分析的时候发现:
这个有mainImg
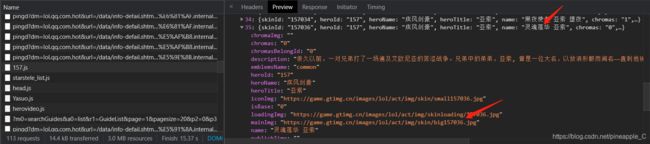 这个没有mainImg
这个没有mainImg

后来经过多次比对发现,有些重复的皮肤名只有原始皮肤版本有url,其他没有,每个英雄都是这样。而且还发现了皮肤名带有“/”的,
这个对给图片命名时很不友善,python会把“/”当作目录分隔符,所以首先将此类的“/”换成“//”再进行下面的判断,对于url是空
的情况就直接输出一个error并记录次数。对于下载成功的则输出success并记录次数。
(6)创建目录
def make_dir(path):
"""
make dir with hero's name
:param path: path
:return: path, skin's dir
"""
if not os.path.exists(path):
os.mkdir(path)
return path
三、完整代码
基于PyCharm、Python3.8、aiohttp3.6.2
# -*- coding: utf-8 -*-
"""
@author :Pineapple
@Blog :https://blog.csdn.net/pineapple_C
@contact :[email protected]
@time :2020/8/13 13:33
@file :lol.py
@desc :fetch lol hero's skins
"""
from time import perf_counter
from loguru import logger
import requests
import asyncio
import aiohttp
import os
start = perf_counter()
# global variable
ROOT_DIR = os.path.dirname(__file__)
os.mkdir(f'{ROOT_DIR}/image')
IMG_DIR = f'{ROOT_DIR}/image'
RIGHT = 0 # counts of right image
ERROR = 0 # counts of error image
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36'
}
# target url
hero_url = 'http://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js'
# skin's url, will completed with hero's id.
base_url = 'http://game.gtimg.cn/images/lol/act/img/js/hero/'
loop = asyncio.get_event_loop()
tasks = []
def get_hero_id(url):
"""
get hero's id, to complete base_url.
:param url: target url
:return: hero's id
"""
response = requests.get(url=url, headers=headers)
info = response.json()
items = info.get('hero')
for item in items:
yield item.get('heroId')
async def fetch_hero_url(url):
"""
fetch hero url, to get skin's info
:param url: hero url
:return: None
"""
async with aiohttp.ClientSession() as session:
async with session.get(url=url, headers=headers) as response:
if response.status == 200:
response = await response.json(content_type='application/x-javascript')
# skin's list
skins = response.get('skins')
for skin in skins:
info = {
}
info['hero_name'] = skin.get('heroName') + '_' + skin.get('heroTitle')
info['skin_name'] = skin.get('name')
info['skin_url'] = skin.get('mainImg')
await fetch_skin_url(info)
async def fetch_skin_url(info):
"""
fetch image, save it to jpg.
:param info: skin's info
:return: None
"""
global RIGHT, ERROR
path = f'{IMG_DIR}/{info["hero_name"]}'
make_dir(path)
name = info['skin_name']
url = info['skin_url']
if name.count('/'):
name.replace('/', '//')
elif url == '':
ERROR += 1
logger.error(f'{name} url error {ERROR}')
else:
RIGHT += 1
async with aiohttp.ClientSession() as session:
async with session.get(url=url, headers=headers) as response:
if response.status == 200:
with open(f'{path}/{name}.jpg', 'wb') as file:
chunk = await response.content.read()
logger.success(f'download {name} right {RIGHT}...')
file.write(chunk)
else:
ERROR += 1
logger.error(f'{name},{url} status!=200')
def make_dir(path):
"""
make dir with hero's name
:param path: path
:return: None
"""
if not os.path.exists(path):
os.mkdir(path)
if __name__ == '__main__':
for hero_id in get_hero_id(hero_url):
url = base_url + str(hero_id) + '.js'
tasks.append(fetch_hero_url(url))
loop.run_until_complete(asyncio.wait(tasks))
logger.info(f'count times {perf_counter() - start}s')
logger.info(f'download RIGHT {RIGHT}, download ERROR {ERROR}')
四、小结
可能有点朋友下好之后发现才285M就花了45s?上次下王者荣耀壁纸的时候下了450M一共57s,那岂不是协程比多线程慢?其实不然,上次是400张壁纸也就是400次get请求,而这次是1385次get请求,你说哪个快?况且这次仅仅是网络请求的异步,写入文件并没有异步操作。
然而这里面有一个致命的问题想必大家也发现了,没用代理。
我在测试的过程中偶尔会出现封IP的情况,于是添加了代理,但是免费代理太不靠谱了,一个代理池中1000个左右的代理也就只有70左右
能用,能用的也不靠谱,由于代理数量的庞大,检测的速度也很慢,这就导致了代理上一秒还行,下一秒就挂了。时不时抛出各种异常,
无奈之下放弃了代理,等改善好代理池之后再做这方面的尝试。
如有错误,欢迎私信留言!
技术永无止境,谢谢支持!
代码修改记录1
line:116:去掉多余的return path ↩︎