Day04:分布式计算存储平台Hadoop
优秀是一种习惯
-
- 知识点01:回顾
- 知识点02:目标
- 知识点03:Zookeeper的存储结构
- 知识点04:Zookeeper的常用命令
- 知识点05:Zookeeper特性:节点类型
- 知识点06:Zookeeper特性:监听机制
- 知识点07:Zookeeper选举:辅助Active Master选举
- 知识点08:Zookeeper选举:内部Leader节点选举
- 知识点09:Zookeeper Java API:环境及连接构建
- 知识点10:Zookeeper Java API:增删改查
- 知识点11:大数据的应用及技术需求
- 知识点12:Hadoop的起源、功能及发展
- 知识点13:Hadoop的核心模块
- 知识点14:HDFS设计
- 知识点15:MapReduce的设计
- 知识点16:YARN的设计
- 知识点17:Hadoop发型厂商与版本
- 知识点18:Hadoop编译
知识点01:回顾
-
什么是Crontab?如何使用Crontab?
-
定时调度的工具:功能只能实现定时调度
-
命令
- crontab -e
-
格式
* * * * * command
-
-
搭建集群环境需要实现哪些步骤?
-
step1:构建多台机器
- 每台机器独立的IP和Hostname
- 配置所有机器的映射关系/etc/hosts
-
step2:构建统一的用户和目录结构
- 大数据机器的用户名和密码都是统一的
- 使用的目录结构:安装目录
-
step3:网络安全配置
- 关闭防火墙或者配置防火墙访问规则
- 关闭selinux
-
step4:免秘钥登陆
- 功能:登陆的时候不需要指定密码
- 实现
- 先生成公私钥
- 将自己的公钥发送给谁,就可以免密登陆谁
-
step5:时钟同步
- 功能:让所有机器的时间保持一致
- 实现:ntp
-
step6:基础软件的部署:JDK
-
-
什么是分布式?分布式能解决什么问题?分布式的设计思想是什么?
- 定义:将多台机器的资源从逻辑上合并为一个整体,对外提供统一的服务
- 功能
- 解决单机资源不足
- 解决单机性能较差
- 设计
- 分而治之
- 分:将一个大的任务拆解成多个小的任务,每台机器完成每个小任务,得到每个小任务的结果
- 合:将所有小任务的结果进行合并,得到最终大任务的结果
-
分布式通过什么样的架构实现分而治之?
-
主从架构
-
主:Master:管理节点
- 管理从节点
- 任务的分配
- 负责接客
- 负责元数据
-
从:Worker:工作节点
- 利用自己所在机器的资源实现任务的处理
-
-
分布式架构中存在哪些问题以及怎么解决?
- 问题1:Master如果只有会存在单点故障问题?
- 解决:启动多个master
- 问题2:多个Master能否一起工作?
- 不能
- 解决:将Master分为两种角色:Active【工作状态】和Standby【备份状态】
- 问题1:Master如果只有会存在单点故障问题?
-
什么是Zookeeper?大数据中什么场景中需要用到Zookeeper?
- 场景1:如果在分布式架构中,多台机器需要共享同一份信息,怎么解决?
- 场景2:两个master如何决定谁是Active谁是Standby?
- |
- 解决:共享外部存储
- |
- Zookeeper
- 本质:是一个外部存储系统,提供读写服务
- 定义:分布式协调服务组件
- 功能:用于解决别的分布式工具存在的问题的
- 辅助选举,存储核心共享元数据信息
- 应用
- 存储核心元数据
- 辅助选举
-
Zookeeper自己本身的架构是什么样的?
- 分布式主从架构
- 主:Leader
- 接受读写请求
- 从:Follower
- 接受读请求,将写的请求转发给Leader
- 如果Leader故障,重新选举一个Follower成为Leader
-
Zookeeper怎么保证自己不出问题?
-
特点:公平节点机制
-
问题1:如果ZK中的一个节点故障,是否有影响?
- 不影响,每台节点存储的内容都是一致的
-
问题2:如何保证每台存储的内容是一致的?
- 只能由Leader负责广播写入请求,超过半数写入成功,就返回成功
-
问题3:如果Leader故障怎么办?
- 允许Follower成为新的Leader
-
所有节点都可以接收客户端请求
-
-
问题
- 解释一下什么叫时间戳?
- 时间戳:时间标记点
- unixtimestamp:以格林威治时间从1970年1月1号的0点0分0秒开始到目前位置的秒数
- Long类型的数值:做时间差值计算

- 时间戳:时间标记点
- 解释一下什么叫时间戳?
知识点02:目标
- Zookeeper的使用
- 存储结构
- 文件系统:树形结构,目录【子节点】、文件【内容】
- 数据库系统:数据库、表、行、列
- 限制?
- 使用
- 怎么通过客户端操作实现对ZK中数据的增删改查
- 特殊机制【重点】
- 节点类型
- 监听机制
- 辅助选举机制
- 内部选举机制
- ZK的Java API
- step1:构建连接:指定连接地址
- step2:调用连接对象方法实现数据的操作
- 存储结构
- Hadoop的入门及介绍
- 大数据在实际生活中的应用场景?
- 大数据开发业务流程和技术有哪些?
- Hadoop的功能和应用场景?
- Hadoop的主要组成模块?
- 什么是HDFS?
- 什么是MapReduce?
- 什么是YARN?
知识点03:Zookeeper的存储结构
-
目标:掌握Zookeeper中的存储结构
- Zookeeper中的数据是如何存储的?
-
路径
- step1:ZK中的存储结构
- step2:节点的设计
-
实施
- ZK中的存储结构
- 结构:树形结构,类似于Linux系统,第一级是/
- 注意:ZK中不区分目录和文件,所有都叫节点
- 节点
- ZK大的范围指的是一台机器
- 在ZK中也代表一个文件或者目录
- 与文件和目录的区别
- 普通文件:能存储内容,但是不能拥有子节点
- 普通目录:可以拥有子节点,不能存储内容
- ZK节点:兼容了目录和文件的特性
- 节点的设计
- 特点1:既可以拥有子节点,也可以存储内容
- 特点2: 不能存储大量数据,每个节点存储的数据内容不能超过1M
- ZK中的存储结构
-
小结
- Zookeeper中的数据是如何存储的?
- 结构:树形结构,第一级节点是/节点
- 特点
- 每个节点既可以有子节点,也可以存储内容,包含了文件和目录共同特性
- 每个节点最多存储不超过1M数据
- 特点
知识点04:Zookeeper的常用命令
-
目标:掌握Zookeeper中的常用命令
- 如何连接Zookeeper的服务端?
- 如何实现Zookeeper中节点的增删改查?
-
路径
- step1:客户端连接ZK服务端
- step2:Zookeeper中的基本命令
-
实施
-
客户端连接ZK服务端
client -server [host1:port1,host2:port2……]bin/zkCli.sh -server node1:2181,node2:2181,node3:2181-
ZK是公平节点,只连接一台就可以使用
-
但是,工作的规范必须给定多台地址,只会连接一台,如果连接失败,会连接其他的机器
-
-
-
Zookeeper中的基本命令
-
帮助:help
[zk: node1:2181,node2:2181,node3:2181(CONNECTED) 0] help ZooKeeper -server host:port cmd args stat path [watch] set path data [version] ls path [watch] delquota [-n|-b] path ls2 path [watch] setAcl path acl setquota -n|-b val path history redo cmdno printwatches on|off delete path [version] sync path listquota path rmr path get path [watch] create [-s] [-e] path data acl addauth scheme auth quit getAcl path close connect host:port [zk: node1:2181,node2:2181,node3:2181(CONNECTED) 1] -
列举:ls path [watch]
-

-
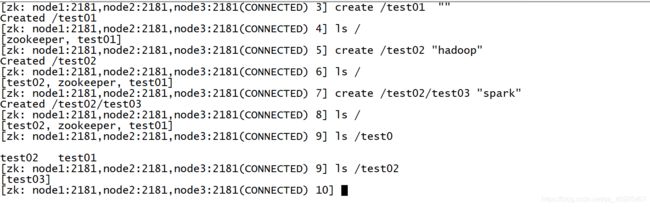
创建:create [-s] [-e] path data
-
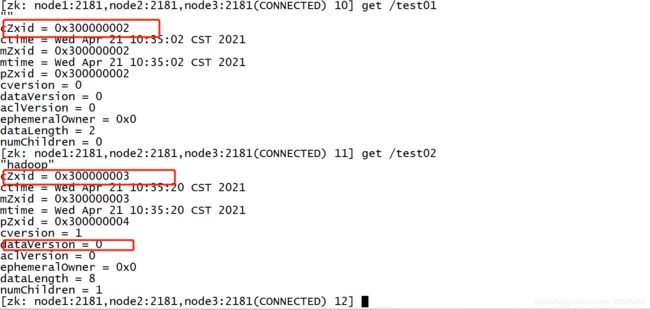
读取:get path [watch]
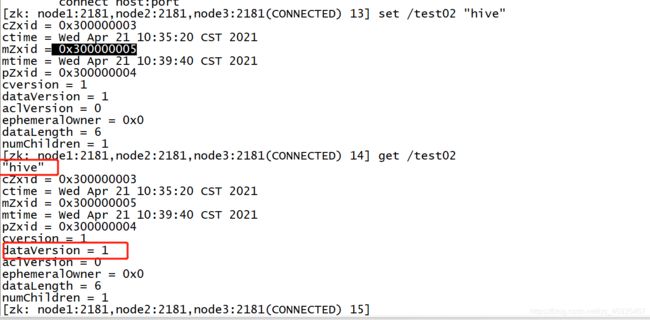
- 修改:set path data [version]
- 删除:rmr path

- 退出:quit

-
小结
-
如何连接Zookeeper的服务端?
- bin/zkCli.sh -server host1:port1,host2:port2……
-
如何实现Zookeeper中节点的增删改查?
- ls path
- create path data
- get path
- set path data
- rmr path
- quit
-
知识点05:Zookeeper特性:节点类型
-
目标:掌握Zk中的节点类型及每种节点的特点
- ZK中有哪几种节点类型?
- 每种节点类型各自有什么特点?
-
路径
- step1:节点类型
- step2:临时节点
- step3:序列节点
-
实施
-
节点类型
create [-s] [-e] path data-
大的分类:永久节点、临时节点【e】、序列节点【s】
-
细的划分
-
永久节点:默认创建的节点都是永久节点
create path data- 普通的节点
- 不手动删除,永远存在
- 不允许创建同名的节点名称的命令
-
永久有序节点
create -s path data- 允许创建同名的名称的命令,自动做编号
-
临时节点
create -e path data- 如果客户端断开,临时节点会自动删除
-
临时有序节点
create -e -s path data- 包含了临时节点和有序节点的特性
- 既做编号也是临时节点
-
-
-
临时节点
- 特点:生命周期随着客户端产生的,如果客户端一旦断开,创建的临时节点将会自动删除

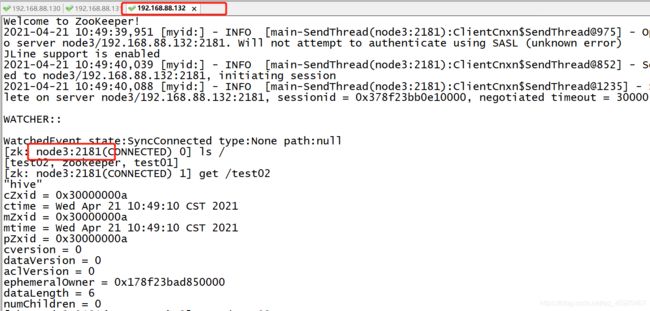
- 特点:生命周期随着客户端产生的,如果客户端一旦断开,创建的临时节点将会自动删除
-

-
序列节点
- 特点:可以执行创建同名的节点,ZK会自动将这些同名的节点进行编号

-
小结
-
ZK中有哪几种节点类型?
-
永久节点:create path data
ephemeralOwner = 0x0-
标记这是个永久节点
-
永久有序节点:create -s path data
-
临时节点:create -e path data
ephemeralOwner = 0x178f23bad850000- 临时节点的标记,是客户端的编号
-
临时有序节点:create -e -s path data
-
-
每种节点类型各自有什么特点?
- 永久节点:永久存在,不允许同名的节点命令的执行
- 临时节点:临时存在,随着客户端断开而自动删除
- 序列节点:允许同名的节点的命令执行,会自动进行编号
-
知识点06:Zookeeper特性:监听机制
-
目标:掌握ZK中的监听机制
- 什么是监听机制?
- 如何设置监听?
-
路径
- step1:监听机制的功能
- step2:监听机制的实现
-
实施
-
监听机制的功能
- 监听:设置监听某个节点,如果这个节点发生变化,可以立即收到这个变化的通知
-
监听机制的实现
-
设置
ls path [watch] get path [watch] -
实现

-
-
-
小结
- 什么是监听机制?
- 用于设置监听一个节点的变化:删除、修改、子节点的改变
- 什么是监听机制?
-
如何设置监听?
- ls path watch
- get path watch
知识点07:Zookeeper选举:辅助Active Master选举
-
目标:了解ZK实现Active Master选举的过程
- 两个Master如何利用ZK实现Active Master选举以及切换?
-
路径
- Active Master选举的两种方式
-
实施
- 所有辅助选举、元数据存储都在分布式工具中封装好了,不用我们干预
- 方式一:临时节点【普遍最常见的方式】
- 需求:MasterA和MasterB,都启动了,但无法选举谁是Active的?
- 实现
- step1:让A和B到ZK中创建同一个临时节点file
- step2:谁创建成功,谁就是Active,A创建成功了,A就是Active的Master
- B创建失败,B就是Standby的Master
- 问题:A故障了,B要变成Active,B如何知道A故障了?
- 由于A创建的是临时节点,如果A故障,这个临时节点会自动被删除
- 可以让B监听这个临时节点,如果这个临时节点消失,B会收到监听
- B就会创建这个临时节点,B成为新的Active
- A重启以后,A发现该节点已存在,说明当前有一个Active,自己只能是Stanby,并且设置监听
- 方式二:临时有序节点
- 需求:MasterA和MasterB,都启动了,但无法选举谁是Active的?
- 实现
- step1:让A和B到ZK中创建同一个临时有序节点file
- step2:谁的编号最小,谁就是Active,A的编号最小就是Active的Master
- B就是Standby的Master
- 问题:A故障了,B要变成Active,B如何知道A故障了?
- 由于A创建的是临时节点,如果A故障,这个临时节点会自动被删除
- 可以让B监听这个临时节点,如果这个临时节点消失,B会收到监听
- B就会创建这个临时节点,B成为新的Active
- A重启以后,A发现该节点已存在,说明当前有一个Active,自己只能是Stanby,并且设置监听
-
小结
- 两个Master如何利用ZK实现Active Master选举以及切换?
- 临时节点:选举
- 监听机制:切换
知识点08:Zookeeper选举:内部Leader节点选举
-
目标:了解ZK中的leader的选举过程
- 如何决定哪个ZK节点是Leader节点的?
-
路径
- step1:Leader的选举规则
- step2:Leader选举过程
-
实施
-
Leader的选举规则
- zxid:数据id
- 用于标记数据的更新状态,zxid,代表数据是越新的数据
- myid:权重id,节点标识id
- 每台zk都有一个唯一标识的id,也作为选举时权重的id
- 规则:先比较zxid,谁大谁就是leader,如果相同,比较myid,谁大并且超过半数谁就是leader
- zxid:数据id
-
Leader选举过程
-
集群第一次启动
- zk1
- zxid:0
- myid:1
- zk2
- zxid:0
- myid:2
- zk3
- zxid:0
- myid:3
- 由于zxid一致,比较myid
- 先启动第一台:投自己一票
- node1[1,1票]
- 然后启动第二台:投自己一票
- node1[1,1票]
- node2[2,1票]
- ||
- node2【2,2票】
- zk1
-
故障恢复启动:如果leader故障了怎么办?
-
node1:follower
1 2 3 4 5 -
node2:leader
1 2 3 4 5 -
node3:follower
1 2 3 4 -
刚写入5,超过半数,leader故障
-
重新选举:先比价zxid
- node1直接成为新的leader
- 原因:保证数据的安全和一致性
-
-
-
ZK的节点个数必须为奇数,不能为偶数?
- 这个说法是错误的:可以为偶数,但一般用奇数台
- 奇数台和偶数台机器的容错率是一样的,避免资源的浪费,一般使用奇数台机器,5台
- 6台:允许2台
- 5台:允许2台
-
-
小结
- 如何决定哪个ZK节点是Leader节点的?
- 规则:先比较zxid,如果相同再比较myid
- 如何决定哪个ZK节点是Leader节点的?
知识点09:Zookeeper Java API:环境及连接构建
-
目标:了解ZK的JavaAPI的开发环境搭建及连接构建
- 如何通过JavaAPI操作ZK?
-
路径
- step1:配置依赖
- step2:构建连接
-
实施
-
配置依赖

- 每天一个模块,每天的模块有独立的pom依赖
- 项目的pom文件中不要放任何东西
-
构建连接
/** * @ClassName ZKClientTest * @Description TODO 测试ZK的Java API * @Date 2021/4/21 11:52 * @Create By Frank */ public class ZKClientTest { //定义一个客户端连接对象 CuratorFramework client = null; //构建连接 @Before public void getConnection(){ //构建重试机制 RetryPolicy retry = new ExponentialBackoffRetry(5000,3); //构建连接客户端 client = CuratorFrameworkFactory.newClient("",retry); } //释放连接 @After public void closeConnect(){ client.close(); } }
-
-
小结
- 如何构建连接?
- CuratorFrameworkFactory.newClient(服务端地址,重试机制)
知识点10:Zookeeper Java API:增删改查
-
目标:通过Java API实现节点的增删改查
-
路径
- step1:创建节点
- step2:查询节点
- step3:修改节点
- step4:删除节点
-
实施
-
创建节点
@Test public void createNode() throws Exception { //启动 client.start(); //创建节点 // client.create().creatingParentsIfNeeded().withMode(CreateMode.PERSISTENT).forPath("/bigdata01","spark".getBytes()); client.create().creatingParentsIfNeeded().withMode(CreateMode.EPHEMERAL).forPath("/bigdata02","spark".getBytes()); Thread.sleep(10000); } -
查询节点
@Test public void getNode() throws Exception { //启动 client.start(); //查询节点 byte[] bytes = client.getData().forPath("/bigdata01"); System.out.println(new String(bytes)); } -
修改节点
@Test public void setNode() throws Exception { //启动 client.start(); //修改节点 client.setData().forPath("/bigdata01","oozie".getBytes()); } -
删除节点
@Test public void rmNode() throws Exception { //启动 client.start(); //删除 client.delete().forPath("/bigdata01"); }
-
-
小结
- 了解对应的类和方法即可
知识点11:大数据的应用及技术需求
-
目标:了解大数据的应用及技术需求
- 什么是大数据?
- 大数据的应用有哪些?
- 大数据需要用到哪些技术?
-
路径
- step1:大数据的本质
- step2:大数据的应用
- step3:大数据业务流程及技术
-
实施
-
大数据的本质
- 本质:实现对海量数据的处理
- 理解:通过大数据软件工具开发数据处理的程序对海量的数据进行处理,从数据中挖掘价值
- 公司希望通过大数据技术来提升公司的收益:ROI
-
大数据的应用
- 数据分析:运营分析、营销分析
- 数据:广告投放的用户点击行为数据
- 处理:统计分析
- 效果:点击量、点击率、购买率 => 衡量广告投放的效果
- 百度:100万
- 100万用户访问
- 10万用户点击
- 1万购买 =》 10万
- 搜狗:100万
- 50万用户访问
- 10万用户点击
- 2万购买 =》 20万
- 抖音:100万
- 1000万访问
- 100万用户点击
- 10万 => 200万
- 百度:100万
- 推荐系统:精准化的营销
- 推广点:传统的营销通过推送广告的方式,点击率非常低
- 推广
- 打广告:新用户送现金优惠券
- 注册:首单转化
- 电商
- 淘宝:稳定,全,价格中等
- 京东:高端服务:物流和售后
- 拼多多:低价
- 推广
- 解决:精准推荐,推荐你想要的东西
- 提供更好的服务,留住更多的用户
- 推广点:传统的营销通过推送广告的方式,点击率非常低
- 风控系统:金融行业,征信评估
- 后台对用户数据做了大数据风控评估
- 交通领域:天网系统、滴滴实现过程
- 数据分析:运营分析、营销分析
-
大数据业务流程及技术
-
数据生成:业务系统自动生成
-
数据采集:将所有需要处理的数据统一采集到大数据平台
- Flume、Sqoop、Logstash、Canal、Beats
-
数据存储:将整个公司所有需要处理的数据统一化存储
- HDFS、Hbase、Kafka、ES、Redis
-
数据处理:根据实际的应用需求对数据进行处理转换
- MapReduce、Impala、Flink、Spark、Kylin、Druid
-
数据应用:根据需求实现对应数据的应用
-
-
-
小结
- 什么是大数据?
- 本质:利用大数据软件工具对海量数据进行处理
- 大数据的应用有哪些?
- 数据分析
- 推荐系统
- 风控系统
- ……
- 大数据需要用到哪些技术?
- 数据采集
- 数据存储:分布式存储:解决大数据存储的问题
- 数据计算:分布式计算:解决大数据计算的问题
- 什么是大数据?
知识点12:Hadoop的起源、功能及发展
-
目标:了解Hadoop的起源、功能及发展
- 什么是Hadoop?
- 大数据中什么情况下需要使用Hadoop?
-
路径
- step1:Hadoop的起源
- step2:Hadoop的功能
- step3:Hadoop的发展
-
实施
- Hadoop的起源
- 源自于Google,发布了三篇
- GFS:Google FileSystem
- 分布式文件系统,用于解决Google数据存储问题
- Hadoop创始人通过自己开发实现了这篇论文:NDFS
- MapReduce:分布式计算框架
- Hadoop创始人自己实现了MapReduce
- 后来将NDFS和MapReduce合并成一个工具:Hadoop = HDFS + MapReduce
- GFS:Google FileSystem
- 源自于Google,发布了三篇
- Hadoop的功能
- 分布式存储:HDFS
- 分布式计算:MapReduce
- Hadoop的发展
- 大数据最早的分布式计算和分布式存储的工具
- Hadoop2.x版本是目前应用最多的版本
- Hadoop3.x是目前最新的版本
- 从Hadoop2开始:包含3个组件
- HDFS
- MapReduce:目前逐渐被淘汰,性能相对较差
- 数据的时效性决定了数据的价值
- 数据在刚产生的时候,价值是最大
- YARN
- 目前在工作中主要使用Hadoop中的HDFS和YARN
- Hadoop的起源
-
小结
- 什么是Hadoop?
- Hadoop是一个分布式存储以及计算的平台
- 什么是Hadoop?
-
大数据中什么情况下需要使用Hadoop?
- HDFS和YARN
知识点13:Hadoop的核心模块
-
目标:掌握Hadoop中的核心模块
- Hadoop中有哪些模块及每个模块的功能是什么?
-
路径
- step1:核心模块
- step2:HDFS
- step3:MapReduce
- step4:YARN
-
实施
-
hadoop.apache.org
-
核心模块
-
Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing.
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
Modules
The project includes these modules:
Hadoop Common: The common utilities that support the other Hadoop modules.
#通用模块,用于集成其他所有模块
Hadoop Distributed File System (HDFS™): A distributed file system that provides high-throughput access to application data.
#分布式文件系统
Hadoop YARN: A framework for job scheduling and cluster resource management.
#分布式任务调度和资源管理平台
Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
#分布式编程模型
-
HDFS:分布式文件系统
- 存储文件
- 分布式
- 解决大数据存储问题
-
MapReduce:分布式编程模型
- 理解为一套分布式编程的规则或者API
- 用MapReduce的API写出来的代码,就是一个分布式的程序
-
YARN:分布式任务调度和资源管理平台
- 分布式计算 = 分布式程序【规则,怎么做】 + 分布式资源平台【具体实现的】
-
小结
- Hadoop中有哪些模块及每个模块的功能是什么?
- HDFS:分布式文件系统,解决大数据存储问题
- MapReduce:分布式编程模型,一套分布式的API
- YARN:分布式任务调度和资源管理平台,实现程序的运行的平台
知识点14:HDFS设计
-
目标:掌握Hadoop中HDFS的功能及设计
- 什么是HDFS?
- HDFS是如何实现分布式存储的?
-
路径
-
step1:HDFS的定义
-
step2:HDFS的本质
-
step3:HDFS的架构
-
-
实施
-
HDFS的定义
- 定义:分布式文件系统
- 文件系统:存储的是文件,对外提供文件的读写
- 分布式:将多台机器的硬盘资源从逻辑上合并为一个整体,对外提供统一的存储服务
- 分:写:将大文件拆分成多个部分【块】,每个部分存储在不同的集群节点上
- 合:读:将这个文件的每个部分从每台节点上读取合并返回给用户
-
HDFS的本质
- 本质:逻辑的文件系统
- 将多台Linux机器的文件系统从逻辑上合并了,变成了一个逻辑的文件系统
-
HDFS的架构
- 分布式主从架构
- 主:NameNode:管理节点
- 管理DataNode:死活
- 接受请求
- 管理元数据
- 从:DataNode:存储节点
- 实现数据块的存储
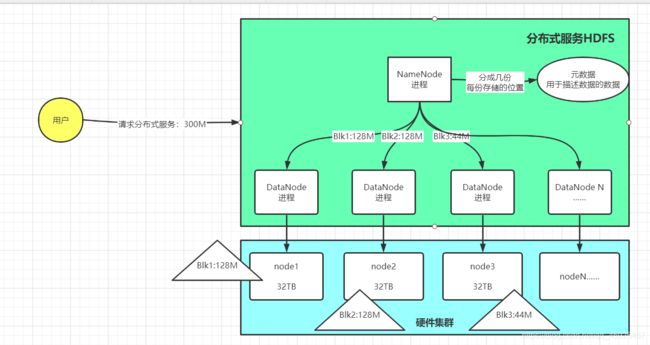
-
-
小结
- 什么是HDFS?
- 分布式文件系统
- 本质:将多台Linux机器的文件系统进行逻辑上的合并,变成一个逻辑的文件系统,数据最终还是存储在Linux
- HDFS是如何实现分布式存储的?
- 分:写入时将文件划分为多个Block,不同的Block分布式存储在多台机器上
- 合:读取时将文件所有Block进行合并
- 什么是HDFS?
知识点15:MapReduce的设计
-
目标:掌握Hadoop中MapReduce的功能及设计
- 什么是MapReduce?
-
路径
- step1:MapReduce的功能
- step2:MapReduce的实现过程
-
实施
- MapReduce的功能
- 一套分布式编程的API
- 快速的帮助我们构建一个分布式的程序
- 举个例子:
- 需求:想实现1 加到 9 ,有三台机器,必须将1 + …… 9这个程序划分为3个小程序
- 实现:1 + 2 + 3 + 4 + 5 + 6 + 7 + 8 +9
- step1:将要处理的数据划分成3个分片
- split1:1 2 3
- split2:4 5 6
- split3:7 8 9
- step2:为每个分片启动一个进程来处理
- MapTask1:1 + 2 + 3 = 6
- MapTask2:4+5+6 = 15
- MapTask3:7+8+9 = 24
- step3:将每个小任务的结果进行合并
- ReduceTask:6 + 15 + 24 = 45
- step4:返回给用户
- step1:将要处理的数据划分成3个分片
- MapReduce的实现过程
- Input:读取数据,将数据划分为多个分片Split
- Map:对每个分片启动一个MapTask进程来实现处理
- Reduce:对所有MapTask结果进行合并
- Output:输出保存结果
- MapReduce的功能
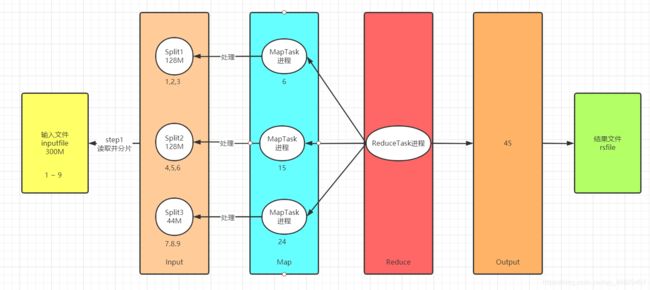
-
小结
- 什么是MapReduce?
- 一套分布式编程API
- 基于这个套API开发的程序就是分布式程序
知识点16:YARN的设计
-
目标:掌握Hadoop中YARN的功能及设计
- 什么是YARN?
-
路径
- step1:分布式计算的构成
- step2:YARN的功能
- step3:YARN的设计
-
实施
-
分布式计算的构成
- 程序:分布式程序
- MapReduce可以构建分布式程序
- 运行:分布式运行
- YARN负责分布式运行的实现
- 程序:分布式程序
-
YARN的功能
- 定义:分布式任务调度和资源管理平台
- 本质:将多台机器的CPU和内存从逻辑上合并为一个整体,对外提供程序运行资源服务
- 资源容器
-
YARN的设计
- 分布式主从架构
- 主:ResourceManager:管理节点
- 管理所有NodeManager
- 负责任务的分配:任务调度和资源管理
- 从:NodeManager:计算节点
- 利用自己所在机器的CPU和内存运行Task进程

-
-
小结
- 什么是YARN?
- 分布式资源管理和任务调度平台:资源容器
知识点17:Hadoop发型厂商与版本
-
目标:了解Hadoop的发型厂商与版本
- Hadoop的不同发型厂商与版本有什么区别?
-
路径
- step1:发行厂商
- step2:版本
-
实施
- 发行厂商
- Apache版本的Hadoop
- 优点:拥有最新的功能、版本
- 缺点:Bug最新
- 大数据平台的各个软件要考虑彼此的兼容性
- Cloudera:CDH
- 基于Apache的版本做了修复并且封装了自己的东西
- 优点:修复了Apache版本中出现的已知的Bug,最稳定
- 不用考虑各种软件版本的兼容性
- 集成集群管理可视化工具来部署
- 缺点:功能更新会比较慢
- 一般选择CDH版本
- Apache版本的Hadoop
- 版本
- Hadoop0.x和1.x:最早的版本,现在不会有了
- HDFS
- MapReduce v1:分布式计算平台
- Hadoop2.x:目前使用最多的版本
- HDFS
- MapReduce v2
- YARN
- Hadoop3.x:目前最新的版本
- 对底层的计算架构做了优化
- Hadoop0.x和1.x:最早的版本,现在不会有了
- 发行厂商
-
小结
- Hadoop的不同发型厂商与版本有什么区别?
知识点18:Hadoop编译
-
目标:了解Hadoop的编译需求
- 为什么要编译Hadoop?
- 怎么编译Hadoop?
-
路径
- step1:编译的需求
- step2:编译的步骤
-
实施
- 编译的需求
- 官方提供了Hadoop的源码,以及编译好的Hadoop
- 需要自己编译的情况
- 情况一:官方的编译环境与自己的编译环境不一致
- 一般是依赖版本不一致
- 情况二:官方编译的功能有缺失
- 例如官方编译的Hadoop中没有Snappy压缩的支持
- 情况一:官方的编译环境与自己的编译环境不一致
- 编译的步骤
- step1:下载源码
- step2:安装编译器:Maven
- step3:修改源码中的依赖版本
- step4:mvn实现编译
- 编译的需求
-
小结
- 为什么要编译Hadoop?
- 情况一:官方的编译环境与自己的编译环境不一致
- 一般是依赖版本不一致
- 情况二:官方编译的功能有缺失
- 例如官方编译的Hadoop中没有Snappy压缩的支持
- 怎么编译Hadoop?
- step1:下载源码
- step2:安装编译器:Maven
- step3:修改源码中的依赖版本
- step4:mvn实现编译