【Spark】Apache日志分析
文章目录
- Apache日志分析
-
- 一、日志格式
- 二、日志解析
-
- 1.主要步骤
- 2.数据清洗代码实现解析
-
- 2.1 环境准备
- 2.2 数据清洗解析
-
- 2.3.1 整体框架
- 2.3.2 解析数据
- 三、日志分析
-
- 1.统计Web服务器返回的内容大小
- 2.统计不同的状态代码出现的次数
- 3.查看频繁访问的客户端主机(访问大于10次)
- 4.查看被访问最多(前10)的资源标识符
- 5.查询状态码不是200中访问次数最多的资源标识符(前10)
- 6.统计独立主机数
Apache日志分析
一、日志格式
这里用到的服务器日志格式是 Apache Common Log Format (CLF)。
简单数来,你看到的每一行都是如下的样式:
127.0.0.12 - - [01/Dec/1995:00:00:01 -0400] "POST /images/launch-logo.gif12 HTTP/1.0" 200 1850
字段说明如下:
-
127.0.0.12
第一项 ,发起请求的客户端IP地址。
-
-
第二项 ,空白,用占位符“
-”替代,表示所请求的信息(来自远程机器的用户身份)。
-
-
第三项,空白,表示所请求的信息(来自本地登录的用户身份)。
-
[01/Aug/1995:00:00:01 -0400]
第四项,服务器端处理完请求的时间,具体细节如下:-
[day/month/year:hour:minute:second timezone]
day = 2 digits
month = 3 letters
year = 4 digits
hour = 2 digits
minute = 2 digits
second = 2 digits
zone = (+ | -) 4 digits
-
-
"POST /images/launch-logo.gif12 HTTP/1.0"
第五项,客户端请求字符串的第一行,包含3个部分。- 1)请求方式 (e.g., GET, POST,HEAD 等)
- 2)资源;
- 3)客户端协议版本,通常是HTTP,后面再加上版本号。
-
200
第六项,服务器发回给客户端的状态码,这个信息非常有用,它告诉我们这个请求成功得到response(以2开头的状态码),重定向(以3开头的状态码),客户端引起的错误(以4开头的状态码),服务器引起的错误(以5开头的状态码)。
-
1850
第七项,这个数据表明了服务器返回的数据大小(不包括response headers),当然,如果没有返回任何内容,这个值会是”-” (也有时候会是0)。
返回顶部
二、日志解析
1.主要步骤
1.通过观察数据的格式,可以发现一行的数据是按照空格进行分隔的,并且在时间、客户请求两个字段中均包含有空格分隔符,所以我们就不能够单纯的以空格为分隔符进行拆分。
2.对于数据第七项服务器返回的数据大小中出现的“-”,我们可以全用0替代
3.对于时间字段,我们需要进行调整。主要是两步:更换月份信息、调整时间格式
4.对于客户请求字段,我们需要进一步进行拆分,将其分为请求、站点、协议三个字段
返回顶部
2.数据清洗代码实现解析
2.1 环境准备
-
这里我们首先配置好
SparkContext和SparkSession,以及导入隐式转换和SparkSQL的函数集。 -
隐式转换就是:当Scala编译器进行类型匹配时,如果找不到合适的候选,那么隐式转化提供了另外一种途径来告诉编译器如何将当前的类型转换成预期类型。
- 这里主要用途就是将
scala的Row对象转为DataFrame[]类型的数据。
- 这里主要用途就是将
-
org.apache.spark.sql.functions是一个Object,提供了约两百多个函数。除UDF函数,均可在spark-sql中直接使用。经过
import org.apache.spark.sql.functions._,也可以用于Dataframe,Dataset。
package Spark网络日志分析
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types.IntegerType
import org.apache.spark.{
SparkConf, SparkContext}
object Log {
// 统计处理数据
var count_valid = 0 // 合规
var count_invalid = 0 // 不合规
def main(args: Array[String]): Unit = {
// sc
val conf = new SparkConf()
.setAppName("log_analysis")
.setMaster("local[6]")
val sc = new SparkContext(conf)
// spark
val spark = SparkSession.builder()
.master("local[6]")
.appName("log")
.getOrCreate()
// 导入隐式转换
import spark.implicits._
import org.apache.spark.sql.functions._
}
返回顶部
2.2 数据清洗解析
2.3.1 整体框架
整体的处理分为:读取数据、解析数据、输出数据三大部分
-
读取数据:利用
sparkContext的textFile()方法将数据文本获取为RDD[Row]类型 -
解析数据:针对
RDD[Row]类型处理,每次处理的是RDD中的单个Row对象数据,也就是原数据集中的每一行封装成了Row对象;解析式利用map()进行逐行清洗。 -
输出数据:处理好的数据最终依然为
RDD(Row)类型,我们利用隐式转换和toDF()方法将其转为DataFrame类型(表结构),并指定表头字段,通过csv()方法最终将结果以.csv的文件存储。
// 正则表达式解析日志
// 匹配规则:“ ” 中的空格不拆分
val LOG_PATTERN = " (?=(?:[^\"]*\"[^\"]*\")*[^\"]*$)"
// 1.读取数据
val data = sc.textFile("src/main/scala/Spark网络日志分析/data/access_2015_03_30.log")
// 2.处理数据
val clean = data
.map {
item =>
// 2.1 内部处理单条数据
}
clean.foreach(println(_))
println(count_valid + "+" + count_invalid1 + "+" + count_invalid2 + "=" + (count_valid + count_invalid1 + count_invalid2))
// 转为DataFrame
val df_data = clean.toDF("host", "client_id", "user_id", "date_time", "method", "endpoint", "protocol", "response_code", "size")
df_data.show()
// 3.输出
// df.coalesce(1) // 设置分区为1
// .write.mode("overwrite")
// .option("header", "true")
// .csv("G:\\Projects\\IdeaProjects\\Spark_Competition\\src\\main\\scala\\Spark网络日志分析\\data\\test01")
// 自定义日期转换函数
def parseDate(str: String): String = {
// 转换日期格式
}
返回顶部
2.3.2 解析数据
- 在处理过程中,处理方式首先是将数据中的 “-“ 进行 0 替换,然后对 [] 进行 ” “ 替换,这样的替换主要是利用之前的正则(保留” “中的分割符不被拆分)
- 在处理时间数据的时候,定义了一个方法,对原有数据进行拆分,依次截取时间分段数据;其中利用Map对月份数据进行了替换。最后整合以字符串的方式返回。后续如果用到可以使用SparkSQL进行实时转换。
- 接着针对客户请求数据进行拆分
利用map函数进行整体数据的清洗处理:
-
首先定义变量
line获取到单行数据(也就是data.item),格式:127.0.0.1 - - [01/Aug/1995:00:00:01 -0400] “GET /images/launch-logo.gif HTTP/1.0” 200 1839 -
初步进行字符替换
[ ]转换为“ ”,格式:127.0.0.1 - - “01/Aug/1995:00:00:01 -0400” “GET /images/launch-logo.gif HTTP/1.0” 200 1839 -
然后利用正则匹配拆分是以空格拆分并且保留
“ ”中的空格,格式:0:127.0.0.1
1:-
2:-
3:“01/Aug/1995:00:00:01 -0400”
4:“GET /images/launch-logo.gif HTTP/1.0”
5:200
6:1839
-
处理
“01/Aug/1995:00:00:01 -0400”部分的数据,利用substring截取引号中的数据 :01/Aug/1995:00:00:01 -0400 -
通过自定义方法,进行日期格式的转换;主要就是利用字符截取拼接,其中月份需要进行匹配转换, 最终转换为:1995-01-08 00:00:01 进行返回
-
接着同样提取 POST /images/launch-logo.gif HTTP/1.0 进行拆分提取字段,这里要进行判断,原始数据中这一部分会有脏数据的出现,提取后针对
protocol进一步处理,将“-”换成“0” -
最后返回
(line(0), line(1), line(2), date, method, endpoint, protocol, line(5), line(6))分别对应("host", "client_id", "user_id", "date_time", "method", "endpoint", "protocol", "response_code", "size") -
有注意到,开头定义了两个变量
count_valid、count_invalid用来计数,分别统计合规数据与非法数据,非法数据处理直接返回(line(0), line(1), line(2), date, "null", "null", "null", line(5), line(6))
// 处理数据
val clean = data
.map {
item =>
// 127.0.0.1 - - [01/Aug/1995:00:00:01 -0400] "GET /images/launch-logo.gif HTTP/1.0" 200 1839
// 1.获取单条记录数据
val line = item
// 2.字段初步拆分
.replace("[", "\"").replace("]", "\"")
.split(LOG_PATTERN, -1)
// 3.转换时间数据
line(3) = line(3).substring(1, line(3).length - 1)
val date = parseDate(line(3))
// 4.字段细分 --- 请求、资源、协议
// 提取字段 POST /images/launch-logo.gif HTTP/1.0
line(4) = line(4).substring(1, line(4).length - 1)
// 以空格拆分字段
val fields = line(4).split(" ")
// GET /images/launch-logo.gif HTTP/1.0
// 判断fields的大小
if (fields.length == 3) {
count_valid += 1
val method = fields(0) // GET
val endpoint = fields(1) // /images/launch-logo.gif
val protocol = fields(2) // HTTP/1.0
// 转换数据 - => 0
if("-".equals(line(6))){
line(6) = "0"
}
// 4.返回结果
(line(0), line(1), line(2), date, method, endpoint, protocol, line(5), line(6))
} else {
count_invalid1 += 1
(line(0), line(1), line(2), date, "null", "null", "null", line(5), line(6))
}
}
// 自定义日期转换函数
def parseDate(str: String): String = {
// 1.定义map匹配月份
val month_map = Map("Jan" -> "01", "Feb" -> "02", "Mar" -> "03", "Apr" -> "04", "May" -> "05", "Jun" -> "06","Jul" -> "07", "Aug" -> "08", "Sep" -> "09", "Oct" -> "10", "Nov" -> "11", "Dec" -> "12")
// 01/Feb/1995:00:00:01 -0400
val timePart = str.split(" ")(0) // 01/Feb/1995:00:00:01
// 截取年份
val year = timePart.substring(7, 11)
// 截取月份
val month = month_map.get(timePart.substring(3, 6)).getOrElse()
// 截取日
val day = timePart.substring(0, 2)
// 截取时
val hour = timePart.substring(12, 14)
// 截取分
val minutes = timePart.substring(15, 17)
// 截取秒
val second = timePart.substring(18, 20)
val date_str = year + "-" + month + "-" + day + " " + hour + ":" + minutes + ":" + second
// 返回结果
date_str
}

toDF()转换处理后的数据成DataFrame类型(表结构),同时指定对应字段名称:
val df_data = clean.toDF("host", "client_id", "user_id", "date_time", "method", "endpoint", "protocol", "response_code", "size")
df_data.show()

这里我们去除非法数据集,保留有效数据:
// 非法数据
df_data.select('*)
.where('method === "null")
.where('endpoint === "null")
.where('protocol === "null")
.show()
// 提出不为null的
val df = df_data.select('*)
.where('protocol =!= "null")
注意以下特殊的不合规记录:


返回顶部
三、日志分析
接下来通过以上处理的数据进行进一步分析,主要采用SparkSQL的方式~
1.统计Web服务器返回的内容大小
// 1.统计Web服务器返回的内容大小,即字段 size ,并计算其平均值、最小值和最大值。
/*方法一 RDD*/
// 首先调用变换函数 map() 并传入一个只取出字段 size 的匿名函数创建一个新的RDD。
// 再调用动作函数 reduce() 和 count() 求出内容大小的总和以及个数,其比值即内容大小的平均值。
// 最后调用动作函数 min() 和 max() 得到内容大小的最小值和最大值。
/*方法二 SparkSQL*/
val test01 = df.select('size cast(IntegerType))
.agg(max('size),min('size),avg('size))
test01.show()
查询size列信息,通过cast()进行类型转换后使用聚合函数agg()进行max()、min()、avg()的聚合操作。

返回顶部
2.统计不同的状态代码出现的次数
// 2.统计不同的状态代码出现的次数。
/*方法一*/
// 与上一步类似,首先调用变换函数 map() 取出字段 response_code ,不同的是,这里取出的是一个二元列表,即字段 response_code 和1,使得之后能够计数。
// 再调用变换函数 reduceByKey() 按照不同的状态代码统计出现次数,并调用函数 cache() 在内存中缓存。
// 最后调用动作函数 take() 输出成列表。
/*方法二*/
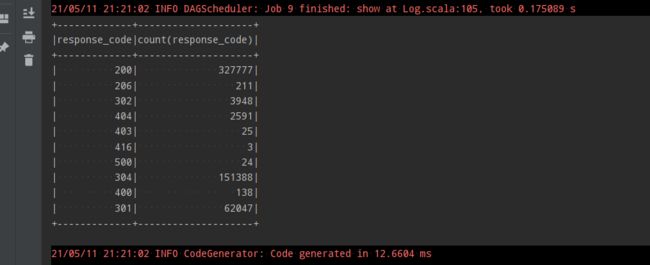
val test02 = df.select('response_code)
.groupBy('response_code)
.agg(count('response_code))
test02.show()
查询response_code列,按照response_code分组聚合,count()求出每组的数量,不同的组别对应的就是不同的response_code。
返回顶部
3.查看频繁访问的客户端主机(访问大于10次)
// 查看频繁访问(大于10次)的客户端主机。
/*方式一*/
// 与上一步类似,首先调用变换函数 map() 取出包含字段 host 和1的二元列表。再调用变换函数 reduceByKey() 按照不同的主机地址统计出现次数。
// 然后调用变换函数 filter() 取出出现次数大于10的主机地址。
// 最后调用动作函数 take() 输出成列表。
/*方式二*/
val test03 = df.select('host)
.groupBy('host)
.agg(count('host) as "count")
.orderBy('count desc)
.where('count > 10)
test03.show()
查询host列信息,并进行groupBy分组agg(count())聚合,求得每组(每个host)的频数,然后进行orderBy排序,查出where条件频数大于10的记录。
返回顶部
4.查看被访问最多(前10)的资源标识符
// 查看被访问最多的资源标识符。
/*方式一*/
//与上一步类似,首先调用变换函数 map() 取出包含字段 endpoint 和1的二元组。
// 再调用变换函数 reduceByKey() 按照不同的资源标识符统计出现次数。
// 最后调用动作函数 takeOrdered() 取出前10被访问最多的资源标识符。
/*方式二*/
val test04 = df.select('endpoint)
.groupBy('endpoint)
.agg(count('endpoint) as "count")
.orderBy('count desc)
.limit(10)
test04.show()
查询endpoint列信息,分组聚合后降序排序,limit取出前10。

返回顶部
5.查询状态码不是200中访问次数最多的资源标识符(前10)
/*方式一*/
// 查看前10个出现错误(即状态代码不是 200 )最多的资源标识符(即字段 endpoint ),最终的返回结果是按访问次数倒序排列的前10个标识符及其相应的访问次数。
/*方式二*/
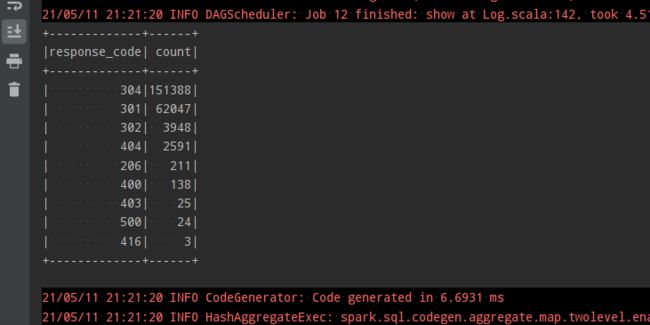
val test05 = df.select('response_code cast(IntegerType),'endpoint)
.where('response_code !== 200)
.groupBy('endpoint)
.agg(count('response_code) as "count" )
.orderBy('count desc)
.limit(10)
test05.show()
查询response_code、endpoint列信息,查询response_code不为200的记录,按照endpoint分组聚合计数,再按照count倒序排序,limit取出前10。
返回顶部
6.统计独立主机数
/*方式一*/
// 统计独立主机数 统计独立主机地址(字段 host)数。
/*方式二*/
val test06 = df.dropDuplicates(Seq("host"))
.count()
println("独立主机数:"+test06)
针对host列进行去重计数,可以直接使用 DataFrame.dropDuplicates() 方法。

返回顶部
参考1:Spark大数据分析实验(三)—— Spark网络日志分析
参考2:Apache Web服务器日志格式