数据集
约瑟夫海勒捕捉22是我最喜欢的小说。我最近读完了 ,并喜欢整本书中语言的创造性使用和荒谬人物的互动。对于我的可视化类,选择文本作为我的最终项目“数据集”是一个简单的选择。该文有大约175,000个单词,分为42章。我在网上找到了这本书的原始文本版本并开始工作。
我使用正则表达式和简单字符串匹配的组合在Python中解析文本。我可以在这里查看我构建的iPython Notebook的代码
该脚本首先从每一章中提取文本,转换为小写和标点符号。然后我循环查看出现超过50次的主要角色列表,并寻找他们的名字。我将他们出现的“时间”定义为章节的百分位数,即。发生在第三章第10个百分点的字符将存储为3.10。该数据集构成了“角色外观”和“角色共同发生”图的基础。
使用类似的过程来提取书中提到的各种地中海位置的出现。我找到了一个粉丝网站,其中列出了所有位置,并在文本中搜索了这些名称。一旦确定,城市就使用geopyPython中的包进行地理编码。该数据集用于“地中海旅行”可视化。
最后的数据集是通过扫描章节提到的约塞连创建的。然后收集这些提及的两侧的25个单词的窗口,并标记它们出现的章节位置。nltkPython中的包用于清除停用词的单词列表,然后对其余部分进行词性标注。该数据集构成了“特征词”可视化的基础。
我shiny在R中以交互方式可视化这些数据集。您可以在我的GitHub存储库中找到代码。在可能的情况下,我链接了绘图之间的交互性,以便您可以放大感兴趣的区域。
地中海旅行

这种可视化映射了整本书中提到的地中海周围位置的提及。在美学上,我对最终产品感到非常满意,maps包装中的低分辨率边框数据与原始文本产生了意想不到的协同作用,即封面上跳跃士兵(Yossarian)的锯齿状轮廓。因此我坚持使用低质量的地图数据,因为我非常喜欢这种效果。
显然,这些旅程也有一个时间元素,我通过应用线性淡入淡出来指示时间,这提示了提及的顺序。边缘由它们的大圆绘制,使用geosphereR中的包非常容易实现。
我觉得可视化提供了有关书籍的信息,这些信息在阅读过程中可能并不完全清楚。虽然我生动地记得米洛在第22章关于各种商船港口的疯狂旅行,但是看到它确实是多么疯狂是非常有趣的,并且为被拖了几天和被剥夺了睡眠的约塞连和奥尔感到遗憾。
人物外貌
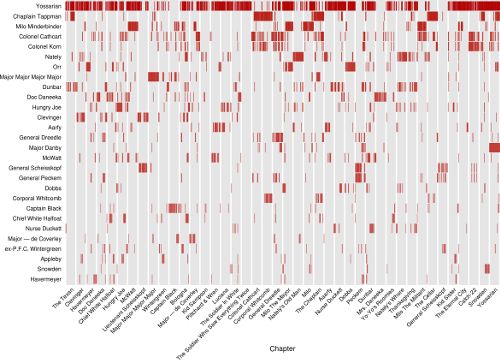
该图基本上代表了书中提到不同字符的时间序列。它的灵感来自杰夫克拉克的小说观点:悲惨世界系列中的“人物提名”情节。
我将数据绘制为标准散点图,章节为x轴(因为它与时间相似),字符为离散y轴,垂直条为标记。
我觉得这个可视化中的每个像素都很难。缺乏“点”的声音和它的存在一样响亮,特别是对于小说中的突出人物而言。我很高兴看到像章节这样的图案很重要,而其他图案几乎没有它们的名字。同样有趣的是看到一些主要角色真的只是偶尔出现在书中,即使它们给读者留下了持久的印象。
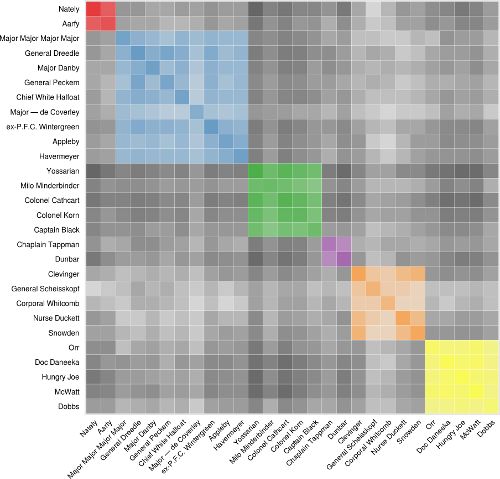
人物共同出现
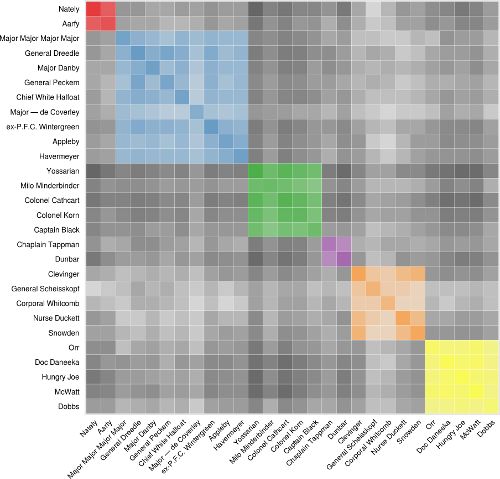
这个情节试图显示哪些角色在整本书中花费了大量时间。它的灵感来自Mike Bostock的悲惨世界共同策划。
用于构建此可视化的数据与前一个中使用的数据完全相同,但需要进行大量转换才能将其转换为可表示这些模式的形式。我们检查了许多不同的方法,以找出字符共处的位置,但我确定的是两个字符都只出现在一章中。寻找角色突出的时候(即两次都提到过)最终会创建一个极端偏向的视图,更频繁出现的角色完全支配着数据。实际上,当使用其他方法时,Yossarian与他自己的同位单元格比其他任何单元格高出几个数量级。
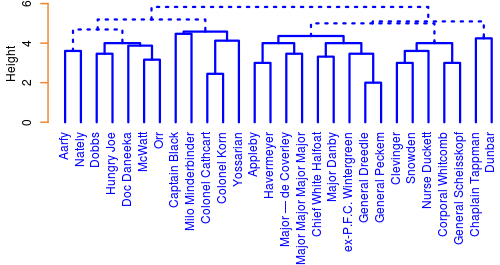
聚类为此图添加了另一个维度。在整本书上应用分层聚类方案,以尝试在角色中找到社区。再次,使用章节(1表示现在,0表示不存在)和42维欧几里德距离用于使用完整链接AGNES算法对字符进行聚类。对不同聚类方案和距离测量的树状图进行人工检查发现,这是最“水平”,因为更频繁出现的角色占主导地位的方案最少。这是六个簇的树形图:
当用户选择通过聚类对图进行着色时,用于共享相同聚类的字符的共同位置的单元用唯一颜色填充,而显示来自不同社区的字符的共同位置的那些单元用灰色阴影。应该注意,聚类是在整个文本上执行的,而不是由应用程序的用户放大的章节。我觉得动态改变聚类会让人分心。
字母或频率排序将群集“爆炸”成无法识别的空间,但按群集排序会将它们带入紧密的社区,让观众也可以看到群集之间的某些交互。
我对共同位置的编码和应用于每个单元的阴影的映射肯定会引起争论,而其他聚类方法导致找到非常不同的社区。也就是说,从定性上讲,我花了很多时间用我自己的文本知识来评估结果,发现当前的实现比我测试的任何其他实现更令人满意。
我发现书中的每个主角在某些时候与几乎所有其他角色互动都非常有趣。我不会期望这么多重叠。与Les Mis相比,情节更加密集,我怀疑这是由于聚集的章节数量的10倍差异。
特色词
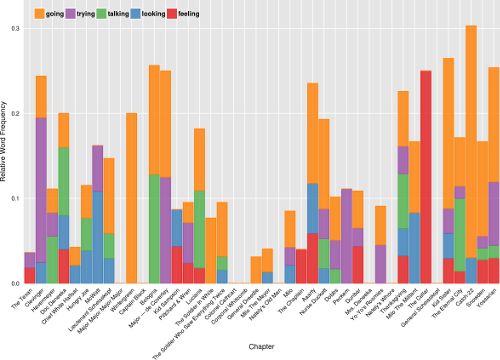
这个图可能是四个图中最常规的图,但可能显示了对文本的很多见解。由于单词窗口包围了Yossarian的提及,我希望它能捕捉到我们的主角在书中不同点感受到的一些不断变化的情绪。
我使用了nltk简化的词性标注,以获得最丰富的单词类型分类,并允许用户选择他们想要检查的词性。仅显示单词类型中的前几个单词,但随着章节范围的缩放,这将重新计算。通过这种方式,单词随着用户的探索而改变。
通过Yossarian在给定章节中提到的提及次数来标准频率这个词。例如,如果第1章中出现“war”一词20次,而Yossarian在该章中收到40次提及,那么该值将被赋予0.5。因此,对我们主要角色提及极高的章节不会有偏见,更重要的词会升到顶端。
我可以选择为此可视化选择堆叠条形图或堆积区域图。我喜欢堆积区域图更好地显示单词突出的连续章节,但是承认当章节之间存在高度可变性时,三角形形式会扭曲关系。我非常喜欢它呈现的景观美感。
顶部单词的动态重新计算使得每个设置的绘图都不同,并且可以根据选择提供各种各样的见解。虽然许多顶级单词都是无趣的,有些甚至被错误分类nltk,但有几次我发现一些非常有趣的单词很突出。