【读书笔记】大数据之路:阿里巴巴大数据实践
大数据之路:阿里巴巴大数据实践
简介:
在Alibaba集团内,数据人员面临的现实情况是:集团数据存储已经达到EB级别,部分单张表每天的数据记录数高达几千亿条;在2016年“双11购物狂欢节”的24小时中,支付金额达到了1207亿元人民币,支付峰值高达12万笔/秒,下单峰值达17.5万笔/秒,媒体直播大屏处理的总数据量高达百亿级别且所有数据都需要做到实时、准确地对外披露……巨大的信息量给数据采集、存储和计算都带来了极大的挑战。《大数据之路——Alibaba大数据实践》就是在此背景下完成的。本书中讲到的Alibaba大数据系统架构,就是为了满足不断变化的业务需求,同时实现系统的高度扩展性、灵活性以及数据展现的高性能而设计的。本书由Alibaba数据技术及产品部组织并完成写作,是Alibaba分享对大数据的认知,与生态伙伴共创数据智能的重要基石。相信本书中的实践和思考对同行会有很大的启发和借鉴意义。
目录:
第1章 总述 1
第1篇 数据技术篇
第2章 日志采集 8
2.1 浏览器的页面日志采集 8
2.1.1 页面浏览日志采集流程 9
2.1.2 页面交互日志采集 14
2.1.3 页面日志的服务器端清洗和预处理 15
2.2 无线客户端的日志采集 16
2.2.1 页面事件 17
2.2.2 控件点击及其他事件 18
2.2.3 特殊场景 19
2.2.4 H5 & Native日志统一 20
2.2.5 设备标识 22
2.2.6 日志传输 23
2.3 日志采集的挑战 24
2.3.1 典型场景 24
2.3.2 大促保障 26
第3章 数据同步 29
3.1 数据同步基础 29
3.1.1 直连同步 30
3.1.2 数据文件同步 30
3.1.3 数据库日志解析同步 31
3.2 阿里数据仓库的同步方式 35
3.2.1 批量数据同步 35
3.2.2 实时数据同步 37
3.3 数据同步遇到的问题与解决方案 39
3.3.1 分库分表的处理 39
3.3.2 高效同步和批量同步 41
3.3.3 增量与全量同步的合并 42
3.3.4 同步性能的处理 43
3.3.5 数据漂移的处理 45
第4章 离线数据开发 48
4.1 数据开发平台 48
4.1.1 统一计算平台 49
4.1.2 统一开发平台 53
4.2 任务调度系统 58
4.2.1 背景 58
4.2.2 介绍 59
4.2.3 特点及应用 65
MaxCompute
系统架构
MaxCompute以数据为中心,内建多种计算模型和服务接口,满足广泛的数据分析需求。一切服务“开通”即用,更好地赋能数据业务。
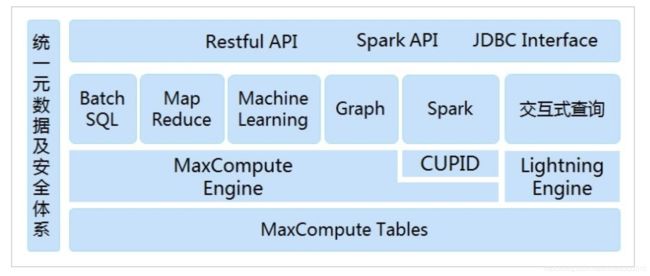
计算模型
支持SQL、MapReduce、Graph多种计算模型于一身
SQL
MaxCompute SQL采用标准的SQL语法,兼容部分Hive语法。在语法上和HQL非常接近,熟悉SQL或HQL的编程人员都容易上手。另外MaxCompute提供更高效的计算框架支持SQL计算模型,执行效率比普通的MapReduce模型更高。需要注意的是,MaxCompute SQL不支持事务、索引及Update/Delete等操作。
MapReduce
MaxCompute提供的Java MapReduce编程模型。值得注意的是,由于MaxCompute并没有开放文件接口,用户只能通过它所提供的Table读写数据,因此MaxCompute的MapReduce模型与开源社区中通用的MapReduce模型在使用上有一定的区别。我们相信,这样的改动虽然失去一定的灵活性,例如:不能够自定义排序及哈希算法,但却能够简化开发流程,免除很多琐碎的工作。更为重要的是,MaxCompute还提供了基于MapReduce的扩展计算模型, 即MR2。在该模型下,一个Map函数后,可以接入连续多个Reduce函数。
Graph
对于某些复杂的迭代计算场景,例如:K-Means,PageRank等,如果仍然使用MapReduce来完成这些计算任务将是非常耗时的。MaxCompute提供的Graph模型能够非常好的完成这一类计算任务。
第5章 实时技术 68
5.1 简介 69
5.2 流式技术架构 71
5.2.1 数据采集 72
5.2.2 数据处理 74
5.2.3 数据存储 78
5.2.4 数据服务 80
5.3 流式数据模型 80
5.3.1 数据分层 80
5.3.2 多流关联 83
5.3.3 维表使用 84
5.4 大促挑战&保障 86
5.4.1 大促特征 86
5.4.2 大促保障 88
第6章 数据服务 91
6.1 服务架构演进 91
6.1.1 DWSOA 92
6.1.2 OpenAPI 93
6.1.3 SmartDQ 94
6.1.4 统一的数据服务层 96
6.2 技术架构 97
6.2.1 SmartDQ 97
6.2.2 iPush 100
6.2.3 Lego 101
6.2.4 uTiming 102
6.3 最佳实践 103
6.3.1 性能 103
6.3.2 稳定性 111
第7章 数据挖掘 116
7.1 数据挖掘概述 116
7.2 数据挖掘算法平台 117
7.3 数据挖掘中台体系 119
7.3.1 挖掘数据中台 120
7.3.2 挖掘算法中台 122
7.4 数据挖掘案例 123
7.4.1 用户画像 123
7.4.2 互联网反作弊 125
第2篇 数据模型篇
第8章 大数据领域建模综述 130
8.1 为什么需要数据建模 130
8.2 关系数据库系统和数据仓库 131
8.3 从OLTP和OLAP系统的区别看模型方法论的选择 132
8.4 典型的数据仓库建模方法论 132
8.4.1 ER模型 132
8.4.2 维度模型 133
8.4.3 Data Vault模型 134
8.4.4 Anchor模型 135
8.5 阿里巴巴数据模型实践综述 136
1、为什么要建模意义
图书,希望分门别类摆放,电脑桌面上文件希望是自己习惯组织方式。

数据模型:数据组织和存储方法。强调从业务、存取和使用角度合理存储。
(烂程序员关心代码,好的程序员关系数据结构和他们间的关系)
重要性:
(1)性能:快速查询、减少IO。
(2)成本:降低计算和存储成本(减少数据冗余、结果复用)
(3)效率:提高查询效率(用户体验好)
(4)质量:改善口径不一致,减少计算错误可能性
2、关系数据库与数据仓库
目前仍大规模使用SQL加工处理,使用table存储数据,关系理论描述数据关系。大数据仅基于存储特点在关系模型的范式上有了新的选择。
OLTP和OLAP:OLTP数据操作随机读写,关注满足3NF的模型,事务处理中解决数据冗余和一致性问题。OLAP数据操作批量读写,关注数据整合和复杂查询的性能问题。
3、数据仓库建模方法论
(1)ER模型
Bill Inmon提出,从企业高度设计的一个3NF模型,用实体关系ER模型来描述企业业务,基本满足3NF理论。为数据分析决策服务,但不能直接用于分析决策。
与OLTP的3NF区别在于,站在企业角度面向主题抽象,而不是针对某一个业务流程的实体对象抽象。
三个特点:需全面了解企业业务和数据,实施周期长,成本高,模型人员要求高。
三个阶段:高阶模型(描述企业业务总体概况)、中层模型(高阶模型基础上细化数据项)、物理模型(中层模型基础上考虑物理存储和基于平台的性能物理属性设计)。
典型代表:Teradata金融行业的FS-LDM(Finacial Services Logical Data Model),10大主题。
(2)维度模型
Ralph Kimball提出,重点关注如何快速完成需求分析,同时复杂查询的响应性能。从分析决策需求出发构建模型,可直接用于分析决策。
设计步骤:选择分析决策业务过程,选择粒度,确定分析维度(维表),确定衡量指标(事实表)
典型代表:星形模型,特殊场景下使用雪花模型。
(3)Data Vault模型
Dan Linstedt提出,ER模型衍生,为实现数据整合,不能直接用于分析决策。
组成部分:hub(企业核心业务实体),Link(hub间的关系,与ER模型最大区别是将关系做为一个独立单元抽象,可提升扩展性),Satellite(hub的描述内容)
(4)Anchor模型
Lars Ronnback提出,高度可扩展模型,扩展只添加不修改。6NF,基本变成k-v结构化模型。增加非常多的join操作,主要适用于基于一小部分字段进行分析的查询,类似列式存储。
组成部分:Anchors(类似hub,业务实体,只有主键),Attributes(类似Satellite,一个表只有一个Anchors属性,k-v结构),Knots(可能会被Anchors使用的多个公共属性)
在各组成部分基础上,又细分历史和非历史。历史会以时间戳加多条记录方式,记录数据变迁历史。
4、阿里数据仓库模型建设发展阶段
(1)ODS+DSS
Oracle数据库,ODS贴源和DSS基于贴源的数据统计,无模型方法体系。
(2)ODL+BDL+IDL+ADL
MPP的Greenplum,希望使用模型改变烟囱式开发,提升数据一致性,减少冗余。ER模型+维度模型方式。
ODL(操作数据层)与源系统一致,
BDL(基础数据层)引入ER模型,进行数据整合,构建一致的基础数据模型。
IDL(接口数据层)引入维度模型,构建集市层。
ADL(应用数据层)完成应用个性化和基于展现需求的数据组装
经验总结:ER模型对于不成熟的、快速变化的业务不适用,风险特别大。
(3)维度建模为核心的公共层数据架构体系(One Data)
hadoop为代表的分布式存储计算平台,着力解决数据存储和数据共享问题。
第9章 阿里巴巴数据整合及管理体系 138
9.1 概述 138
9.1.1 定位及价值 139
9.1.2 体系架构 139
9.2 规范定义 140
9.2.1 名词术语 141
9.2.2 指标体系 141
9.3 模型设计 148
9.3.1 指导理论 148
9.3.2 模型层次 148

9.3.3 基本原则 150
高内聚低耦合
核心模型与扩展模型分离
9.4 模型实施 152
9.4.1 业界常用的模型实施过程 152
9.4.2 OneData实施过程 154
第10章 维度设计 159
10.1 维度设计基础 159
10.1.1 维度的基本概念 159
10.1.2 维度的基本设计方法 160
10.1.3 维度的层次结构 162
10.1.4 规范化和反规范化 163
10.1.5 一致性维度和交叉探查 165
10.2 维度设计高级主题 166
10.2.1 维度整合 166
10.2.2 水平拆分 169
10.2.3 垂直拆分 170
10.2.4 历史归档 171
10.3 维度变化 172
10.3.1 缓慢变化维 172
10.3.2 快照维表 174
10.3.3 极限存储 175
10.3.4 微型维度 178
10.4 特殊维度 180
10.4.1 递归层次 180
10.4.2 行为维度 184
10.4.3 多值维度 185
10.4.4 多值属性 187
10.4.5 杂项维度 188
第11章 事实表设计 190
11.1 事实表基础 190
11.1.1 事实表特性 190
11.1.2 事实表设计原则 191
11.1.3 事实表设计方法 193
11.2 事务事实表 196
11.2.1 设计过程 196
11.2.2 单事务事实表 200
11.2.3 多事务事实表 202
11.2.4 两种事实表对比 206
11.2.5 父子事实的处理方式 208
11.2.6 事实的设计准则 209
11.3 周期快照事实表 210
11.3.1 特性 211
11.3.2 实例 212
11.3.3 注意事项 217
11.4 累积快照事实表 218
11.4.1 设计过程 218
11.4.2 特点 221
11.4.3 特殊处理 223
11.4.4 物理实现 225
11.5 三种事实表的比较 227
11.6 无事实的事实表 228
11.7 聚集型事实表 228
11.7.1 聚集的基本原则 229
11.7.2 聚集的基本步骤 229
11.7.3 阿里公共汇总层 230
11.7.4 聚集补充说明 234
第3篇 数据管理篇
第12章 元数据 236
12.1 元数据概述 236
12.1.1 元数据定义 236
12.1.2 元数据价值 237
12.1.3 统一元数据体系建设 238
12.2 元数据应用 239
12.2.1 Data Profile 239
12.2.2 元数据门户 241
12.2.3 应用链路分析 241
12.2.4 数据建模 242
12.2.5 驱动ETL开发 243
第13章 计算管理 245
13.1 系统优化 245
13.1.1 HBO 246
13.1.2 CBO 249
13.2 任务优化 256
13.2.1 Map倾斜 257
13.2.2 Join倾斜 261
13.2.3 Reduce倾斜 269
第14章 存储和成本管理 275
14.1 数据压缩 275
14.2 数据重分布 276
14.3 存储治理项优化 277
14.4 生命周期管理 278
14.4.1 生命周期管理策略 278
14.4.2 通用的生命周期管理矩阵 280
14.5 数据成本计量 283
14.6 数据使用计费 284
第15章 数据质量 285
15.1 数据质量保障原则 285
15.2 数据质量方法概述 287
15.2.1 消费场景知晓 289
15.2.2 数据加工过程卡点校验 292
15.2.3 风险点监控 295
15.2.4 质量衡量 299
第4篇 数据应用篇
第16章 数据应用 304
16.1 生意参谋 305
16.1.1 背景概述 305
16.1.2 功能架构与技术能力 307
16.1.3 商家应用实践 310
16.2 对内数据产品平台 313
16.2.1 定位 313
16.2.2 产品建设历程 314
16.2.3 整体架构介绍 317
附录A 本书插图索引 320
